

ChatGPT是一种基于Transformer的预训练语言模型,本文使用Python伪代码描述它的核心执行流程

ChatGPT
ChatGPT,全称为Chat Generative Pre-trained Transformer,
ChatGPT是一种基于Transformer的预训练语言模型
想象一下,你有一个超级聪明的朋友,名叫ChatGPT。ChatGPT能够阅读和理解大量的书籍、文章和网页等各种材料。它读得越多,就越聪明。
ChatGPT记忆力非常惊人,不仅能记住读过的每个词内容, 还能理解这些词之间的关联和模式。比如,如果你问它一本小说的主要情节,它不仅能告诉你情节,还能分析人物性格,甚至预测故事可能的结局。
ChatGPT详细原理和训练过程非常复杂,并涉及到大量的工程技术、分布式计算以及大规模数据处理。OpenAI也没有公开完整训练的源代码。
有个开源版本的ChatGPT OpenChatKit(github.com/togethercom…)
下面是一个简化版的流程并给出部分Python伪代码来说明关键步骤。
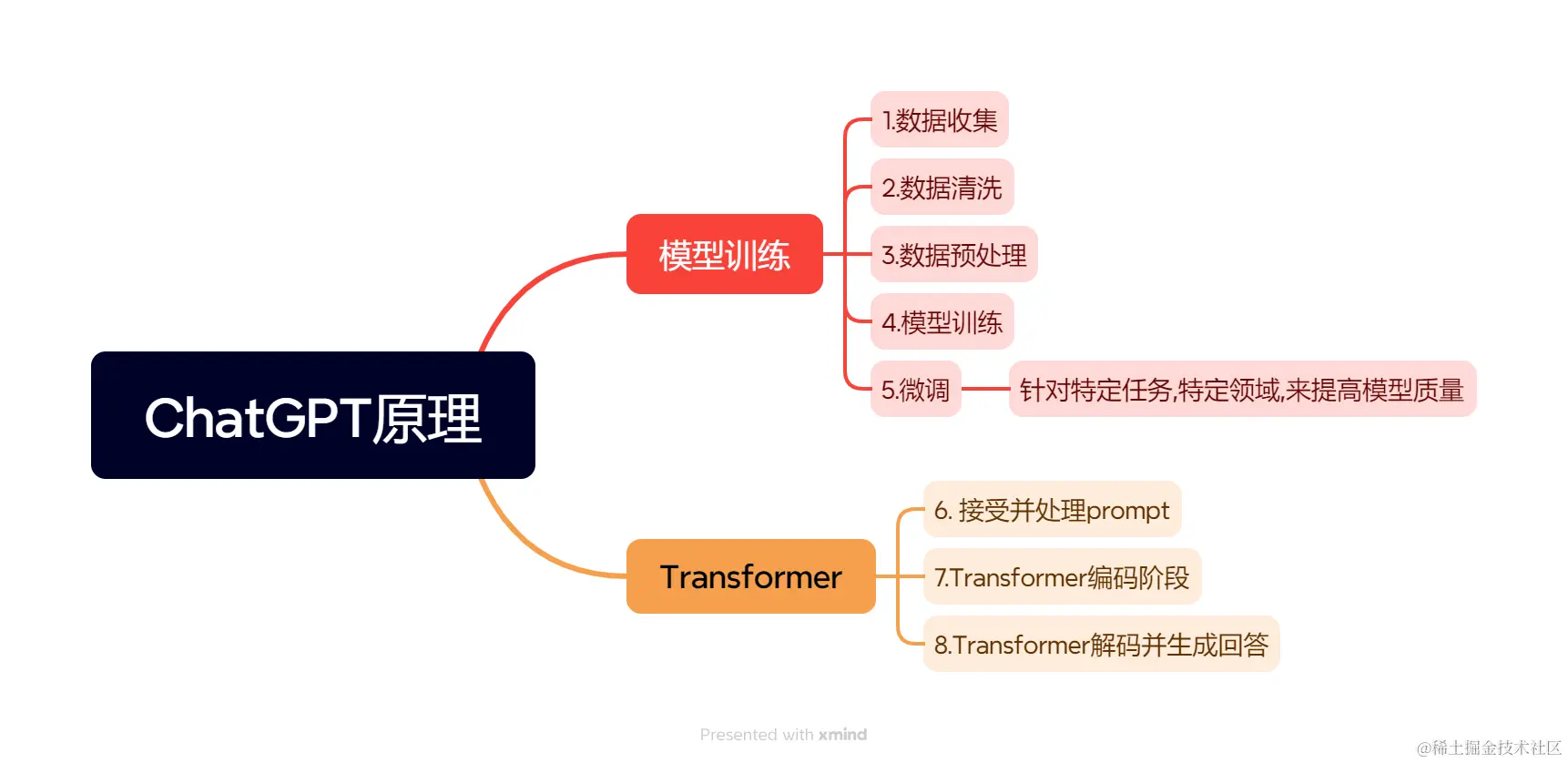
1.数据收集
- ChatGPT收集大量的公开的文本数据,包括网页、新闻、书籍、对话和代码等。
- 同时, 分析网络上的热点话题和流行文化,以了解最新的语言模式和表达方式。
- 数据越大、越多样化,模型生成的自然语言文本就越好。
arduino复制代码def collect_data():
raw_text_data = []
# 使用爬虫或者其他手段抓取数据
for webpage in web_crawler():
raw_text_data.append(webpage.text)
cleaned_data = [clean_text(text) for text in raw_text_data]
return cleaned_data_
2.数据清洗
去除HTML标签、特殊字符等, 帮助模型更好地理解输入的文本,并提高生成的文本的质量。
ini复制代码def clean_text(text):
# 实际清理可能包括很多操作
cleaned = re.sub('<.*?>', '', text) # 移除HTML标签
cleaned = ''.join(c for c in cleaned if c.isprintable()) # 只保留可打印字符
return cleaned
3. 数据预处理
实际预处理还会包括去除噪声、标准化词汇、构建词汇表等步骤,最终生成数据集(词汇表).
ini复制代码def preprocess_data(cleaned_data, tokenizer):
input_ids, attention_masks = [], []
for text in cleaned_data:
'''
1. 分词:将输入的文本分割成单词或子词。
2. 添加特殊标记:可能会添加一些特殊的标记或标识符,用于表示文本的开头和结尾,或者用于区分不同的部分。
3. 编码:将单词或子词映射到特定的编码或索引。
4. 添加其他信息:可能会添加一些额外的信息,例如词的位置、词性标记等。
'''
encoded = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=tokenizer.model_max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
input_ids.append(encoded['input_ids'])
attention_masks.append(encoded['attention_mask'])
dataset = torch.utils.data.TensorDataset(torch.cat(input_ids), torch.cat(attention_masks))
# 返回数据集
return dataset
4.训练
生成最终的模型
ini复制代码def train(dataset, optimizer):
# 初始化训练模型和配置
config = transformers.GPT2Config.from_pretrained('gpt2')
# 创建模型实例
model = GPT2LMHeadModel(config)
# 将模型移动到指定的设备上进行训练,如 GPU。
device = "cuda" # 或者 "cuda:0" 等具体的 GPU 索引
model.to(device)
# 在每个epoch中,对数据集的多个批次进行处理,计算损失,并根据损失的梯度来更新模型的参数,以逐步改进模型的性能
for epoch in range(num_epochs):
for batch in dataloader:
inputs, masks = batch
inputs, masks = inputs.to(device), masks.to(device)
outputs = model(inputs, masks)
loss = compute_loss(outputs, targets) # 根据实际情况定义损失函数
optimizer.zero_grad()
loss.backward()
optimizer.step()
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()
5. 微调
对模型进行微调以适应特定任务, 进一步提高模型在特定领域的性能和表现。
ruby复制代码def fine_tune_on_task(model, task_data):
# 更新训练参数以适应微调任务
training_args.num_train_epochs = 3 # 示例:减少预训练时长
trainer = Trainer(model, train_dataset=task_data)
# 执行微调
trainer.train()
# 返回新的模型
return model
class ChatGPTTransformerEncoder:
def __init__(self, config):
self.encoder = GPT2Model(config)
def encode(self, input_ids, attention_mask):
# 输入ids经过嵌入层、位置编码后送入多层Transformer编码器
encoded_output = self.encoder(input_ids=input_ids, attention_mask=attention_mask)
# 最后一层Transformer编码器的输出作为上下文向量
context_vector = encoded_output.last_hidden_state[:, 0, :] # 取第一个Token(通常是[CLS])的向量
return context_vector, encoded_output.attentions # 返回上下文向量及各层注意力权重
6. 接受并处理prompt(提示词)
将文本prompt转换为模型所需的input_ids和attention_mask。 参数:
- prompt: 输入的文本提示
- max_length: 模型的最大prompt序列长度
ini复制代码def process_prompt(prompt, max_length=512):
# 对prompt进行编码
encoding = tokenizer.encode_plus(
prompt,
add_special_tokens=True, # 添加特殊token(如[CLS]和[SEP])
max_length=max_length,
padding='max_length', # 若长度不足,则填充到最大长度
truncation=True, # 若长度超过,则截断至最大长度
return_tensors='pt' # 返回PyTorch张量格式
)
# 提取必要的部分
input_ids = encoding['input_ids']
attention_mask = encoding['attention_mask']
return input_ids, attention_mask
7. Transformer编码阶段
ini复制代码def transformer_encode(input_ids, attention_mask):
# 初始化编码器
config = transformers.GPT2Config.from_pretrained('gpt2')
encoder = ChatGPTTransformerEncoder(config)
# 返回上下文向量及各层注意力权重
context_vector, attentions = encoder.encode(input_ids, attention_mask)_
8. Transformer解码并生成回答
ini复制代码def transformer_decode(input_ids, attention_mask, max_length=512):
# 使用预训练好的完整GPT模型进行解码生成
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = transformers.GPT2Tokenizer.from_pretrained('gpt2')
output = model.generate(
input_ids=input_ids,
max_length=max_length,
pad_token_id=model.config.eos_token_id,
no_repeat_ngram_size=3, # 控制生成不重复n-gram
do_sample=False, # 开启或关闭采样生成
temperature=1.0, # 控制生成随机性
top_p=1.0, # 设置top-p采样策略(此处设置为1代表使用概率最高的token)
eos_token_id=model.config.eos_token_id, # 指定结束符ID
num_return_sequences=1, # 返回单个序列
truncation=True # 开启截断
)
# 解码生成最终用户看到的文本
responseText = tokenizer.decode(output[0], skip_special_tokens=True)
return responseText
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
