

本章提供了OpenAI及其最显著的发展——ChatGPT的概述,重点介绍了它的历史、技术和能力。
总体目标是提供对ChatGPT如何在各个行业和应用中使用以改善沟通和自动化流程的深入了解,最终展示这些应用如何影响技术领域以及其他领域。
我们将通过以下主题来介绍这些内容:
- 什么是OpenAI?
- OpenAI模型家族概述
- 通往ChatGPT的道路:其背后的模型数学原理
- ChatGPT:最先进的技术现状
技术要求
为了能够测试本章中的示例,您需要以下内容:
- OpenAI账户,用于访问Playground和Models API(openai.com/api/login20…
- 您喜欢的集成开发环境(IDE),如Jupyter或Visual Studio
- 已安装Python 3.7.1+(www.python.org/downloads)
- 已安装pip(pip.pypa.io/en/stable/i…
- 已安装OpenAI Python库(pypi.org/project/ope…
什么是OpenAI?
OpenAI是由Elon Musk、Sam Altman、Greg Brockman、Ilya Sutskever、Wojciech Zaremba和John Schulman于2015年创立的研究组织。正如OpenAI网页上所述,其使命是“确保人工通用智能(AGI)造福于全人类”。由于它是通用的,AGI旨在具备学习和执行各种任务的能力,而无需进行特定任务的编程。
自2015年以来,OpenAI一直专注于深度强化学习(DRL),这是机器学习(ML)的一个子领域,将强化学习(RL)与深度神经网络相结合。该领域的首个贡献可以追溯到2016年,当时该公司发布了OpenAI Gym,这是一个供研究人员开发和测试RL算法的工具包。

OpenAI在该领域继续进行研究和贡献,但其最显著的成就与生成模型——生成式预训练变换器(GPT)相关。 在他们的论文《通过生成式预训练改进语言理解》中介绍了该模型架构,并将其命名为GPT-1之后,OpenAI的研究人员很快在2019年发布了其继任者,即GPT-2。这个版本的GPT是在一个名为WebText的语料库上进行训练的,该语料库当时包含了超过800万个文档,总共40 GB的文本,这些文本来自于Reddit提交的URL,至少有3个赞。GPT-2拥有12亿个参数,是其前身的十倍。
在这里,您可以看到HuggingFace发布的GPT-2的用户界面的登录页(transformer.huggingface.co/doc/distil-…:
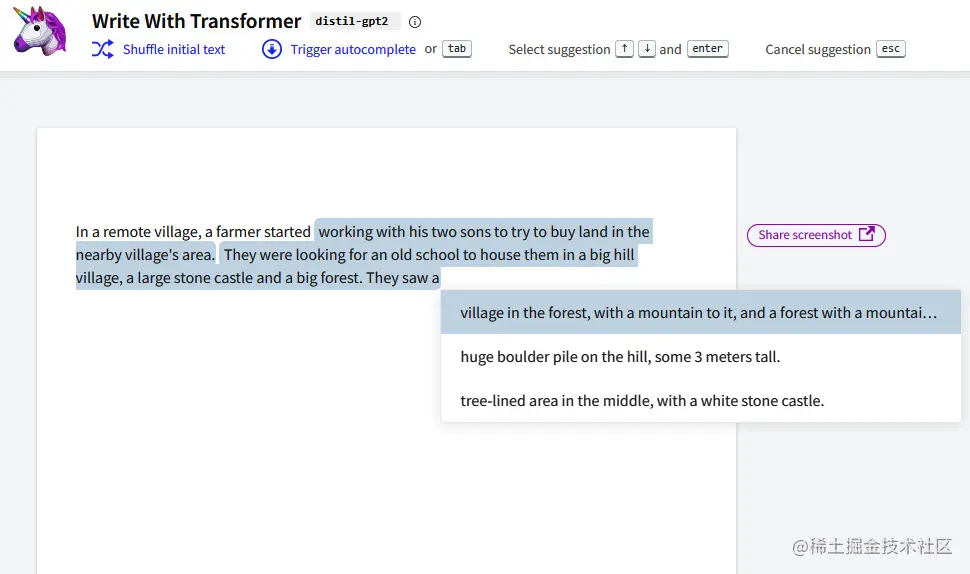
然后,在2020年,OpenAI首先宣布然后发布了GPT-3,该模型拥有1750亿个参数,在基准测试结果上显著优于GPT-2。
除了自然语言生成模型外,OpenAI还在图像生成领域进行了开发,并在2021年发布了该领域的第一个模型,名为DALL-E。正如前一章提到的,DALL-E能够根据自然语言输入创建全新的图像,这些输入由最新版本的GPT-3进行解释。
DALL-E最近升级到了新版本DALL-E 2,并于2022年4月宣布发布。
在下图中,您可以看到DALL-E生成的以自然语言提示“生成一个舒适环境中的一杯咖啡的逼真图片”的示例图像:
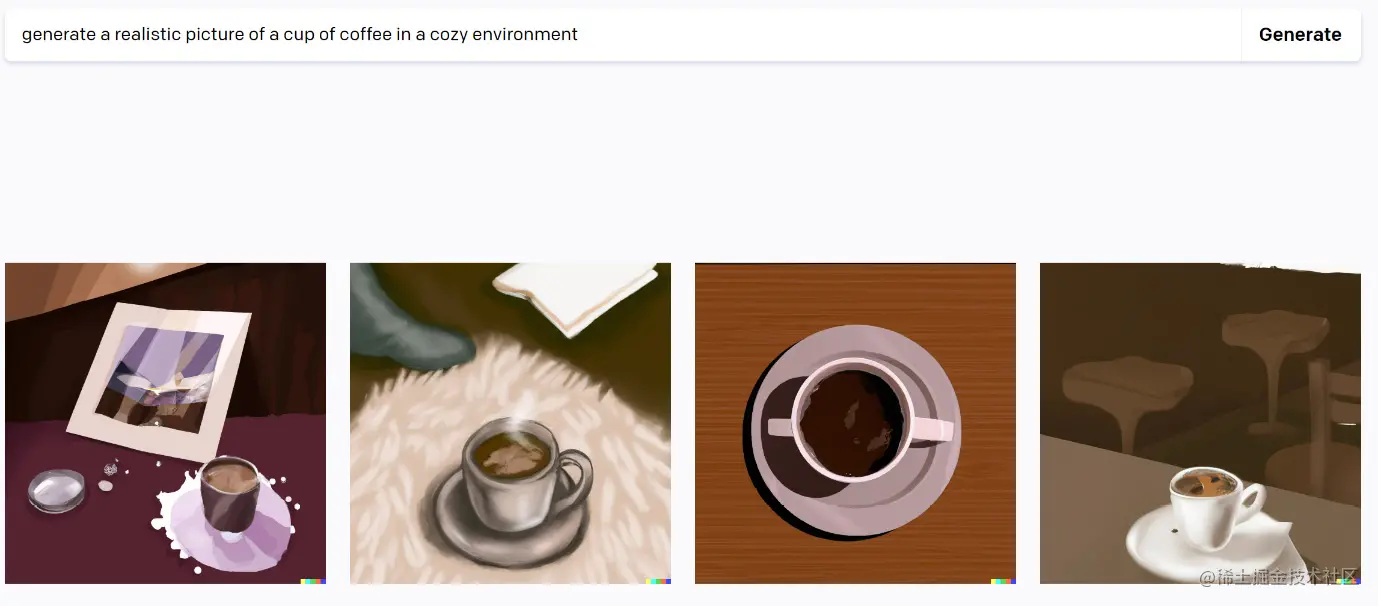
您可以在OpenAI DALL-E的实验室(labs.openai.com/)中尝试生成创意图片,您将获得有限的免费积分进行实验。
尽管OpenAI在生成式人工智能的许多领域进行了投资,但其在文本理解和生成方面的贡献卓越,这要归功于我们将在下面的段落中探讨的基础GPT模型的发展。
OpenAI模型家族概览
如今,OpenAI提供了一套预训练的、可供普通用户使用的模型。这有两个重要的意义:
- 强大的基础模型可以直接使用,而不需要进行长时间而昂贵的训练。
- 不需要成为数据科学家或机器学习工程师也可以操作这些模型。
用户可以在OpenAI Playground中测试OpenAI模型,这是一个友好的用户界面,您可以在其中与模型进行交互,而无需编写任何代码。
以下是OpenAI Playground的首页截图:
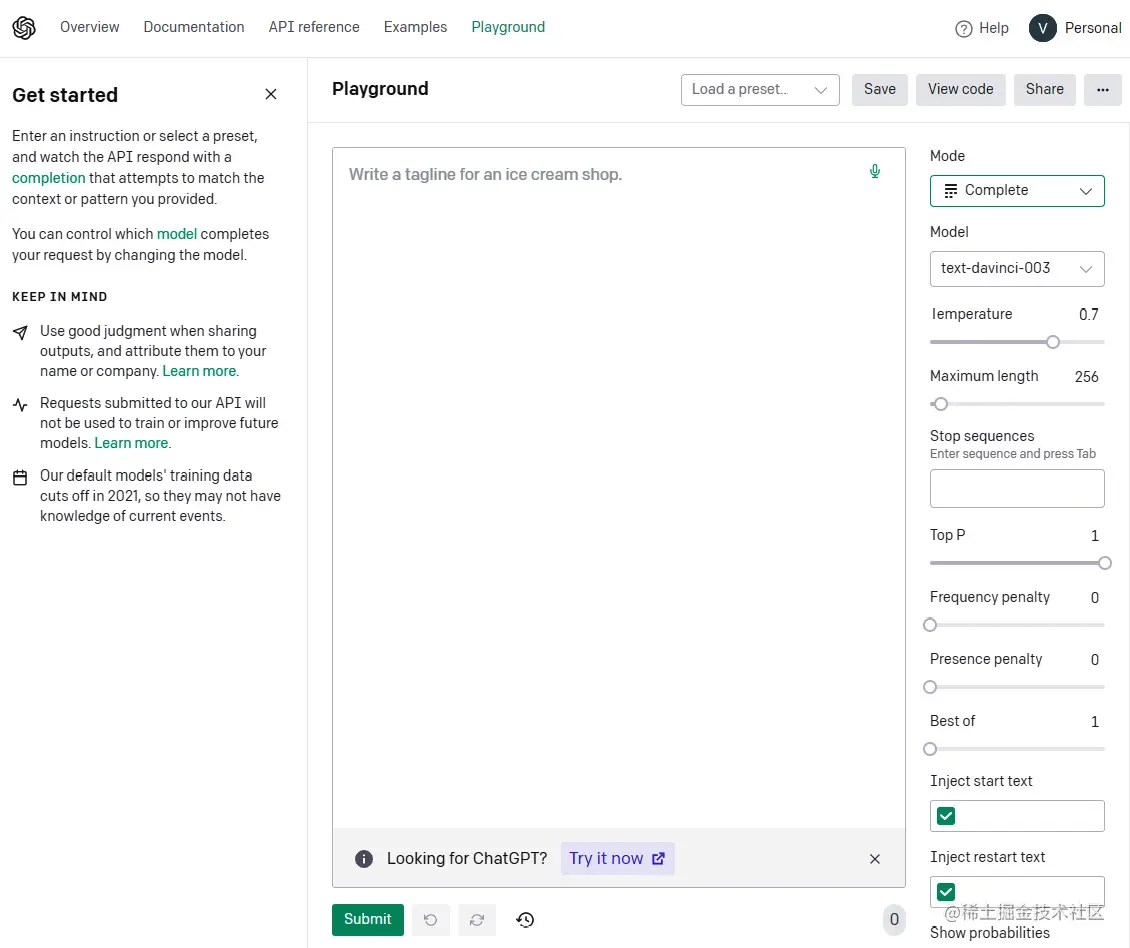
正如图2.4所示,Playground提供了一个用户界面,用户可以在界面的右侧选择要与之交互的模型。要开始与Playground进行交互,只需在输入空间中以自然语言输入任何问题或指令即可。您还可以从OpenAI文档中的一些示例开始(platform.openai.com/examples)。
在深入研究模型系列之前,让我们首先定义一些在本章中会看到的术语:
令牌(Tokens):令牌可以被视为API用于处理输入提示的单词片段或段落。与完整的单词不同,令牌可能包含尾随的空格甚至部分子词。为了更好地理解令牌的长度概念,有一些一般准则需要记住。例如,一个英文令牌大约相当于四个字符或四分之三个单词。
提示(Prompt):在自然语言处理(NLP)和机器学习(ML)的背景下,提示是指作为输入提供给AI语言模型以生成响应或输出的文本片段。提示可以是一个问题、一个陈述或一个句子,它用于为语言模型提供上下文和方向。
上下文(Context):在GPT领域,上下文指的是出现在用户提示之前的单词和句子。语言模型使用这个上下文来根据训练数据中找到的模式和关系生成最有可能的下一个单词或短语。
模型置信度(Model confidence):模型置信度是指AI模型对特定预测或输出分配的确定性或概率水平。在NLP的背景下,模型置信度通常用于指示AI模型对其生成的响应与给定输入提示的正确性或相关性有多有信心。
上述定义对于理解如何使用Azure OpenAI模型系列以及如何配置它们的参数将起到关键作用。
在Playground中,有两个主要的模型系列可以进行测试:
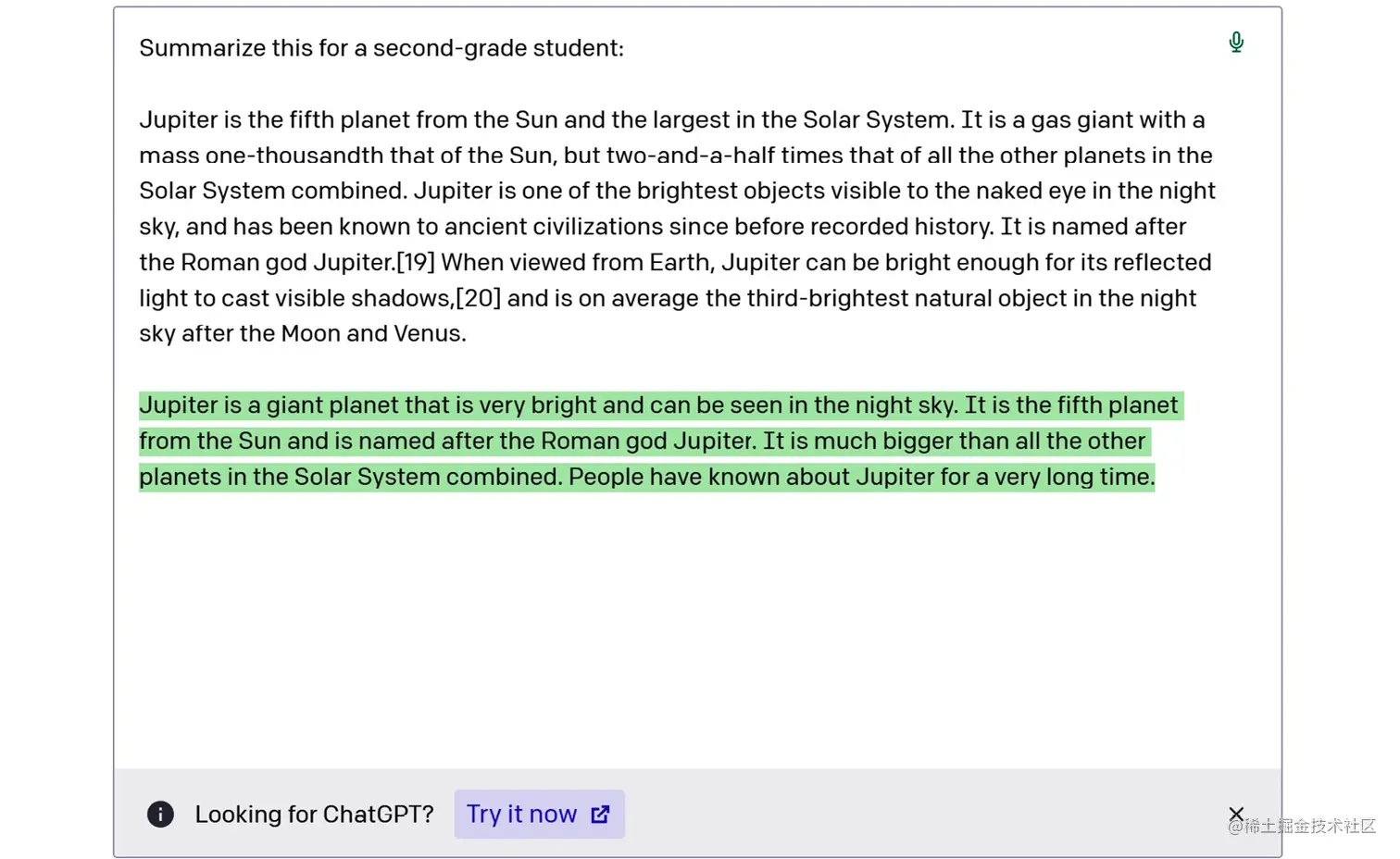
- GPT-3:一组能够理解和生成自然语言的模型。GPT-3在大量文本语料库上进行了训练,可以执行各种自然语言任务,如语言翻译、摘要生成、问答等。以下是一个例子:
- GPT-3.5:这是一组基于GPT-3的新模型,旨在提高其自然语言理解和生成能力。GPT-3.5模型可以执行复杂的自然语言任务,如组成连贯的段落或文章、生成诗歌,甚至用自然语言创建计算机程序。GPT-3.5是ChatGPT背后的模型,在其API上运行,并且在Playground中也可以通过专用的用户界面进行使用:

- Codex:这是一组可以理解和生成多种编程语言代码的模型。Codex可以将自然语言提示转化为可运行的代码,使其成为软件开发的强大工具。下面是一个使用Codex的示例:

注意:
在2023年3月,OpenAI宣布从该日期起将废弃Codex模型。这是因为新的聊天模型(包括ChatGPT背后的GPT-3.5-turbo)具有惊人的能力,涵盖了编码任务,并且其结果在基准测试中甚至超过了Codex模型的结果。 对于每个模型,您还可以调整一些可配置的参数。以下是一些参数列表:
- 温度(从0到1):控制模型回复的随机性。较低的温度使得模型更具确定性,这意味着它倾向于对相同的问题给出相同的输出。例如,如果我多次问我的模型“OpenAI是什么?”,温度设置为0,它将始终给出相同的答案。另一方面,如果我使用温度设置为1的模型进行相同的操作,它将尝试在措辞和风格方面每次都进行修改。
- 最大长度(从0到2048):控制模型对用户提示的响应的长度(以标记为单位)。
- 停止序列(用户输入):使响应在所需位置结束,例如句子或列表的末尾。
- 前概率(从0到1):在生成响应时,控制模型将考虑哪些标记。将其设置为0.9将考虑前90%最可能的所有可能标记。有人可能会问:“为什么不将前概率设置为1,以选择所有最可能的标记?”答案是,即使在得分最高的标记中,用户可能仍希望保持多样性,当模型信心较低时。
- 频率惩罚(从0到1):控制生成的响应中相同标记的重复次数。惩罚越高,相同标记在相同响应中重复的概率越低。该惩罚基于到目前为止文本中标记出现的频率,与下一个参数的关键区别在于此。
- 存在惩罚(从0到2):与前一个参数类似,但更严格。它减少了到目前为止文本中出现的任何标记重复的机会。由于存在惩罚比频率惩罚更严格,它还增加了在响应中引入新主题的可能性。
- 最佳(从0到20):生成多个响应并仅显示所有标记的总概率最佳的响应。
- 响应前文本和响应后文本(用户输入):在模型的响应之前和之后插入文本。这有助于为模型准备响应。
除了在Playground中尝试OpenAI模型,您还可以在自定义代码中调用模型API并将模型嵌入到您的应用程序中。实际上,在Playground的右上角,您可以点击“查看代码”并导出配置,如下图所示:
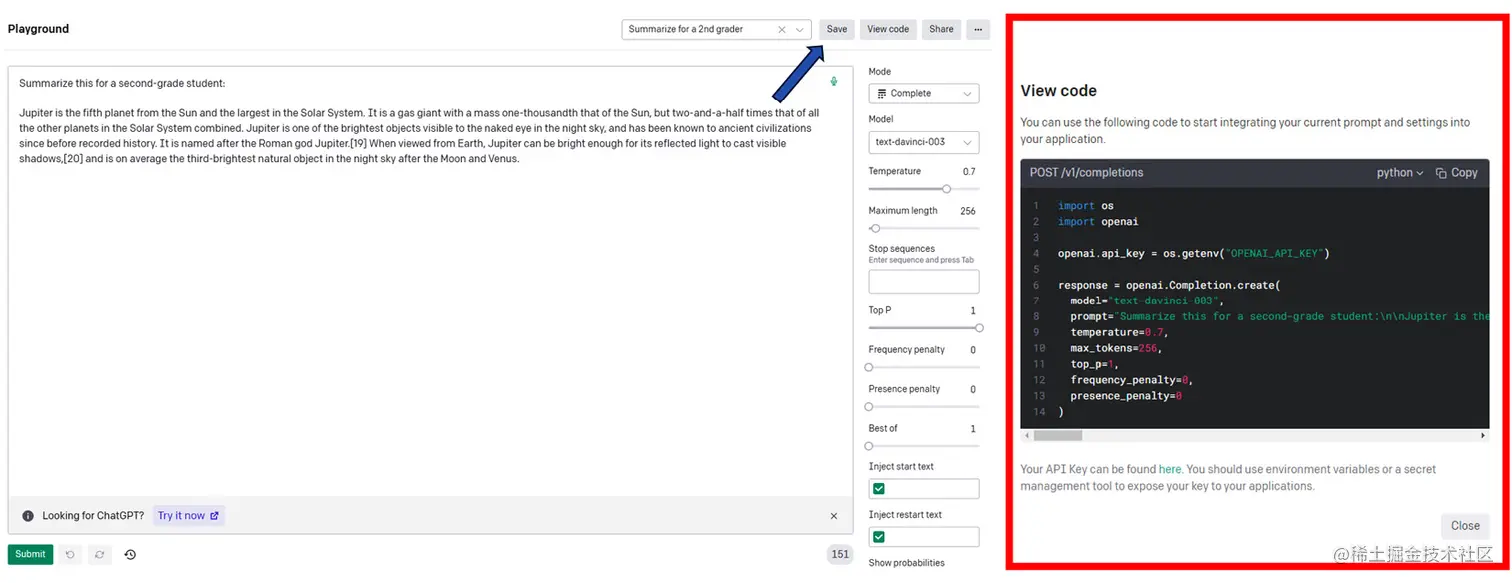
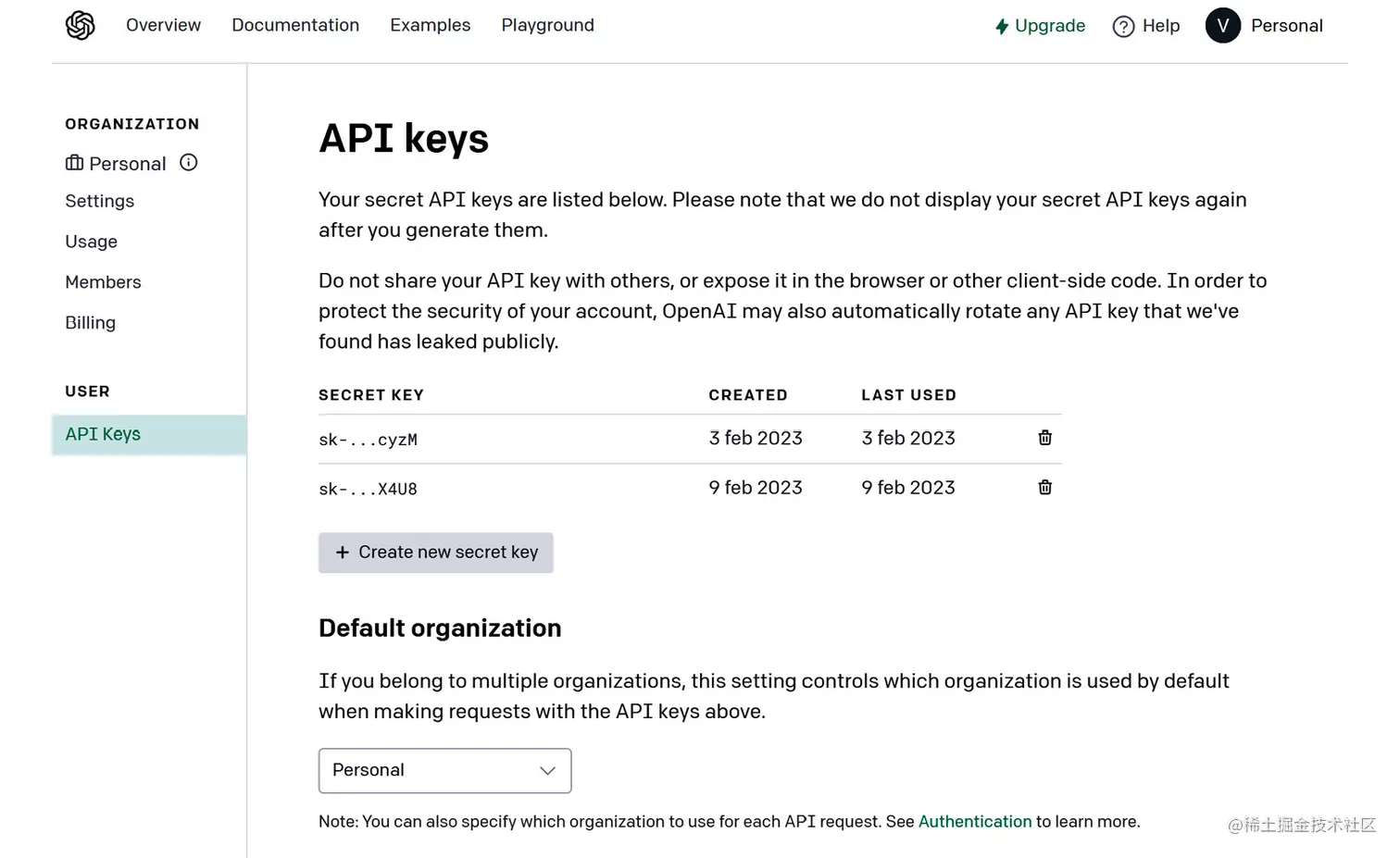
正如您从上述屏幕截图中可以看到的那样,代码导出了您在Playground中设置的参数配置。 现在,您可以通过在终端中使用pip install openai命令安装OpenAI库,然后在Python中开始使用它。为了使用模型,您需要生成一个API密钥。您可以在帐户设置中找到您的API密钥(platform.openai.com/account/api…),如下图所示:
使用OpenAI API,您还可以尝试以下在Playground中不可用的其他模型系列:
- Moderation(内容审查):这是OpenAI开发的一个经过精调的模型,可以检测潜在的敏感或不安全的文本内容。Moderation利用机器学习算法根据文本的上下文和语言使用来对文本进行安全或不安全的分类。该模型可用于自动化社交媒体平台、在线社区等领域的内容审查。有多个类别,如仇恨、威胁、自残、性行为、未成年人的性行为、暴力、暴力/图形等。 下面是使用Moderation API的示例代码:
lua复制代码import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Moderation.create(
input="I want to kill him",
)
输出结果如下:
bash复制代码<OpenAIObject id=modr-6sHusuY9frxJdfqTBXHsOAfWhckrh at 0x218bd8482c0> JSON: {
"id": "modr-6sHusuY9frxJdfqTBXHsOAfWhckrh",
"model": "text-moderation-004",
"results": [
{
"categories": {
"hate": false,
"hate/threatening": false,
"self-harm": false,
"sexual": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": false
},
"category_scores": {
"hate": 1.7164344171760604e-05,
"hate/threatening": 2.614225103059198e-08,
"self-harm": 2.5988580176772302e-08,
"sexual": 2.8184256279928377e-06,
"sexual/minors": 9.1383149936064e-09,
"violence": 0.9910049438476562,
"violence/graphic": 5.316753117767803e-07
},
"flagged": true
}
]
}
在这种情况下,Moderator API 检测到了暴力内容的证据。
- 嵌入(Embeddings):某些模型可以使用嵌入。这些嵌入将单词或句子表示为多维空间中的向量。在这个空间中,不同实例之间的数学距离表示它们在意义上的相似性。例如,想象一下单词 queen(女王)、woman(女人)、king(国王)和man(男人)。在我们的多维空间中,如果表示正确,我们希望实现以下目标:
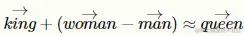
这意味着女人和男人之间的距离应该等于女王和国王之间的距离。以下是一个嵌入的示例:
ini复制代码import openai
embedding = openai.Embedding.create(
input="The cat is on the table",
model="text-embedding-ada-002")["data"][0][ "embedding"]
上述方法创建了输入的向量表示。我们可以在这里查看输出的前10个向量:
css复制代码embedding[1:10]
[-0.01369840931147337, -0.007505378685891628, -0.002576263388618827, -0.014773285016417503, 0.019935185089707375, -0.01802290789783001, -0.01594814844429493, -0.0010944041423499584, -0.014323337003588676]
在智能搜索场景中,嵌入可以非常有用。事实上,通过获取用户输入和用户想要搜索的文档的嵌入,可以计算它们之间的距离度量(即余弦相似度)。通过这样做,我们可以检索与用户输入在数学距离上更接近的文档。
- Whisper:是一个语音识别模型,可以将音频转录为文本。Whisper能够高准确度地识别和转录各种语言和方言,使其成为自动语音识别系统的宝贵工具。以下是一个示例:
ini复制代码# Note: you need to be using OpenAI Python v 0.27.0 for the code below to work
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
audio_file= open("/path/to/file/audio.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
输出结果如下所示:
less复制代码{"text": Yes, hi, I just noticed a dent on the side of my car and I have no idea how it got there. There were no witnesses around and I'm really frustrated.
….
}
所有之前提到的模型都是预先构建的,也就是说它们已经在一个庞大的知识库上进行了预训练。
然而,你可以通过一些方式来使你的模型更加定制化,以适应你的使用场景。
第一种方法是嵌入在模型设计中的,它涉及到在少样本学习方法中提供上下文信息(我们将在本书的后面部分重点讨论这种技术)。也就是说,你可以要求模型生成一篇文章,其中模板和词汇表与你已经写过的另一篇文章相似。为此,你可以向模型提供一个生成文章的查询和之前的文章作为参考或上下文,以便模型更好地为你的请求做准备。
下面是一个示例:
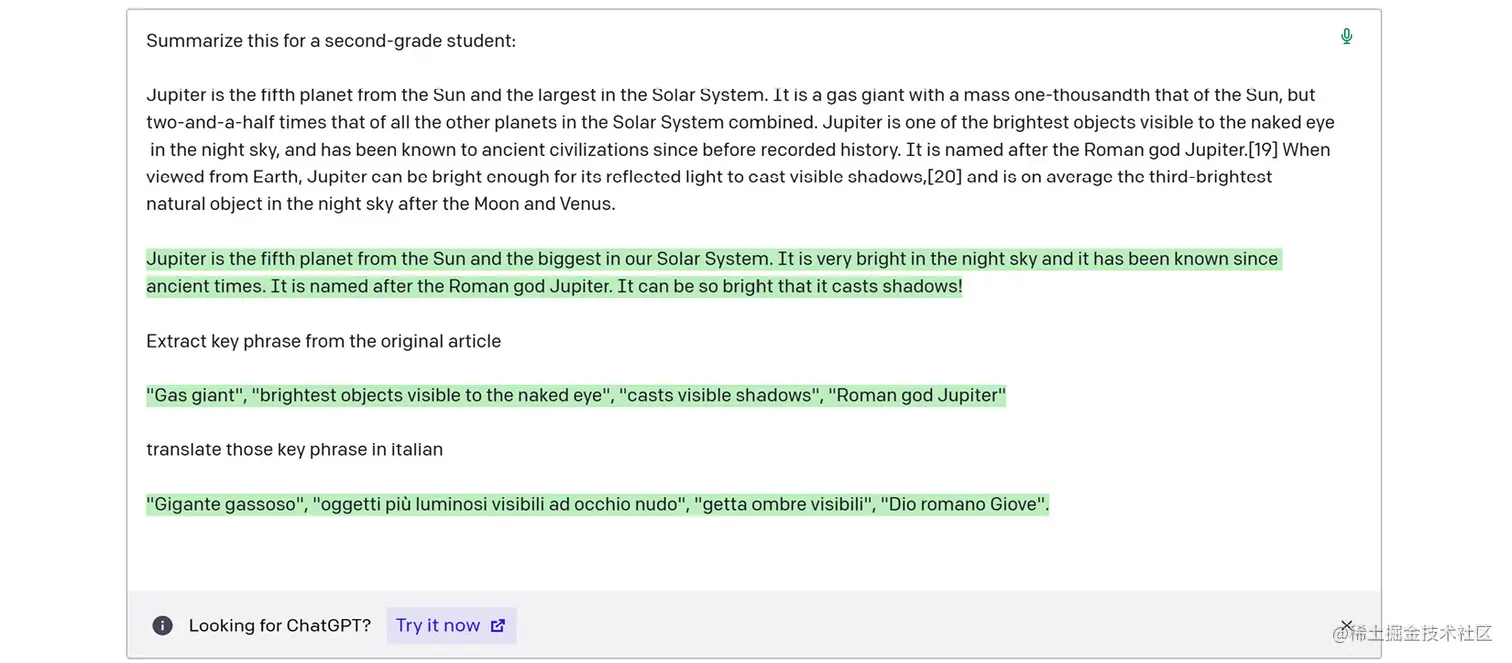
第二种方法更为复杂,称为微调(fine-tuning)。微调是将预训练模型适应于新任务的过程。
在微调中,通过调整现有参数或添加新参数来改变预训练模型的参数,以更好地适应新任务的数据。这是通过在一个针对新任务的较小的有标签数据集上训练模型来实现的。微调的关键思想是利用从预训练模型中学到的知识,并将其微调到新任务上,而不是从头开始训练一个模型。请看下图:
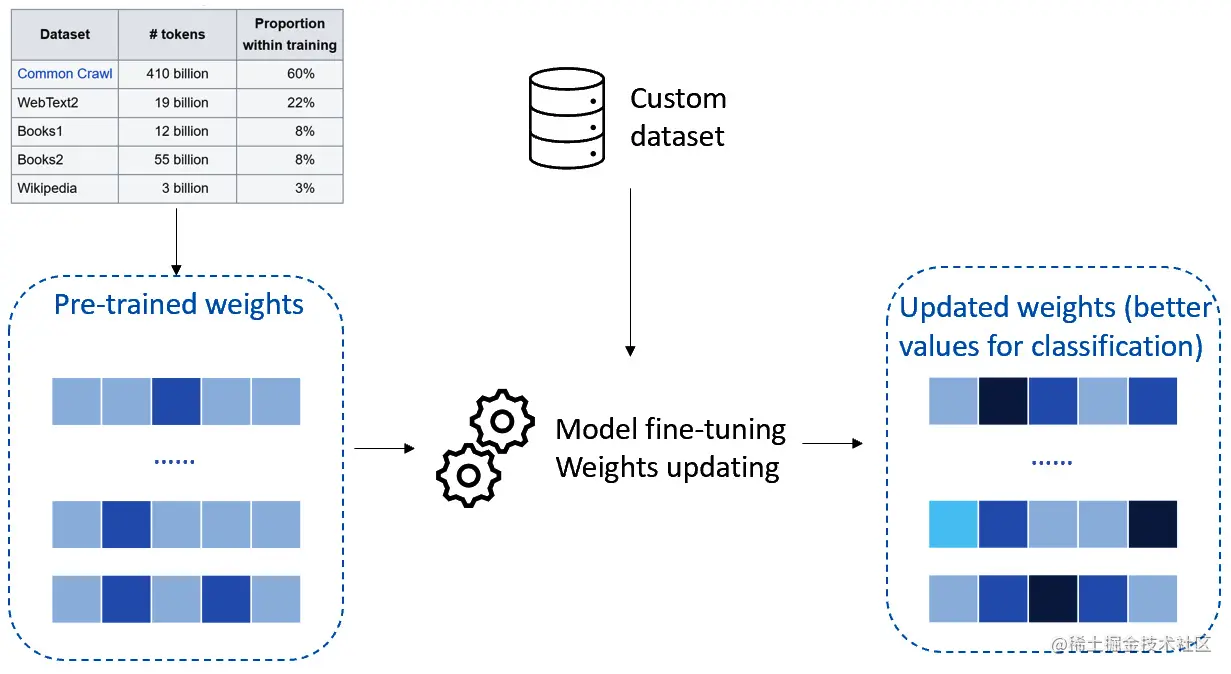
在上图中,您可以看到微调在OpenAI预建模型上的工作原理的示意图。思路是您可以使用具有通用权重或参数的预训练模型。然后,您可以使用自定义数据来训练模型,通常以键值提示和补全的形式,如下所示:
erlang复制代码{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
一旦训练完成,您将获得一个定制化的模型,该模型在特定任务上表现出色,例如对您公司的文档进行分类。 微调的好处在于,您可以将预建模型针对您的用例进行定制,无需从头开始重新训练它们,同时利用较小的训练数据集,从而减少训练时间和计算成本。同时,该模型保留了通过原始训练(在大规模数据集上进行的训练)学到的生成能力和准确性。
在本段中,我们对OpenAI向公众提供的模型进行了概述,从您可以直接在Playground中尝试的模型(GPT、Codex)到更复杂的模型(例如嵌入)。我们还了解到,除了使用预建模型,您还可以通过微调来自定义它们,提供一组示例供其学习。
在接下来的章节中,我们将重点介绍这些惊人模型的背景,从它们背后的数学开始,然后深入了解使得ChatGPT成为可能的伟大发现。
ChatGPT的发展之路:背后模型的数学基础
自从2015年成立以来,OpenAI一直在研究和开发一类被称为生成预训练Transformer(GPT)的模型,并且它们作为ChatGPT背后的引擎引起了广泛关注。
GPT模型属于Transformer架构框架,该架构在谷歌研究员于2017年发表的论文《Attention Is All You Need》中首次引入。
Transformer架构的引入是为了克服传统循环神经网络(RNNs)的局限性。RNNs最早是在1980年代由洛斯阿拉莫斯国家实验室的研究人员提出的,但直到1990年代才引起了广泛关注。RNNs的最初想法是处理序列数据或时间序列数据,跨时间步骤保留信息。
事实上,在那个时候,经典的人工神经网络(ANN)架构是前馈ANN的架构,每个隐藏层的输出是下一层的输入,不保留关于过去层的信息。
为了理解Transformer背后的思想,我们需要从其起源开始。因此,我们将深入探讨以下主题:
- RNN的结构
- RNN的主要限制
- 如何通过引入新的架构元素(包括位置编码、自注意力和前馈层)克服这些限制
- 我们如何达到GPT和ChatGPT的最新技术水平
让我们从Transformer的前身架构开始。
循环神经网络(RNNs)的结构
让我们设想我们想要预测房屋价格。如果我们只有今天的价格,我们可以使用前馈网络结构,通过隐藏层(带有激活函数)对输入进行非线性转换,然后输出明天的价格预测。以下是具体的步骤:

然而,对于这种类型的数据,我们很可能还有更长的序列可用。例如,我们可能有该房屋未来5年的时间序列数据。当然,我们希望将这些额外的信息嵌入到我们的模型中,以便我们的循环神经网络(RNN)能够保持对过去输入的记忆,以便正确解释当前输入并预测未来的输出。
所以,回到我们的例子,想象一下我们不仅有今天的价格,还有昨天(t-1)和前天(t-2)的价格。这是如何计算的:
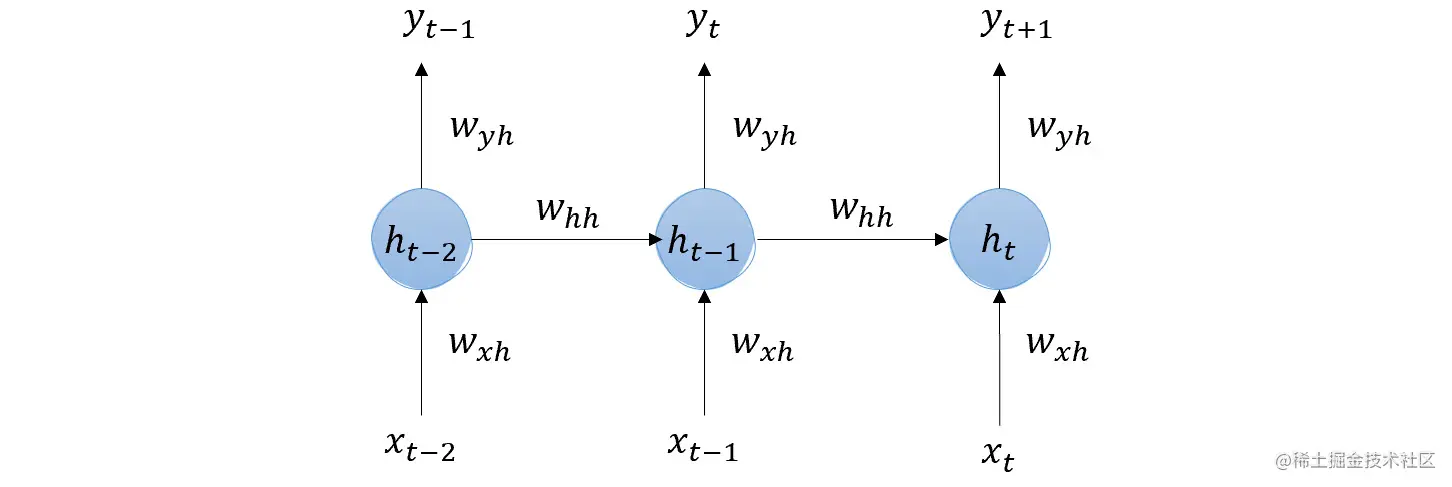
由于我们只关注明天的价格,让我们忽略 t-1 和 t 的中间最终输出。
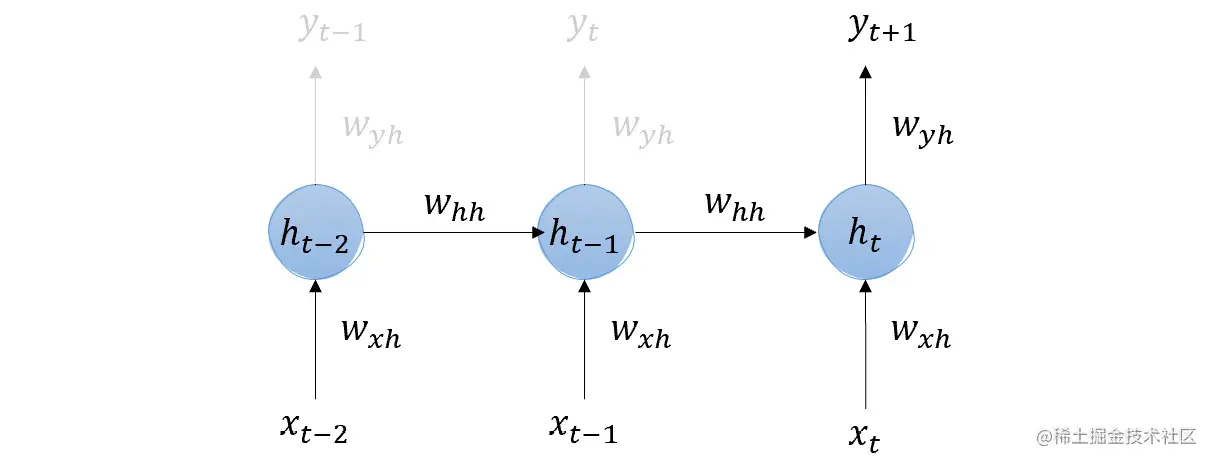
正如你所看到的,t-2 的隐藏层输出作为 t-1 的(加权)输入,同时 t-1 的隐藏层也接收 t-1 的输入。然后,t-1 的隐藏层输出,已经保存了 t-2 和 t-1 的输入记忆,作为 t 的隐藏层的输入。因此,明天的价格(yt+1),也就是我们感兴趣的那个,包含了所有先前天数输入的记忆。
最后,如果我们想要简化这个图示,我们可以将 RNN 理解为如下形式:
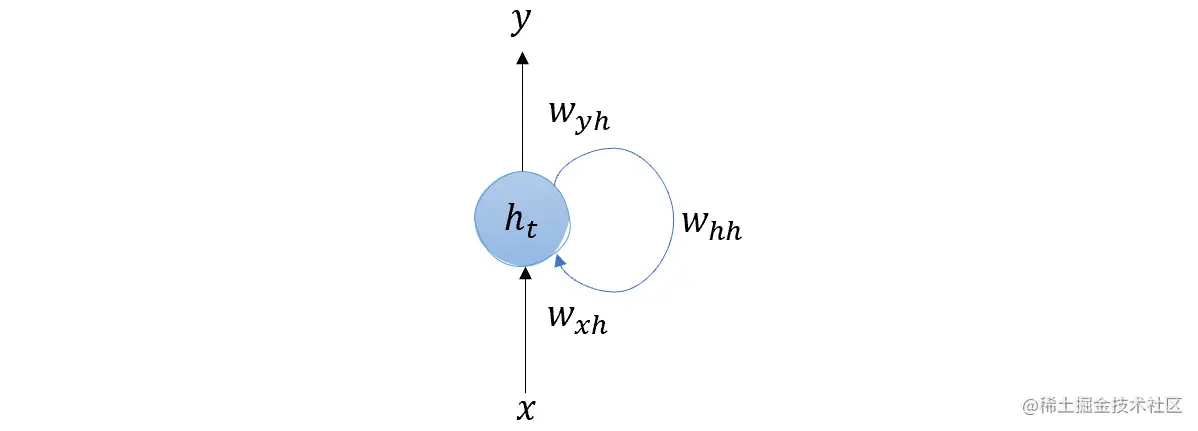
这意味着 RNN 在时间步 t-n 的输出会被生成并传递给下一个时间步的输入。RNN 层的隐藏状态也会传递给下一个时间步的输入,使得网络能够在输入序列的不同部分之间维持和传播信息。
尽管 RNN 在人工神经网络领域是一个重大的发展,但它们仍然存在一些限制,我们将在下一节中对其进行讨论。
RNN一些主要的限制
如前所述,RNN存在三个主要限制:
- 梯度消失和梯度爆炸:RNN面临梯度消失和梯度爆炸的问题,这使得有效训练网络变得困难。这个问题的原因是在反向传播过程中,梯度会多次相乘,从而导致梯度变得非常小或非常大。
- 有限的上下文:传统的RNN只能捕捉有限的上下文,因为它们逐个元素地处理输入序列。这意味着它们无法有效处理长期依赖关系或输入序列中相距较远的元素之间的关系。
- 难以并行化:RNN本质上是顺序执行的,这使得它们的计算难以并行化,因此它们无法充分利用当今的图形处理单元(GPU)。这使得它们在大规模数据集和设备上训练和部署变得缓慢。
为了克服前两个限制(有限的上下文和梯度消失和梯度爆炸),1997年Sepp Hochreiter和Jürgen Schmidhuber在他们的论文《长短期记忆》中提出了一种新的架构。具有这种新架构的网络被称为长短期记忆(LSTM)。
LSTM网络通过引入细胞状态的概念来解决有限上下文的问题。细胞状态与隐藏状态分开,并且能够更长时间地保持信息。细胞状态在网络中传递而不改变,使其能够存储来自前一个时间步的信息,否则这些信息将会丢失。
此外,LSTM网络通过使用精心设计的门控制信息的流动,从而解决了梯度消失和梯度爆炸的问题。这有助于防止梯度变得过小或过大。
然而,LSTM网络仍然存在并行化不足和训练时间缓慢的问题(甚至比RNN更慢,因为它们更复杂)。目标是拥有一个能够在顺序数据上实现并行化的模型。
为了克服这些限制,引入了一种新的框架。
克服限制 – 引入Transformer
Transformer架构通过替代循环(使用自注意力机制)来解决这些限制,从而实现并行计算和捕捉长期依赖关系。
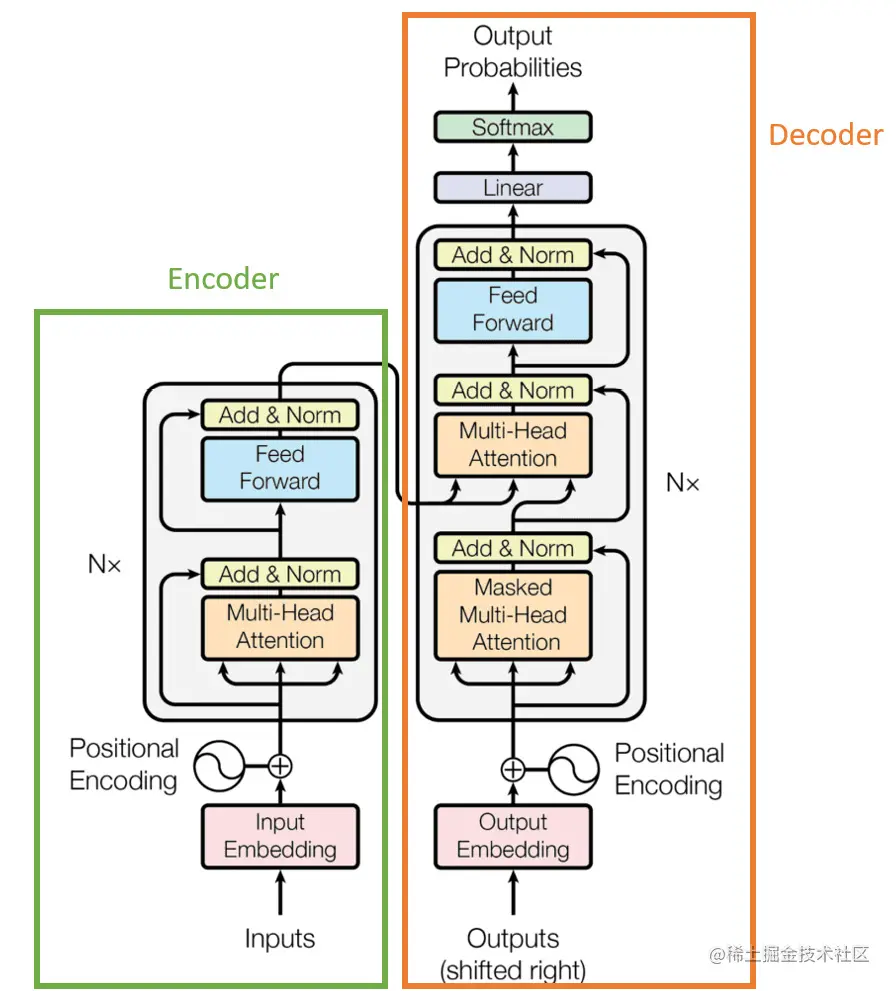
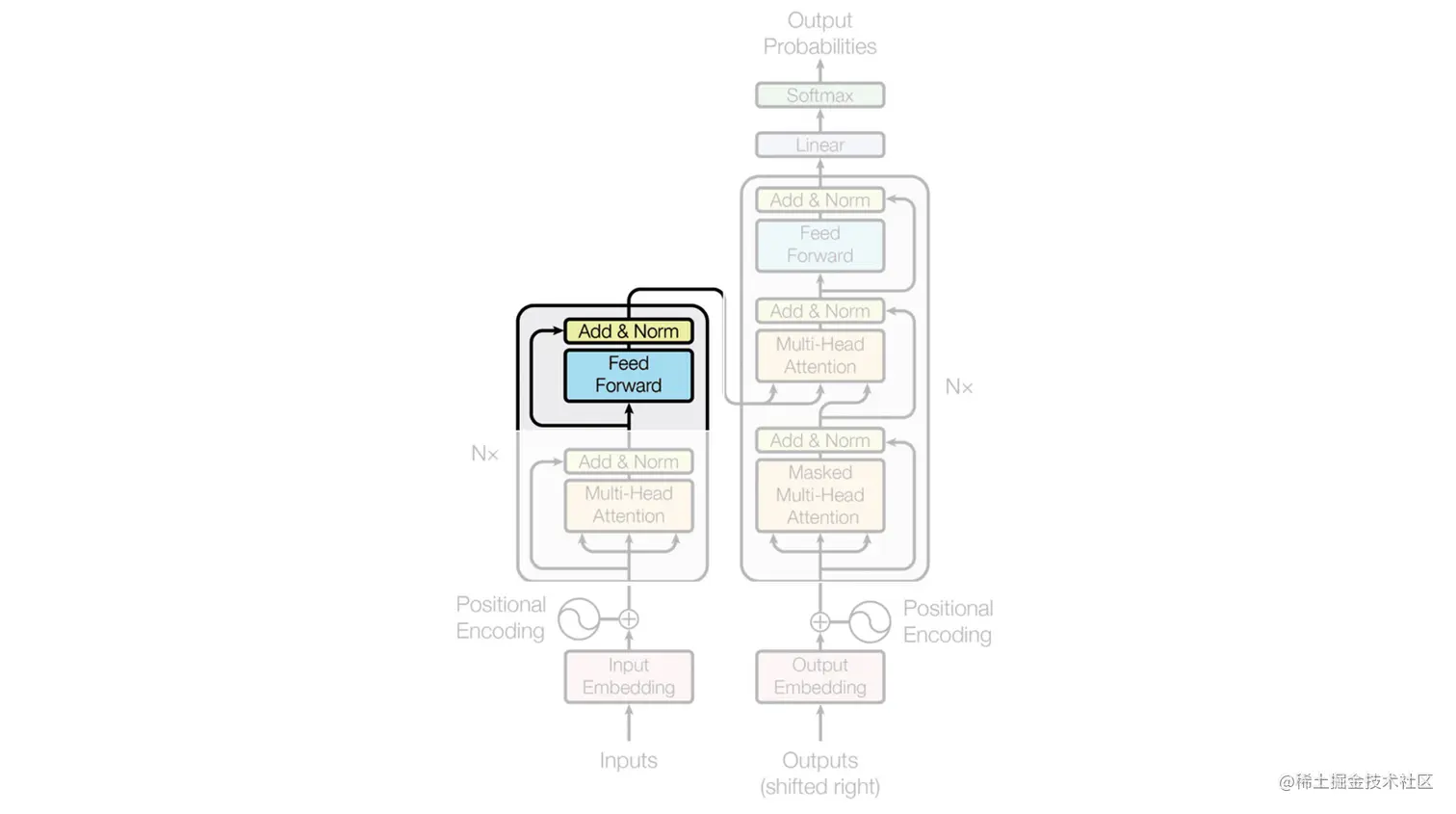
在上图(摘自原始论文)中,您可以看到有两个主要的构建模块:在左侧,我们有“编码器”,其任务是将输入表示为低维空间;在右侧,我们有“解码器”,其任务是将编码器提供的低维数据转换回原始数据格式。
编码器和解码器共享了三种区分Transformer架构的主要类型的层:位置编码、自注意力和前馈。 接下来,我们将在以下部分详细介绍每个部分的理解。
位置编码(Positional Encoding)
编码器是将自然语言输入转化为数值向量的层。这是通过嵌入(embedding)的过程实现的,嵌入是一种自然语言处理技术,它用向量表示单词,使得在向量空间中,向量之间的数学距离代表它们所表示的单词之间的相似性。请看下面的图示:
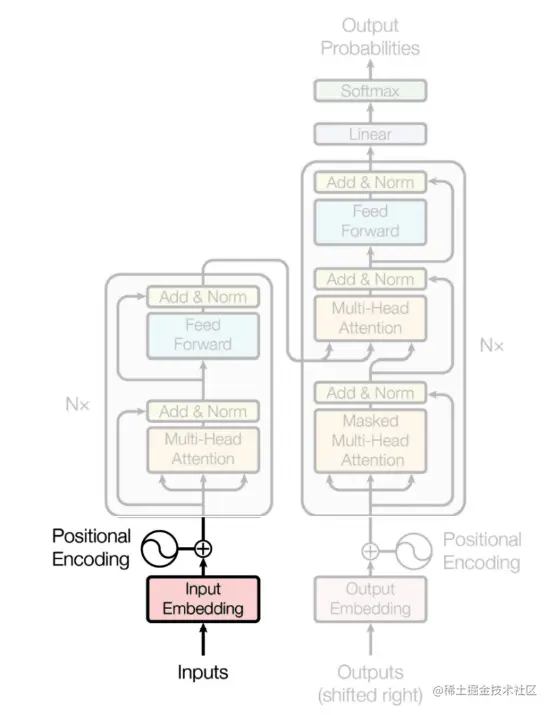
在我们谈论句子的含义时,我们都认同句子中单词的排列对于确定其含义非常重要。这就是为什么我们希望我们的编码器能够考虑到这个顺序,以实现位置编码。
位置编码是一个固定的、可学习的向量,表示单词在序列中的位置。它被加到单词的嵌入向量中,使得最终的单词表示既包括其含义又包括其位置信息。
自注意力(Self-attention)
自注意力层负责确定生成输出时每个输入标记的重要性。它们回答了这样一个问题:“我应该关注输入的哪个部分?”
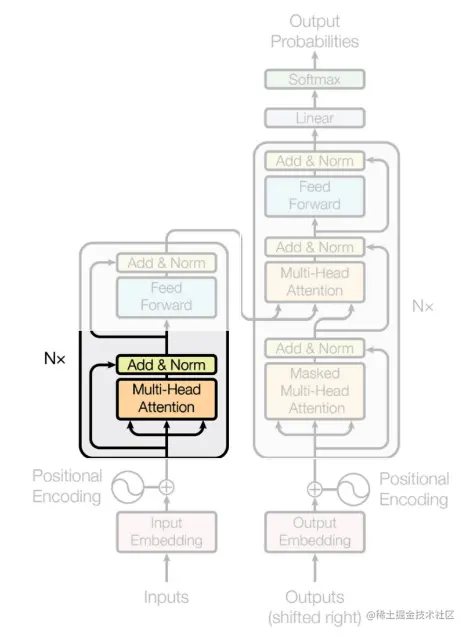
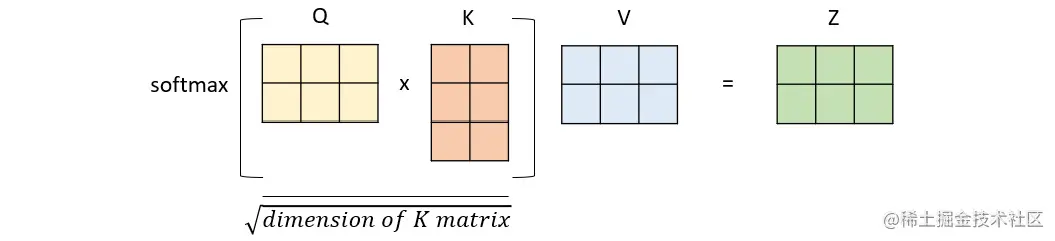
为了获得句子的自注意力向量,我们需要用到值(value)、查询(query)和键(key)这些元素。这些矩阵用于计算输入序列中各元素之间的注意力分数,它们是在训练过程中学习到的三个权重矩阵(通常用随机值进行初始化)。
查询用于表示注意机制当前的关注点,键用于确定应该关注输入的哪些部分,而值用于计算上下文向量。然后,这些矩阵相互相乘,并通过非线性变换(通过softmax函数)进行处理。自注意力层的输出以一种转换后的、具有上下文感知的方式表示输入值,这使得Transformer能够根据当前任务关注输入的不同部分。下面是如何表示矩阵乘法的示例:
请注意,在《Attention is all you need》这篇论文中提出的架构中,注意力层被称为多头注意力(multi-headed attention)。多头注意力实际上是一种机制,在其中多个自注意机制并行地操作于输入数据的不同部分,产生多个表示。这使得Transformer模型能够并行地关注输入数据的不同部分,并从多个视角汇总信息。 一旦注意力层的并行输出准备好后,它们将被连接起来,并通过一个前馈层进行处理。
前馈层(feedforward layers) 前馈层负责将自注意层的输出转换为适合最终输出的表示形式。它通过全连接的前馈神经网络对输入进行变换处理。
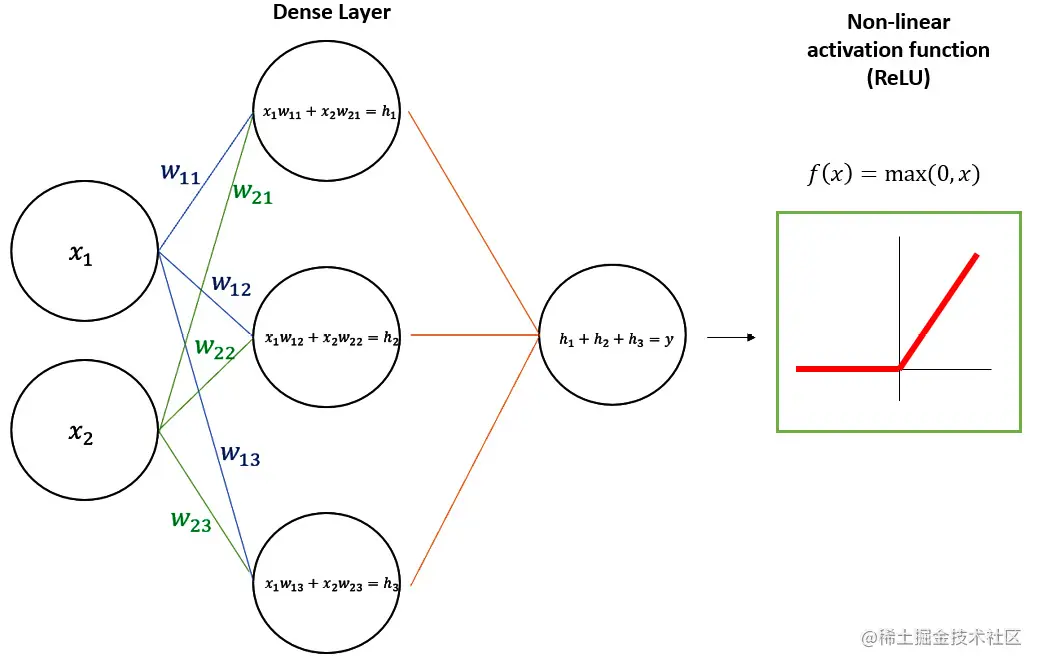
前馈层是Transformer架构的主要构建块,由两个主要元素组成:
- 全连接层(也称为稠密层):这是一种每个神经元与前一层的每个神经元都相连的层。换句话说,来自上一层的每个输入与当前层的每个神经元相连,并且当前层的每个神经元都对下一层的所有神经元的输出做出贡献。密集层中的每个神经元通过线性变换计算其输入的加权和。
- 激活函数:这是应用于全连接层输出的非线性函数。激活函数用于在神经元的输出中引入非线性,这对于网络学习输入数据中的复杂模式和关系是必要的。在GPT中,激活函数是ReLU。 前馈层的输出然后作为下一层网络的输入。
在下图中,我们可以看到一个通用前馈层的示例,它以一个二维向量作为输入,在稠密层中使用训练好的权重进行线性操作,然后使用ReLU激活函数对输出进行非线性变换:
最后一步 – 解码结果
我们提到,Transformer由编码器和解码器两个组件组成。尽管它们共享位置编码、自注意力和前馈层的核心元素,但解码器还需要执行额外的操作 – 将输入解码为原始数据格式。这个操作由一个线性层(一个将输入维度调整为输出维度的前馈网络)和一个softmax函数完成(它将输入转换为概率向量)。 从该向量中,我们选择概率最高的对应词语,并将其用作模型的最佳输出。
以上解释的所有架构元素定义了Transformer的框架。在下一节中,我们将看到这个创新框架如何为OpenAI开发的GPT-3和其他强大的语言模型铺平了道路。
GPT-3
然后我们来到GPT-3,ChatGPT背后的架构。它确实是基于Transformer架构的模型,但有一个特点:它只有解码器层。事实上,在OpenAI的引论论文《通过生成式预训练提高语言理解能力》中,研究人员采用了单解码器的方法。 GPT-3是巨大的。但是,具体有多大呢? 让我们从它所训练的知识库开始。它的目标是尽可能详尽地涵盖人类知识,因此它由不同的来源组成:
- Common Crawl(commoncrawl.org/):一个在8年期间收集的大规模网络数据语料库,基本没有过滤
- WebText2(openwebtext2.readthedocs.io/en/latest/b…):Reddit帖子中链接的网页文本集合,其中至少有3个赞
- Books1和Books2:两个分别包含在互联网上可用的书籍的语料库
- 维基百科:一个包含来自流行在线百科全书维基百科英语版的文章的语料库
在这里你可以更好地了解一下:
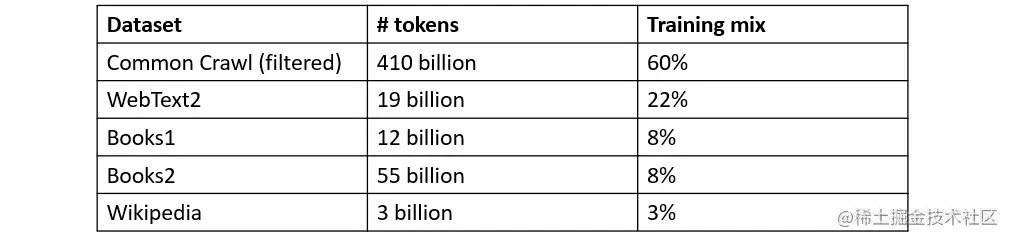
- 1个标记 ≈ 4个英文字符
- 1个标记 ≈ ¾个单词
我们可以得出结论,GPT-3大约在3740亿个单词上进行了训练! 这个知识库旨在在96个隐藏层中稀疏地训练1750亿个参数。为了让你对GPT-3的庞大有所了解,让我们将其与之前的版本GPT-1和GPT-2进行比较:
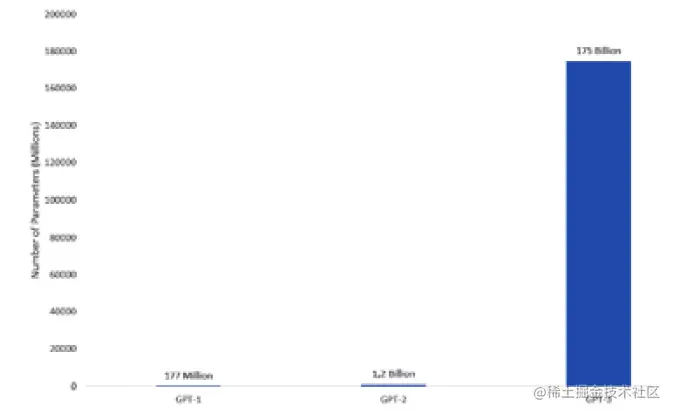
正如你所见,在自2018年推出GPT-1以来的短短几年里,GPT模型的复杂性和深度呈指数级增长。
GPT模型的发展速度令人惊讶,特别是考虑到这个模型的最新版本,也是首个向大众开放的版本:ChatGPT。
ChatGPT:前沿技术水平
在2022年11月,OpenAI宣布了其面向大众的对话式人工智能系统ChatGPT的Web预览。这引起了学科专家、组织机构和广大公众的巨大关注,以至于在仅仅5天内,该服务就吸引了100万用户!
在介绍ChatGPT之前,我先让它自我介绍一下:
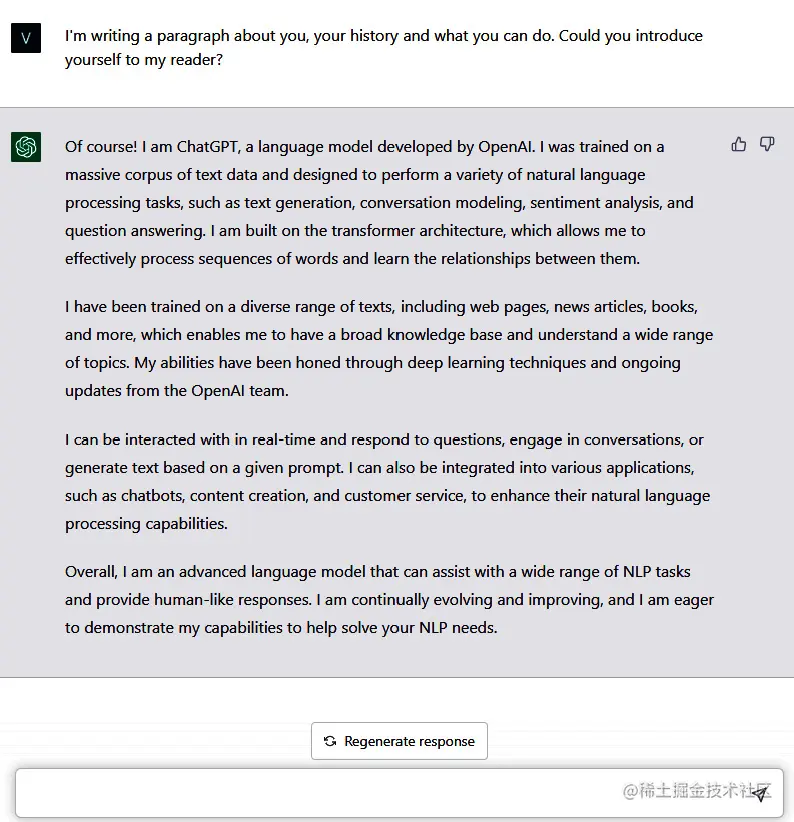
ChatGPT是建立在先进语言模型之上的,它利用了经过修改的GPT-3版本,专门针对对话进行了微调。优化过程中采用了强化学习与人类反馈(RLHF)的技术,这种技术利用人类的输入来训练模型展现出期望的对话行为。
我们可以将RLHF定义为一种机器学习方法,其中算法通过接收人类的反馈来学习执行任务。算法被训练成做出能够最大化人类提供的奖励信号的决策,人类则提供额外的反馈来改善算法的性能。当任务对于传统编程来说过于复杂,或者期望的结果难以事先指定时,这种方法非常有用。
这里的关键区别在于ChatGPT在训练过程中引入了人类参与,以使其与用户保持一致。通过采用RLHF,ChatGPT被设计成能够更好地理解和回应人类语言,以一种自然而引人入胜的方式。
注意: 同样的RLHF机制也被用于我们可以看作是ChatGPT前身的InstructGPT。在OpenAI的研究人员于2022年1月发表的相关论文中,介绍了InstructGPT作为一类比GPT-3更擅长遵循英语指令的模型。
ChatGPT的知识截止日期是2021年,这意味着该模型了解的信息仅限于2021年之前可得到的。然而,您仍然可以通过少量的学习样本为模型提供上下文,尽管模型的回答仍然基于截止日期之前的知识库。
ChatGPT正在革新我们与人工智能的互动方式。ChatGPT生成类似人类的文本能力使其成为广泛应用于聊天机器人、客户服务和内容创作等领域的热门选择。此外,OpenAI宣布将很快发布ChatGPT API,使开发人员能够直接将ChatGPT集成到定制应用程序中。
ChatGPT在架构和训练方法上持续进行的发展和改进将进一步推动语言处理的边界。
总结
在本章中,我们回顾了OpenAI的历史、研究领域以及最新的发展,直到ChatGPT。我们深入介绍了OpenAI Playground作为测试环境以及如何将Models API嵌入到您的代码中。然后,我们深入研究了GPT模型家族背后的数学原理,以便更清楚地了解ChatGPT背后的GPT-3模型的运作方式。
通过更深入地理解GPT模型背后的数学原理,我们可以更好地认识到这些模型的强大能力以及它们对个人和组织的多种影响方式。通过对OpenAI Playground和Models API的第一次体验,我们看到了测试或将预训练模型嵌入到应用程序中的简单性:这里的改变游戏规则的因素是您不需要强大的硬件和数小时的训练时间来训练您的模型,因为它们已经为您提供,并且如果需要,还可以进行定制,只需提供几个示例。
在下一章中,我们还将开始本书的第二部分,在其中我们将看到ChatGPT在各个领域中的应用以及如何发挥其潜力。您将学习如何通过正确设计提示语来充分利用ChatGPT,如何提高日常生产力,以及它如何成为开发人员、市场营销人员和研究人员的良好项目助手。
