


AI 时代的到来,可以做和想象的事情很多,不管是什么类型的场景,宗旨主要是提高效率。构建自己的 DevSecOps 知识库,可以在保障数据安全性和效率。而使用 OpenAI、LangChain 和 LlamaIndex 等技术是可以帮助更好地构建一个强大的知识库,以支持 DevSecOps 实践。借助这些技术可以自动化文本分析、翻译、归类和搜索等任务,从而节省时间和精力。
DevSecOps 对于开发者来说,是日常工作的重要组成部分,喜欢在 DevSecOps 领域学习并通过博客与他人分享知识。通常,发现自己在文章中搜索需要的信息。为 DevSecOps 构建自己的自定义知识库,以便可以将文件或文章提供给它并在需要时进行搜索。
在本文中,将探索使用 OpenAI、LangChain 和 LlamaIndex(GPT 索引)构建自定义 DevSecOps 知识库。
- 文章涉及的内容在Github仓库:github.com/QuintionTan…
整体架构
首先将文章文件提供给知识库,然后,使用与 DevSecOps 相关文章文件中的问题查询知识库。整理架构分为两个阶段:
数据摄取/索引
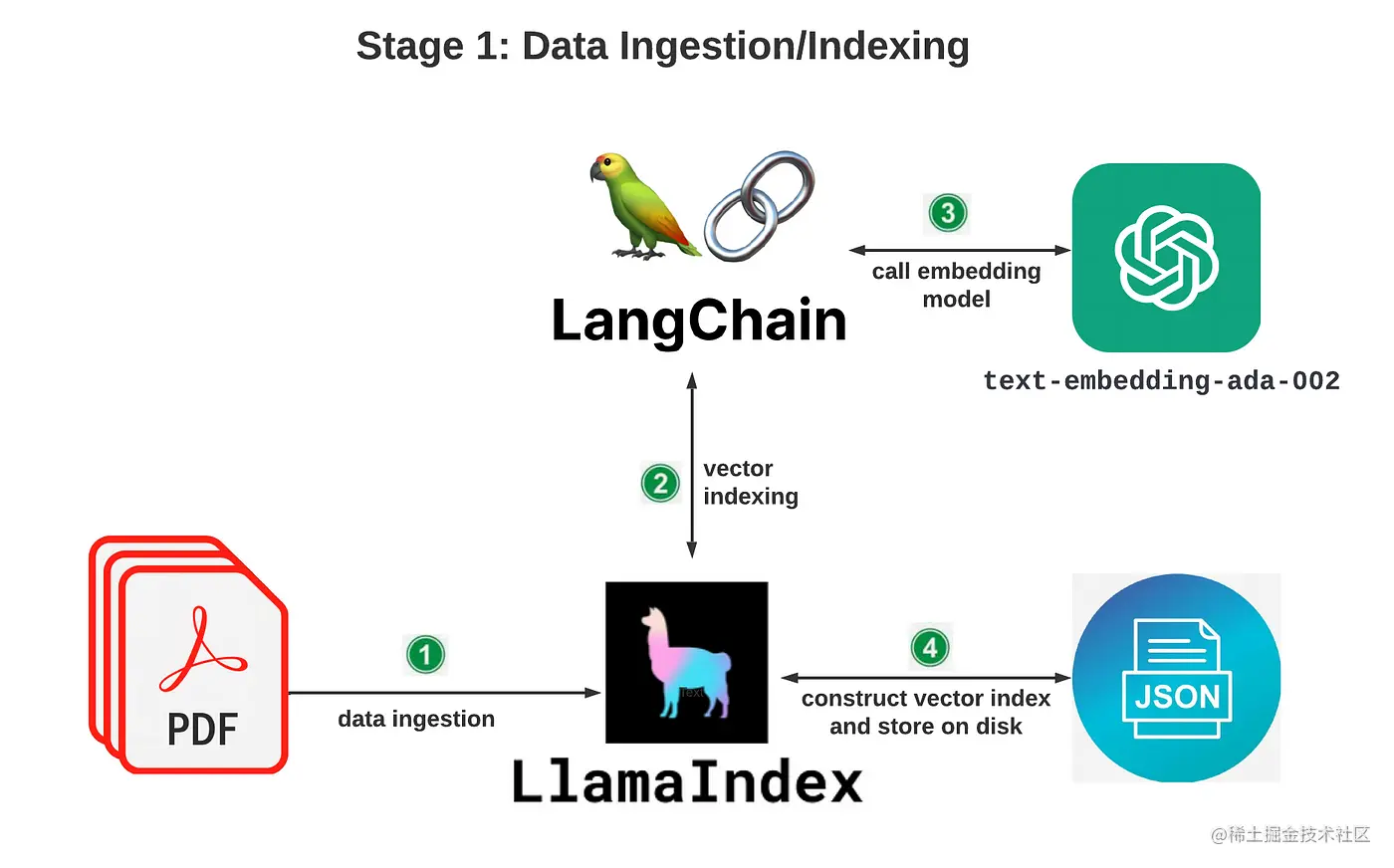
数据查询
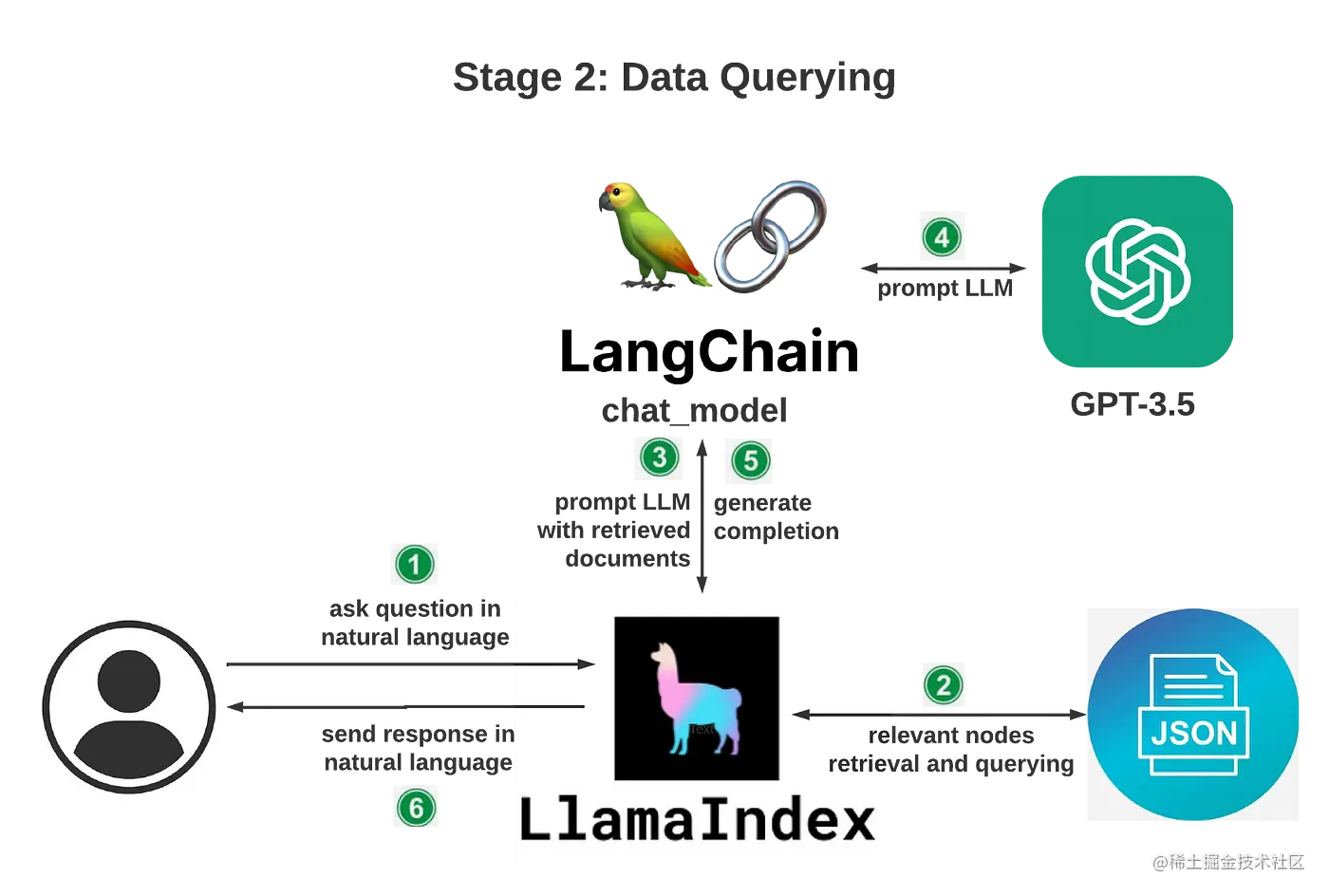
下面就开始构建知识库。
环境准备
Python 安装:这是 AI 应用开发必备的环境之一,环境的配置就不做介绍了。如果没有,请参考 Python 下载页面下载安装 Python。确保通过运行以下命令将 pip 升级到最新版本:
复制代码python -m pip install -U pip
OpenAI API 密钥:打开 OpenAI 的官网的 API 密钥页面生成一个新的 API 密钥(如果还没有)。建议通过使用限制页面设置使用限制相关信息以便更好的控制支出。
创建项目目录,命名为 AI-DevSecOps,打开终端,在项目目录下执行命令创建一个虚拟环境:
复制代码python -m venv venv
接下来执行以下命令使其环境生效:
bash复制代码source venv/bin/activate
为了训练自定义 DevSecOps 知识库,需要安装一些依赖库,运行命令:
ini复制代码pip install openai langchain llama_index==0.6.12 pypdf PyCryptodome gradio
注意:命令中为
llama_index指定了0.6.12版本。在不指定版本的情况下,它将安装最新版本0.7.22。
简单介绍一下安装的依赖库。
openai
使用 OpenAI 库有两个目的:
- 数据摄取/索引:如上面的架构图所示,将在底层通过 LangChain 调用 OpenAI 的嵌入模型
text-embedding-ada-002。 - 数据查询:调用 OpenAI 的
GPT-3.5 LLM(大语言模型)。GPT-3.5模型可以理解并生成自然语言或代码。GPT-3.5的模型gpt-3.5-turbo是最强大和最具成本效益的模型。
langchain
LangChain 是一个开源库,为开发人员提供必要的工具来创建由 LLM 提供支持的应用程序。它是一个围绕 LLM 构建的框架,可用于聊天机器人、生成式问答 (GQA)、摘要等。LangChain 的核心思想是开发人员可以将不同的组件像 链 一样串在一起,以围绕 LLM 创建更高级的示例。
LangChain 提供了一系列模块,这些模块是作为任何 LLM 支持的应用程序构建块的核心抽象。这些模块包括模型、提示、内存、索引、链、代理和回调。对于知识库聊天机器人,将使用 LangChain 的 chat_models 模块。
llama_index
LlamaIndex 使用 LangChain 的 LLM 模块并允许自定义底层 LLM。LlamaIndex 是一个强大的工具,提供了一个中央接口来将 LLM 与外部数据连接起来,并允许根据提供的数据创建一个聊天机器人。使用 LlamaIndex,无需成为 NLP 或机器学习专家,只需要提供希望聊天机器人使用的数据,LlamaIndex 会处理剩下的事情。正如 LlamaIndex 的创建者 Jerry Liu 所述,LlamaIndex 以易于使用的方式提供以下工具:
- 提供数据连接器以获取现有的数据源和数据格式(API、PDF、文档、SQL 等)
- 提供构建数据(索引、图表)的方法,以便这些数据可以轻松地与 LLM 一起使用。
- 为数据提供高级检索/查询界面:输入任何 LLM 输入提示,取回检索到的上下文和知识增强输出。
- 允许与外部应用程序框架(例如:LangChain、Flask、Docker、ChatGPT 或其他任何东西)轻松集成。
pypdf+PyCryptodome
pypdf 是一个免费开源的纯 python PDF 库,能够拆分、合并、裁剪和转换 PDF 文件的页面。本文将使用这个库来解析 PDF 文件。 PyCryptodome 是另一个有助于在解析 PDF 文件时防止错误的库。
gradio
Gradio 是一个开源 Python 包,可以通过几行代码为 ML 模型、任何 API 甚至任意 Python 函数快速创建易于使用、可自定义的 UI 组件。可以将 Gradio GUI 直接集成到 Jupyter Notebook 中,或将其作为链接与任何人共享。本文将使用 Gradio 为知识库构建一个简单的 UI。
添加数据源
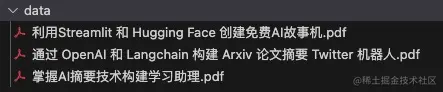
测试数据源这里就使用之前发布过的三篇博客。
- 《利用Streamlit 和 Hugging Face 创建免费AI故事机》
- 《通过 OpenAI 和 Langchain 构建 Arxiv 论文摘要 Twitter 机器人》
- 《掌握AI摘要技术构建学习助理》
编写 Python 代码
网上有很多用于构建自定义聊天机器人的开源 Python 教程,有些包含过时的代码,是在旧版本的库上构建的,很难让它们按预期的方式运行。建议按照LlamaIndex Usage Pattern 上的说明作为基本框架,然后添加自己的逻辑。
第 1 步:导入模块和类
javascript复制代码from llama_index import StorageContext, ServiceContext, GPTVectorStoreIndex, LLMPredictor, PromptHelper, SimpleDirectoryReader, load_index_from_storage
from langchain.chat_models import ChatOpenAI
import gradio as gr
import sys
import os
SimpleDirectoryReader、LLMPredictor、PromptHelper、StorageContext、ServiceContext、GPTVectorStoreIndex和load_index_from_storage都是来自llama_index模块的类。ChatOpenAI是langchain.chat_models模块中的一个类。gradio是用来创建WEB界面的库。sys和os是用于系统相关操作的标准 Python 模块。
第 2 步:使用
os.environ["OPENAI_API_KEY"]将 OpenAI 的 API 密钥设置为环境变量。需要将YOUR-OPENAI-API-KEY替换为实际 OpenAI API 密钥才能正常工作。
lua复制代码os.environ["OPENAI_API_KEY"] = 'YOUR-OPENAI-API-KEY'
第 3 步:定义函数
data_ingestion_indexing(directory_path),这个函数负责提取数据,并在知识库中创建和保存用于数据查询的索引。
ini复制代码def create_service_context():
# 参数配置
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
# 允许用户显式设置某些参数配置
prompt_helper = PromptHelper(
max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
# LLMPredictor 是 LangChain 的 LLMChain 的包装类,可以轻松集成到 LlamaIndex 中
llm_predictor = LLMPredictor(llm=ChatOpenAI(
temperature=0.5, model_name="gpt-3.5-turbo", max_tokens=num_outputs))
# 构造 service_context
service_context = ServiceContext.from_defaults(
llm_predictor=llm_predictor, prompt_helper=prompt_helper)
return service_context
def data_ingestion_indexing(directory_path):
# 从指定目录路径加载数据
documents = SimpleDirectoryReader(directory_path).load_data()
# 第一次建立索引时
index = GPTVectorStoreIndex.from_documents(
documents, service_context=create_service_context()
)
# 持久化索引到磁盘,默认 storage 文件夹
index.storage_context.persist()
return index
下面就来简单解释一下代码:
- 定义了一个名为
create_service_context的函数,创建ServiceContext,一个用于LlamaIndex索引和查询类的实用容器。该容器包含通常用于配置每个索引和查询的对象,如LLMPredictor(用于配置 LLM,它是 LangChain 的 LLMChain 的包装类,可以轻松集成到 LlamaIndex 中),PromptHelper(允许用户显式设置某些约束参数,例如最大输入大小、生成的输出标记数、最大块重叠等)、BaseEmbedding(用于配置嵌入模型)等。 - 使用
SimpleDirectoryReader从指定的目录路径加载数据。 - 它使用加载的文档创建
GPTVectorStoreIndex实例,并通过调用函数create_service_context()创建service_context。 - 最后,调用
storage_context并将索引持久化到默认存储文件夹下的磁盘,并返回索引对象。
第 4 步:定义函数
data_querying(input_text),这个函数是知识库逻辑的核心。
ini复制代码def data_querying(input_text):
# 重建存储上下文
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# 从存储加载索引
index = load_index_from_storage(
storage_context, service_context=create_service_context())
# 用输入文本查询索引
response = index.as_query_engine().query(input_text)
return response.response
- 重建存储上下文
- 从存储中加载索引。由于使用自定义的
ServiceContext对象初始化了索引,因此还需要在load_index_from_storage期间传入相同的ServiceContext。 - 使用
index.as_query_engine().query()使用输入文本查询索引。 - 返回从索引收到的响应。
第 5 步:通过创建
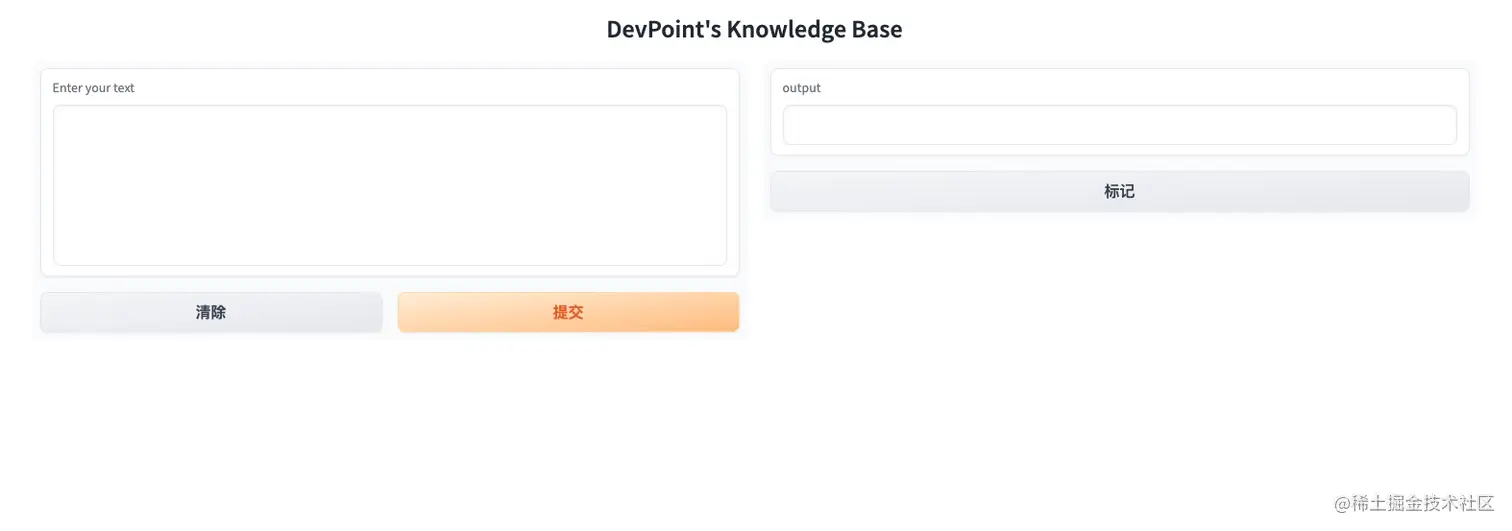
gr.Interface实例来定义 UI。
ini复制代码iface = gr.Interface(fn=data_querying,
inputs=gr.components.Textbox(
lines=7, label="Enter your text"),
outputs="text",
title="DevPoint's Knowledge Base")
fn参数设置为前面定义的data_querying函数。inputs参数指定一个文本框输入组件,有7行用于输入文本。outputs参数指定输出将基于文本。title参数设置网页界面的标题。
第 6 步:使用参数数据调用
data_ingestion_indexing函数以创建和保存索引。请注意,此数据目录是存储 PDF 文档的地方。如果想以不同的方式命名目录,可以在此处相应地进行更改。
ini复制代码#passes in data directory
index = data_ingestion_indexing("data")
第 7 步:
iface.launch(share=False)启动 UI,使聊天机器人可以通过WEB浏览器访问。
可以选择将 share 设置为 True,这允许 Gradio 创建共享链接,以便可以与他人共享知识库聊天机器人。
启动 DevSecOps 知识库
现在已经准备好自定义 PDF 文件和代码,打开终端,在 AI-DevSecOps 目录中运行以下命令来启动 DevSecOps 知识库:
复制代码python bot.py
启动新知识库的用户界面:http://127.0.0.1:7860/。
输入一下简单的问题:
问:AI机器人使用什么技术
复制代码回答:AI机器人使用的技术包括arXiv API、LLMChain和Langchain代理。
在 PDF 的内容中,有一遍博客用到了 arXiv API。
问:AI 助理可以用来做什么?使用什么技术架构?
复制代码回答:根据上述上下文信息,AI助理可以用来进行多种任务,包括生成论文摘要和故事机。技术架构方面,论文摘要的AI助理使用了arXiv API、LLMChain和Langchain代理进行信息检索、摘要生成和发布过程。而故事机的AI助理则利用了Streamlit和Hugging Face开源语言模型。
- 文章涉及的内容在Github仓库:github.com/QuintionTan…
AI 机器人会把隐私数据暴露给 OpenAI 吗?
答案是否定的。根据 API 上的 OpenAI 隐私政策:
OpenAI 不会使用客户通过 API 提交的数据来训练 OpenAI 模型或改进 OpenAI 的服务产品。
两个函数,用于数据摄取/索引的 data_ingestion_indexing 和用于问答的 data_querying,都通过 LangChain 调用 OpenAI API,因此可以放心,OpenAI 不会根据上述 API 的隐私政策使用私人数据。
关于成本
可能已经知道,使用 OpenAI 模型确实会产生费用。在用例中,在数据摄取/索引期间使用它的嵌入模型,并在数据查询中使用聊天模型。以下是定价详情:
- 对于嵌入模型
text-embedding-ada-002:$0.0004 / 1KToken - 对于聊天模型
gpt-3.5-turbo:$0.002 / 1KToken
如果打算使用 OpenAI LLM,强烈建议在 OpenAI 的使用限制页面上配置使用限制,可以在其中定义硬限制和软限制,以便妥善管理使用情况。
总结
本文探讨了如何构建定制的 DevSecOps 知识库聊天机器人。这仅仅是一个概念证明。将 LlamaIndex 和 LangChain 结合到构建通过私人数据利用 LLM 力量的应用程序中的潜力是无限的!
