

Gemma 模型的出身
要运行Gemma模型,需要将ollama版本升级到>0.1.26,通过运行ollama的安装。
由于Gemma模型(2b和7b)的大小,其质量将严重依赖于训练数据。从kaggle参考中我们可以读到,它们是在6万亿个令牌上训练的,包括:
- 网络文档:多样化的网络文本确保模型接触到广泛的语言风格、主题和词汇。主要是英语内容。
- 代码:让模型接触代码有助于其学习编程语言的语法和模式,从而提高其生成代码或理解代码相关问题的能力。
- 数学:在数学文本上进行训练有助于模型学习逻辑推理、符号表示,并解决数学查询。
信息检索的使用案例
由于ollama为在本地计算资源上运行LLM提供了一个方便的框架。私人LLM的一个使用案例是根据提供的文档回答问题。
为了使用Gemma 7bn模型执行此任务,需要下载模型的指示版本,这种情况下是从ollama:
arduino复制代码ollama run gemma
模型的其他版本可以从Gemma的标签列表中下载。
在与Mixtral进行此任务的比较中,模型的限制变得可见。这当然是由于70b对7b参数模型的不公平比较。然而,当Gemma 7b模型被用来从文档中检索信息时,它仍然可以执行较简单的搜索任务(检索信息片段,如值或日期),但无法从文档中总结部分,其中它只是声明文档不包含请求的信息。
限制和最佳实践
Gamma在文档信息检索上的行为突显了限制:
- 由于使用的训练数据,理解上下文
- 需要在提示中提供更多的上下文来对抗任务复杂性
- 事实正确性可能会有问题
这个模型的理想使用案例是在文本生成,聊天中。文本总结仍然可能受到上述限制的阻碍。
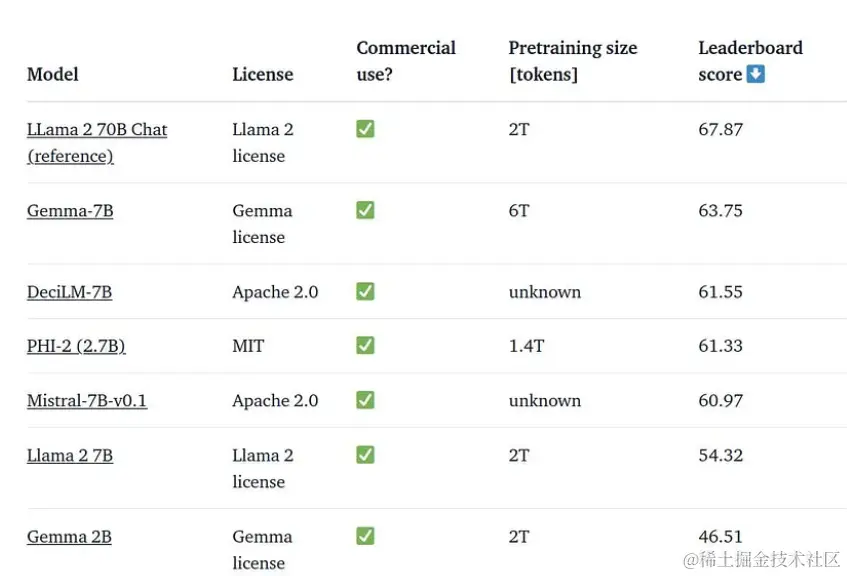
Gemma-7b如何与其它同等参数级别LLM进行比较
像Mixtral这样的大型模型(8x mistral 7b模型的MoE)对于这个任务表现得非常好。然而,在计算资源不那么糟糕的情况下,一个单一的7b参数模型也可能是一个不错的选择。根据一些测试,7b Gemma模型在数学推理方面表现优于其他模型——它可以是总结论文或科学内容的非常方便的模型。
使用Ollama 定制执行特定任务的Gemma模型
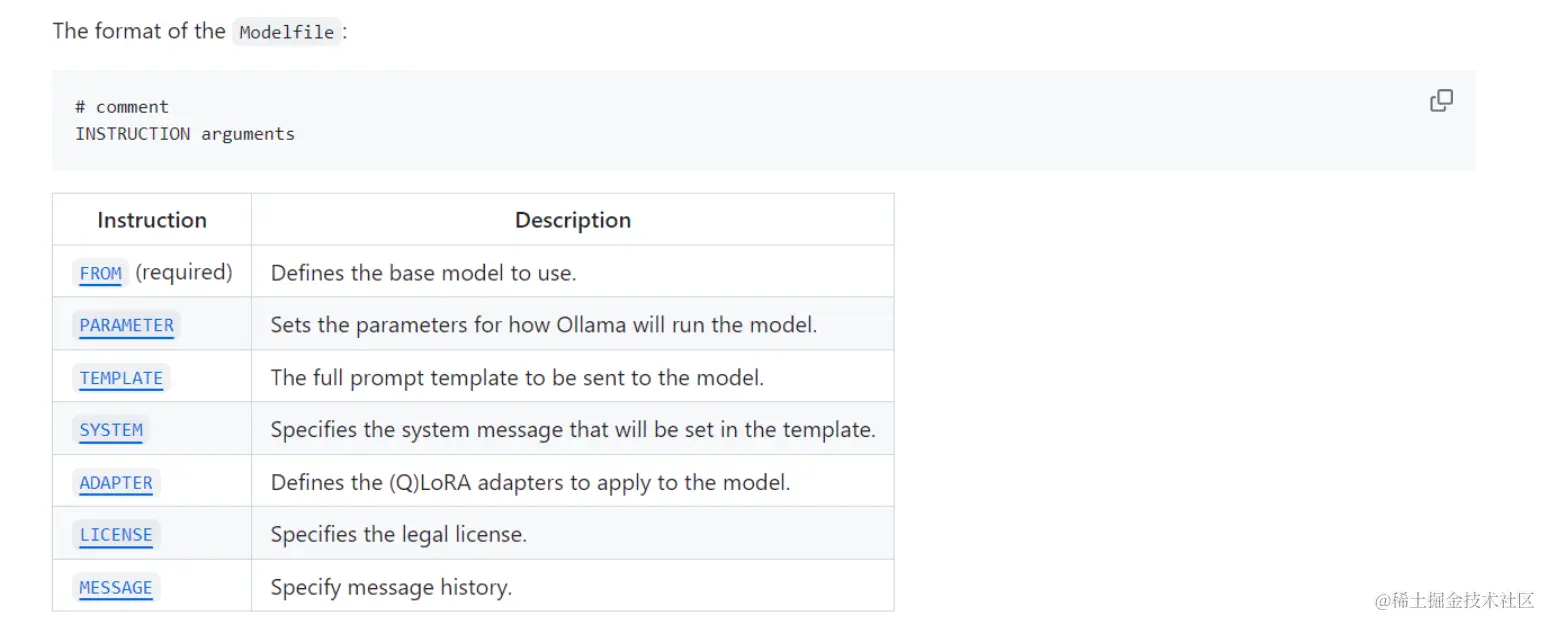
Ollama作为目前最流行的大模型本地化工具,也已经支持Gemma模型的本地化。利用Ollama的Modelfile机制实现Gemma模型的定制化。
通过Ollama modelfile机制创建新的模型或者修改已有的模型,以满足我们特定的应用场景的需求。其机制非常像在Docker应用中的Dockerfile。
其原理是通过指令构建模型,比如可以通过From设定基础模型,同时可以设置一系列的参数,这些参数告诉Ollama该如何运行这个模型。
总结
Gemma模型针对的是那些不需要LLM携带所有知识的使用案例。它专注于在某种程度上受限的情况下运行LLM的用途,无论是批量处理大量请求,还是在本地机器、笔记本电脑、小型服务器上运行一个不错的LLM,因为它的架构提供了更快的推理速度和较低的计算需求。
