

框架介绍
本质上可以把 Vanna 当作一个 Python 包,它使用检索增强技术来帮助用户使用 LLM 为数据库生成准确的 SQL 语句。
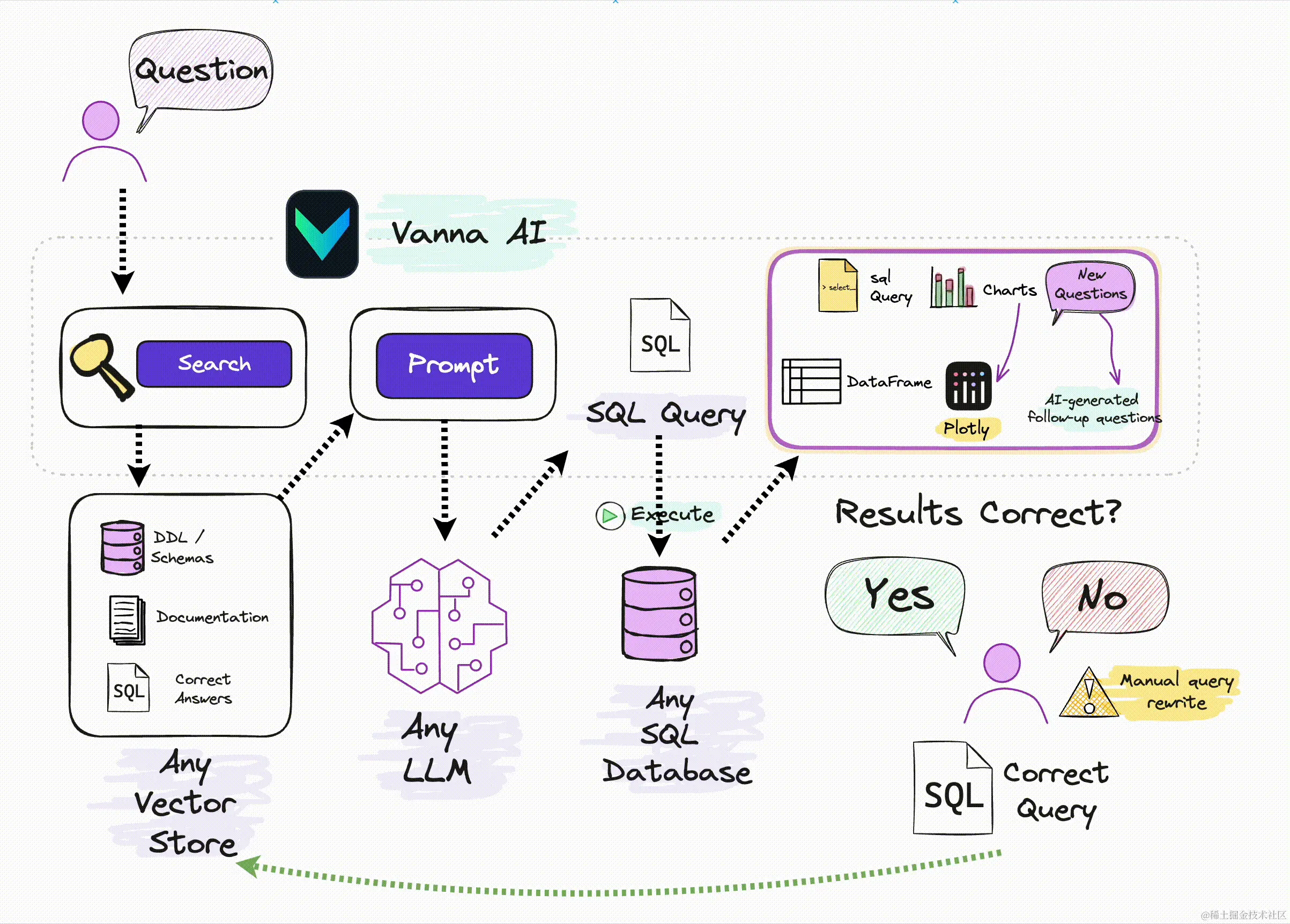
从上图可以看出来,有以下几个步骤:
- 用户提出查询的自然语言描述
Search - 向量库中预先存放了数据库的各种信息(如: DDL Schemas、Documentation、Correct SQL Answers 等),使用 Search 在向量库中进行检索,召回合适的相关
数据库元数据内容 - 将这些召回的内容和
Search进行整理变成Prompt - 使用
LLM对Prompt进行语义解析转译成符合要求的SQL - 使用 SQL 去数据库中进行查找
- 最后以
图标等形式进行展示 - 这里有一个可选的操作就是用户可以评价结果是否正确,以此来调整向量库的召回性能
特点
- LLM 默认免费提供 gpt-3.5-turbo
- 目前产品免费
- RAG 架构,主流趋势
- 效果惊人
- 保证数据安全
- 自学习能力(还没有测)
注册账号
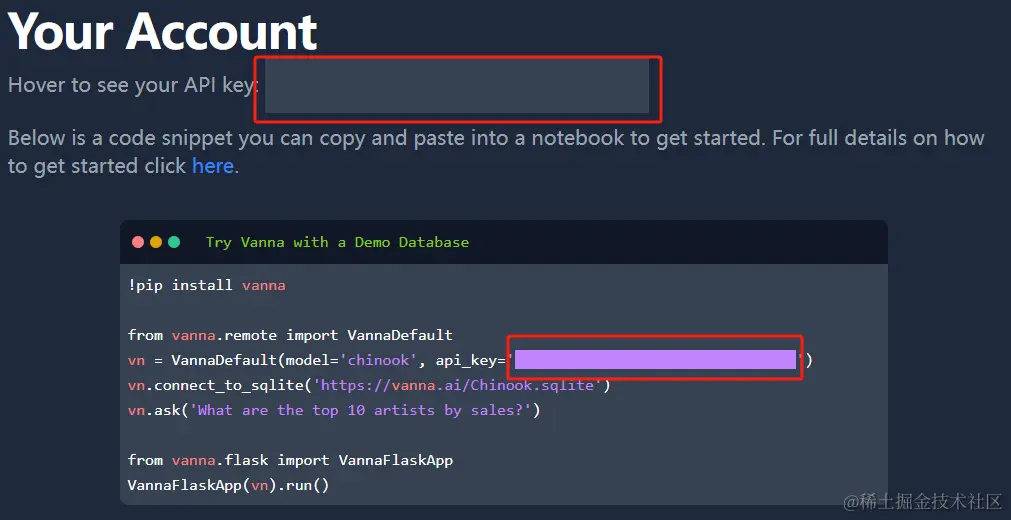
注册账号很简单,进入页面之后就会给一个 API key ,也就是下图红框的内容,页面上直观看不到,只有复制或者鼠标选中的时候才会显示,我们在使用后续的 api 的时候就是用这个 key 。
训练模型
Vanna 的工作原理很简单,只需两个步骤,首先在用户的数据上 训练 RAG 模型,然后将提出的问题转化为可以在数据库上自动运行的 SQL 语句。要想训练模型主要使用的是 vn.train 函数,它有以下多种使用方式。
DDL statements
这些 DDL 语句可以使系统了解表结构中的各种内容,LLM 可能需要这些文档来辅助了解用户问题。
ini复制代码vn.train(ddl="CREATE TABLE my_table (id INT, name TEXT)")
Documentation strings
这些可以是关于用户的数据库的辅助文档,最常见的就是对字段的定义和解释,LLM 可能需要这些文档来辅助了解用户问题。
ini复制代码vn.train(documentation="Our business defines XYZ as ABC")
SQL Statements
对系统理解最有帮助的事情之一是组织中常用的 SQL 查询用例,这类似于少样本学习。
ini复制代码vn.train(sql="SELECT * FROM my_table")
Question-SQL Pairs
还可以使用 Question-SQL 对来训练系统,这和上面一样,也是类似于少样本学习,这是训练系统最直接的方法。
ini复制代码vn.train(question="What is the average age of our customers?", sql="SELECT AVG(age) FROM customers" )
Training Plan
这种方法其实就是将数据库的 schema 告诉 LLM ,让它对数据库整体结构有了解。
ini复制代码df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
plan = vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)
举例
在开始之前现在自己本地的 postgres 数据库中建自己的表,我这里是两张表 company 和 person ,详情后文描述。
然后根据前面提到的内容可知,要先新建一个模型,随便起一个名字即可,我这里已经创建好了叫 query_statistics
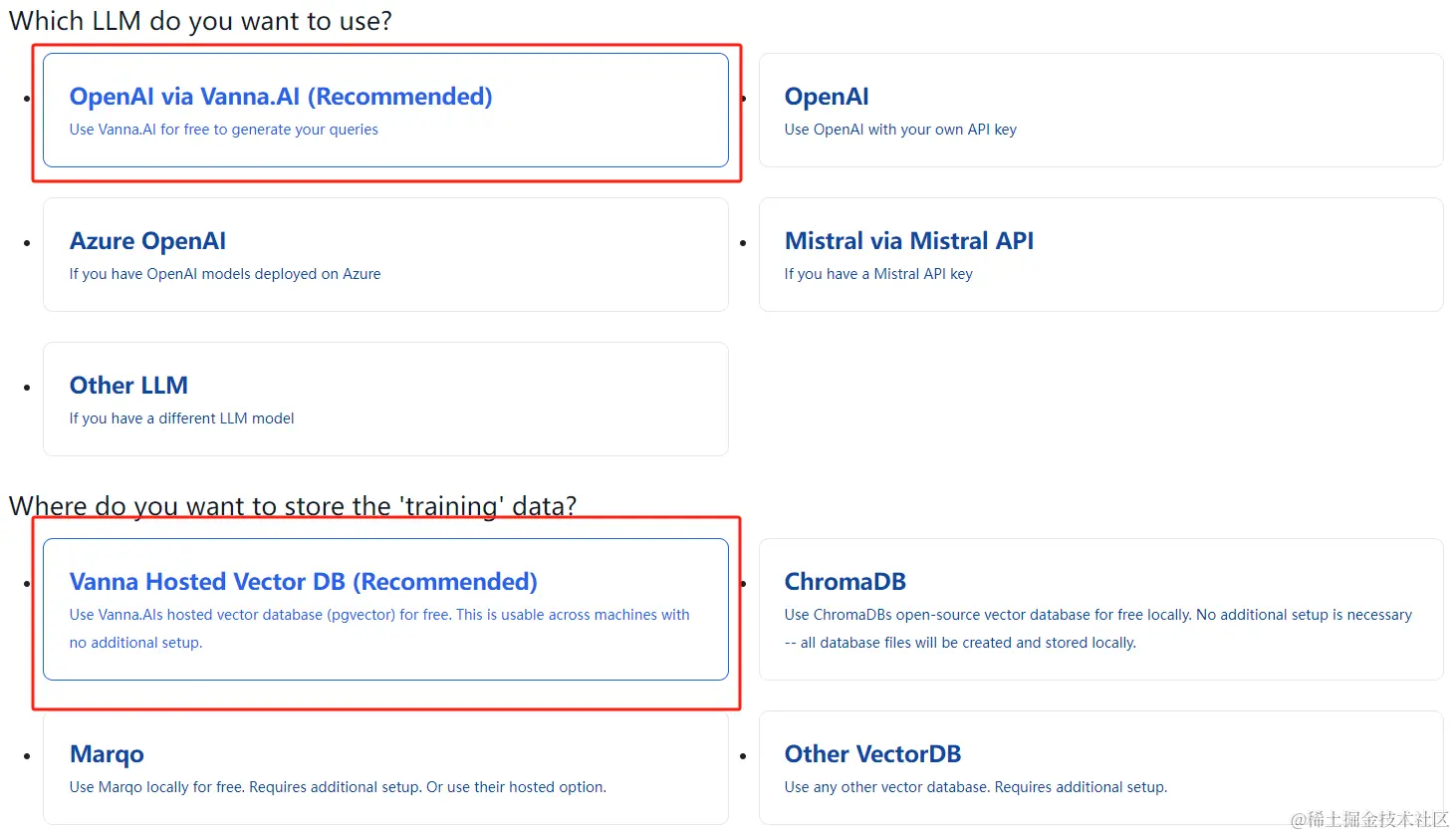
然后根据自己的情况在这个页面中找到自己的配置。我这里使用的 LLM 和向量库就是推荐的工具,然后以 postgres 数据库中的多张表为例子,展示如何训练,我这里加入了 DDL statements 、Documentation strings 和 Question-SQL Pairs 多种方式综合进行训练,最后提问,系统可以使用生成的 SQL 自动去 postgres 中查找并返回结果。
pip 使用下面命令进行包的安装:
arduino复制代码pip install 'vanna[postgres]'
下面就可以使用代码对模型进行训练了,具体代码实现如下,将关键的配置改成自己的配置即可。
需要注意的是这里很多 vn.train 语句中的 documentation 或者 question 是英文写的,同样的换成中文也是可以的哦,只是需要详细的描述各个表以及字段的含义,或者详细描述问题-SQL对。
ini复制代码from vanna.remote import VannaDefault
vn = VannaDefault(model='你自己新建的模型名字', api_key='你自己的key')
vn.connect_to_postgres(host='你的数据库 ip', dbname='你的数据库名字', user='数据库账号', password='数据库密码', port='数据库端口')
vn.train(ddl="""CREATE TABLE company(
"risk_label" character varying(128) COLLATE pg_catalog."default",
"company_name" character varying(128) COLLATE pg_catalog."default" NOT NULL,
"company_address" character varying(128) COLLATE pg_catalog."default",
CONSTRAINT company_pkey PRIMARY KEY ("company_name")
)""")
vn.train(ddl="""CREATE TABLE person
(
"person_id" character varying(128) COLLATE pg_catalog."default",
"name" character varying(128) COLLATE pg_catalog."default",
"company_name" character varying(128) COLLATE pg_catalog."default",
CONSTRAINT "company_fkey" FOREIGN KEY ("company_name")
REFERENCES company ("company_name") MATCH SIMPLE
)""")
vn.train(documentation="The company table describes the name, address, risk profile of each company")
vn.train(documentation="The person table describes each person's unique code, name, and company where they work")
vn.train(documentation="The risk_label field in the zddw table describes the potential risks of the company")
vn.train(documentation="The company_name field in the zddw table describes the name of the company")
vn.train(documentation="The company_address field in the zddw table describes the address information of the company")
vn.train(documentation="The person_id field in the zdry table describes the person's unique number")
vn.train(documentation="The name field in the zdry table describes the name of the person")
vn.train(documentation="The company_name field in the zdry table describes the name of the company where the person works")
vn.train(question='What is Sam’s company?', sql="SELECT company_name FROM person WHERE name = 'Sam'")
vn.train(question='What is the company_address of Sam’s company_name?', sql="SELECT company.company_address FROM company JOIN person ON company.company_name = person.company_name WHERE person.name = 'Sam';")
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
运行之后,日志中会有一个链接提示 http://localhost:8084 ,点进去回到一个页面。
sql复制代码Adding ddl: CREATE TABLE company(
"risk_label" character varying(128) COLLATE pg_catalog."default",
"company_name" character varying(128) COLLATE pg_catalog."default" NOT NULL,
"company_address" character varying(128) COLLATE pg_catalog."default",
CONSTRAINT company_pkey PRIMARY KEY ("company_name")
)
Adding ddl: CREATE TABLE person
(
"person_id" character varying(128) COLLATE pg_catalog."default",
"name" character varying(128) COLLATE pg_catalog."default",
"company_name" character varying(128) COLLATE pg_catalog."default",
CONSTRAINT "company_fkey" FOREIGN KEY ("company_name")
REFERENCES company ("company_name") MATCH SIMPLE
)
Adding documentation....
Adding documentation....
Adding documentation....
Adding documentation....
Adding documentation....
Adding documentation....
Adding documentation....
Adding documentation....
Your app is running at:
http://localhost:8084
* Serving Flask app 'vanna.flask'
* Debug mode: off
提问效果展示
我提出的问题是What is the company address of Tom's company ,因为我的数据库中还没有数据,所以返回的都是空数据,如果有数据的话,会有精美的表格和图进行展示,最后还会询问你结果是否正确。
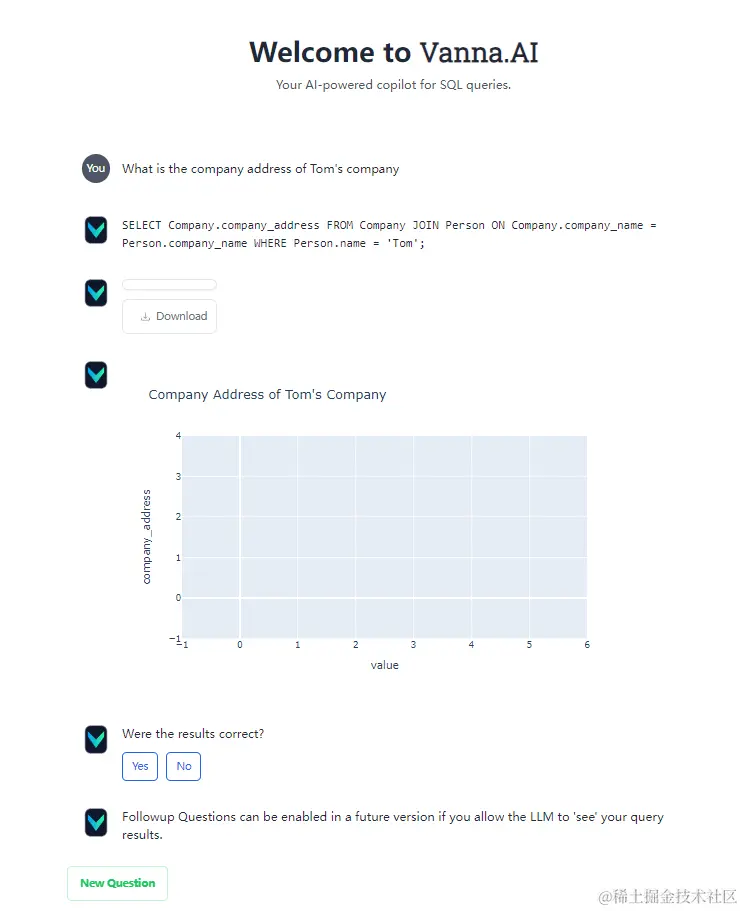
这个效果是相当惊人了,吊打大部分产品!
