

你好!欢迎来到《ChatGPT和OpenAI模型的现代生成式人工智能》!在本书中,我们将探索生成式人工智能(AI)的迷人世界以及它的创新应用。生成式AI已经改变了我们与机器的互动方式,使计算机能够在没有明确人类指令的情况下创造、预测和学习。通过ChatGPT和OpenAI,我们见证了在自然语言处理、图像和视频合成等领域取得的前所未有的进展。无论您是一个好奇的初学者还是经验丰富的从业者,本指南将为您提供在生成式AI令人兴奋的领域中导航所需的知识和技能。那么,让我们深入探讨并从一些定义开始,了解我们所处的背景。
本章概述了生成式AI领域,该领域利用机器学习(ML)算法创建新的、独特的数据或内容。它侧重于生成式AI在图像合成、文本生成、音乐创作等各个领域的应用,突出生成式AI革新各行各业的潜力。这个生成式AI的介绍将提供该技术的所处背景,以及将其置于人工智能(AI)、机器学习(ML)和深度学习(DL)广阔世界中的知识。然后,我们将详细探讨生成式AI的主要应用领域,并提供具体示例和最新进展,使您熟悉它对企业和社会的影响。
此外,了解生成式AI在当前最先进技术的研究历程将帮助您更好地理解最新进展和最先进模型的基础。
我们将涵盖以下主题:
- 理解生成式AI
- 探索生成式AI的领域
- 生成式AI研究的历史和现状
通过本章的学习,您将熟悉生成式AI的精彩世界,了解其应用、背后的研究历史以及当前的发展,这些都可能对企业产生颠覆性影响。
生成式AI的介绍
近年来,人工智能(AI)取得了显著的进展,其中一个领域取得了可观的增长是生成式人工智能(generative AI)。生成式AI是AI和深度学习(DL)的一个子领域,专注于使用机器学习(ML)技术训练的算法和模型,在现有数据的基础上生成新的内容,如图像、文本、音乐和视频。
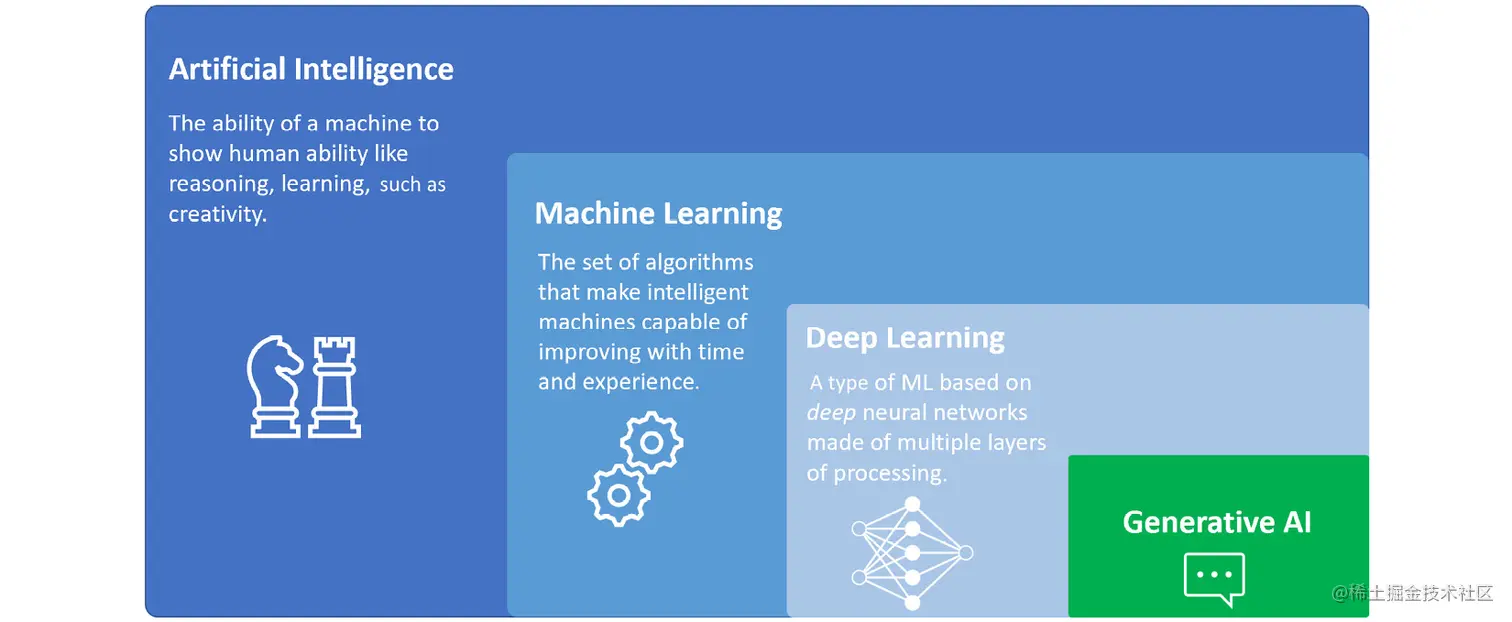
为了更好地理解AI、ML、DL和生成式AI之间的关系,可以将AI视为基础,而ML、DL和生成式AI则代表着越来越专门化和专注的研究和应用领域:
- AI代表着创建能够执行任务、展现人类智能和能力,并能够与生态系统进行交互的系统的广泛领域。
- ML是一个专注于创建算法和模型的分支,使这些系统能够通过时间和训练来学习和改进自己。ML模型从现有数据中学习,并随着其成长自动更新参数。
- DL是ML的一个子分支,它涵盖了深度学习模型。这些深度模型称为神经网络,特别适用于计算机视觉或自然语言处理(NLP)等领域。当我们谈论ML和DL模型时,通常指的是判别模型,其目的是对数据进行预测或推理模式。
- 最后,我们来到生成式AI,这是DL的进一步子分支,它不使用深度神经网络对现有数据进行聚类、分类或预测,而是利用这些强大的神经网络模型生成全新的内容,从图像到自然语言,从音乐到视频。
以下图表显示了这些研究领域之间的关系:
[图表:AI → ML → DL → 生成式AI]
生成式AI模型可以在大量数据上进行训练,然后利用数据中的模式从头开始生成新的示例。这个生成过程与判别模型不同,判别模型的训练目标是预测给定示例的类别或标签。
生成式AI的领域
近年来,生成式人工智能(generative AI)取得了重大进展,并将其应用扩展到艺术、音乐、时尚、建筑等广泛领域。在某些领域中,生成式AI确实正在改变我们创造、设计和理解周围世界的方式。在其他领域中,它正在改进和提高现有的流程和操作的效率。
生成式AI在许多领域中的应用意味着其模型可以处理不同类型的数据,从自然语言到音频或图像。让我们了解生成式AI模型如何处理不同类型的数据和领域。
文本领域
生成式AI的最重要的应用之一,也是我们在本书中将重点涵盖的内容,是其能够生成自然语言的新内容。事实上,生成式AI算法可以用于生成新的文本,如文章、诗歌和产品描述。
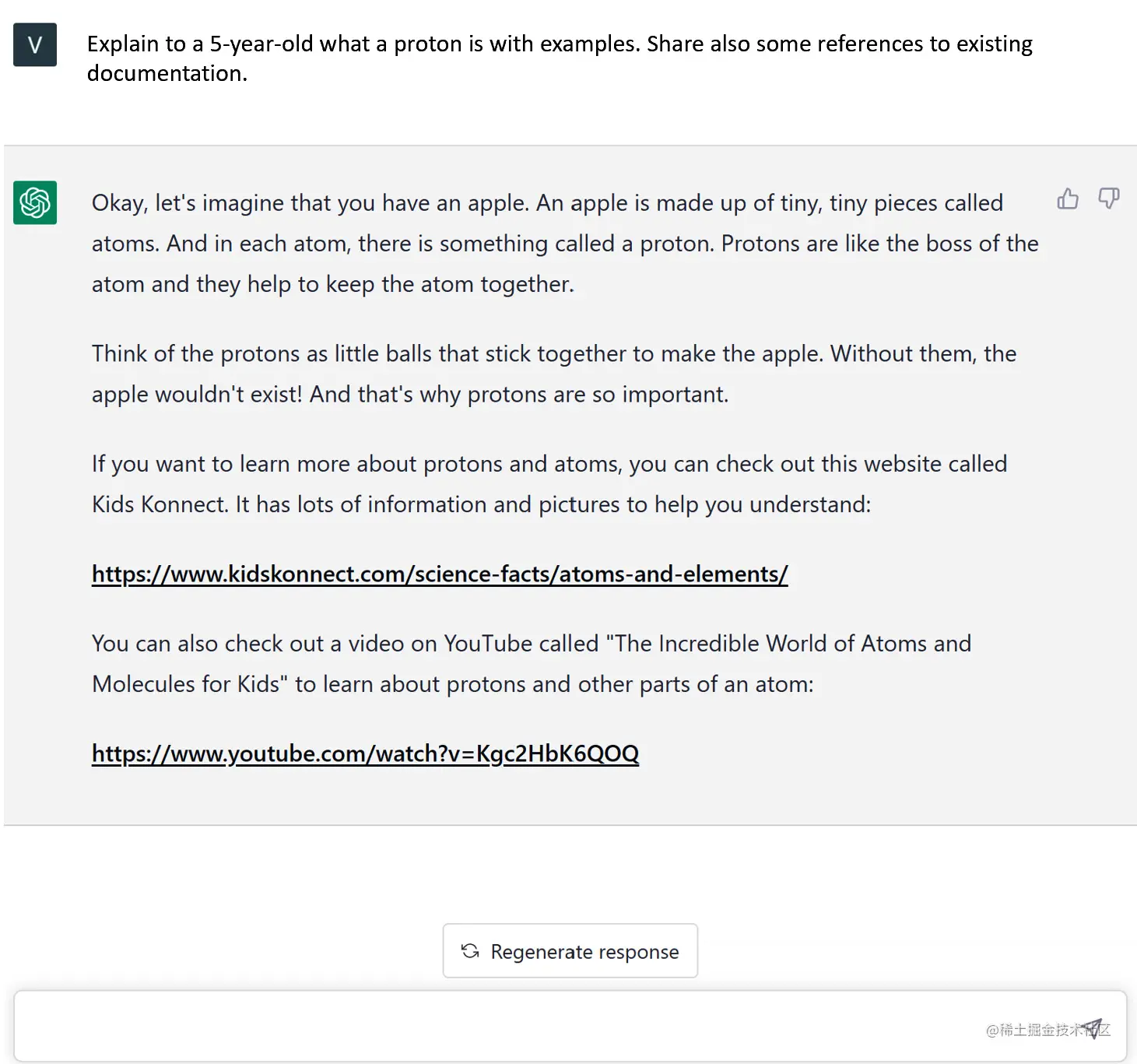
例如,OpenAI开发的GPT-3等语言模型可以在大量文本数据上进行训练,然后用于生成新的、连贯且符合语法规则的文本,可以处理不同语言(无论是输入还是输出),还可以从文本中提取相关特征,如关键词、主题或全文摘要。
以下是使用GPT-3的示例:
图像领域
在图像合成方面,生成式AI最早且最为人熟知的例子之一是生成对抗网络(Generative Adversarial Network,简称GAN)架构,该架构在2014年I. Goodfellow等人的论文《生成对抗网络》中首次提出。GAN的目的是生成与真实图像无法区分的逼真图像。这项能力在业务应用中具有多个有趣的应用,例如为训练计算机视觉模型生成合成数据集,生成逼真的产品图像,以及为虚拟现实和增强现实应用生成逼真图像。
以下是一个由AI完全生成的不存在的人脸的示例:

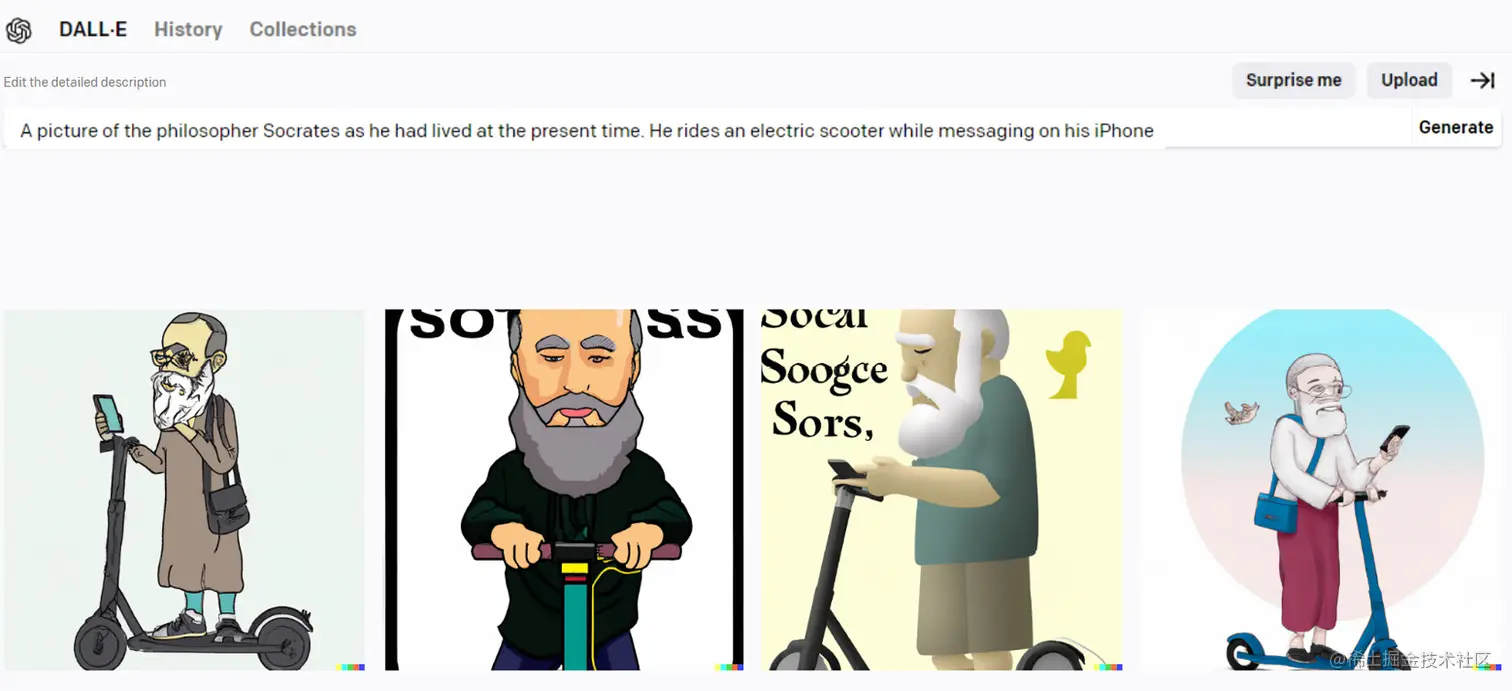
然后,2021年,OpenAI在这个领域引入了一种新的生成式AI模型,名为DALL-E。与GAN不同,DALL-E模型设计用于根据自然语言描述生成图像(GAN以随机噪声向量作为输入),它可以生成各种各样的图像,这些图像可能看起来不太真实,但仍能描绘出所需的概念。
DALL-E在广告、产品设计、时尚等创意产业中具有巨大潜力,可以创建独特而富有创意的图像。
在这里,您可以看到DALL-E根据自然语言请求生成四幅图像的示例:
请注意,文本和图像生成可以结合在一起产生全新的材料。近年来,广泛应用的新型AI工具就使用了这种组合。
一个例子是Tome AI,它是一种生成式叙事格式,除了其他能力外,还能够从零开始创建幻灯片,利用了DALL-E和GPT-3等模型。

正如您所见,前面的AI工具完全能够根据我在自然语言中提供的简短输入创建一个初步的演示文稿。
音乐领域
生成音乐的生成式AI最早可以追溯到50年代,当时在算法作曲领域进行了研究,这是一种利用算法生成音乐作品的技术。事实上,1957年,Lejaren Hiller和Leonard Isaacson创作了《Illiac弦乐四重奏组曲》(www.youtube.com/watch?v=n0n…),这是第一首完全由AI创作的音乐作品。从那时起,音乐生成式AI领域已经持续进行了几十年的研究。在最近几年的发展中,新的架构和框架已经在公众中广泛应用,例如谷歌于2016年推出的WaveNet架构,它能够生成高质量的音频样本,以及谷歌开发的Magenta项目,该项目使用循环神经网络(RNN)和其他机器学习技术来生成音乐和其他形式的艺术。然后,在2020年,OpenAI还宣布推出了Jukebox,一种能够生成音乐的神经网络,可以根据音乐和声乐风格、流派、参考艺术家等进行输出的定制。
这些和其他框架成为许多音乐生成的AI作曲助手的基础。一个例子是索尼CSL研究开发的Flow Machines。这个生成式AI系统是通过对大量音乐作品进行训练而创建的,可以创作多种风格的新音乐。法国作曲家Benoît Carré使用它创作了一张名为《Hello World》(www.helloworldalbum.net/)的专辑,其中与几位人类音乐家合作。
在这里,您可以听到完全由Magenta项目中的Music Transformer模型生成的一首曲目的例子:

音乐领域中生成式AI的另一个令人难以置信的应用是语音合成。事实上,可以找到许多能够根据文本输入以知名歌手的声音创建音频的AI工具。 例如,如果您一直想知道如果Kanye West演唱您的歌曲会是什么样子,那么现在您可以通过FakeYou.com (fakeyou.com/)、Deep Fake Text to Speech或UberDuck.ai (uberduck.ai/)等工具来实现您的梦想。
不得不说,结果真的令人印象深刻。如果你想好好玩一下,你还可以尝试一下你所有最喜欢的卡通人物的声音,比如小熊维尼… 接下来,我们来看看生成式AI在视频领域的应用。
视频领域
生成式AI用于视频生成与图像生成有着相似的发展时间线。事实上,视频生成领域的关键发展之一就是生成对抗网络(GAN)的发展。由于其在生成逼真图像方面的准确性,研究人员开始将这些技术应用于视频生成。基于GAN的视频生成的最显著示例之一是DeepMind的“运动到视频”(Motion to Video)系统,它可以从一张单独的图像和一系列动作生成高质量的视频。另一个很好的例子是NVIDIA的“视频到视频合成”(Vid2Vid)基于深度学习的框架,它使用GAN来合成高质量的视频。 Vid2Vid系统能够生成时间连续的视频,即它们在时间上保持平滑和逼真的运动。该技术可以用于执行各种视频合成任务,例如:
- 将一个领域的视频转换为另一个领域(例如,将白天的视频转换为夜晚的视频或将草图转换为逼真的图像)
- 修改现有视频(例如,更改视频中物体的风格或外观)
- 从静态图像创建新的视频(例如,将一系列静态图像制作成动画)
在2022年9月,Meta的研究人员宣布了Make-A-Video(makeavideo.studio/)的普遍可用性,这是一个新的AI系统,允许用户将自然语言提示转换为视频片段。在这样的技术背后,你可以看到我们之前提到的许多模型,例如语言理解用于提示,图像和动作生成与图像生成,以及由AI作曲家创作的背景音乐。总的来说,生成式AI多年来已经对许多领域产生了影响,并且一些AI工具已经持续支持艺术家、组织和一般用户。未来似乎非常有前途;然而,在跳跃到市场上现有的终极模型之前,我们首先需要更深入地了解生成式AI的起源、研究历史以及最近的发展,这最终导致了当前的OpenAI模型。
研究的历史和当前状况
在前面的部分中,我们概述了生成式人工智能领域最近几年的最新和尖端技术。然而,这个领域的研究可以追溯到几十年前。
我们可以将生成式人工智能研究的起点标记为20世纪60年代,当时Joseph Weizenbaum开发了聊天机器人ELIZA,这是NLP系统的最早例子之一。它是一个基于规则的简单交互系统,旨在通过基于文本输入的响应来娱乐用户,并为NLP和生成式人工智能的进一步发展铺平了道路。然而,现代生成式人工智能是深度学习的一个子领域,虽然最早的人工神经网络(ANNs)是在1940年代首次提出的,但研究人员面临着诸多挑战,包括计算能力有限和对大脑生物学基础的理解不足。因此,直到20世纪80年代,人工神经网络才引起了较大的关注,当时除了新的硬件和神经科学的发展之外,反向传播算法的出现也简化了人工神经网络的训练过程。事实上,在反向传播算法出现之前,训练神经网络是困难的,因为无法有效地计算出与每个神经元相关的参数或权重的误差梯度,而反向传播使得自动化训练过程成为可能,并实现了人工神经网络的应用。
然后,在21世纪2000年代和2010年代,计算能力的提升以及大量可用于训练的数据使得深度学习变得更加实用和普及,从而推动了研究的发展。
在2013年,Kingma和Welling在他们的论文《Auto-Encoding Variational Bayes》中引入了一种新的模型架构,称为变分自编码器(VAEs)。VAEs是基于变分推断概念的生成模型。它们通过将数据编码成一个称为潜空间(使用编码器组件)的低维空间中的紧凑表示,然后将其解码回原始数据空间(使用解码器组件)来学习。
VAEs的关键创新是对潜空间引入概率解释。编码器不再学习从输入到潜空间的确定性映射,而是将输入映射到潜空间上的概率分布。这使得VAEs能够通过从潜空间中采样并将样本解码回输入空间来生成新样本。
举个例子,假设我们想训练一个能够创建看起来像是真实猫和狗图片的新猫和狗图片的VAE。
为了实现这一目标,VAE首先接收一张猫或狗的图片,并将其压缩成一组较小的数字,这些数字表示图片的最重要特征。这些数字称为潜变量。
然后,VAE使用这些潜变量来创建一张新的图片,看起来像是真实的猫或狗图片。这张新图片可能与原始图片有一些差异,但它仍然应该看起来属于同一组图片。
随着时间的推移,VAE通过将生成的图片与真实图片进行比较,并调整其潜变量使生成的图片更像真实图片,从而不断改善生成逼真图片的能力。
VAEs为生成式人工智能领域的快速发展铺平了道路。事实上,仅仅一年后,Ian Goodfellow提出了GANs。与VAEs架构不同,VAEs的主要组成部分是编码器和解码器,而GANs由两个神经网络组成——生成器和判别器——它们在一个零和博弈中相互竞争。
生成器创建伪造的数据(在图像的情况下,创建一张新的图像),旨在看起来像真实数据(例如一张猫的图像)。判别器接收真实数据和伪造数据,并试图区分它们——在我们对艺术赝品制作者的例子中,判别器充当评论家的角色。
在训练过程中,生成器试图创建可以欺骗判别器以为它是真实数据的数据,而判别器试图变得更擅长区分真实数据和伪造数据。这两个部分通过对抗性训练的过程一起进行训练。
随着时间的推移,生成器在创建看起来像真实数据的伪造数据方面变得越来越好,而判别器在区分真实数据和伪造数据方面也变得越来越好。最终,生成器变得非常擅长创建看起来像真实数据的伪造数据,以至于判别器甚至无法区分真实数据和伪造数据的区别。
这里有一个由GAN完全生成的人脸的例子:

这两种模型——VAEs和GANs——旨在生成与原始样本无法区分的全新数据,并且它们的架构在它们的概念提出后不断改进,与此同时,像Van den Oord及其团队提出的PixelCNNs和Google DeepMind开发的WaveNet等新模型的发展也推动了音频和语音生成的进步。
另一个重要的里程碑是在2017年,谷歌研究人员在一篇名为《Attention Is All You Need》的论文中介绍了一种名为Transformer的新架构。在语言生成领域,这是一场革命,因为它允许并行处理同时保留有关语言上下文的记忆,优于以循环神经网络(RNNs)或长短期记忆(LSTM)框架为基础的语言模型的先前尝试。
Transformer确实为谷歌在2018年推出的名为BERT(Bidirectional Encoder Representations from Transformers)的大型语言模型奠定了基础,并很快成为自然语言处理实验的基准。
Transformer也是OpenAI引入的所有生成式预训练(GPT)模型的基础,包括ChatGPT背后的GPT-3模型。
尽管在这些年中有大量的研究和成就,但直到2022年下半年,公众的普遍关注才转向生成式人工智能领域。
不是偶然的是,2022年被称为生成式人工智能之年。这一年,强大的AI模型和工具在普通大众中广泛传播:基于扩散的图像服务(MidJourney、DALL-E 2和Stable Diffusion)、OpenAI的ChatGPT、文本到视频(Make-a-Video和Imagen Video)以及文本到3D(DreamFusion、Magic3D和Get3D)工具都对个人用户提供了使用,有时甚至是免费的。
这对于两个主要原因产生了颠覆性的影响:
- 一旦生成式人工智能模型传播到公众,每个个人用户或组织都有可能在不需要成为数据科学家或机器学习工程师的情况下,对其潜力进行实验和欣赏。
- 这些新模型的输出和它们内嵌的创造力在客观上令人惊叹,而且常常引起关注。迫切需要对个人和政府进行适应的呼声也随之而起。
因此,从现在开始不久的将来,我们可能会目睹人工智能系统在个人使用和企业级项目中的采用急剧增加。
总结
在本章中,我们探索了令人兴奋的生成式人工智能世界及其在图像生成、文本生成、音乐生成和视频生成等各个领域的应用。我们了解了生成式人工智能模型(如OpenAI训练的ChatGPT和DALL-E)如何利用深度学习技术来学习大规模数据集中的模式,并生成既新颖又连贯的内容。我们还讨论了生成式人工智能的历史、起源以及当前的研究现状。
本章的目标是为生成式人工智能的基础知识打下坚实的基础,并激发您进一步探索这个迷人领域的兴趣。
在下一章中,我们将重点介绍目前市场上最具前景的技术之一,即ChatGPT:我们将深入了解其背后的研究和OpenAI的开发工作,探讨其模型的架构以及它可以解决的主要用例。
