

背景
今年五月的时候我写了一篇文章《花了大半个月,我终于逆向分析了Github Copilot》,受到了不少关注。当时应该还是copilot刚出不久,通过AST将webpack_modules的chunk自动拆分到不同的module文件,并通过一些语法转换让代码更易读。
但是当时最大的问题还是变量缺乏语义,需要花费很大的精力做上下文语义推导,代码看起来十分费劲。最近趁着copilot chat也要正式发布,重新看了一下copilot,发现有sourcemap文件,于是结合sourcemap反推了整个行列的变量映射关系以及文件关系,写了《再次揭秘Copilot:sourcemap逆向分析》这篇文章。
顺着sourcemap逆向的结果,代码变的更加可读了,于是也是从入口重新梳理了一下整体逻辑,发现了很多之前没有注意到的细节,有了以下几篇文章:
虽然copilot功能看起来很简单,但是细节之处非常多,要做到一个比较好的体验,copilot团队在细节之处有很多打磨,整体copilot代码盘点了下总共有近2万行左右,可见还是有不少复杂的细节。
整体架构
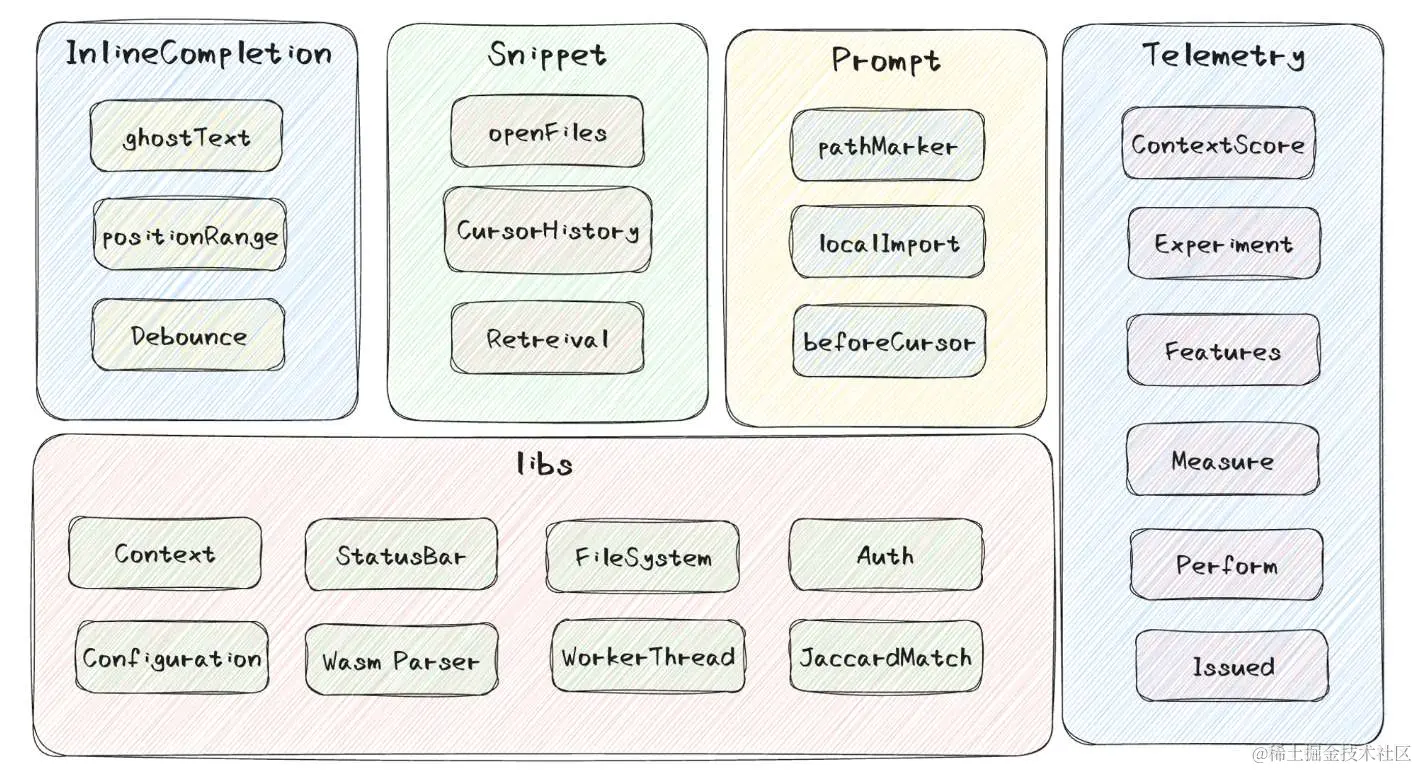
image
上图是我认为的Copilot基本架构:
libs提供了最基础的服务(图中不全,还有network、Extension相关等等一系列服务)InlineCompletion负责核心的补全能力入口,包含了对补全的处理策略,空行、光标、Debounce等等相关的处理。Snippet模块负责索引到具有一定相似度的代码片段,有可能来自于外部,也可能来自最近打开的文件内容,会作为prompt的一个参考。Prompt负责组装最终的prompt,把snippet、pathMarker、localImport、beforeCursor等组装起来。Telemetry是最基础的上报监控,里面包含了关于采纳率评分、实验特性、性能或缺陷度量等等重要的功能模块。
细节为王
Copilot在很多体验细节都有非常精细的打磨推敲,我试着列举一下目前所看到的:
双worker线程
在主线程中,Copilot开启了两个线程,分别代理了以下方法:
getFunctionPositionsisEmptyBlockStartisBlockBodyFinishedgetNodeStartgetCallSitesparsesWithoutErrorgetNeighborSnippetsextractLocalImportContextsleepgetPrompt
这些方法跟prompt和snippet相关,其中有一些方法需要进行wasm语法树的解析,有一些涉及到打开文件的遍历和相似度的计算,这些比较耗性能的操作都放到worker线程去处理。
多行预测模型
补充文本的提示到底是多行模式还是单行模式其实有很多细节,对于不同的语言来说,一般只有在块作用域的时候才需要多行提示,光标在行的中间位置,一般是需要单行提示,而光标处于新行的时候,往往又需要多行提示。
在Copilot内部对单行和多行模式的推断还是比较精细的,最后通过一个类似逻辑回归的模型来预测决定是否采用多行模式:
ini复制代码constructFeatures() {
let numFeatures = new Array(14).fill(0);
numFeatures[0] = this.prefixFeatures.length, numFeatures[1] = this.prefixFeatures.firstLineLength, numFeatures[2] = this.prefixFeatures.lastLineLength, numFeatures[3] = this.prefixFeatures.lastLineRstripLength, numFeatures[4] = this.prefixFeatures.lastLineStripLength, numFeatures[5] = this.prefixFeatures.rstripLength, numFeatures[6] = this.prefixFeatures.rstripLastLineLength, numFeatures[7] = this.prefixFeatures.rstripLastLineStripLength, numFeatures[8] = this.suffixFeatures.length, numFeatures[9] = this.suffixFeatures.firstLineLength, numFeatures[10] = this.suffixFeatures.lastLineLength, numFeatures[11] = this.prefixFeatures.secondToLastLineHasComment ? 1 : 0, numFeatures[12] = this.prefixFeatures.rstripSecondToLastLineHasComment ? 1 : 0, numFeatures[13] = this.prefixFeatures.prefixEndsWithNewline ? 1 : 0;
let langFeatures = new Array(Object.keys(languageMap).length + 1).fill(0);
langFeatures[languageMap[this.language] ?? 0] = 1;
let prefixLastCharFeatures = new Array(Object.keys(contextualFilterCharacterMap).length + 1).fill(0);
prefixLastCharFeatures[contextualFilterCharacterMap[this.prefixFeatures.lastChar] ?? 0] = 1;
let prefixRstripLastCharFeatures = new Array(Object.keys(contextualFilterCharacterMap).length + 1).fill(0);
prefixRstripLastCharFeatures[contextualFilterCharacterMap[this.prefixFeatures.rstripLastChar] ?? 0] = 1;
let suffixFirstCharFeatures = new Array(Object.keys(contextualFilterCharacterMap).length + 1).fill(0);
suffixFirstCharFeatures[contextualFilterCharacterMap[this.suffixFeatures.firstChar] ?? 0] = 1;
let suffixLstripFirstCharFeatures = new Array(Object.keys(contextualFilterCharacterMap).length + 1).fill(0);
return suffixLstripFirstCharFeatures[contextualFilterCharacterMap[this.suffixFeatures.lstripFirstChar] ?? 0] = 1, numFeatures.concat(langFeatures, prefixLastCharFeatures, prefixRstripLastCharFeatures, suffixFirstCharFeatures, suffixLstripFirstCharFeatures);
}
基于wasm的语法解析
copilot要支持多种不同类型的语言,语法树的解析是无法通过babel这类js工具的,需要借助wasm进行解析。

image
目前Copilot支持的主流语言有go、js、python、ts、ruby。在多行推导块作用域、localImport等功能上都用到了语法树的解析能力。
采用的解析库应该是tree-sitter.github.io/tree-sitter…
采纳率预测模型
在针对ghostText是否显示的问题上,Copilot也做了很多考量,有一个决策因素就是看contextualFilterScore ,是否满足设定的阈值:
ini复制代码function contextualFilterScore(ctx, telemetryData, prompt, contextualFilterEnableTree) {
let cfManager = ctx.get(ContextualFilterManager),
yt_1 = cfManager.previousLabel,
acw = 0;
"afterCursorWhitespace" in telemetryData.properties && telemetryData.properties.afterCursorWhitespace === "true" && (acw = 1);
let dt_1 = (Date.now() - cfManager.previousLabelTimestamp) / 1e3,
ln_dt_1 = Math.log(1 + dt_1),
ln_promptLastLineLength = 0,
promptLastCharIndex = 0,
promptPrefix = prompt.prefix;
if (promptPrefix) {
ln_promptLastLineLength = Math.log(1 + getLastLineLength(promptPrefix));
let promptLastChar = promptPrefix.slice(-1);
contextualFilterCharacterMap[promptLastChar] !== void 0 && (promptLastCharIndex = contextualFilterCharacterMap[promptLastChar]);
}
let ln_promptLastLineRstripLength = 0,
promptLastRstripCharIndex = 0,
promptPrefixRstrip = promptPrefix.trimEnd();
if (promptPrefixRstrip) {
ln_promptLastLineRstripLength = Math.log(1 + getLastLineLength(promptPrefixRstrip));
let promptLastRstripChar = promptPrefixRstrip.slice(-1);
contextualFilterCharacterMap[promptLastRstripChar] !== void 0 && (promptLastRstripCharIndex = contextualFilterCharacterMap[promptLastRstripChar]);
}
let ln_documentLength = 0;
if ("documentLength" in telemetryData.measurements) {
let documentLength = telemetryData.measurements.documentLength;
ln_documentLength = Math.log(1 + documentLength);
}
let ln_promptEndPos = 0;
if ("promptEndPos" in telemetryData.measurements) {
let promptEndPos = telemetryData.measurements.promptEndPos;
ln_promptEndPos = Math.log(1 + promptEndPos);
}
let relativeEndPos = 0;
if ("promptEndPos" in telemetryData.measurements && "documentLength" in telemetryData.measurements) {
let documentLength = telemetryData.measurements.documentLength;
relativeEndPos = (telemetryData.measurements.promptEndPos + .5) / (1 + documentLength);
}
let languageIndex = 0;
contextualFilterLanguageMap[telemetryData.properties.languageId] !== void 0 && (languageIndex = contextualFilterLanguageMap[telemetryData.properties.languageId]);
let probabilityAccept = 0;
if (contextualFilterEnableTree) {
let features = new Array(221).fill(0);
features[0] = yt_1, features[1] = acw, features[2] = ln_dt_1, features[3] = ln_promptLastLineLength, features[4] = ln_promptLastLineRstripLength, features[5] = ln_documentLength, features[6] = ln_promptEndPos, features[7] = relativeEndPos, features[8 + languageIndex] = 1, features[29 + promptLastCharIndex] = 1, features[125 + promptLastRstripCharIndex] = 1, probabilityAccept = treeScore(features)[1];
} else {
let sum = contextualFilterIntercept;
sum += contextualFilterWeights[0] * yt_1, sum += contextualFilterWeights[1] * acw, sum += contextualFilterWeights[2] * ln_dt_1, sum += contextualFilterWeights[3] * ln_promptLastLineLength, sum += contextualFilterWeights[4] * ln_promptLastLineRstripLength, sum += contextualFilterWeights[5] * ln_documentLength, sum += contextualFilterWeights[6] * ln_promptEndPos, sum += contextualFilterWeights[7] * relativeEndPos, sum += contextualFilterWeights[8 + languageIndex], sum += contextualFilterWeights[29 + promptLastCharIndex], sum += contextualFilterWeights[125 + promptLastRstripCharIndex], probabilityAccept = 1 / (1 + Math.exp(-sum));
}
return ctx.get(ContextualFilterManager).probabilityAccept = probabilityAccept, probabilityAccept;
}
这个模型看起来是会根据参数采用线性模型还是决策树模型。
debounce预测
对于代码补全的Debounce,甚至Copilot都做了预测,可见其细致程度:
ini复制代码async function getDebounceLimit(ctx, telemetryData) {
let expDebounce;
if ((await ctx.get(Features).debouncePredict()) && telemetryData.measurements.contextualFilterScore) {
let acceptProbability = telemetryData.measurements.contextualFilterScore,
sigmoidMin = 25,
sigmoidRange = 250,
sigmoidShift = .3475,
sigmoidSlope = 7;
expDebounce = sigmoidMin + sigmoidRange / (1 + Math.pow(acceptProbability / sigmoidShift, sigmoidSlope));
} else expDebounce = await ctx.get(Features).debounceMs();
return expDebounce > 0 ? expDebounce : 75;
}
不确定这些参数是否是经验值。
Jaccard相似度
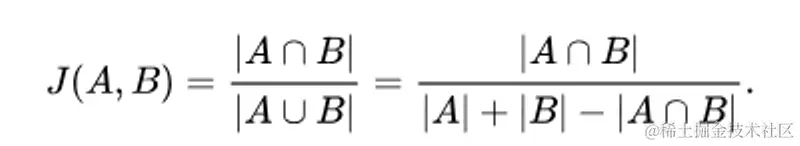
image
在进行snippet选取的时候,会进行相似度比对,选择相似度较高的片段作为相关的snippet发送给模型来辅助推断。
这里Copilot采用的是较为简单的Jaccard相似度加一个滑动窗口,进行分词比较。
Prompt优先级
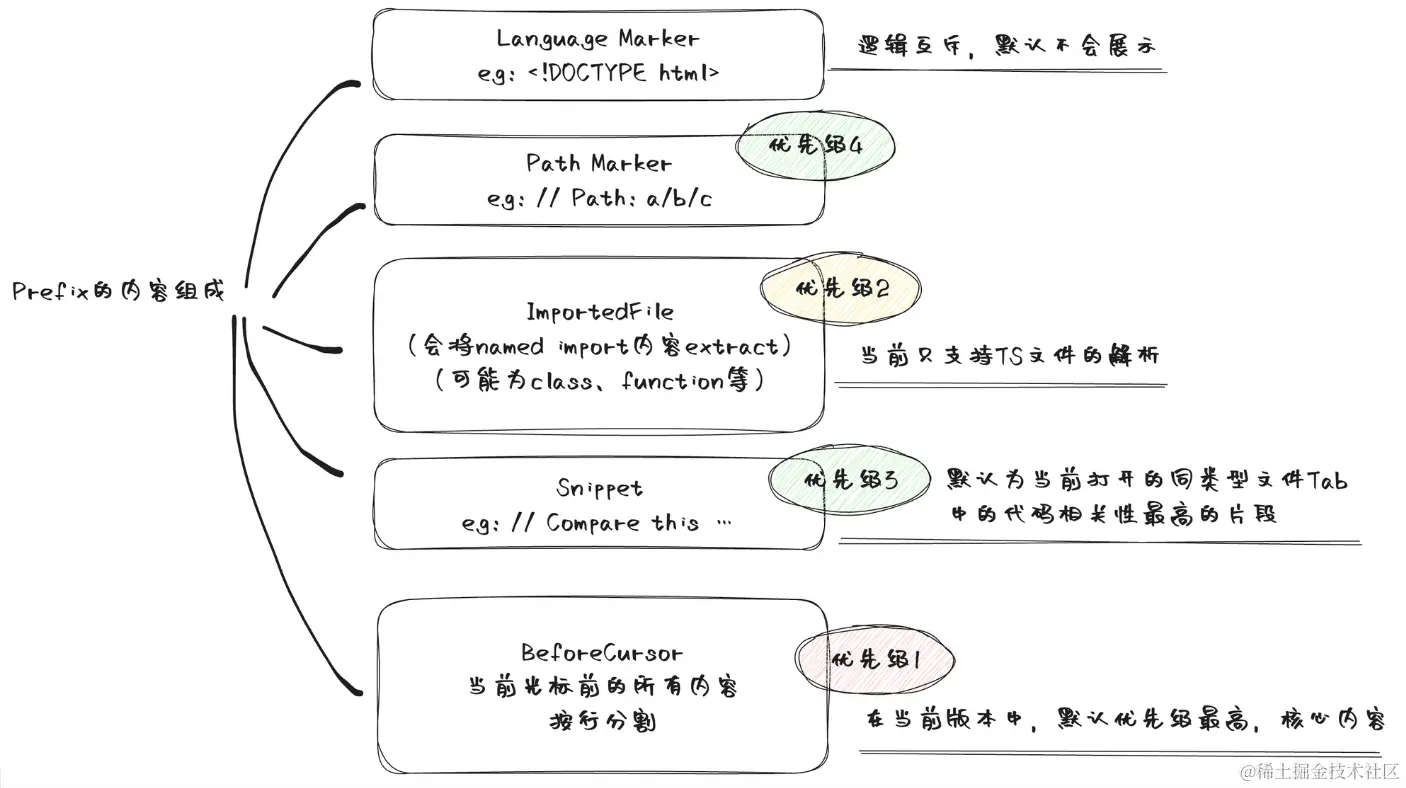
image
copilot对Prompt的处理也非常精细,不止是beforeCursor根据token数目进行推算,还结合了不同语言的language特性加上language Marker,path Marker,以及Import和snippet,设立优先级机制组装最终的Prompt给到模型,这也赋予了Copilot的代码补全更强大的推导能力。
实验平台下发参数
ini复制代码async getAssignment(feature, requestFilters = {}, telemetryData) {
let granularityDirectory = this.getGranularityDirectory(),
preGranularityFilters = this.makeFilterSettings(requestFilters),
rememberedGranularityExtension = granularityDirectory.extendFilters(preGranularityFilters),
expAccordingToRememberedExtension = await this.getExpConfig(rememberedGranularityExtension.newFilterSettings);
granularityDirectory.update(preGranularityFilters, +(expAccordingToRememberedExtension.variables.copilotbycallbuckets ?? NaN), +(expAccordingToRememberedExtension.variables.copilottimeperiodsizeinh ?? NaN));
let currentGranularityExtension = granularityDirectory.extendFilters(preGranularityFilters),
filters = currentGranularityExtension.newFilterSettings,
exp = await this.getExpConfig(filters),
backgroundQueue = new Promise(resolve => setTimeout(resolve, _Features.upcomingDynamicFilterCheckDelayMs));
for (let upcomingFilter of currentGranularityExtension.otherFilterSettingsToPrefetch) backgroundQueue = backgroundQueue.then(async () => {
await new Promise(resolve => setTimeout(resolve, _Features.upcomingDynamicFilterCheckDelayMs)), this.getExpConfig(upcomingFilter);
});
return this.prepareForUpcomingFilters(filters), telemetryData && (telemetryData.filtersAndExp = {
exp: exp,
filters: filters
}), exp.variables[feature];
}
copilot很多参数都是通过实验平台下发的,比如:
debounceMsdebouncePredictcontextualFilterEnablecontextualFilterEnableTreecontextualFilterAcceptThresholdmultiLogitBiasrequestMultiModelrequestMultiModelThreshold- …还有一系列参数
边界处理(缓存、缩进空行、token计算、语言语法等)
copilot在很多边界的处理上都非常细致,之前分析过它的缓存设计,语言语法等,下面举一个缩进处理的例子:
vbnet复制代码function adjustLeadingWhitespace(index, text, ws) {
if (ws.length > 0) {
if (text.startsWith(ws)) return {
completionIndex: index,
completionText: text,
displayText: text.substr(ws.length),
displayNeedsWsOffset: !1
};
{
let textLeftWs = text.substr(0, text.length - text.trimLeft().length);
return ws.startsWith(textLeftWs) ? {
completionIndex: index,
completionText: text,
displayText: text.trimLeft(),
displayNeedsWsOffset: !0
} : {
completionIndex: index,
completionText: text,
displayText: text,
displayNeedsWsOffset: !1
};
}
} else return {
completionIndex: index,
completionText: text,
displayText: text,
displayNeedsWsOffset: !1
};
}
可以看到completionText 和displayText 的差异点主要就是空格本身,通过displayNeedsWsOffset 来标识最终的处理结果。
codeReference(新特性)
在代码补全建议被采纳后,会索引codeReference:
ini复制代码function handlePostInsertion(githubLogger) {
return async event => {
let {
ctx: ctx,
completionText: completionText,
completionId: completionId,
start: start,
fileURI: fileURI,
insertionOffset: insertionOffset
} = event,
insertionDoc = await ctx.get(TextDocumentManager).getTextDocument(fileURI);
if (!insertionDoc) {
codeReferenceLogger.debug(ctx, `Expected document matching ${fileURI}, got nothing.`);
return;
}
if (!completionId || !start) {
snippyTelemetry.handleCompletionMissing({
context: ctx,
origin: "onPostInsertion",
reason: "No completion metadata found."
});
return;
}
let docText = insertionDoc.getText();
if (!hasMinLexemeLength(docText)) return;
let potentialMatchContext = completionText;
if (!hasMinLexemeLength(completionText)) {
let textWithoutCompletion = docText.slice(0, insertionOffset),
minLexemeStartOffset = offsetLastLexemes(textWithoutCompletion, MinTokenLength);
potentialMatchContext = docText.slice(minLexemeStartOffset, insertionOffset + completionText.length);
}
if (!hasMinLexemeLength(potentialMatchContext)) return;
let matchResponse = await snippyRequest(ctx, () => Match(ctx, potentialMatchContext));
if (!matchResponse || !matchResponse.snippets.length) {
codeReferenceLogger.info(ctx, "No match found");
return;
}
codeReferenceLogger.info(ctx, "Match found");
let {
snippets: snippets
} = matchResponse,
citationPromises = snippets.map(async snippet => {
let response = await snippyRequest(ctx, () => FilesForMatch(ctx, {
cursor: snippet.cursor
}));
if (!response) return;
let files = response.file_matches,
licenseStats = response.license_stats;
return {
match: snippet,
files: files,
licenseStats: licenseStats
};
});
notify(ctx), Promise.all(citationPromises).then(citations => citations.filter(Boolean)).then(filtered => {
if (filtered.length) for (let citation of filtered) {
let licensesSet = new Set(Object.keys(citation.licenseStats?.count ?? {}));
licensesSet.has("NOASSERTION") && (licensesSet.delete("NOASSERTION"), licensesSet.add("unknown"));
let allLicenses = Array.from(licensesSet).sort(),
matchLocation = `[Ln ${start.line}, Col ${start.character}]`,
shortenedMatchText = `${citation.match.matched_source.slice(0, 100).replace(/[rnt]+|^[ t]+/gm, " ").trim()}...`,
workspaceFolders = y3.workspace.workspaceFolders ?? [],
fileName = fileURI.fsPath;
for (let folder of workspaceFolders) if (fileURI.fsPath.startsWith(folder.uri.fsPath)) {
fileName = fileURI.fsPath.replace(folder.uri.fsPath, "");
break;
}
githubLogger.info(`'${fileName}'`, `Similar code with ${pluralize(allLicenses.length, "license type")}`, `[${allLicenses.join(", ")}]`, `${citation.match.github_url.replace(/,s*$/, "")}&editor=vscode`, matchLocation, shortenedMatchText), copilotOutputLogTelemetry.handleWrite({
context: ctx
});
}
});
};
}
这是一项新的能力,会搜索整个Github上的仓库,推荐有相同代码片段的引用过来,具体可以参见:
小结一下
copilot在产品功能上看似简单,但要想做好细节真的非常不容易。在写了之前那篇文章之后,很多人觉得仅仅逆向客户端插件这部分没什么用,但其实里面有很多细节是值得分析的,copilot插件已经不仅仅是在前端工程方面做优化,更是结合了传统的机器学习能力去做更好的体验。
所谓细节决定成败,copilot在众多vscode插件能够脱颖而出,做到了很多插件做不到的细节之处,非常值得我们学习。
上述代码已经提交在Github上,有需要的小伙伴可自取:
