

转换加载器(Transform Loaders:)就像上文提到的的`TextLoader`一样 - 它们将输入格式转换为我们的文档格式。`LangChain`中有越来越多的转换加载器
Transform Loaders:将数据从特定格式加载到文档格式
转换加载器(Transform Loaders:)就像上文提到的的TextLoader一样 – 它们将输入格式转换为我们的文档格式。LangChain中有越来越多的转换加载器,包括但不限于以下几种:
- CSV
- HTML
- Markdown
- Microsoft Word/PowerPoint
- Notion (raw files or through API integration)
许多这些加载器的基础是Unstructured Python库。这个库非常擅长将各种文件类型转换为我们文档所需的文本数据。
无结构分区(Unstructured Partitions)
Unstructured库的核心概念是将文档划分为元素。当传递一个文件时,库将读取源文档,将其分割为多个部分,对这些部分进行分类,然后提取每个部分的文本。在划分之后,返回一个文档元素列表。
以下是直接使用库时的例子:
python复制代码from unstructured.partition.auto import partition
elements = partition(filename="dashboard.html")
该库在底层使用了一些工具来自动检测文件类型,并根据文件类型正确地进行划分。
例子:加载Microsoft Word文档
让我们看一下加载Microsoft Word文档的过程是什么样的。
这是我们的样例Word文档:
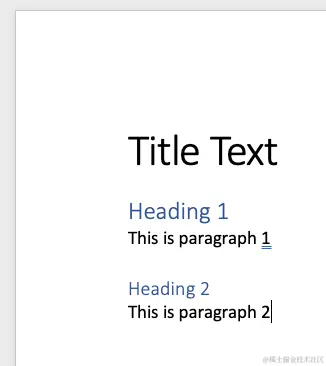
现在我们可以使用LangChain的UnstructuredWordDocumentLoader来划分这个文档。
python复制代码from langchain.document_loaders import UnstructuredWordDocumentLoader
# use mode="elements" to return each Element as a Document
# otherwise it defaults the "single" option which returns a single document
loader = UnstructuredWordDocumentLoader(file_path="test_doc.docx", mode="elements")
data = loader.load()
print(data)
当使用mode=”elements”时的结果,它将为源文档中的每个元素返回一个文档。
python复制代码[
Document(page_content = 'Title Text', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'Title'
}),
Document(page_content = 'Heading 1', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'Title'
}),
Document(page_content = 'This is paragraph 1', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'NarrativeText'
}),
Document(page_content = 'Heading 2', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'Title'
}),
Document(page_content = 'This is paragraph 2', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'NarrativeText'
})
]
使用默认的mode=”single”时的结果,它将为源文档中的所有文本返回一个单一的文档。
python复制代码[
Document(
page_content='Title TextnnHeading 1nnThis is paragraph 1nnHeading 2nnThis is paragraph 2',
metadata={'source': 'test_doc.docx'}
)
]
总结下,在”single”模式下,元素之间使用”nn”分隔符连接。接下来我们介绍文本拆分器时,这是字符拆分器的默认拆分字符。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
