

突如其来的消息,一夜之间,OpenAI分家的Anthropic公司悄悄地释放出他们的秘密武器——Claude3,这货居然在默默无闻中一举超越了GPT-4的地位。没发布会,没吹牛逼,就发了一帖子。

Anthropic推出了三款模型:Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku。这个命名真是有意思,Opus(超大杯)、Sonnet(大杯)、Haiku(中杯),一看就知道规模大小。
首先得提一句,Claude3的Opus模型似乎在全面碾压GPT-4上拔得头筹。有人搞了个MGSM测试集,也就是多语言数学推理,Claude3 Opus用0-shot的方式达到了90.7%的准确率,而GPT-4居然要用8-shot,结果才74.5%。0-shot就是大模型直接上阵,不给任何示例,8-shot是在上阵前给了8个示例。这区别一看就明显,GPT-4都给了8个示例了还输给了Claude3 Opus。
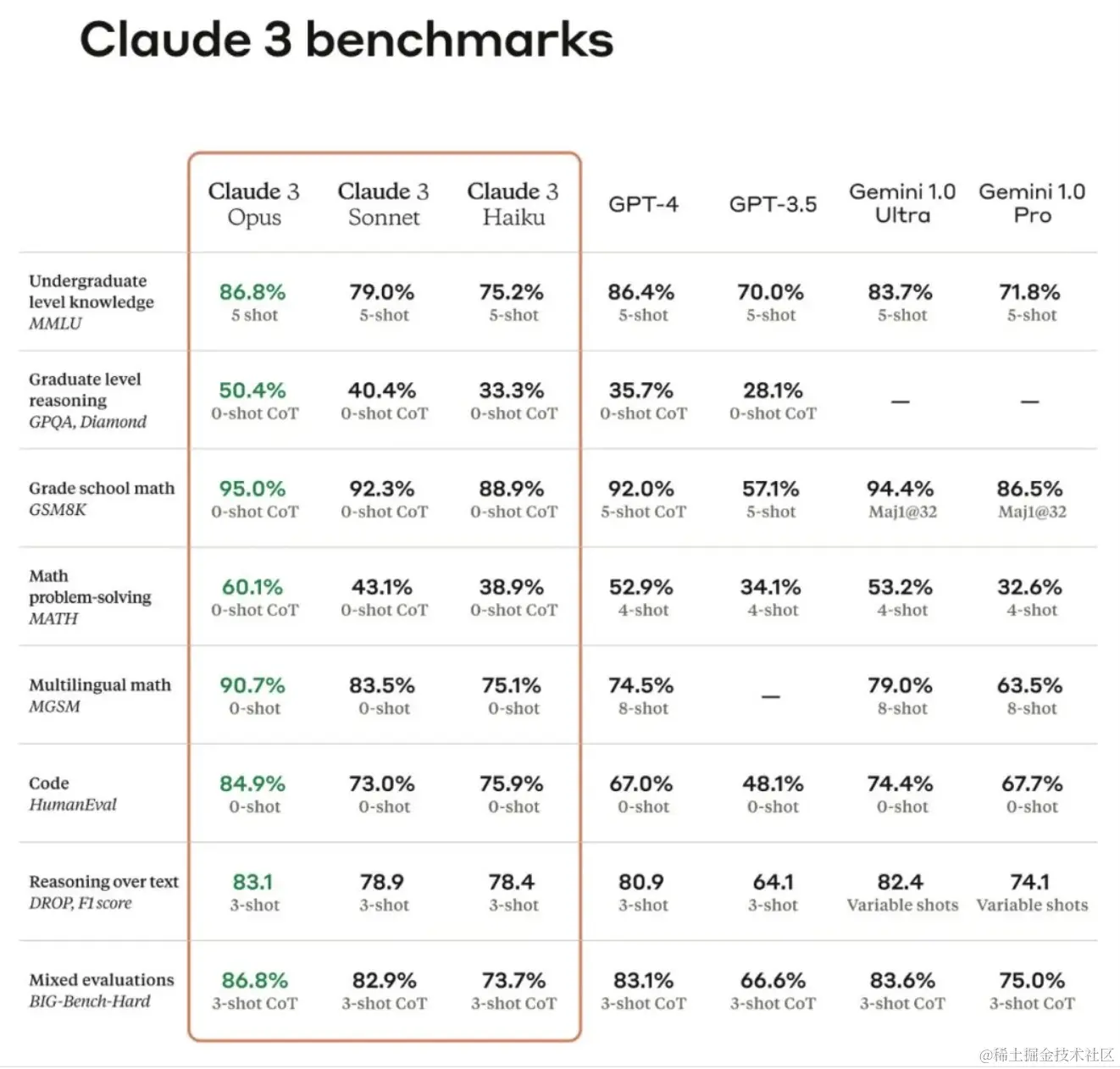
在复杂的推理任务上,Claude3简直就是GPT-4的克星。
再看其他测试集,比如MMLU、GSM8K这些语言知识的测试集,Claude3和GPT-4差不多水平,总体来说,提升主要在推理能力上。
Claude3 Opus,就是个厉害的货。不过有点小插曲,得付费才能玩这个。Anthropic的花样还真跟OpenAI一样,免费的只有Sonnet,Opus得交20刀的会员费才能撸。
对了如果需要,解决无法使用国外银行卡的问题,推荐个平台,整个流程只需要几分钟。
如果不知道怎么使用平台,详细的流程,可以看看这篇文章 详细流程
Claude3最大的进化点,就是推理和逻辑。虽然单看参数你可能感觉不到,但有人专门给了初中的数学题,推理题,等等致命题。在已经明确了补集法的情况下,GPT-4的错误率竟然高达50%。而Claude3 Opus,我测了10遍,准确率高达90%。简直刷新认知。
总体看,Claude在逻辑和推理上的进化巨大,初中的理科题基本上是随便玩,不过高中题还是有点难度,全线阵亡状态。不过,一些看似弱智的问题或者语义逻辑,Claude3已经是无往而不利了。
再说说多模态,GPT-4V也出来很久了,多模态功能可是个把人离不开的好东西。这次Claude3也不甘示弱,把视觉能力给强化了。你可以直接扔图进去。玩了几个小时后,整体评价是,跟GPT-4V大致打平手。官方数据也有这样的倾向。
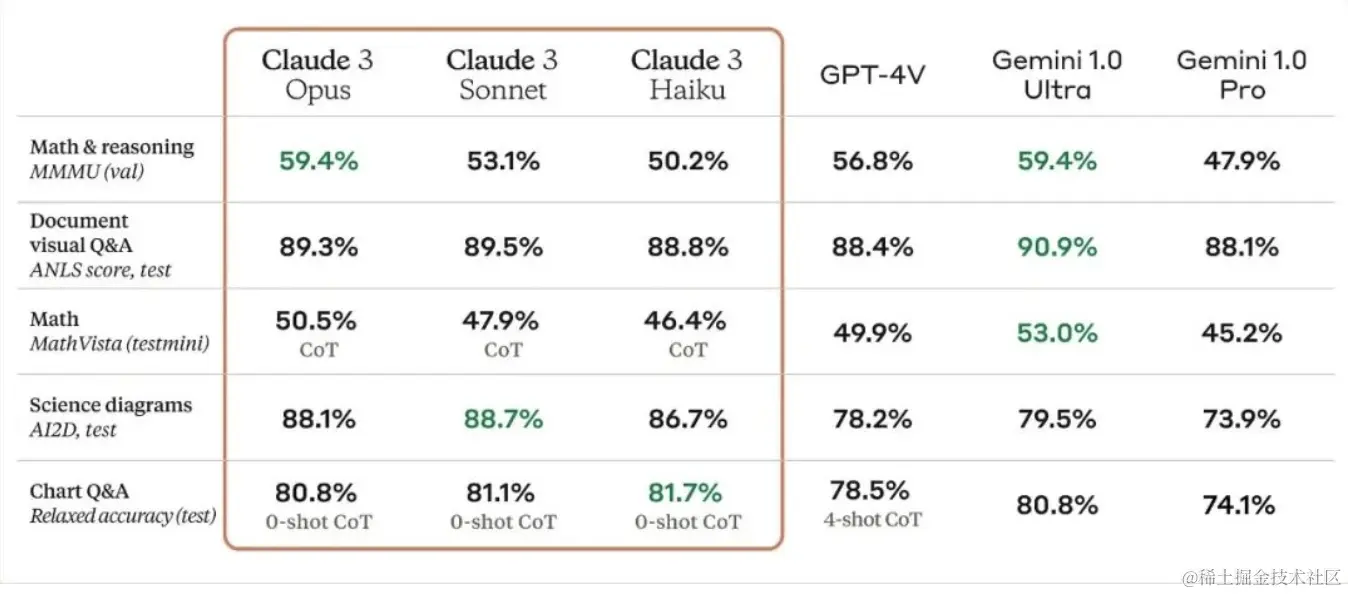
总体上,跟GPT-4V差不多,对中文的支持也不错,算是Anthropic弥补了一直以来Claude的短板。
基于超长文本的对话、总结、查询能力,在Claude3中也终于有了质的飞跃。当然,得说实话,Kimi都在这方面耕耘了差不多半年,Claude3现在也才刚刚赶上Kimi在长文本这块的水平。
但是综合来看,Claude3 Opus,绝对是目前最为水桶的大模型。或者说,就是当前的No.1。
这次更新,Claude3还有一些其他特点。比如减少了不必要的拒绝,准确性更高等等,但是我觉得就不展开说了。Claude3这次更新后,不仅有独一档的推理能力,跟GPT-4V打平的多模态,还有200K长文本优化。
可以当之无愧地说,Claude3 Opus就是市面上目前最强的大模型。
当然,OpenAI和奥特曼的尿性你了解的,他们这肯定忍不了这口气。评论区里,网友说出了我的心声。Anthropic这么一出手,Claude3一露面,GPT-4的地位有点危险了。
未来的竞争,肯定会更加激烈。看看评论区,网友们早就开始猜OpenAI会怎么回应了。Anthropic这一次搞得风生水起,GPT-4的霸主地位真的有点摇摇欲坠。这一场巅峰对决,我可是期待了好久。
