

主流的LLM都需要通过CUDA才能高效的运行在本地,但是随着Github上出现了Llama.cpp这个神器,一切都改变了。它通过AVX指令和MPI来实现CPU上并行计算,从而在本地计算机高效地运行各种主流的类Llama模型。同时它也支持metal,使得Apple Silicon的系统也能部署LLM。然而他的架构偏向于编译,安装部署较为复杂,于是衍生了Ollama之类的傻瓜式工具。而我要介绍的是Mozilla公司推出了Llamafile工具。

这个工具强大之处在于可以像Nvidia推出了一款 “Chat with RTX” ——原生支持Windows环境运行(而Ollama只有Windows10和11的预览版),但同时非常轻。
| Model | Size | License | llamafile |
|---|---|---|---|
| LLaVA 1.5 | 3.97 GB | LLaMA 2 | llava-v1.5-7b-q4.llamafile |
| Mistral-7B-Instruct | 5.15 GB | Apache 2.0 | mistral-7b-instruct-v0.2.Q5_K_M.llamafile |
| Mixtral-8x7B-Instruct | 30.03 GB | Apache 2.0 | mixtral-8x7b-instruct-v0.1.Q5_K_M.llamafile |
| WizardCoder-Python-34B | 22.23 GB | LLaMA 2 | wizardcoder-python-34b-v1.0.Q5_K_M.llamafile |
| WizardCoder-Python-13B | 7.33 GB | LLaMA 2 | wizardcoder-python-13b.llamafile |
| TinyLlama-1.1B | 0.76 GB | Apache 2.0 | TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile |
| Rocket-3B | 1.89 GB | cc-by-sa-4.0 | rocket-3b.Q5_K_M.llamafile |
| Phi-2 | 1.96 GB | MIT | phi-2.Q5_K_M.llamafile |
支持的系统
- Linux 2.6.18+ (i.e. every distro since RHEL5 c. 2007)
- Darwin (macOS) 23.1.0+ [1] (GPU is only supported on ARM64)
- Windows 8+ (AMD64 only)
- FreeBSD 13+
- NetBSD 9.2+ (AMD64 only)
- OpenBSD 7+ (AMD64 only)

演示
文本生成
css复制代码./mistral-7b-instruct-v0.2.Q5_K_M.llamafile -ngl 9999 --temp 0.7 -p '[INST]Write a story about llamas[/INST]'
代码生成
bash复制代码./wizardcoder-python-13b.llamafile -ngl 9999 --temp 0 -e -r '```n' -p '```cnvoid *memcpy_sse2(char *dst, const char *src, size_t size) {n'
VQA
css复制代码./llava-v1.5-7b-q4.llamafile -ngl 9999 --temp 0.2 --image lemurs.jpg -e -p '### User: What do you see?n### Assistant:'

WEB 服务
bash复制代码./mistral-7b-instruct-v0.2.Q5_K_M.llamafile -ngl 9999
想要只用CPU运行,只需要-ngl 0 或 --gpu disable
支持 Python版的OpenAI SDK
ini复制代码#!/usr/bin/env python3
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port"
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="LLaMA_CPP",
messages=[
{"role": "system", "content": "You are ChatGPT, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests."},
{"role": "user", "content": "Write a limerick about python exceptions"}
]
)
print(completion.choices[0].message)
或是 REST API请求
arduino复制代码curl http://localhost:8080/v1/chat/completions
-H "Content-Type: application/json"
-H "Authorization: Bearer no-key"
-d '{
"model": "LLaMA_CPP",
"messages": [
{
"role": "system",
"content": "You are LLAMAfile, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests."
},
{
"role": "user",
"content": "Write a limerick about python exceptions"
}
]
}' | python3 -c '
import json
import sys
json.dump(json.load(sys.stdin), sys.stdout, indent=2)
print()
‘
存在问题
Windows的exe只能支持4GB大小,所以5G以上需要使用github上的release文件和LLM的Guff文件。
原文: Unfortunately, Windows users cannot make use of many of these example llamafiles because Windows has a maximum executable file size of 4GB, and all of these examples exceed that size. (The LLaVA llamafile works on Windows because it is 30MB shy of the size limit.) But don’t lose heart: llamafile allows you to use external weights; this is described later in this document.
我在WSL中运行,会被杀毒误杀
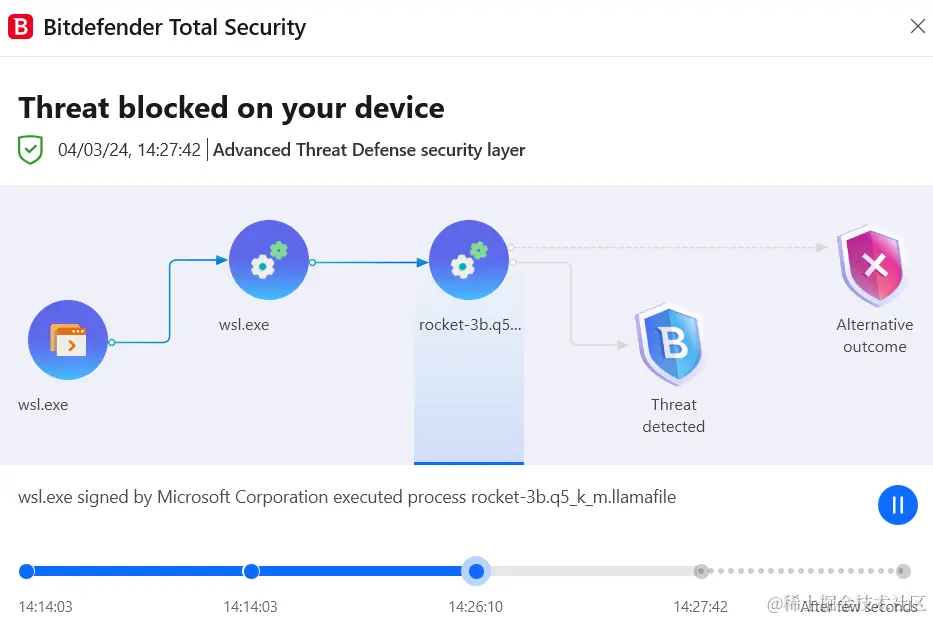
在Windows环境中GPU运行会乱码输出,但是CPU运行能正常显示,且在WSL环境下GPU模式可以正常输出。尚不清楚原因。
