

大语言模型 (LLM) 的世界正在快速发展,像 LLAMA2 和 Falcon 这样的突破性模型不断出现。
去年 9 月 27 日,法国初创公司 Mistral 推出了第一个模型 —— Mistral 7B ,引起了科技界的轰动,并获得了迄今为止同类规模中最强大的语言模型的称号。
本文将展示通过 4-bit 量化加载和运行运行 Mistral 7B AI
什么是Mistral 7B?
Mistral-7B-v0.1 是对 Llama 2 等其他 小型 大型语言模型的进一步改进,以相当低的计算成本提供类似的功能(根据一些标准基准)。可适应许多场景,可以执行各种自然语言处理任务,序列长度为 8k。例如,它非常适合文本摘要、分类、文本补全、代码补全。
下面是 Mistral 7B 的特征:
-
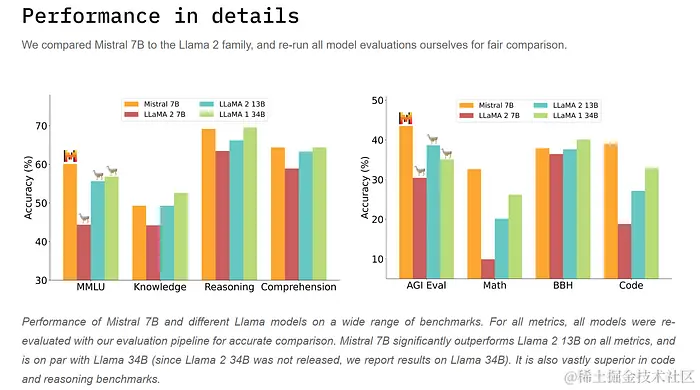
无与伦比的性能:
Mistral 7B在所有基准测试中均优于Llama 2 13B。
-
更高效:得益于分组查询注意力 (GQA) 和滑动窗口注意力 (SWA),
Mistral 7B可以提供更快的推理速度并轻松处理更长的序列。 -
开源:
Mistral 7B在 Apache 2.0 许可证下发布,可以不受限制地使用。
什么是量化 quantization 和 QLoRA?
与同类产品相比,Mistral 7B 可能更小,但让它在消费类硬件中运行和训练仍然是一个巨大的挑战。
为了能在单个 GPU 上运行它,需要以 4-bit 精度运行模型,并使用 QLoRA 来减少内存使用。
QLoRA 解决方案
QLoRA 代表具有低阶适配器的量化 LLM,是一种有效的微调方法。它使用 4-bit 量化来压缩预训练的语言模型,与标准 16-bit 模型微调相比,无需牺牲性能。
QLoRA论文摘要: 我们提出了 QLoRA,这是一种高效的微调方法,可减少内存使用量,足以在单个
48GB GPU上微调65B参数的模型,同时保留完整的16-bit微调任务性能。QLoRA 引入了多项创新技术来节省内存而不牺牲性能:a)4-bit普通浮点型NF4一种新的数据类型,理论上对于正态分布权重来说是最佳信息;b)双量化通过量化量化常数来减少平均内存占用,以及分页优化器来管理内存峰值。
使用步骤
第 1 步:安装必要的软件包
QLoRA 使用 bitsandbytes 进行量化,并与 Hugging Face 的 PEFT 和transformers 库集成。
这里希望确保使用最新功能,将从源代码安装这些依赖库。
ruby复制代码pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
第 2 步:通过 Transformer 的 BitsandBytesConfig 定义量化参数
现在将使用 Transformer 库中的 BitsandBytesConfig 配置 QLoRA 参数。
这里是对可以调整和使用的参数进行说明:
load_in_4bit=True:指定要以4-bit精度转换和加载模型。bnb_4bit_use_double_quant=True:使用嵌套量化来提高内存效率的推理和训练。bnd_4bit_quant_type="nf4":4-bit集成带有 2 种不同的量化类型FP4和NF4。NF4 dtype代表Normal Float 4,在 QLoRA 论文中有介绍。默认情况下,使用FP4量化。bnb_4bit_compute_dype=torch.bfloat16:计算数据类型用于更改计算期间将使用的数据类型。默认情况下,计算数据类型设置为float32,但可以设置为bf16以提高速度。
ini复制代码import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
第 3 步:为 Mistral 7B 加载量化
现在来指定模型 ID,然后使用之前定义的量化配置加载它。
ini复制代码model_id = "mistralai/Mistral-7B-Instruct-v0.1"
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
第 4 步:加载后,运行一代并尝试一下!
最后,准备好将 Mistral 7B 投入使用。
- 首先测试它的文本生成能力,使用以下模板:
ini复制代码PROMPT= """ ### Instruction: Act as a data science expert.
### Question:
Explain to me what is Large Language Model. Assume that I am a 5-year-old child.
### Answer:
"""
device = "cuda:0"
encodeds = tokenizer(PROMPT, return_tensors="pt", add_special_tokens=True)
model_inputs = encodeds.to(device)
generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.eos_token_id)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
该模型遵循了我们的指示,并很好地解释了大语言模型的概念!

- 现在来测试一下 Mistral 7B 的代码能力
ini复制代码messages = [
{"role": "user", "content": "write a python function to generate a list of random 1000 numbers between 1 and 10000?"}"role": "user", "content": "write a python function to generate a list of random 1000 numbers between 1 and 10000?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
device = "cuda:0"
model_inputs = encodeds.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
看来模型完成的代码效果:

总结
从目前模型的发展情况来看,Mistral AI 是 LLaMA 和 Falcon 等流行模型的一个非常不错的替代品。
它是免费的、更小但更高效。它允许完全定制,并且可以轻松微调并具有令人惊喜的性能。
