
前段时间一直在思考自己应该做点 AI 相关的事情,思考来思考去想法挺多的,但一直都没有付诸实际。不是觉得太难不想动手,就是觉得太简单不值得动手。直到 6 月,自己小有觉悟,觉得即使再容易,也得动手才行。于是,准备从简单的开始,复刻一个 EmojiSearch 的 Android 版本。
体验地址:www.emojisearch.app/ 产品的功能简单易懂:输入一段描述,来找到对应的 Emoji 表情
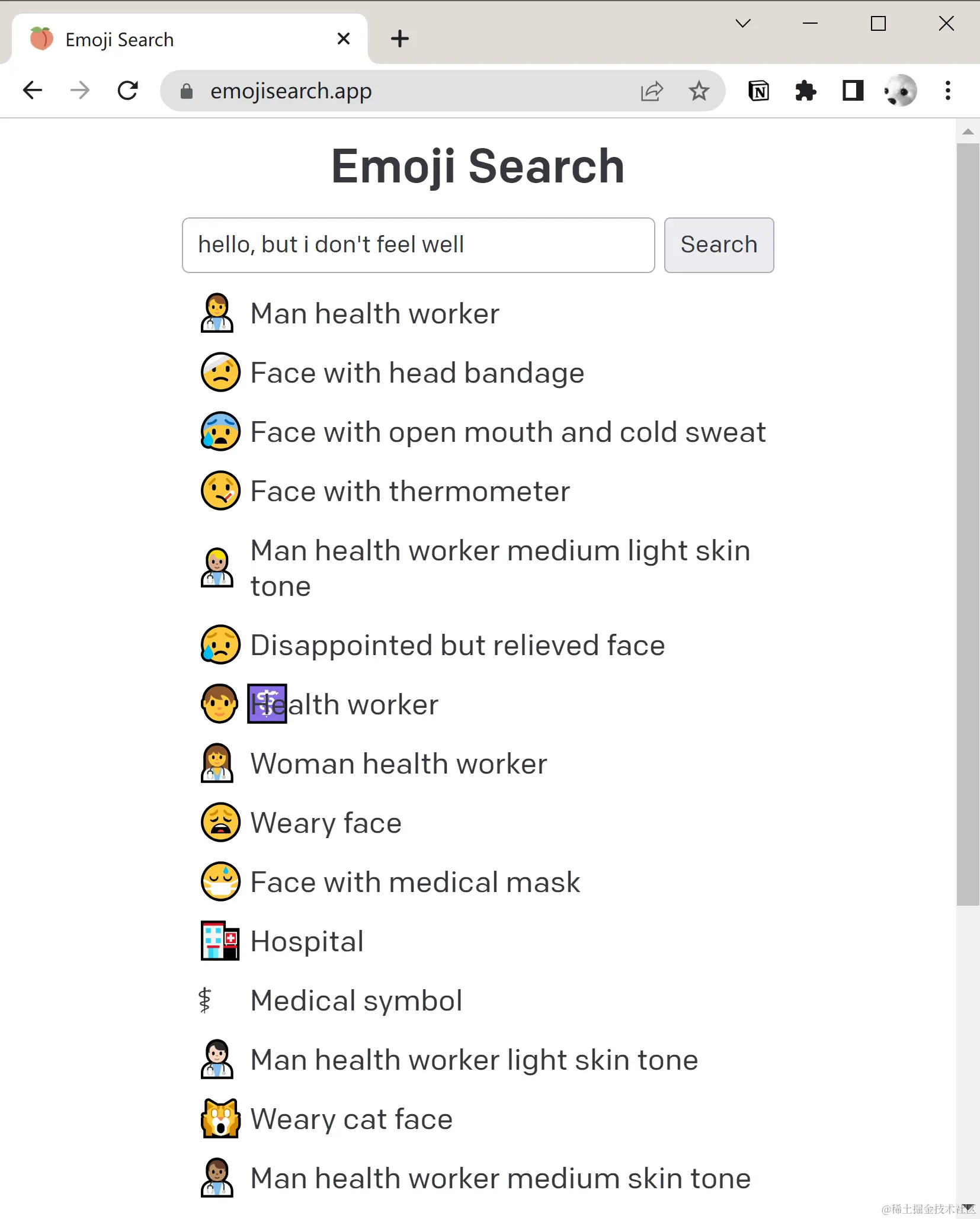
事实证明,要做好一个类似的产品,是不容易的,前前后后经历了 2 个月,95h 的工作量。如果只需要做出来,我想一周足够了,但是如果想做好,那么就得考虑到产品的方方面面。如何节约成本、如何提升用户体验、如何缩减包体积等等,接下来我会和大家一一讨论。当然,我做的肯定还不够,还有很多可以改进的地方,也欢迎大家在评论区告诉我~
文章写完,发现自己描述的还是比较简单易懂的。但如果想知道,为什么我前前后后花了两个月来做这件事情,可以移步文章最后的待优化及踩坑项一探究竟。
在开始之前,我还想啰嗦两句,关于为什么选择做这个 Project。首先这个 Project “看起来” 比较简单,网页版的作者是 lilianweng,自己在 18 年拜读大佬 Policy Gradient 的 blog,受益匪浅(云里雾里)。想着在大佬搭好的脚手架上做,应该不成问题。
APP 功能预览

体验 APP 下载:github.com/sunnyswag/e…
License:MIT License
项目时序简介
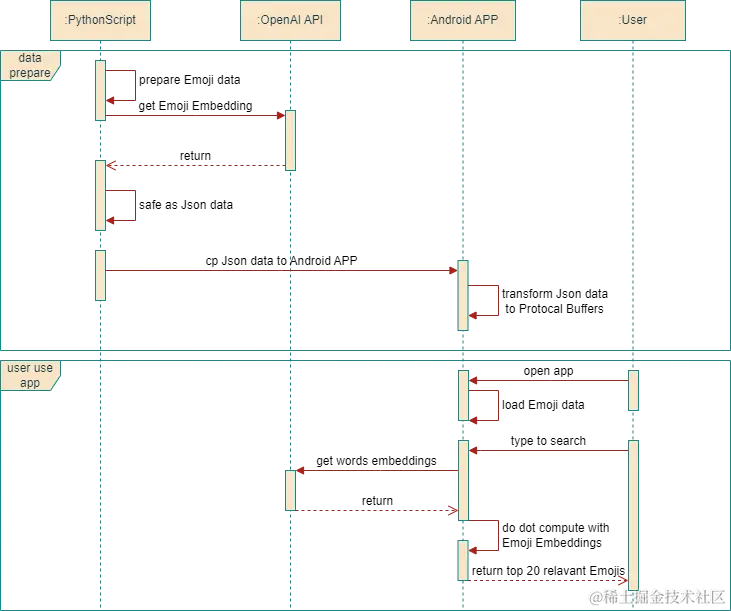
项目的构建分为两个部分,准备数据和构建 Android APP,具体的步骤如下:
- 准备数据
- 用 Python 来解析并获取到 Emoji 的数据
- 向 OpenAI 发送 POST 请求,获取 Emoji 的 Embedding 数据
- 将 Emoji 数据保存为 Json 格式的文件
- 将数据复制到 Android APP,并将数据转换为 Protocol Buffers 的格式
- 构建 Android APP
- 加载 Emoji 数据到内存
- 处理用户输入,拿到用户输入的 Embeddings
- 将 Embeddings 和 Emoji 的 Embedding 做点积运算,得到前 20 个最相关的 Emoji
接下来,我们将会按照项目的构建步骤来一一了解,项目是怎么一步一步构建完的。
数据准备
解析获取 Emoji 数据
Emoji 的数据来源有两个,一个是 UniCode 官网,另外一个是 Python 的 emoji 库,在拿到这两部分的数据之后对 Emoji 数据进行整合,得到如下格式的数据:
json复制代码emojis_full_msg_dedupe = {
"😄": "grinning face",
"😃": "grinning face with big eyes",
"😁": "beaming face",
// other emojis...
}
将如上的数据再转换成自然语言的描述,作为 embedding 的输入数据:
csharp复制代码The emoji 😄 is about grinning face.
The emoji 😃 is about grinning face with big eyes.
The emoji 😁 is about beaming face.
如上解析操作的代码可以查看 build_emoji_data.py/extract_emo…
获取 Emoji 的 Embedding 数据
获取 Embedding 数据其实也比较简单,实现起来就是 Python 对 OpenAI API 的调用:
python复制代码def get_embeddings(inps: List[str], batch: int=1000) -> List[List[float]]:
i = 0
outputs = []
while i < len(inps):
result = openai.Embedding.create(input=inps[i:i+batch], model=EMBEDDING_MODEL)
outputs += [x["embedding"] for x in result['data']]
i += batch
assert len(outputs) == len(inps)
return outputs
保存 Emoji 数据为 Json 格式的文件
最后输出的数据格式为如下,保存为 json.zip 格式即可
json复制代码// 文件行数为:3753
// embed 向量维度为:1536
{"emoji": "ud83eudd47", "message": "1st place medal", "embed": [-0.018469301983714104, -0.004823130089789629, ...]}
{"emoji": "ud83eudd48", "message": "2nd place medal", "embed": [-0.023217657580971718, -0.0019081177888438106, ...]}
将 Emoji 数据转换为 Protocol Buffers 格式
由于 Protocol Buffers 是二进制格式的文件,比基于文本存储的 Json 文件占用空间更小,读取速度也更快。所以在移动设备上,我这里选择使用 Protocol Buffers 格式进行存储。具体的测试及对比结果,可以查看之前写的 Android 当你需要读一个 47M 的 json.gz 文件。
这里我们使用 Kotlin 实现一下 Json → Protocol Buffers 的转换,Why Kotlin?,可以查看一下 待优化及踩坑项。
kotlin复制代码private val pbEntityCollection = mutableListOf<EmojiEmbeddingOuterClass.EmojiEmbedding>()
override suspend fun process(context: Context) = withContext(Dispatchers.IO) {
context.resources.openRawResource(R.raw.emoji_embeddings_json).use { inputStream ->
GZIPInputStream(inputStream).bufferedReader().useLines { lines ->
lines.forEach { line ->
val entity = gson.fromJson(line, EmojiEmbeddingEntity::class.java)
val pbEntity = EmojiEmbeddingOuterClass.EmojiEmbedding.newBuilder()
.setEmoji(entity.emoji)
.setMessage(entity.message)
.addAllEmbed(entity.embed.toList())
.build()
pbEntityCollection.add(pbEntity)
}
}
}
saveToProtoBuf(context)
}
private fun saveToProtoBuf(context: Context) {
val fileStream = context.openFileOutput("emoji_embeddings_proto.gz", Context.MODE_PRIVATE)
GZIPOutputStream(fileStream).use { gzipOutputStream ->
try {
pbEntityCollection.forEach {
it.writeDelimitedTo(gzipOutputStream)
}
} catch (e: IOException) {
e.printStackTrace()
}
}
}
这里的代码阅读起来我想应该是不难的,比较关键的是 writeDelimitedTo 这个方法,它会将当前字段的长度存储在字段的头部,方便之后的读取工作。
Android APP 的构建
加载 Emoji 数据
因为 Emoji 的数据必须 APP 启动后就可以读取到,所以我使用了 Jetpack 的 Startup 来加载。
kotlin复制代码class AppInitializer : Initializer<Unit> {
private val initializerScope = CoroutineScope(Dispatchers.Default)
@OptIn(ExperimentalTime::class)
override fun create(context: Context) {
initializerScope.launch {
measureTime { readEmojiEmbeddings(context) }
}
}
private suspend fun readEmojiEmbeddings(context: Context) {
ProcessorFactory.doProcess(
context,
ProcessorType.PROTOBUF_PROCESSOR,
listOf(R.raw.emoji_embeddings_proto)
)
}
}
加载过程中,使用 parseDelimitedFrom ,该方法和 writeDelimitedTo 对应起来了。读取的原理和写入的相对应,先读取字段长度,根据长度读取对应的字段即可。
这里用到了多线程,读取在 IO 线程,数据解析在 Default 线程。
解析的过程,使用 flatMapMerge 开启了多个协程,提高解析的速度。
kotlin复制代码private var index = AtomicInteger(0)
override suspend fun process(context: Context) = withContext(Dispatchers.Default) {
flow {
context.resources.openRawResource(R.raw.emoji_embeddings_proto).use { inputStream ->
GZIPInputStream(inputStream).buffered().use { gzipInputStream ->
while (true) {
EmojiEmbeddingOuterClass.EmojiEmbedding.parseDelimitedFrom(gzipInputStream)?.let {
emit(it)
} ?: break
}
}
}
}.flowOn(Dispatchers.IO)
.buffer()
.flatMapMerge { byteArray ->
flow { emit(readEmojiData(byteArray)) }
}.collect {}
}
private fun readEmojiData(entity: EmojiEmbeddingOuterClass.EmojiEmbedding) {
val currentIdx = index.getAndIncrement()
// read data
}
Compose UI
整个 APP 的界面长这样:

都是一些非常简单的 Compose UI 元素构建,整体布局为 TextField + LazyColumn 的组合。
如篇头的时序图所示,用户输入相关搜索内容,请求得到结果之后,使用 MVVM,通过 UiState 的方式来更新 UI。定义了如下的 UiState:
kotlin复制代码sealed class UiState {
object Loading: UiState()
data class Success(val data: List<EmojiInfoEntity>): UiState()
data class Error(@StringRes val message: Int): UiState()
object Default: UiState()
}
-
沉浸式状态栏
使用了 accompanist-systemuicontroller 库,实现起来既简单又方便。在 Theme 中书写如下代码,即可实现沉浸态:
kotlin复制代码val systemUiController = rememberSystemUiController() SideEffect { systemUiController.setSystemBarsColor( color = colorScheme.background ) } -
搜索逻辑的书写
Compose 的
TextField使用起来也非常方便,如果TextField是用来做搜索,那么只需要如下定义即可,软键盘确认按钮的位置会变为搜索的 Button,点击后也会执行相对应的操作。kotlin复制代码TextField( // other parameters ... keyboardOptions = KeyboardOptions.Default.copy(imeAction = ImeAction.Search), keyboardActions = KeyboardActions(onSearch = { onSearch(searchText.text) }) )
使用 OpenAI API 发送网络请求
调用接口获取用户输入所对应的 Embedding,都是一些通用的操作,不过参考了第三方 SDK github.com/aallam/open… 的实现,缩减了一部分工作量。
网络接口代码也简单贴一下吧,API_KEY 放在了 BuildConfig 里边:
kotlin复制代码interface OpenAIAPI {
@Headers(
"Content-Type:application/json",
"Authorization:Bearer ${BuildConfig.API_KEY}"
)
@POST("v1/embeddings")
suspend fun getEmbedding(@Body request: EmbeddingRequest): EmbeddingResponse
}
计算得出最相关的 Emojis
从 OpenAI API 拿到用户输入的 Embedding 数据之后,需要和之前的 Protocol Buffers 格式的 Emojis Embedding 数据做一次矩阵点积运算,得到的点积越大,即和用户输入的相似度越高(如果两个向量的点积越大,则表明两个向量的相似度越高)。具体可以表示成如下公式所示:
代码实现上,则使用到了 github.com/Kotlin/mult… 这个 Kotlin 官方的矩阵运算库。使用其提供的数据结构存储 Embedding 数据后,调用其 dot 方法即可:
kotlin复制代码const val EMOJI_EMBEDDING_SIZE = 3753
const val EMBEDDING_LENGTH_PER_EMOJI = 1536
val emojiEmbeddings = mk.zeros<Float>(EMOJI_EMBEDDING_SIZE, EMBEDDING_LENGTH_PER_EMOJI)
val embeddingReshaped = mk.ndarray(embedding).reshape(EMBEDDING_LENGTH_PER_EMOJI, 1)
val dotResult = emojiEmbeddings.dot(embeddingReshaped).flatten().toList()
result = topKIndices(dotResult, topK)
fun topKIndices(list: List<Float>, k: Int): List<Int> {
val indices = List(list.size) { index -> index }
return indices.sortedByDescending { list[it] }.take(k)
}
待优化及踩坑项
使用后端服务器做分发,实现国内的直接访问
当前情况下,使用 APP 时,需要开启科学上网。如果可以搭建一个国外服务器作为跳板机来访问 OpenAI 的 API,那么国内用户就可以直接使用了,确实能极大的提升用户体验。于是我参考 相关教程 ,尝试使用腾讯云函数,用 Python 简单搭建一下。
尝试了硅谷和新加坡的服务器,使用如下命令测试,每次请求都是返回 443 Timeout,根本没办法访问,考虑到 OpenAI API 在国内的诸多限制,遂放弃了,其他家估计也很难保持稳定。
bash复制代码curl https://api.openai.com/v1/embeddings
-H "Content-Type: application/json"
-H "Authorization: Bearer API_KEY"
-d '{
"input": "Your text string goes here",
"model": "text-embedding-ada-002"
}'
使用 Mobile-Bert,实现本地化部署
实际上,实现一个 Emoji Search 的功能,完全可以自己训练一个 Embedding 模型,于是在这个方向上我也花了大把时间进行尝试。
想法也非常简单直接,使用 Mobile-Bert 来实现本地推理,这样我就可以不需要调用 OpenAI 的 API 了。
赶紧使用预训练的 Mobile-Bert 尝试了一下,结果发现不管我搜索什么,输出的都是这些内容:
less复制代码get_top_relevant_emojis, ind: [ 661 1529 2221 564 3114]
result: [ {'emoji': '🎛', 'message': 'Control knobs', 'score': 1.0089411635249676e+16}, {'emoji': '🔐', 'message': 'Closed lock with key', 'score': 9776858819601088.0}, {'emoji': '📂', 'message': 'Open file folder', 'score': 9320027788615100.0}, {'emoji': '🗃', 'message': 'Card file box', 'score': 8816309843148762.0}, {'emoji': '™', 'message': 'Trade mark sign', 'score': 8319274302748725.0}]
看了这篇解答,预训练的 Bert 模型,对 emoji 支持并不友好,Emoji 相关的数据太少了。接下来,又尝试了一波 DistilRoBERTa。效果依旧很差,如果需要实现本地推理的话,需要自己搜集 Emoji 数据来训练了。考虑到时间成本,准备先放弃本地推理的方案。不过以后自己肯定需要去做这些的!
降低 Embedding 的维度
通过 OpenAI API 得到的 Embedding 向量维度为1536,其实针对只有 3000 多条 Emoji 数据进行搜索的场景,1536 维确实没有必要。于是我尝试使用 PCA 算法对 Embedding 数据实现降维操作。发现降到 100 维的样子,能保持相对于原始数据 0.77650886 的准确率。这对于当前场景来说,完全足够了。
但是,降维之后,我需要保存并加载 PCA 的相关权重文件,虽然可以减少较多的包体积,但是会把数据加载的过程弄得更加复杂,更难维护,于是就没有实际在 APP 上实现了,只使用 Python 进行了简单的测试。
Python 端直接保存成 Protocol Buffers 文件
在 将 Emoji 数据转换为 Protocol Buffers 格式 那一节,我使用 Kotlin 将 Json 格式的数据转换为 Protocol Buffers 格式。其实 Protocol Buffers 作为支持众多语言的一个二进制文件存储协议,使用 Python 转换,Kotlin 读取会更加方便。
而转换和读取都使用 Kotlin 的原因,是因为 Python 的 float 类型默认为双精度浮点数,占用 8 个 Byte,Kotlin 的 float 是单精度浮点数,占用 4 字节(32 位)的内存。举个简单的例子:
有如下的数据需要使用 Protocol Buffers 存储
json复制代码{"embed": [1.1, 1.1]}
使用 Python 序列化后得到的 Byte 数组:
复制代码26, 16, 154, 153, 153, 153, 153, 153, 241, 63, 154, 153, 153, 153, 153, 153, 241, 63
使用 Kotlin 序列化后得到的 Byte 数组:
复制代码26, 8, 205, 204, 140, 63, 205, 204, 140, 63
第一个 Byte 26 表示的是数据类型,第二个 Byte 16 和 8 表示数据的长度,由于是 2 个 Float 数字,所以在 Python 中的大小为 16,而在 Kotlin 中占用的大小为 8。
Android 端矩阵运算 SDK 的选择
这里虽然不是什么大规模的矩阵运算,但是为了提升矩阵运算的速度,还是有一些值得取舍的点。
是使用 Koltin 原生,还是使用 Native,亦或是使用 Pytorch Mobile 或者 RenderScript。
这里我想的是先不要搞那么复杂,先不考虑自己去跑 Benchmark 然后决定使用哪个,直接使用 Kotlin 官方的,使用 Native 方法实现的库 viktor。RenderScript 适用于图像图像处理,视频编辑等。Pytorch 适用于大规模的矩阵运算,而且会增加包体积。单次的简单的矩阵运算,我想,我想使用 Native 方法实现的 viktor 已经够用了。
-
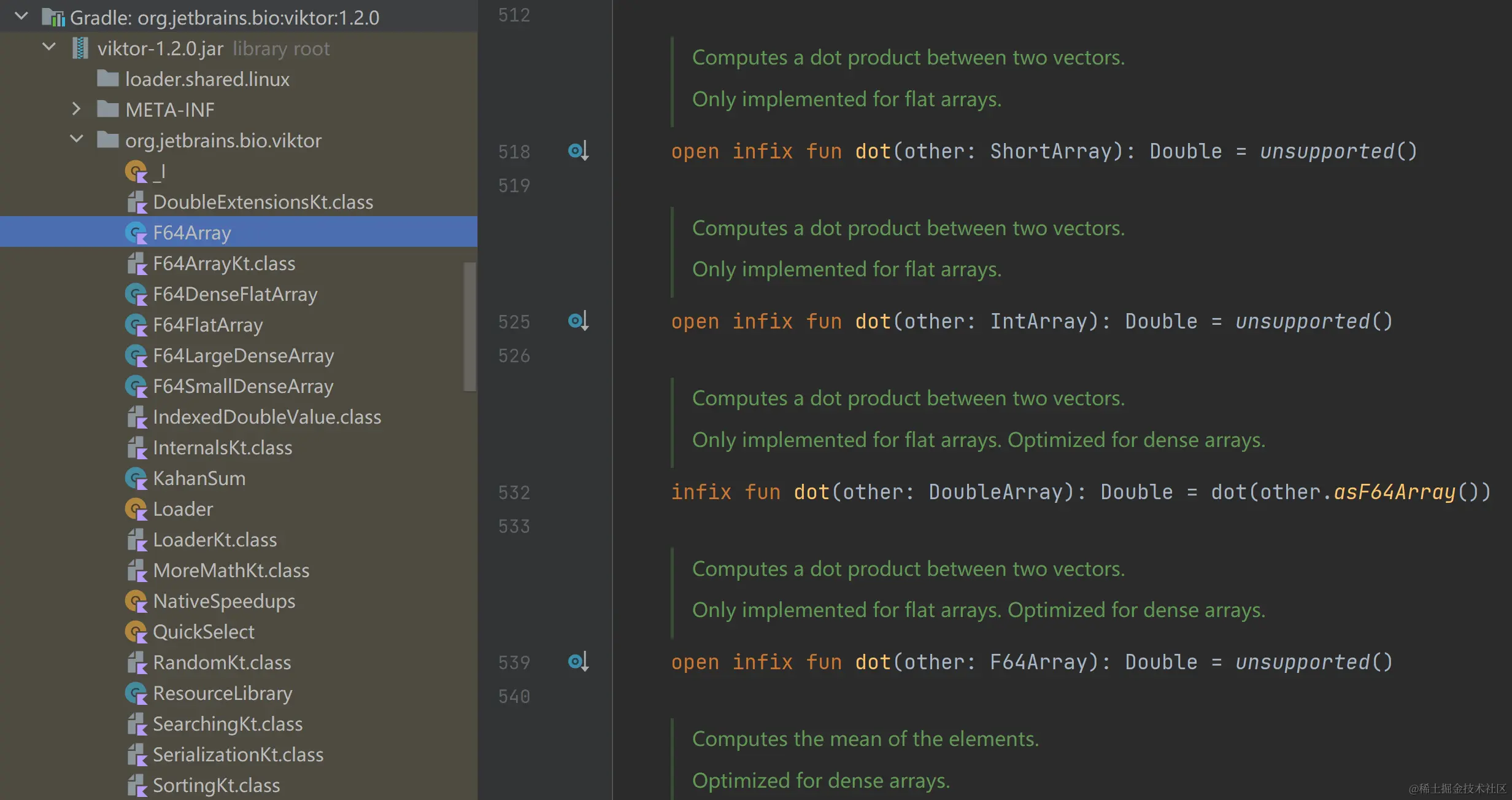
viktor 的使用

看到这张图,我整个人直接沉默了,viktor 库的 dot 方法,不持支多维向量,只支持一维向量和一维向量之间求点积!只能再找找其他的了。
-
multik 的使用
同样是 Kotlin 官方的库, multik 比 viktor 要好很多,至少支持多维向量的点积了。但是没办法用 Native 的方法,因为 Native 库还没有编译 Windows 平台的。使用的是 Kotlin 原生进行计算,每次 reshape + dot 运算大概花费 70ms 的样子,是完全可以接受的。
-
使用 Kotlin 代码
简单实现了一下 Kotlin 的矩阵点积操作:
kotlin复制代码val emojiEmbeddings = Array(EMOJI_EMBEDDING_SIZE) { FloatArray(EMBEDDING_LENGTH_PER_EMOJI) } fun calculateDot(embeddings: Array<FloatArray>, resEmbedding: FloatArray): FloatArray { val result = FloatArray(embeddings.size) embeddings.forEachIndexed { index, embedding -> result[index] = embedding.zip(resEmbedding).fold(0f) { res, cur -> res + cur.first * cur.second } } return result }和 multik 比起来,差距还是蛮大的,Kotlin 的实现耗时在 700ms,是 multik 的 10 倍。
Reference
Flowchart Maker & Online Diagram Software
Android 当你需要读一个 47M 的 json.gz 文件 – 掘金
