

引言
🧠 随着人工智能驱动的视频创作技术的不断进步,视频内容制作迎来了创新的浪潮。在研究人员和工程师的引领下,人工智能正在不断突破极限,这一变革之旅正在重塑着视频制作的面貌,使之更加自由化。
借助自然语言处理(NLP)和计算机视觉技术的长足进步,现在制作高清视频只需编写简要提示语即可实现。这项技术采用复杂的算法和深度学习模型,能够解释用户输入、生成脚本、识别视觉效果,并模仿人类讲故事。整个过程涉及理解提示语的语义,同时考虑语气、情绪和语境等要素。
📡 继 Runway 的 Gen-2、Stability AI 的 Stable Video Diffusion、Meta 的 Emu 和谷歌的 Lumiere 等文本到视频生成器发布之后,OpenAI 作为 ChatGPT 的创建者又推出了一款最先进的文本到视频深度学习模型,名为 Sora AI。该模型专门用于根据文本提示生成短视频。尽管 Sora AI 尚未向公众开放,但其发布的输出样本已引起了不同的反响,一些人表示了热情,而另一些人则表示了担忧,这是由于其令人印象深刻的质量所致。
🤔 本章内容
🔎 Sora 是什么
🔎 Sora 的新视频
🔎 Sora 的使用案例
🔎 Sora 是如何工作的
🔎 Sora 的局限性
🔎 Lumiere Vs Sora AI 文本到视频工具的比较
🔎 Sora 的道德约束
🔎 Sora 模型采取的安全措施
🔎 结论
Sora 是什么
🧐 Sora AI 是 OpenAI 公司在人工智能领域的最新突破性成果,它标志着多媒体内容创作进入了一个崭新的时代。作为一款先进的文本驱动视频生成工具,Sora AI 能够依据用户的文字输入,创造出流畅且视觉效果逼真的长达一分钟以上的视频内容。这项技术旨在深刻理解并模拟物理世界的复杂动态,使得用户仅通过精炼的文字描述就能够实现视频场景的精准转化和生成。
目前,Sora AI 不仅面向特定团队如Red Teaming开放,供他们用于评估各种场景下的潜在风险和危害,同时也向视觉艺术、设计及电影制作行业的专业人士敞开了大门。他们可以借助 Sora AI 提升工作效率,激发创新灵感,并通过实践反馈协助 OpenAI 不断优化和完善这款模型。
OpenAI 一如既往地秉承其科研理念,积极与外界共享研发进程,使早期用户能够参与到 Sora AI 的测试与迭代中,共同探索这一开创性技术所带来的无限可能性,并在互动过程中预先适应和引导未来人工智能的发展方向。
🪐 例如:
SoraPrompt: A movie trailer featuring the adventures of the 30-year-old spaceman wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.
👽 电影预告片,讲述了这位 30 岁的太空人戴着红色羊毛针织摩托车头盔的冒险经历,蓝天,盐沙漠,电影风格,用 35 毫米胶片拍摄,色彩鲜艳。
SoraPrompt: The animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. The art style is 3D and realistic, focusing on lighting and texture. The mood of the painting is one of wonder and curiosity as the monster gazes at the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.
👽 动画场景的特写镜头是一个短小的毛茸茸的怪物跪在一根融化的红蜡烛旁边。艺术风格是3D和逼真的,专注于照明和纹理。这幅画的情绪是一种惊奇和好奇,因为怪物睁大眼睛和张开嘴巴凝视着火焰。它的姿势和表情传达出一种天真和俏皮的感觉,仿佛它是第一次探索周围的世界。暖色调和戏剧性照明的使用进一步增强了图像的舒适氛围。
⚛️ Sora AI 能生成包含多个角色、特定运动类型以及精确主体和背景细节的复杂场景。该模型能理解用户的提示以及这些元素在物理世界中的存在方式。凭借对语言的深刻理解,Sora AI 能准确解释提示,并创造出表达生动情感的迷人角色。它可以在一个视频中制作多个镜头,保持人物和视觉风格的一致性。
Sora 的新视频
Latest Sora Prompt: A giant, towering cloud in the shape of a man looms over the earth. The cloud man shoots lightning bolts down to the earth.
👾 一朵巨大的、高耸的云,以人的形状笼罩着地球。云人将闪电射向地面。
Latest Sora Prompt: A Samoyed and a Golden Retriever dog are playfully romping through a futuristic neon city at night. The neon lights emitted from the nearby buildings glisten off of their fur.
👾 一只萨摩耶犬和一只金毛猎犬在晚上嬉戏地在一座未来主义的霓虹灯城市中嬉戏。附近建筑物发出的霓虹灯从它们的皮毛上闪闪发光。
Latest Sora Prompt: A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics, and finally, the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer.
👾 一只猫叫醒熟睡的主人要求早餐。主人试图无视猫,但猫尝试了新的策略,最后,主人从枕头下掏出一个秘密的零食藏匿处,让猫多呆一会儿。
Sora 的使用案例
🪐 文字转视频:
- Sora 擅长将文字说明转换成具有视觉吸引力的视频,使用户能够将想法无缝转化为动态的视觉内容。
🪐 图像动画:
- 该模型可以通过对静止图像进行动画处理,为静态视觉效果引入运动和活力,从而使静止图像栩栩如生。
🪐 视频延续:
- Sora 可以扩展现有视频,使场景和叙事无缝衔接,提高讲故事的可能性。
🪐 视频编辑:
- 用户可以利用 Sora 执行视频编辑任务,例如更改视频中的背景或设置,从而展示了它在增强和修改视觉内容方面的多功能性。
🌠 Sora AI 技术的应用潜力非常广泛,超越了简单的文本到视频转换功能。它可以扩展至包括但不限于动画静态图像生成、连续视频片段创造以及高级视频编辑等多领域应用。这意味着无论是平面设计师利用该技术快速将静止设计转化为生动的动画,还是教育工作者为教学内容制作定制化动画以增强学生的学习体验,甚至是建筑学和生物学的学生及专业人士采用 Sora AI 创建概念演示视频或可视化复杂的科学过程,都能从中受益匪浅。
同时,OpenAI 明确意识到随着此类先进技术的普及和发展,相应的伦理和社会风险也随之增加,比如版权问题、虚假信息传播、以及可能带来的劳动力市场变化等。因此,OpenAI 强调与外部各方合作,积极寻求用户反馈和专家意见,以确保技术的安全合理使用,并努力制定相应的指导原则和策略,以减轻潜在负面影响,充分发挥 AI 对人类社会发展的正面作用。
Sora 是如何工作的

Sora 技术依托于 OpenAI 开发的先进 DALL-E 3 技术架构,被赋予“扩散变换器”的称谓,其核心技术采用了基于潜在扩散模型的去噪方法。在这一机制中,Sora AI 利用一个经过精心设计的变换器作为核心组件来执行去噪操作,在潜在的空间维度上逐步构建三维“补丁”,这些“补丁”随后经由专门的视频解码器映射到实际的视频帧序列,从而生成高质量的连续动态视频内容。
为了进一步提升模型性能并丰富训练数据集,Sora 还引入了一项创新的视频转文字技术。该技术能够自动生成详尽且准确的视频字幕,通过对现有视频资源的深度理解和诠释,有效增强了系统的语义理解能力及跨模态学习效果,使得 Sora AI 在动画静态图像生成、连续视频创作乃至视频后期编辑等诸多场景下均展现出卓越的表现。
☄️ 该模型的架构包括视觉编码器、扩散转换器和视觉解码器。
- 视觉编码器可将视频压缩到一个潜空间中,从而降低维度。
- 扩散变换器根据用户提示生成视觉片段序列,然后视觉解码器反转编码,生成最终视频。
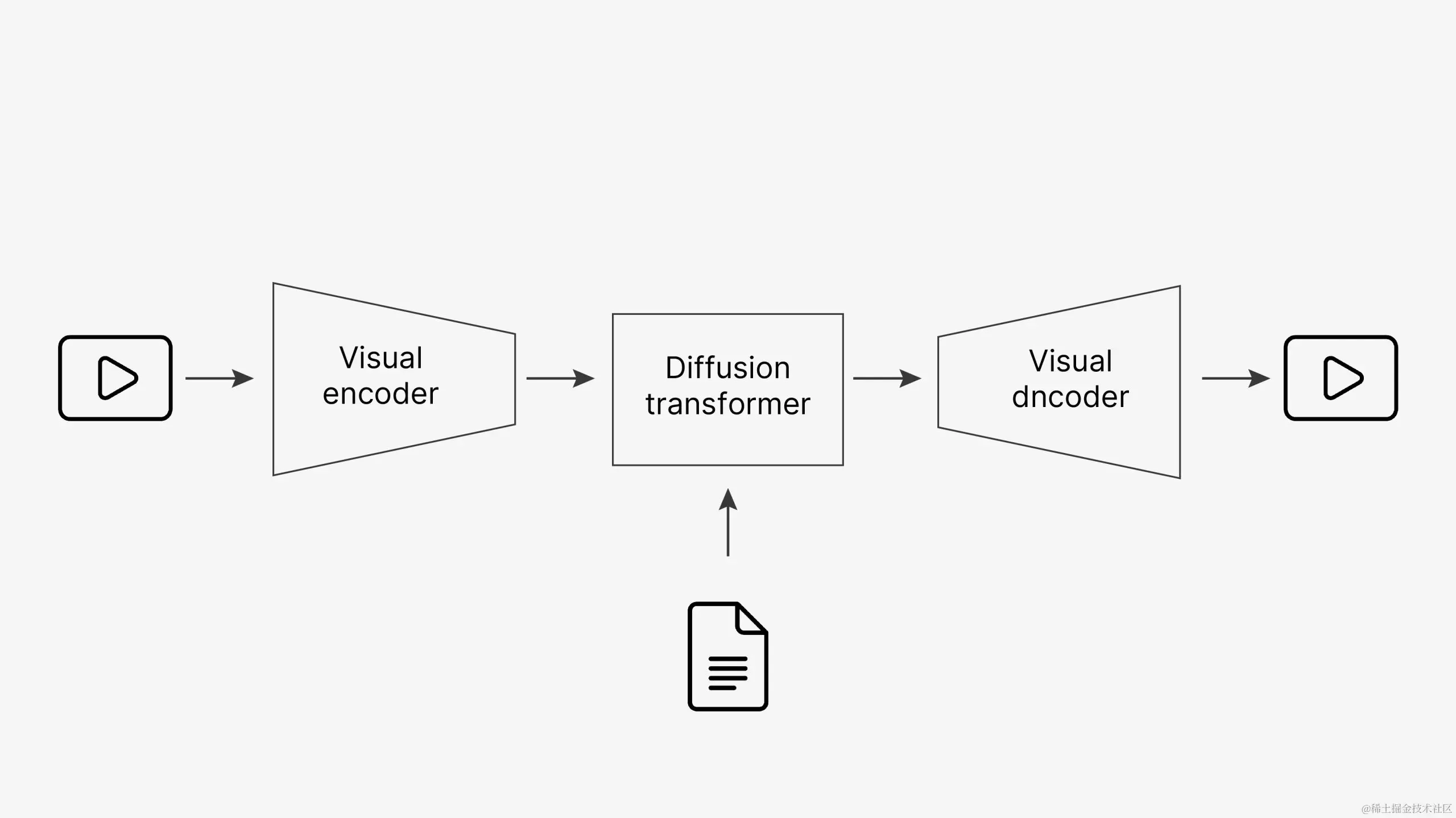
🌌 Sora 的工作原理
🧪 用于图像增强的降噪网络
- Sora 利用去噪网络(denoising network)来消除图像噪点,逐步产生干净和高质量的视觉效果。
- 训练包括对数据集中的干净图像进行编码,并预测添加的噪声,类似于前向扩散过程。
🧪 创新的图像生成技术
- Sora 采用级联扩散和潜在扩散方法生成高分辨率图像。
- starts with a low-resolution image, progressively upsampling to achieve high resolution.
- 级联扩散(Cascade diffusion)从低分辨率图像开始,逐步提高采样率以达到高分辨率。
- 潜像扩散法是将图像压缩为低分辨率的潜像,从而有效地训练去噪网络。
🧪 扩散变压器的灵活性和可扩展性
- Sora 采用扩散变压器,在管理数据和计算资源方面具有灵活性和可扩展性。
- 调整模型大小和标记数量会对视频生成质量产生积极影响。
🧪 高效处理可变图像尺寸
- 在训练过程中,通过将补丁打包成单一序列,可有效处理不同大小的图像。
- 这样,Sora 就能生成不同长宽比的视频,以适应各种分辨率。
🧪 利用重拟字幕技术进行培训
- Sora 依靠《DALL-E 3》中的重新字幕技术,为文本-视频训练对生成描述性字幕。
- 大规模、高质量的数据集对于训练文本到视频模型至关重要。
🧪 长视频生成的不确定方法
- 制作内容一致的长视频的具体方法仍不确定。
- 一种可行的方法是生成一组稀疏的关键帧,并将其作为生成其余内容的条件。
🧪 多种技术提高能力
- Sora 集成了潜在扩散模型(latent diffusion models)、级联演化、重新字幕、扩散转换器和原生视觉转换器,以增强其特定方面的能力。
🧪 卓越的视频生成质量
- Sora 展示了非凡的视频生成质量,具有三维一致性、物体持久性以及与物体的物理交互等特点。
- 尽管在模拟复杂物理场景方面存在局限性,但扩大训练过程已被证明是有效的。
🧪 令人振奋的未来创新
- 技术报告缺乏有关训练数据的详细信息,但 Sora 令人印象深刻的成果让人对未来的创新充满期待。
- Sora 擅长静态图像动画、创建循环视频以及输入视频之间的无缝转换。
🌌 Sora AI 展示了新出现的特性,在 3D一致性、远距离连贯性、物体永恒性、交互性以及模拟整个数字世界等方面展现了一定的理解水平。我们期待未来有更多像 Sora AI 这样的模型出现。

Sora 的局限性
💻 当前版本的 Sora 模型尽管展现出了强大的视频生成能力,但仍存在一定的局限性。尤其是在模拟包含精细物理交互和动态变化的复杂场景时,模型的精确度有所欠缺。比如,在尝试复现一个人咬食饼干这类细节丰富的动作时,Sora 可能无法精确模拟出饼干被咬后应有的形态变化,即可能出现缺失咬痕等不准确的视觉表现。
OpenAI 在训练 Sora 模型时运用了大量的视频数据集,其中包括一部分通过合法授权获取的公共可用视频资源,同时也涵盖了受版权保护的视频片段,但具体的数据规模和来源信息并未向公众公布。
此外,Sora 在处理特定类型的提示时空间定位精准性上存在挑战,如左右方向的认知问题。模型在面对随时间演变的连续事件时,也有可能出现描述不准确的情况,特别是在遵循特定摄像机运动轨迹的情况下。例如,在呈现狼群繁殖后代进而形成庞大群体这样的复杂动态场景时,模型可能难以准确无误地追踪并再现每个时间节点上的画面细节。
Lumiere Vs Sora AI 文本到视频工具的比较
🧲 视频质量:
- Lumiere 最近发布,其视频质量优于前几代产品。
- 另一方面,Sora AI 显示出比 Lumiere 更强大的功能,能够生成最大 1920 × 1080 像素的视频,并具有多种长宽比,而 Lumiere 只能生成 512 × 512 像素的视频。
🧲 视频时长:
- Lumiere 的视频时长限制在 5 秒左右,而 Sora OpenAI 可以创建时长更长的视频,最长可达 60 秒。
🧲 多色合成:
- Lumiere 无法制作多镜头视频,而 Sora 在这方面表现出色。
🧲 视频编辑能力:
- 与其他机型类似,Sora 也具有先进的视频编辑功能,包括从图像或现有视频中创建视频、组合不同来源的元素以及延长视频时长等任务。
🧲 现实主义和认可度:
- 两种模型生成的视频都具有大致逼真的外观,但 Lumiere 的人工智能生成的视频可能更容易识别。
- 而 Sora 的视频则呈现出一种动态的特质,各元素之间的互动性增强。
在决定选用Lumiere还是Sora OpenAI时,用户应当考虑自身对于视频质量、时长以及后期编辑灵活性的需求。两者作为前沿的人工智能驱动视频生成工具,均在实际应用中表现出卓越性能,但也偶有输出结果不一致或产生非真实感的反馈。随着技术的迭代升级,这两种模型所存在的局限性有望得到逐步克服,并进一步推动AI视频创作行业的整体进步。
尤其值得一提的是,OpenAI研发的Sora模型在场景构建与视觉布局方面展现出更先进的能力,允许用户按照不同设备屏幕尺寸和原生长宽比的要求,轻松创造出适应性极强且保持高质量的画面内容。这意味着使用Sora不仅能够实现多样化的视频生成,还能确保在跨平台分发时视频内容的美学效果与观看体验得以优化。
🛰️ 另请阅读:Google Lumiere:通过逼真的视频合成改变内容创作。
Sora 的道德约束
Sora 模型引起了人们对其可能被滥用于生成有害内容的严重关切,包括但不限于以下内容:
🔭 制作色情内容:
Sora AI 能够根据文字提示生成逼真、高质量的视频,这可能会带来制作露骨或色情内容的风险。恶意用户可能会利用该模型制作不恰当、剥削性和有害的内容。
🔭 传播假新闻和虚假信息:
Sora AI 的文本到视频功能可被滥用于制造令人信服的假新闻或虚假信息。例如,该模型可以生成逼真的政治领导人虚假言论视频,传播错误信息,并可能损害公众的看法和信任。
🔭 创建危害公共卫生措施的内容:
Sora AI 能够根据提示生成视频,这引起了人们对制作与公共卫生措施相关的误导性内容的担忧。恶意行为者可能会利用该模型制作视频,阻止接种疫苗、宣传虚假疗法或破坏公共卫生准则,从而危及公共安全。
🔭 引发不和谐和社会动荡的可能性:
Sora OpenAI 生成的视频的逼真性可能会被用来制作煽动不和谐和社会动荡的内容。例如,该模型可生成虚假暴力、歧视或动乱视频,从而导致紧张局势和潜在的现实后果。
OpenAI 预计 Sora 会对创造力产生重大影响,但也承认有必要解决安全威胁。道德问题包括模型训练数据的透明度、版权问题和权力集中,因为 OpenAI 对人工智能创新产生了重大影响。
虽然 Sora 的潜力巨大,但 OpenAI 对强大人工智能模型的垄断引发了人们对更广泛的人工智能领域的透明度、问责制和道德考量的担忧。不过,OpenAI 意识到了滥用的可能性,并正在采取措施解决安全问题。
🛰️ 另请阅读:2024 年将使用的 11 种人工智能视频生成器: 将文本转换为视频。
Sora 模型采取的安全措施
OpenAI 在其产品中发布 Sora 模型之前,正在实施几项关键的安全措施。关键点包括
🧰 Red Teaming
OpenAI 与错误信息、仇恨内容和偏见方面的Red Teaming和专家合作。
这些专家将进行对抗测试,以评估模型的稳健性并识别潜在风险。
🧰 误导性内容检测工具
OpenAI 正在开发包括检测分类器在内的工具,以识别 Sora 生成的误导性内容。
目标是加强内容审查,并在区分人工智能生成的内容和真实内容时保持透明度。
🧰 C2PA 元数据集成
OpenAI 计划将 C2PA 元数据纳入其产品的未来模型部署中。
该元数据将作为额外的信息层,用于显示 Sora 模型是否生成了视频。
🧰 利用现有安全方法
OpenAI 正在利用已为使用 DALL-E 3 的产品建立的安全方法,这些方法与 Sora 相关。
这些技术包括文本分类器,用于拒绝违反使用政策的提示;图像分类器,用于审查生成的视频帧是否符合政策。
🧰 与利益相关者合作
OpenAI 将在全球范围内与政策制定者、教育工作者和艺术家进行接触,以了解他们所关心的问题并确定积极的使用案例。
目的是收集不同的观点和反馈,为负责任地部署和使用该技术提供依据。
🧰 真实世界学习方法
尽管进行了广泛的研究和测试,OpenAI 仍然承认技术使用的不可预测性。
从真实世界的使用中学习对于不断提高人工智能系统的安全性至关重要。
结论
简而言之,Sora AI 是一种扩散模型,它通过逐步转换静态噪声来生成视频。它可以同时生成整个视频,扩展现有视频,即使在暂时脱离视线的情况下也能保持主体的连续性。与 GPT 模型类似,Sora 也采用了变压器架构,以获得卓越的缩放性能。视频和图像以补丁的形式表示,允许扩散变换器在更广泛的视觉数据上进行训练,包括不同的持续时间、分辨率和长宽比。
在 DALL-E 和 GPT 研究的基础上,Sora 采用了 DALL-E 3 中的重构技术,提高了生成视频中用户文本指令的保真度。该模型可以根据文本指令创建视频,准确地为静态图像制作动画,并通过填充缺失的帧来扩展现有视频。Sora 是通过理解和模拟现实世界实现人工通用智能(AGI)的基础性步骤。
🖥️ 参考链接:
Sora OpenAI :openai.com/sora
OpenAI 视频生成模型: openai.com/research/vi…
