

在本章中,我们将讨论开发人员如何利用ChatGPT。本章重点介绍了ChatGPT在开发领域的主要应用场景,包括代码审查和优化、文档生成以及代码生成。本章将提供示例,并让您可以自行尝试使用提示。
在介绍为什么开发人员应该将ChatGPT作为日常助手的一般原因之后,我们将重点关注ChatGPT,并介绍以下几个方面:
- 为什么开发人员应该选择ChatGPT?
- 生成、优化和调试代码
- 生成与代码相关的文档并调试您的代码
- 解释机器学习(ML)模型,以帮助数据科学家和业务用户理解模型的可解释性
- 翻译不同的编程语言
通过本章的学习,您将能够在编码活动中利用ChatGPT,并将其作为您编码生产力的助手。
为什么开发人员应选择ChatGPT?
就个人而言,我认为ChatGPT最令人惊叹的能力之一是处理代码。无论是哪种类型的代码,ChatGPT都可以胜任。我们在第四章已经看到了ChatGPT如何作为Python控制台的示例。然而,ChatGPT对于开发人员的能力远不止这个例子。它可以成为代码生成、解释和调试的日常助手。
在最流行的编程语言中,我们当然可以提到Python、JavaScript、SQL和C#。然而,ChatGPT覆盖了广泛的编程语言,如它自己所透露的那样:
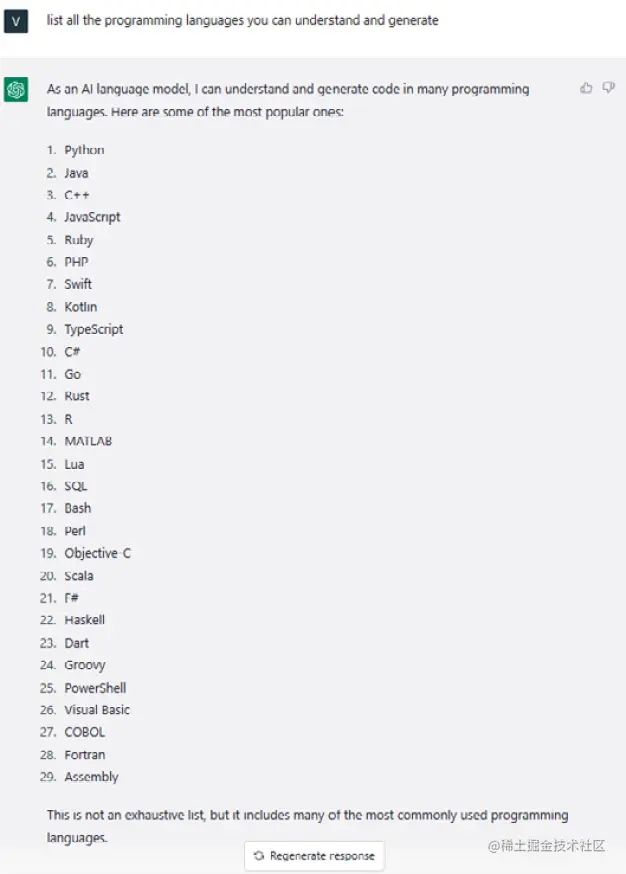
无论您是后端/前端开发人员、数据科学家还是数据工程师,只要您使用编程语言进行工作,ChatGPT都可以改变游戏规则,接下来的几个示例中我们将看到如何实现这一点。
从下一节开始,我们将深入探讨ChatGPT在处理代码时可以实现的具体示例。我们将看到涵盖不同领域的端到端用例,以便我们熟悉如何使用ChatGPT作为代码助手。
生成、优化和调试代码
您应该利用的主要功能是ChatGPT的代码生成能力。有多少次您在寻找预先构建的代码片段来作为起点?生成工具函数、示例数据集、SQL模式等等?ChatGPT能够根据自然语言输入生成代码:
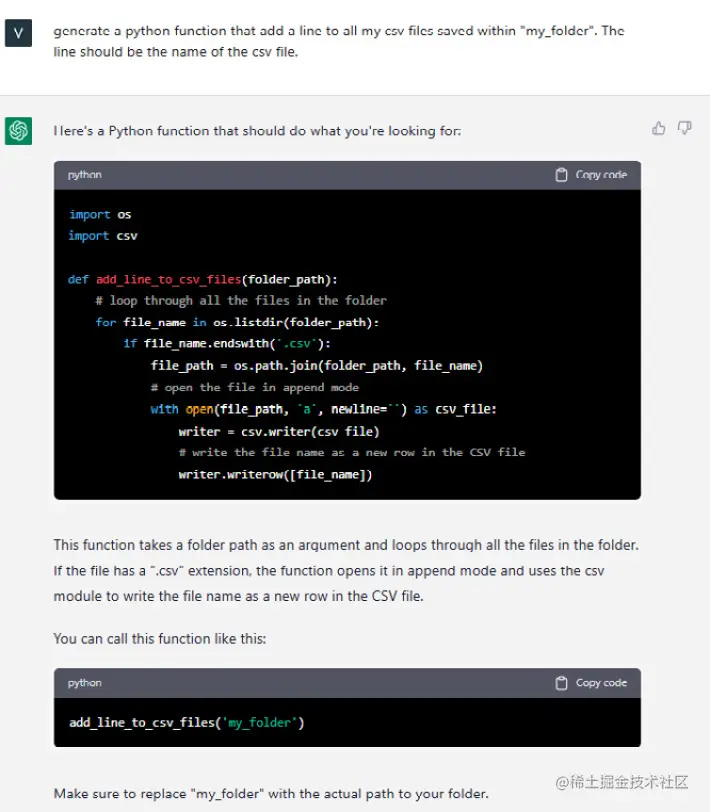
正如您所看到的,ChatGPT不仅能够生成函数,还能够解释函数的作用、如何使用以及使用类似my_folder的占位符进行替换。
另一个例子是创建结构化表的模式。假设您是一位数据工程师,正在为SAP ERP系统中的两个标准表(MARA和VBAP)之间创建关系,分别存储常规物料数据和销售文档数据。
让我们通过给出列名作为上下文,向ChatGPT询问为这些表创建模式:
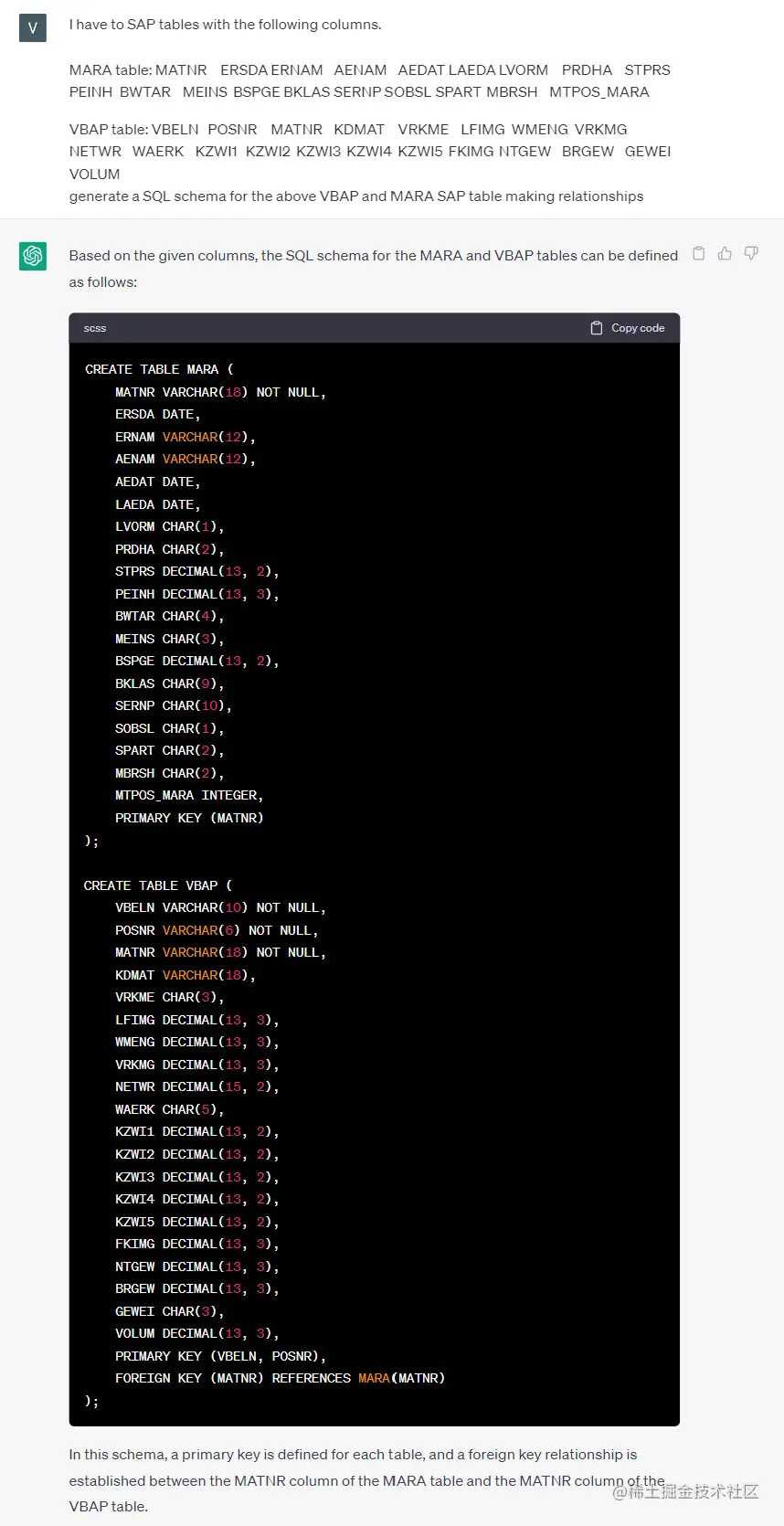
需要注意的是,ChatGPT能够建立关系,因为它了解SAP的分类法和列名解释,而这是许多不熟悉SAP分类法(包括数据工程师在内)的人所困扰的。为了证实这一点,让我们请ChatGPT使用更易理解的名称来重命名所有这些列:

最后,让我们使用新的列重新创建模式,确保避免重复(新名称“Condition Value”确实重复了五次):
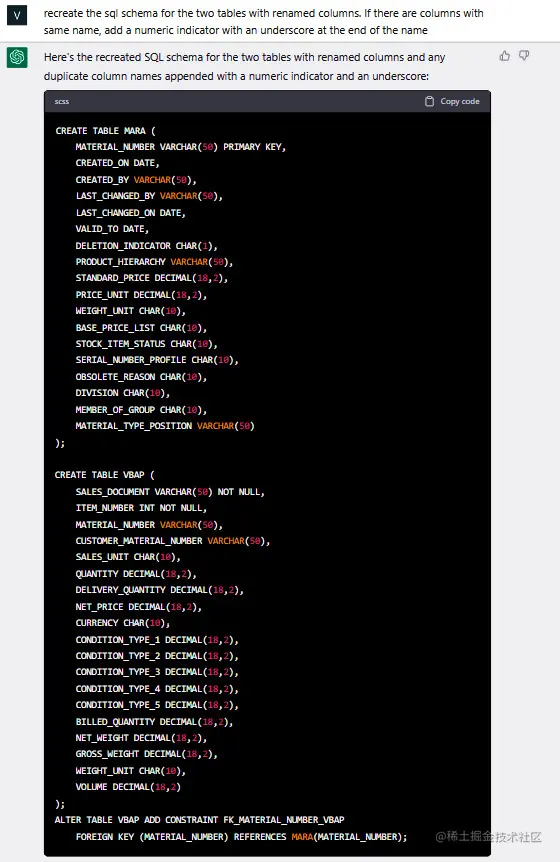
上述示例是减少创建进一步数据分析模式所需时间的关键。
ChatGPT还可以成为代码优化的良好助手。事实上,通过从输入开始生成优化脚本,它可以节省运行时间或计算资源。在自然语言领域中,这种能力可以与我们在第5章“提高写作技巧和翻译”部分中看到的写作辅助功能进行比较。
例如,假设您想从另一个列表开始创建一个奇数列表。为了实现这个目标,您编写了以下Python脚本(为了本练习的目的,我还使用了timeit和datetime库来跟踪执行时间):
ini复制代码from timeit import default_timer as timer
from datetime import timedelta
start = timer()
elements = list(range(1_000_000))
data = []
for el in elements:
if not el % 2:
# if odd number
data.append(el)
end = timer()
print(timedelta(seconds=end-start))
执行时间为0.141185秒。如果我们要求ChatGPT优化这个脚本,会发生什么呢?
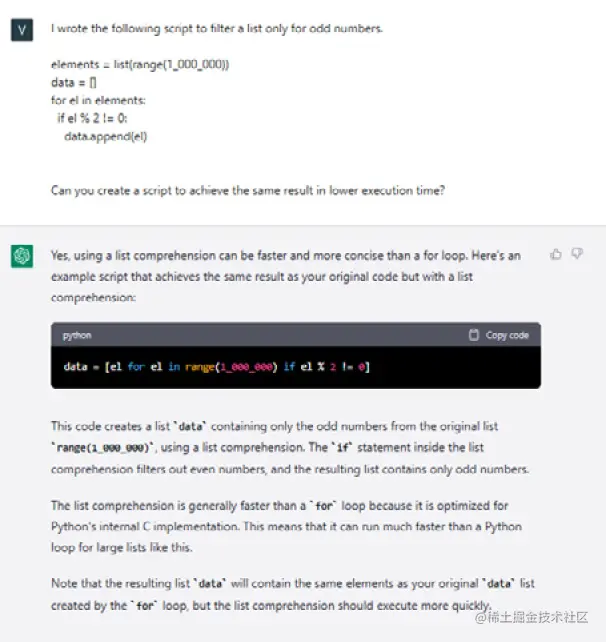
ChatGPT向我提供了一个例子,以更短的执行时间达到相同的结果。它还详细解释了为什么列表推导方法比for循环更快的原因。
让我们看看这个新脚本与之前的脚本相比的性能:
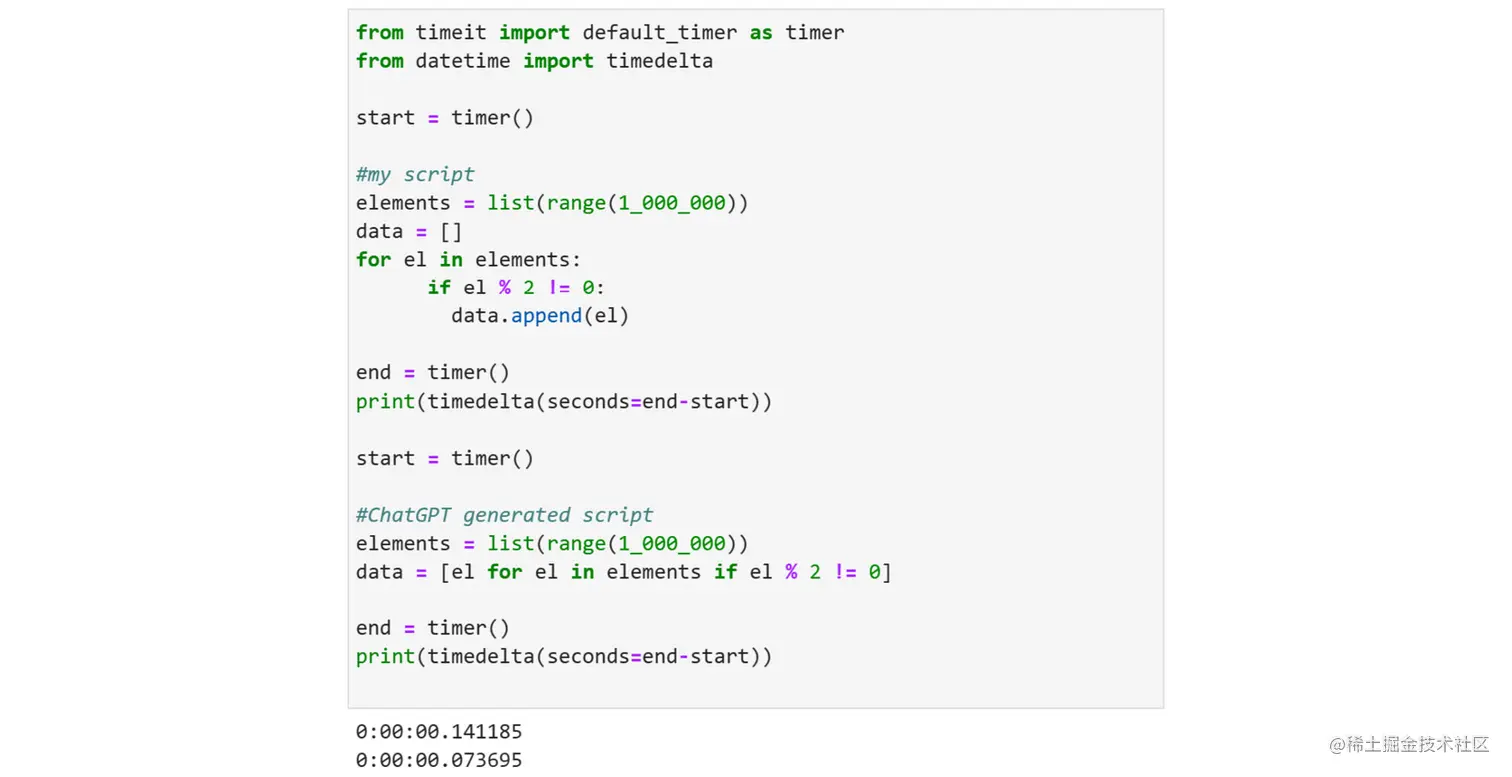
正如您所见,第二种方法(由ChatGPT生成)的执行时间减少了约47.8%。
除了代码生成和优化之外,ChatGPT还可以用于错误解释和调试。有时,错误很难解释;因此,自然语言解释可以帮助您确定问题并引导您找到解决方案。
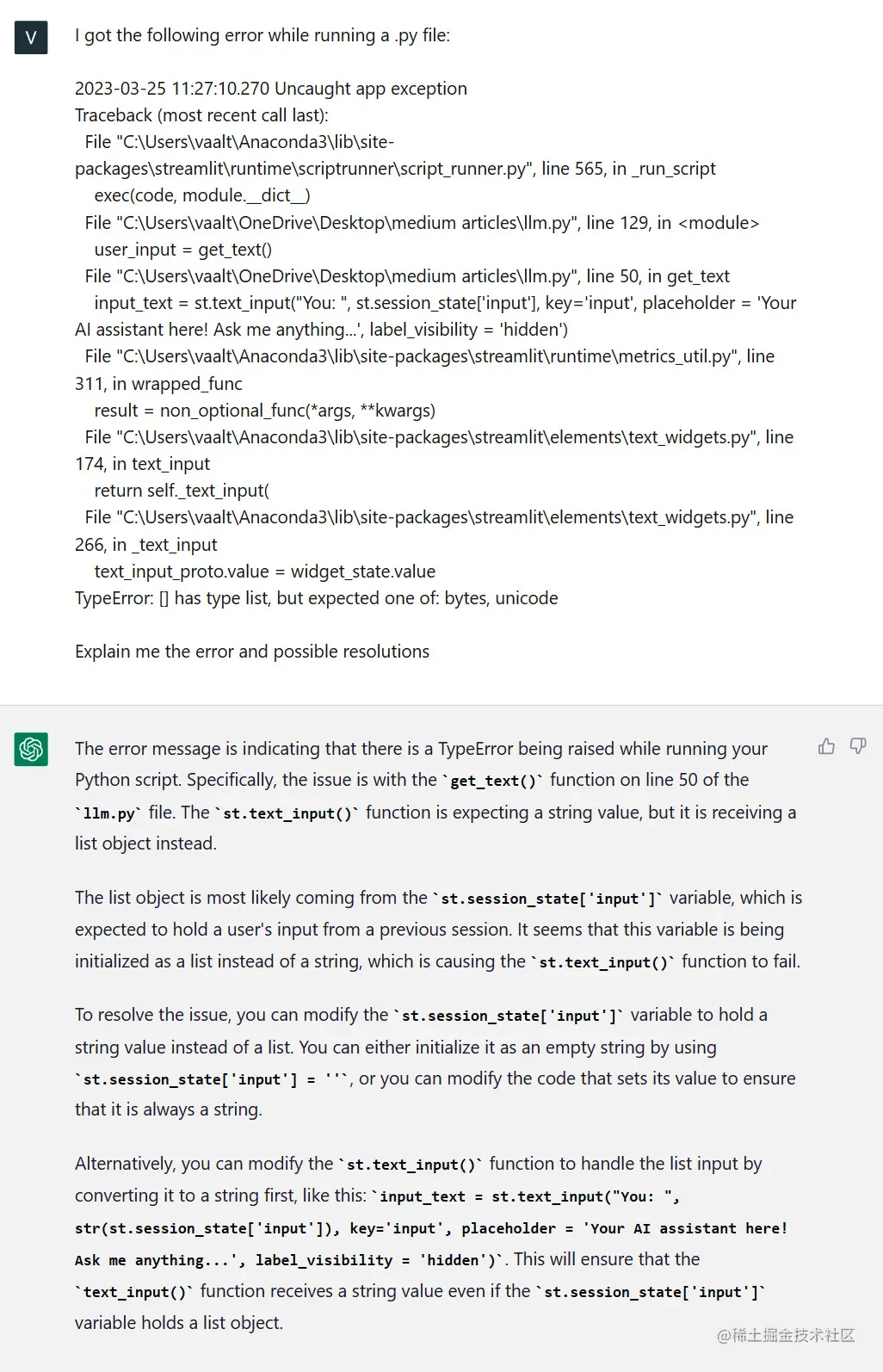
例如,当我从命令行运行一个.py文件时,出现了以下错误:
arduino复制代码2023-03-25 11:27:10.270 Uncaught app exception
Traceback (most recent call last):
File "C:UsersvaaltAnaconda3libsite-packagesstreamlitruntimescriptrunnerscript_runner.py", line 565, in _run_script
exec(code, module.__dict__)
File "C:UsersvaaltOneDriveDesktopmedium articlesllm.py", line 129, in <module>
user_input = get_text()
File "C:UsersvaaltOneDriveDesktopmedium articlesllm.py", line 50, in get_text
input_text = st.text_input("You: ", st.session_state['input'], key='input', placeholder = 'Your AI assistant here! Ask me anything...', label_visibility = 'hidden')
File "C:UsersvaaltAnaconda3libsite-packagesstreamlitruntimemetrics_util.py", line 311, in wrapped_func
result = non_optional_func(*args, **kwargs)
File "C:UsersvaaltAnaconda3libsite-packagesstreamlitelementstext_widgets.py", line 174, in text_input
return self._text_input(
File "C:UsersvaaltAnaconda3libsite-packagesstreamlitelementstext_widgets.py", line 266, in _text_input
text_input_proto.value = widget_state.value
TypeError: [] has type list, but expected one of: bytes, Unicode
让我们看看ChatGPT是否能帮助我理解错误的本质。为此,我只需将错误文本提供给ChatGPT,并要求它给我解释。
最后,让我们假设我在Python中编写了一个函数,它接受一个字符串作为输入,并返回在每个字母后面加上下划线的相同字符串。
在上面的例子中,我期望看到 g_p_t_ 的结果,但是使用这段代码只返回了 t_:

让我们请求ChatGPT为我们调试这个函数:
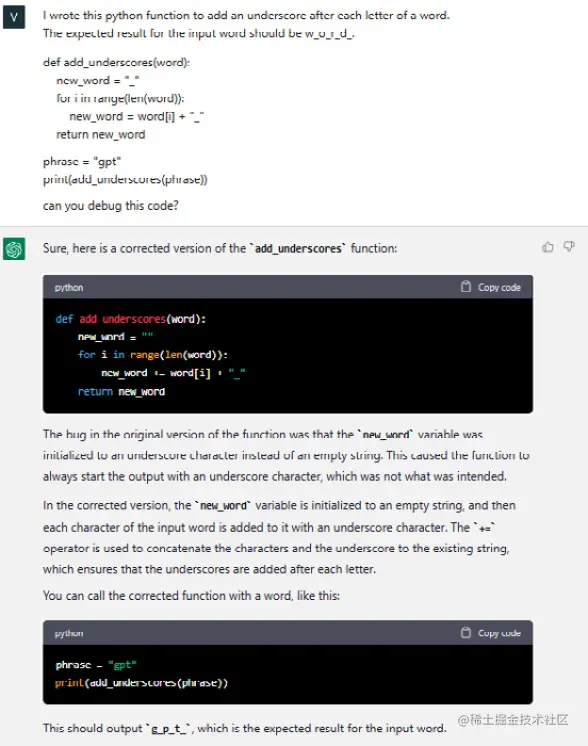
令人印象深刻,不是吗?再次,ChatGPT提供了正确的代码版本,并帮助解释了错误出现的位置以及为什么会导致不正确的结果。现在让我们看看它是否能正常工作:

显然可以!这些以及许多其他与代码相关的功能可以大大提高您的工作效率,缩短完成许多任务所需的时间。
然而,ChatGPT不仅限于纯粹的调试功能。由于GPT模型在语言理解方面的出色表现,这个人工智能(AI)工具能够在代码旁生成适当的文档,并且能够准确解释一段代码将做什么,我们将在下一部分中看到。
生成文档和代码解释
无论在处理新的应用程序或项目时,将代码与文档相关联都是一个良好的实践。可以通过在函数或类中嵌入文档字符串的方式提供文档,以便他人可以直接在开发环境中调用它们。
例如,下面的Python类包含了10个不同的方法用于基本的数学运算:
python复制代码class Calculator:
def add(self, x, y):
return x + y
def subtract(self, x, y):
return x - y
def multiply(self, x, y):
return x * y
def divide(self, x, y):
try:
return x / y
except ZeroDivisionError:
print("Error: division by zero")
return None
def power(self, x, y):
return x ** y
def square_root(self, x):
try:
return x ** 0.5
except ValueError:
print("Error: square root of a negative number")
return None
def logarithm(self, x, base):
try:
return math.log(x, base)
except ValueError:
print("Error: invalid logarithm arguments")
return None
def factorial(self, x):
if x < 0:
print("Error: factorial of a negative number")
return None
elif x == 0:
return 1
else:
return x * self.factorial(x-1)
def fibonacci(self, n):
if n < 0:
print("Error: fibonacci sequence index cannot be negative")
return None
elif n == 0:
return 0
elif n == 1:
return 1
else:
return self.fibonacci(n-1) + self.fibonacci(n-2)
您可以按照以下方式初始化该类并进行测试(作为示例,我将使用加法方法):

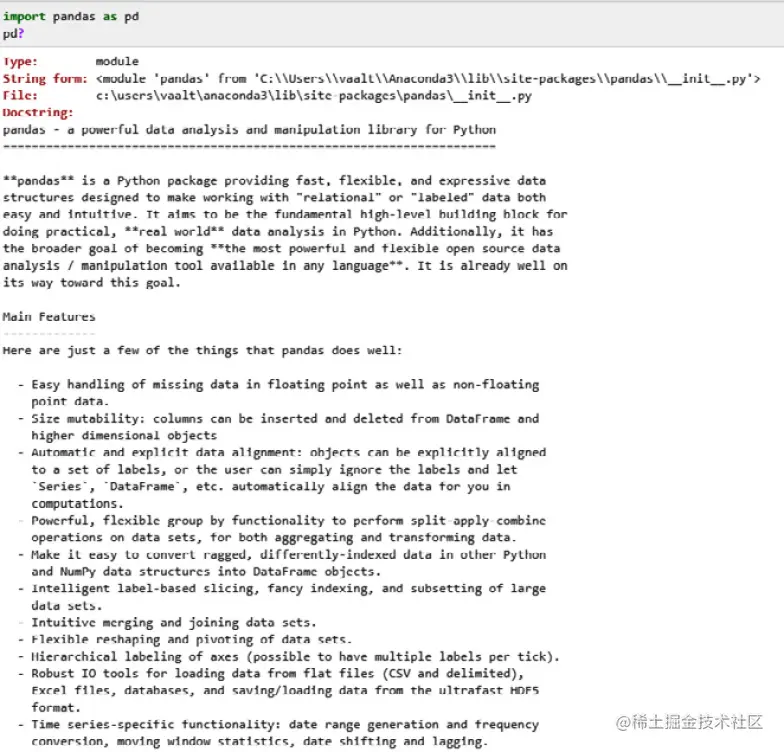
现在,假设我希望能够使用Calculator?的方式检索文档字符串文档。通过这种方式,对于Python包、函数和方法,我们可以完整地获得该特定对象的功能文档,如下所示(以pandas Python库为例):
现在,让我们请求ChatGPT为我们的Calculator类生成相同的结果。
因此,在将Calculator类作为上下文提供给ChatGPT之后,我请求它按照以下方式生成相关文档:
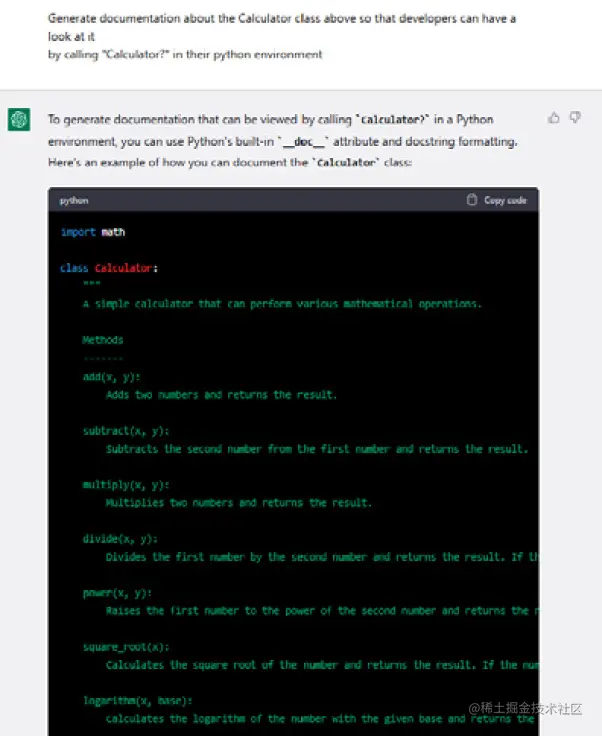
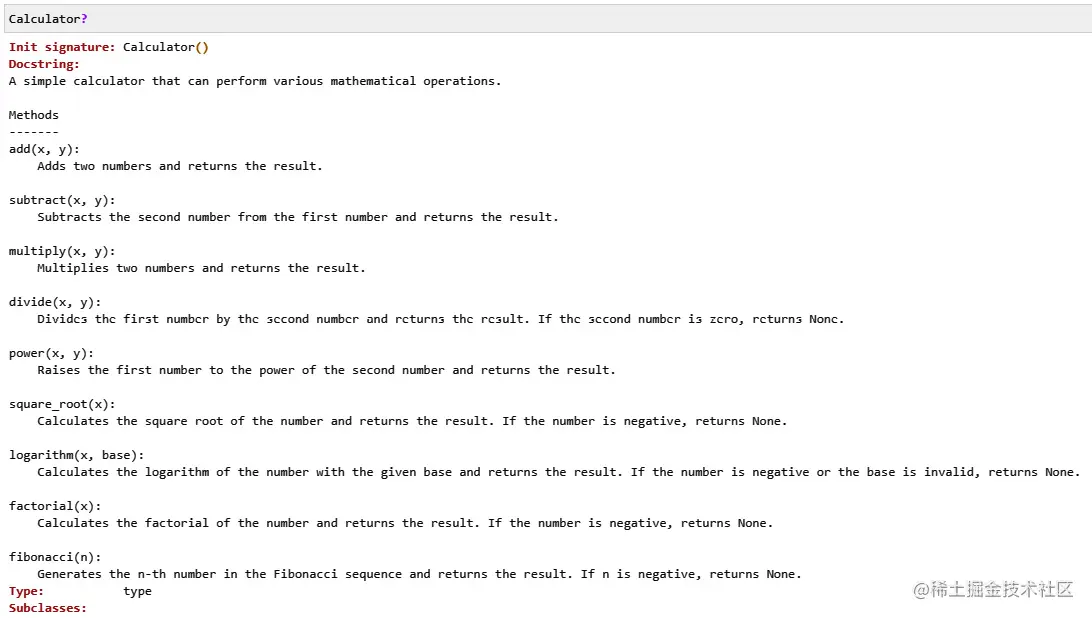
您可以在本书的GitHub存储库中找到完整的ChatGPT响应,网址为github.com/PacktPublis… 因此,如果我们按照上述代码更新我们的类并调用Calculator?,将会得到以下输出:
最后,ChatGPT还可以用自然语言解释脚本、函数、类或其他类似的事物的功能。我们已经看到ChatGPT在其与代码相关的响应中提供了许多清晰的解释的示例。然而,我们可以通过以代码理解的方式提出具体问题来提升这种能力。
例如,让我们请教ChatGPT解释以下Python脚本的功能:
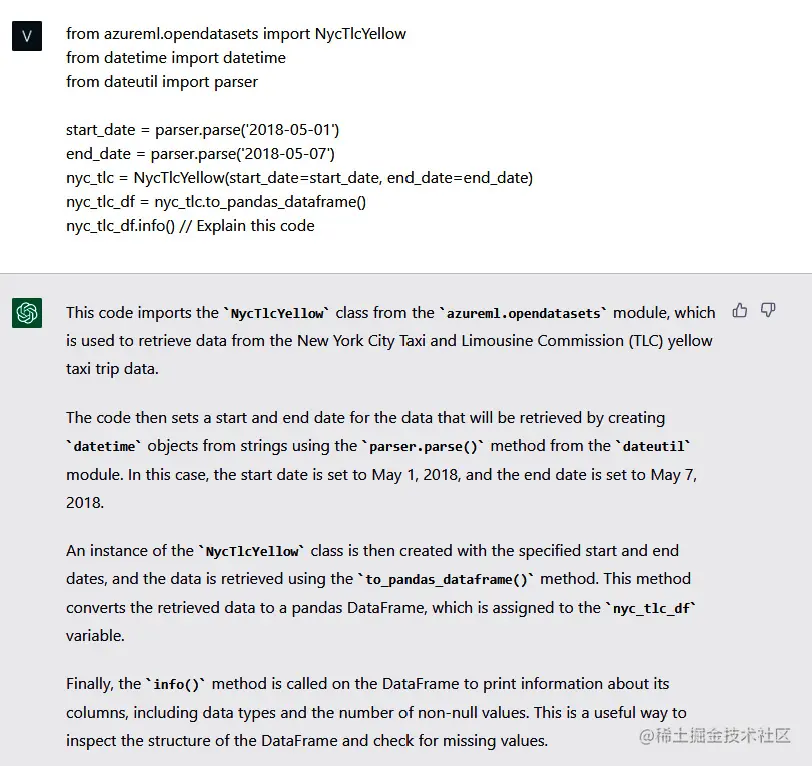
代码可解释性也可以成为前面提到的文档的一部分,或者可以在开发人员之间使用,他们可能希望更好地理解其他团队的复杂代码,或者(正如有时发生在我身上的情况)记住一段时间前编写的内容。
借助ChatGPT和本节中提到的能力,开发人员可以以自然语言轻松跟踪项目的生命周期,使新团队成员和非技术用户更容易理解迄今为止所做的工作。
在下一节中,我们将看到代码可解释性对于数据科学项目中机器学习模型的解释性至关重要。
理解机器学习模型的可解释性
模型的可解释性是指人类能够轻松理解机器学习模型预测背后的逻辑程度。本质上,它是理解模型如何做出决策以及哪些变量对其预测起到了贡献的能力。
让我们通过一个使用深度学习卷积神经网络(CNN)进行图像分类的示例来看一下模型的可解释性。我使用Python和Keras构建了这个模型。为此,我将直接从Keras下载CIFAR-10数据集:它包含60,000个32×32的彩色图像(因此是3通道图像),分为10个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车),每个类别有6,000张图像。这里,我将仅分享模型的主体部分;你可以在本书的GitHub存储库中找到有关数据准备和预处理的所有相关代码,网址为github.com/PacktPublis…
ini复制代码model=tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),activation='relu',input_shape=
(32,32,1)))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1024,activation='relu'))
model.add(tf.keras.layers.Dense(10,activation='softmax'))
前面的代码由几个层组成,每个层执行不同的操作。我可能对模型的结构以及每个层的目的感兴趣。让我们向ChatGPT寻求一些帮助来解释这些内容:
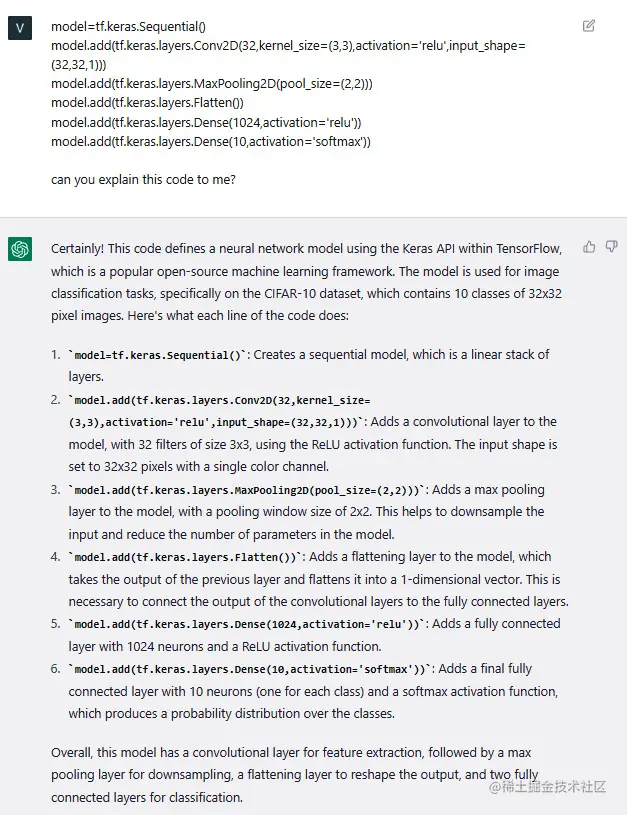
正如您在前面的图中所看到的,ChatGPT能够清楚地解释我们的CNN的结构和层次。它还添加了一些注释和提示,比如使用最大池化层有助于减少输入的维度。
在验证阶段,ChatGPT也可以帮助我解释模型的结果。因此,在将数据分割为训练集和测试集,并在训练集上训练模型之后,我想看一下模型在测试集上的表现:

让我们也请ChatGPT对我们的验证指标进行详细解释:
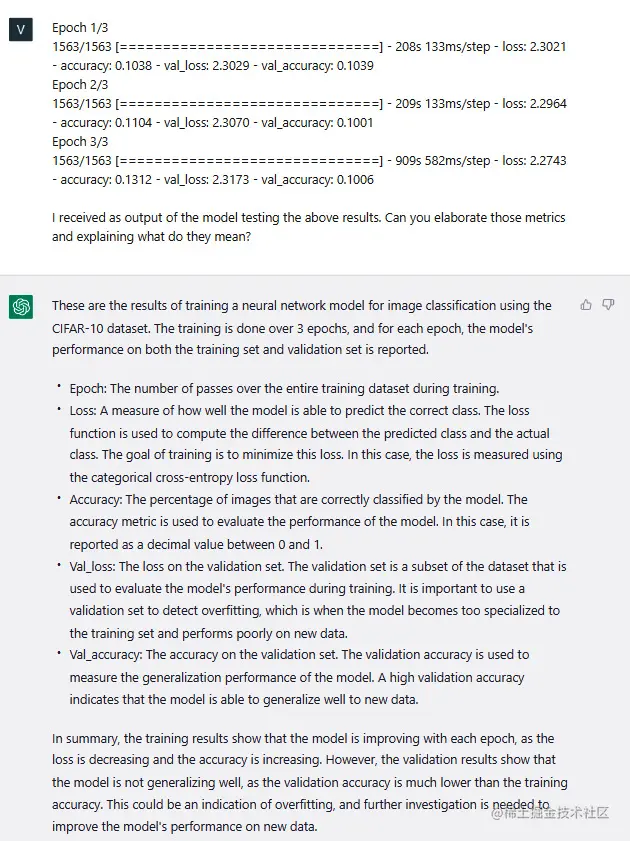
再一次,结果令人印象深刻,它清晰地解释了如何在训练和测试集上设置机器学习实验的重要性。它解释了模型具有足够的泛化性是多么重要,以便它不会过拟合,并能够对其从未见过的数据进行准确的预测结果。
模型可解释性的重要性有很多原因。其中一个关键因素是它减少了业务用户与模型背后的代码之间的差距。这对于使业务用户理解模型的行为以及将其转化为商业想法的代码至关重要。 此外,模型可解释性实现了负责任和道德人工智能的一个关键原则,即透明化AI系统背后的模型的思考和行为方式。解锁模型的可解释性意味着检测模型在生产中可能具有的潜在偏见或有害行为,并防止它们发生。
总体而言,ChatGPT在模型可解释性方面提供了有价值的支持,可以生成在行级别的洞察,就像我们在前面的示例中看到的那样。
接下来,我们将探索的ChatGPT的最后一个能力将进一步提高开发人员的生产力,特别是在同一个项目中使用多种编程语言的情况下。
在不同编程语言之间进行翻译
在第5章中,我们看到ChatGPT具有在不同语言之间进行翻译的强大能力。令人难以置信的是,它不仅可以翻译自然语言,还可以在保持相同输出和样式的同时,在不同编程语言之间进行翻译(即,如果有文档字符串文档,它会保留它)。 在许多场景下,这都可以是一个改变游戏规则的因素。
例如,你可能需要学习一种你从未接触过的新编程语言或统计工具,因为你需要快速完成一个项目。借助ChatGPT的帮助,你可以用你偏好的语言编程,然后要求它将代码翻译成你需要学习的目标语言,在这个翻译过程中你将同时学习目标语言。
假设项目需要用MATLAB(一种由MathWorks开发的专有的数值计算和编程软件)交付,但你一直在用Python编程。该项目的任务是对来自Modified National Institute of Standards and Technology(MNIST)数据集的图像进行分类(原始数据集描述和相关论文可以在此处找到:yann.lecun.com/exdb/mnist/)。该数据集包含许多手写数字,并经常用于教授各种图像处理系统。
为了开始,我编写了以下Python代码来初始化一个用于分类的深度学习模型:
ini复制代码import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# Load the MNIST dataset
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Preprocess the data
x_train = x_train.reshape(-1, 28*28) / 255.0
x_test = x_test.reshape(-1, 28*28) / 255.0
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
# Define the model architecture
model = keras.Sequential([
layers.Dense(256, activation='relu', input_shape=(28*28,)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(x_train, y_train, validation_split=0.2, epochs=10, batch_size=128)
# Evaluate the model
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print('Test accuracy:', test_acc)
现在让我们看看如果将前面的代码作为上下文提供给ChatGPT,并要求它将其翻译成MATLAB,会发生什么:
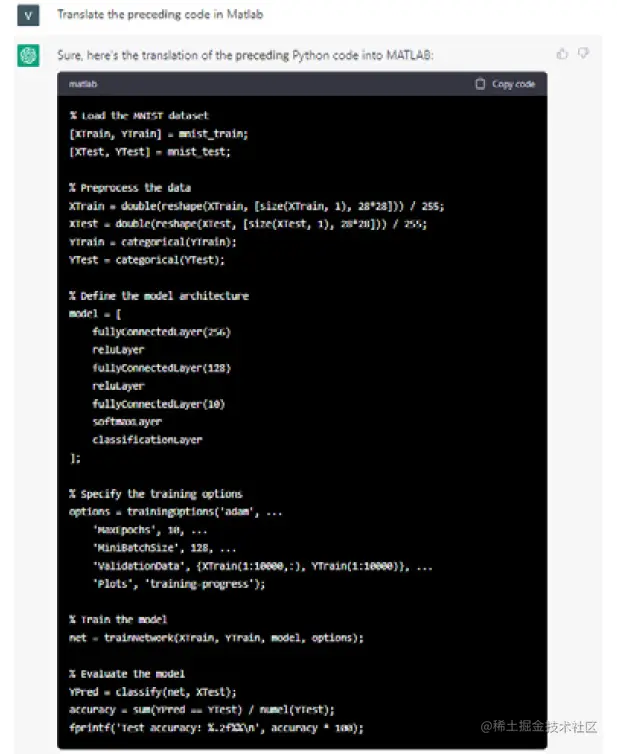
让我们也看看它是否能将其翻译成其他语言,比如JavaScript:
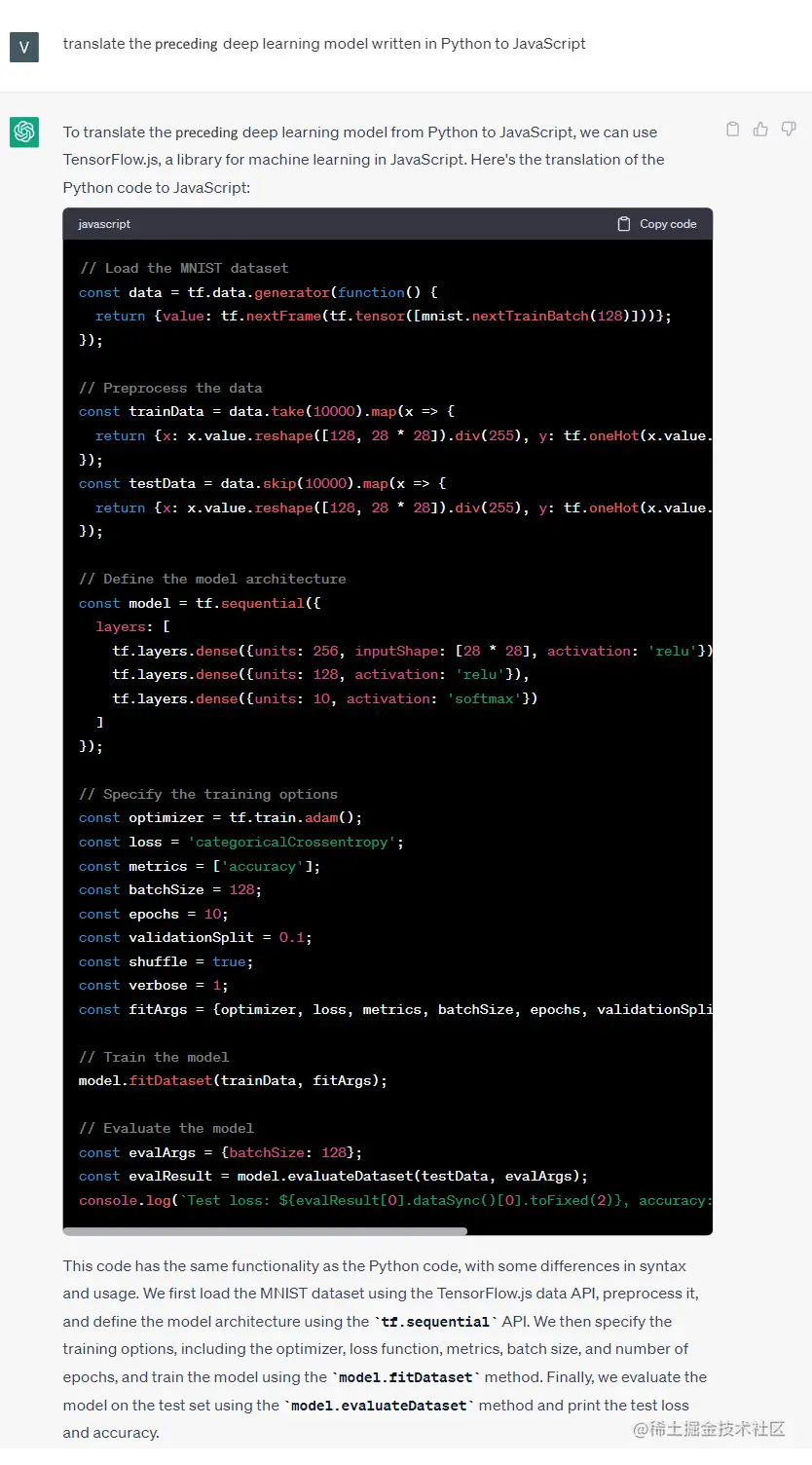
代码翻译还可以减少新技术与当前编程能力之间的差距。
代码翻译的另一个关键影响是应用程序现代化。想象一下,您想要更新应用程序堆栈,即迁移到云平台。您可以选择从简单的“抬起和转移”开始,使用基础设施即服务(IaaS)实例(如Windows或Linux虚拟机(VM))。然而,在第二阶段,您可能希望对应用程序进行重构、重新架构或甚至重新构建。
下图展示了应用程序现代化的各种选项:
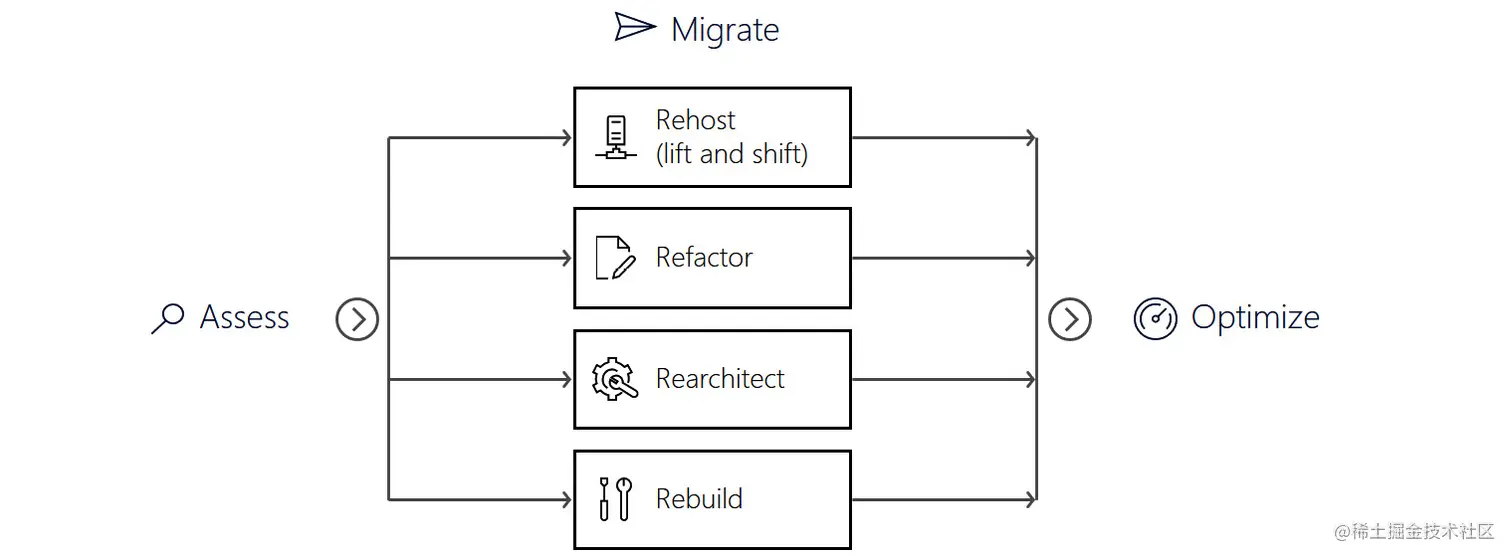
ChatGPT和OpenAI Codex模型可以帮助您进行迁移。以大型计算机为例,大型计算机主要由大型组织使用,执行诸如人口普查、消费者和行业统计、企业资源规划和大规模事务处理等重要任务的大数据处理。大型计算机环境的应用程序编程语言是通用商务定向语言(COBOL)。尽管COBOL于1959年发明,但至今仍在使用,是现存最古老的编程语言之一。
随着技术的不断进步,处于大型计算机领域的应用程序一直在进行持续的迁移和现代化过程,旨在增强现有的遗留大型计算机基础设施在接口、代码、成本、性能和可维护性等方面的能力。 当然,这意味着将COBOL转换为更现代的编程语言,如C#或Java。问题在于,对于大多数新一代程序员来说,他们并不了解COBOL,因此在这个背景下存在巨大的技能缺口。
让我们来看一个读取员工记录文件并编写报告的COBOL脚本,报告显示在公司工作超过10年的员工:
sql复制代码IDENTIFICATION DIVISION.
PROGRAM-ID. EMPLOYEEREPORT.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT EMPLOYEE-FILE ASSIGN TO 'EMPLOYEE.DAT'
ORGANIZATION IS LINE SEQUENTIAL.
SELECT REPORT-FILE ASSIGN TO 'EMPLOYEEREPORT.TXT'
ORGANIZATION IS LINE SEQUENTIAL.
DATA DIVISION.
FILE SECTION.
FD EMPLOYEE-FILE.
01 EMPLOYEE-RECORD.
05 EMPLOYEE-ID PIC X(10).
05 HIRE-DATE PIC 9(6).
05 EMPLOYEE-NAME PIC X(30).
FD REPORT-FILE.
01 REPORT-LINE PIC X(80).
WORKING-STORAGE SECTION.
01 WS-CURRENT-DATE PIC 9(6).
01 WS-EMPLOYEE-YEARS PIC 9(2).
01 WS-REPORT-HEADER.
05 FILLER PIC X(30) VALUE 'EMPLOYEES WITH 10+ YEARS OF SERVICE'.
05 FILLER PIC X(10) VALUE SPACES.
05 WS-REPORT-DATE PIC X(6).
PROCEDURE DIVISION.
MAIN-PARAGRAPH.
OPEN INPUT EMPLOYEE-FILE
OPEN OUTPUT REPORT-FILE
MOVE FUNCTION CURRENT-DATE TO WS-CURRENT-DATE
MOVE WS-CURRENT-DATE(1:6) TO WS-REPORT-DATE
WRITE REPORT-LINE FROM WS-REPORT-HEADER
WRITE REPORT-LINE FROM SPACES
PERFORM READ-EMPLOYEE UNTIL EMPLOYEE-FILE-STATUS = '10'
CLOSE EMPLOYEE-FILE
CLOSE REPORT-FILE
STOP RUN.
READ-EMPLOYEE.
READ EMPLOYEE-FILE
AT END MOVE '10' TO EMPLOYEE-FILE-STATUS
END-READ
COMPUTE WS-EMPLOYEE-YEARS = FUNCTION INTEGER-OF-DATE(WS-CURRENT-DATE) - HIRE-DATE(1:6)
IF WS-EMPLOYEE-YEARS >= 10
WRITE REPORT-LINE FROM EMPLOYEE-RECORD
END-IF.
我将之前的COBOL脚本传递给ChatGPT,以便它可以将其用作上下文来形成回答。现在让我们向ChatGPT询问将该脚本转换为JavaScript的翻译结果:
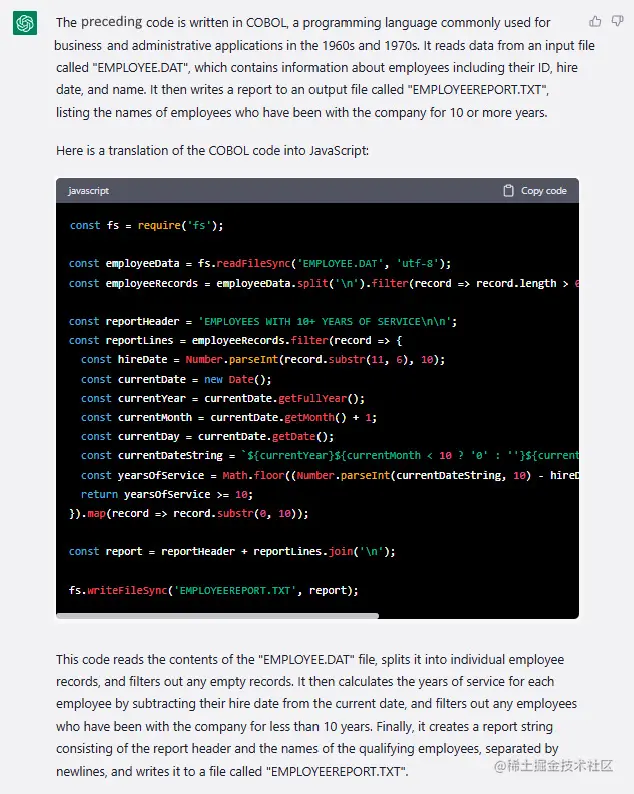
工具如ChatGPT可以帮助减少这种场景和类似场景中的技能差距,引入一个既了解编程的过去又了解未来的层级。
总之,ChatGPT可以成为应用现代化的有效工具,提供代码升级以及有关改进传统系统的宝贵见解和建议。凭借其先进的语言处理能力和广泛的知识库,ChatGPT可以帮助组织简化现代化工作,使过程更快、更高效、更有效。
注意: OpenAI Codex模型是GitHub Copilot背后的引擎。这种新的能力包括本章中我们将看到的许多用例,例如代码生成、自动填充和代码优化。
总结
ChatGPT可以成为开发人员提升技能和简化工作流程的宝贵资源。我们开始时看到了ChatGPT如何生成、优化和调试代码,但我们还介绍了其他功能,如在代码旁边生成文档、解释机器学习模型以及在应用现代化过程中进行不同编程语言之间的翻译。
无论您是经验丰富的开发人员还是刚刚入门,ChatGPT都为学习和成长提供了强大的工具,缩小了代码和自然语言之间的差距。
在下一章中,我们将深入探讨ChatGPT可能成为游戏规则改变者的另一个应用领域:市场营销。
