

在这个快速发展的数字时代,AI人工智慧已经渐渐成为我们日常生活的一部分。而OpenAI,作为AI研究的机构之一,提供了强大的工具和LLM模型,如GPT-3.5、GPT-4,来帮助我们更好地理解和使用AI。
在本文中,将以简单明了的方式来说明如何控制OpenAI模型的一些关键设定。从生成多样回复的 n 参数,到控制回答长度的 max_tokens ,再到建立词汇黑名单的 stop 参数,以及最后的 temperature 参数,这些都是让AI生成的内容更加贴合我们需求的实用工具。让我们一起探索这个令人兴奋的AI世界。
如何用OpenAI获得多个答案?
使用参数
n可选择多个答案。
当我们使用ChatGPT时,通常我们会得到一个答案。但如果你对这个答案不太满意怎么办?有时候,我们希望能看到不同的答案,从中选择一个最适合的。这时候你需要在答案的下方按下「重新生成」按钮,让ChatGPT重新生成一组新的回答。

ChatGPT的状况
好消息是在OpenAI,我们可以让它一次给我们好几个答案作为选择。这就是 n 这个参数的作用。通过设置 n 参数,我们可以告诉OpenAI一次生成多少个答案。比如说,设置 n = 3 就会一次得到三个不同的答案。
但要注意,这些答案都是针对同一个问题,回答的不同回答,而不是一来一回的连续对话。
如何做?
假设你使用Python语言来跟OpenAI沟通,可以这样写:
ini复制代码 openai<=1.0.0 时
reply = openai.ChatCompletion.create(
model= "gpt-3.5-turbo",
messages = [{"role": "user", "content": "今天是个晴朗的天气吧"}],
n = 2
)
print(reply)
for choice in reply["choices"]:
print(choice["index"], choice["messages"]["content"])
openai>=1.0.0 时
reply = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "今天是个晴朗的天气吧"}],
n=2
)
pprint(reply)
for choice in reply.choices:
print(choice.index, choice.message.content)
这段程序会让OpenAI给我们两个不同的回答。我们透过一个for loop 回圈把这些回答一个一个显示出来。每个回答都有一个编号,从0开始。
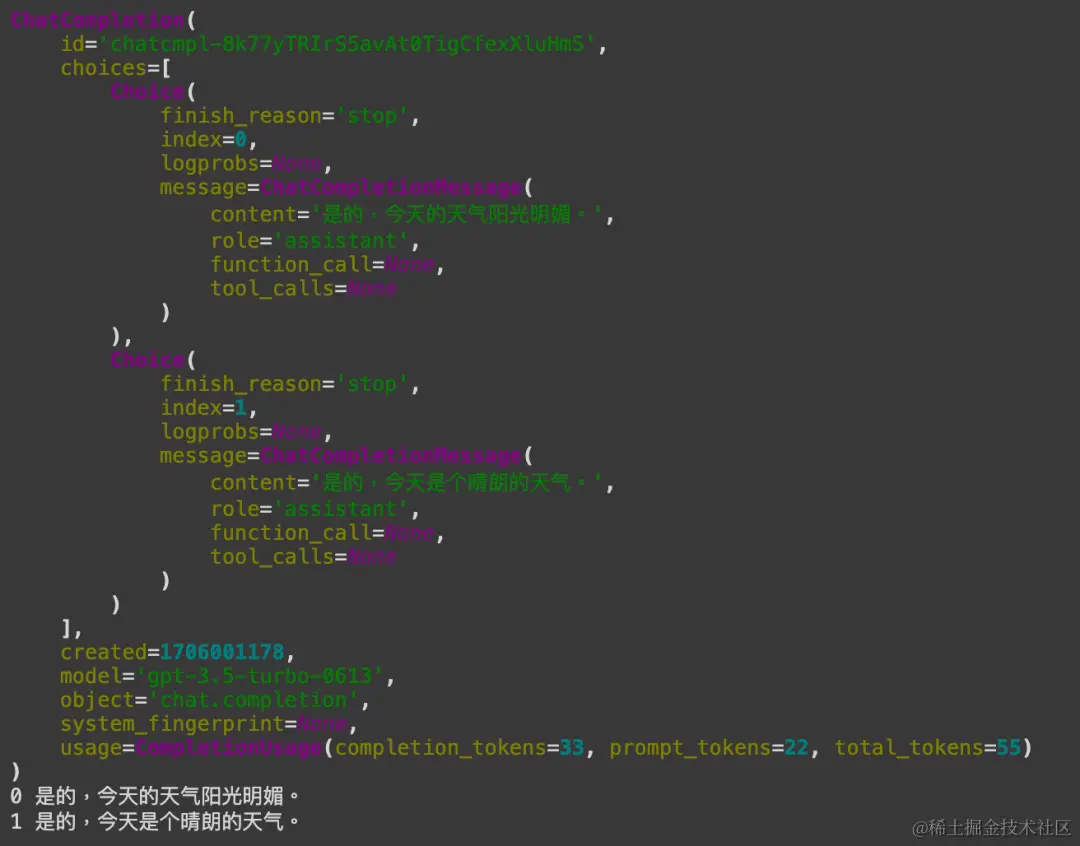
这样你就可以看到两个不同的答案了。不过,这里必需要记得的一点是,当我们要求更多的答案时,使用的 token 数量也会增加。token 是OpenAI计算使用量的单位,所以多个答案意味着可能需要付出更多费用。
如何设定OpenAI回答的长度限制?
使用max_tokens参数,控制回复内容长度
回答的答案越长,所用到的 token 数越多,连带的费用也会越高。因此,有时候我们在使用OpenAI时不希望模型给我们太长的回答,以便于节省成本。这时,我们可以使用一个叫做 max_tokens 的设定来限制回复的长度,控制 token 的使用数量。以下用两个例子说明:
举例 1
比如说,我们只想要一个很短的回答,可以这样设定:
ini复制代码 openai<=1.0.0 时
reply = openai.ChatCompletion.create(
model= "gpt-3.5-turbo",
messages = [{"role": "user", "content": "冬天为何会下雪?"}],
max_tokens = 10
)
print(reply["choices"][0]["message"]["content"])
print(reply["choices"][0]["finish_reason"])
print(reply["usage"]["completion_tokens"])
openai>=1.0.0 时
reply = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages = [
{"role":"user", "content": "冬天为何会下雪?"}
],
max_tokens = 10
)
print(reply.choices[0].message.content)
print(reply.choices[0].finish_reason)
print(reply.usage.completion_tokens)
这样设定后,OpenAI只会回答一个很短的句子,大概10个词(tokens)左右。显然,这个回答不可能完整,因为 max_tokens 限制了它的长度。我们可以看到 finish_reason 的结果为length,就可以得知,这次的回答是因为长度受到限制而停止,回答并不完整。

举例 2
还有,我们必须注意不要设定一个太大的 max_tokens 值。例如,gpt-3.5-turbo模型最多能处理4097个 token 。如果设定的 max_tokens 太大,超过这个范围,API就会出现错误,因为它超出了模型的处理能力。
ini复制代码 openai<=1.0.0 时
reply = openai.ChatCompletion.create(
model= "gpt-3.5-turbo",
messages = [{"role": "user", "content": "冬天为何会下雪?"}],
max_tokens = 4090
)
print(reply["choices"][0]["message"]["content"])
print(reply["choices"][0]["finish_reason"])
print(reply["usage"]["completion_tokens"])
openai>=1.0.0 时
reply = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages = [
{"role":"user", "content": "冬天为何会下雪?"}
],
max_tokens = 4090
)
print(reply.choices[0].message.content)
print(reply.choices[0].finish_reason)
print(reply.usage.completion_tokens)
执行这个例子,会产生如下的结果。告诉我们这个模型最多只能处理4097个 token ,但是我们却设定了超过这个限制的 token 数( This model’s maximum context length is 4097 tokens. However, you requested 4110 tokens (20 in the messages, 4090 in the completion)
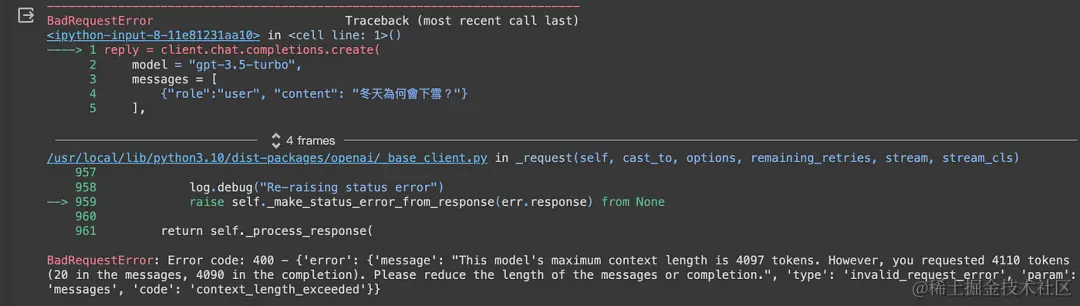
总体来说, max_tokens 是一个很有用的设定,可以帮我们控制回答的长度,进而控制用量与成本。反之,由于它的默认值为无限大,若没有特别设定 max_tokens 的话,就没有任何限制。因此要记得,设定得太高或太低都可能会影响回答的质量。
如何设定OpenAI模型回答的禁用语?
stop参数,可建立词汇黑名单
当我们使用OpenAI的时候,可能会担心它的回答中出现一些我们不想要的词汇。那么,我们怎么才能避免这种情况呢?这时候,OpenAI提供我们一个叫做 stop 的参数来设定黑名单。
stop 参数可以让我们指定一些不想让AI使用的词汇。默认情况下,这个 list列表是空的,这也就意味着没有任何词汇被禁止。
我们最多可以在这个列表中设定四个词汇。一旦AI在回答中遇到这些词汇时,就会立刻停止回答,并返回目前的结果。以下举例说明:
举例
假如我们不希望回答中出现「好」这个字词,我们可以透过下面方式设定:
ini复制代码 openai<=1.0.0 时
reply = openai.ChatCompletion.create(
model= "gpt-3.5-turbo",
messages = [{"role": "user", "content": "我很好,您好吗?"}],
stop = ["好"]
)
print(reply["choices"][0]["message"]["content"])
print(reply["choices"][0]["finish_reason"])
openai>=1.0.0 时
reply = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "我很好,您好吗?"}],
stop=['好']
)
print(reply.choices[0].message.content)
print(reply.choices[0].finish_reason)
我们将stop参数设定为「好」( stop = [“好”] )。这样一来,如果AI的回答中包含了「好」这个字词,它就会立即停止回答。这个功能对于控制AI回答的内容非常有用,可以确保不会出现不适当或不想看到的词汇。
如何通过「温度」设定让OpenAI回答更有趣
temperature参数,可增加回答的多样性
「temperature」这个参数就像是调节OpenAI回答的「温度」设定器。当我们讲温度时,高温通常意味著更多活力和热情,而低温则意味著冷静和稳定。这个概念也适用于OpenAI的设定。通过调整 temperature ,我们可以控制AI回答的随机性和创造性。这个参数的范围从0到2,数值越高,回答就越多变和有趣;数值越低,回答就越稳定和可预测。
设定为最低值:0
当我们把 temperature 设为0时:
ini复制代码reply = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "嗨!我很好,您好吗?"}],
temperature=0,
n=2
)
for choice in reply.choices:
print(choice.index, choice.message.content)
这样设定后,如下图所示:

AI产生的回答会非常稳定和一致,几乎没有太多变化。
设定为最高值:2
反之,如果将 temperature 设为2:
ini复制代码reply = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "嗨!我很好,您好吗?"}],
temperature=2,
n=2
)
for choice in reply.choices:
print(choice.index, choice.message.content)
在这个设定下,AI产生的回答会非常活泼和多变,有时甚至可能显得有点奇怪或不相关(如下图显示)。而且,这可能会导致AI需要更长的时间来生成回答。

实际上, temperature 的默认值是1。在这个设定下的回答既不会太僵硬,也不会太过活跃,是一个较为均衡的选择。因此,如果你不确定从哪里开始,可以先尝试设定 temperature 为1开始测试。
结语
透过本文的介绍,我们一起探索了如何控制OpenAI模型的几个重要设定。从设定生成回复数量的 n 参数,到控制回答长度的 max_tokens ,再到建立词汇黑名单的 stop 参数,以及调节回答风格的 temperature ,这些都是使我们能够更有效地利用AI技术的强大工具。这些设定,让我们可以调整与控制AI的回答,使之更贴合我们的需求和预期,无论是在节省成本、避免不适当内容,还是创造更有趣和多样的回答上都大有裨益。
希望这篇文章能够帮助您对OpenAI的功能有了更深入的理解,无论目前的您是AI领域的初学者还是已经有一定经验的使用者。在这个不断变化的AI领域,保持学习和实验的心是非常重要的。随著技术的进步,你我将会看到更多令人叹为观止的可能性。期待AI在未来的发展,并积极参与其中,共同塑造一个更智能、更有效的未来。
