
背景
聊天机器人正在变成我们不可或缺的工具,改变了如今的工作方式。甚至有人开玩笑说2023 Web 开发者做的 HelloWorld 项目不再是 TodoList了而是 AI 聊天机器人,但是它还是被认为具有很高的开发门槛,被认为只有开发者才能构建出应用。但本文将教你如何无需编写任何代码创建自己的聊天机器人,在几分钟内训练任何网站数据,提供的思路和方法也适用于处理其他数据和其他场景。
LangChain介绍
随着OpenAI的发布,大型语言模型 (Large Language Model即LLM) 正在成为一种变革性技术而席卷了世界,使开发人员能够构建他们以前无法构建的应用程序,但是单独使用这些 LLM 往往不足以创建一个真正强大的应用程序,但是当可以将它们与其他计算或知识来源相结合时,就有真的价值了。LangChain旨在帮助开发人员充分利用 LLM 的全部潜力,用于广泛的应用程序。LangChain 围绕将不同组件“链接”在一起的核心概念构建,简化了与 GPT-3、GPT-4 等 LLM 合作的过程,使得我们可以轻松实现聊天机器人、生成式问答、文本摘要等功能。
在这里你可以看到目前LangChain已经集成的模块
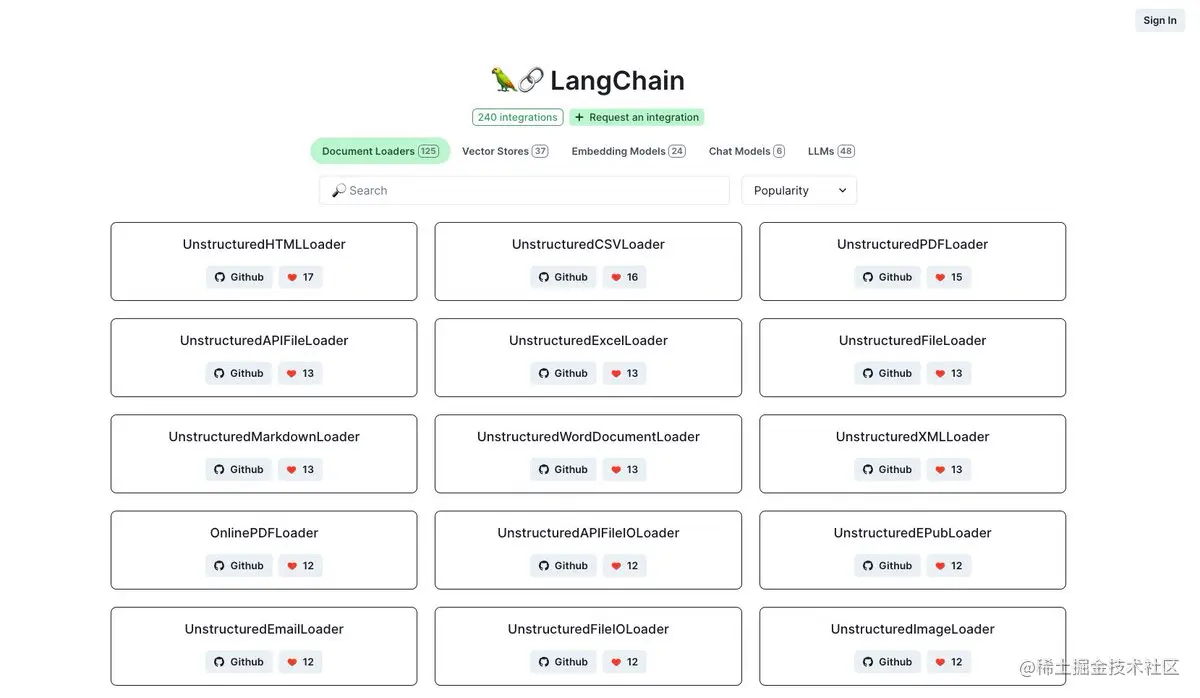
高兴的是,LangChain不仅有python版本,还提供了JS/TS版本。
Flowise介绍
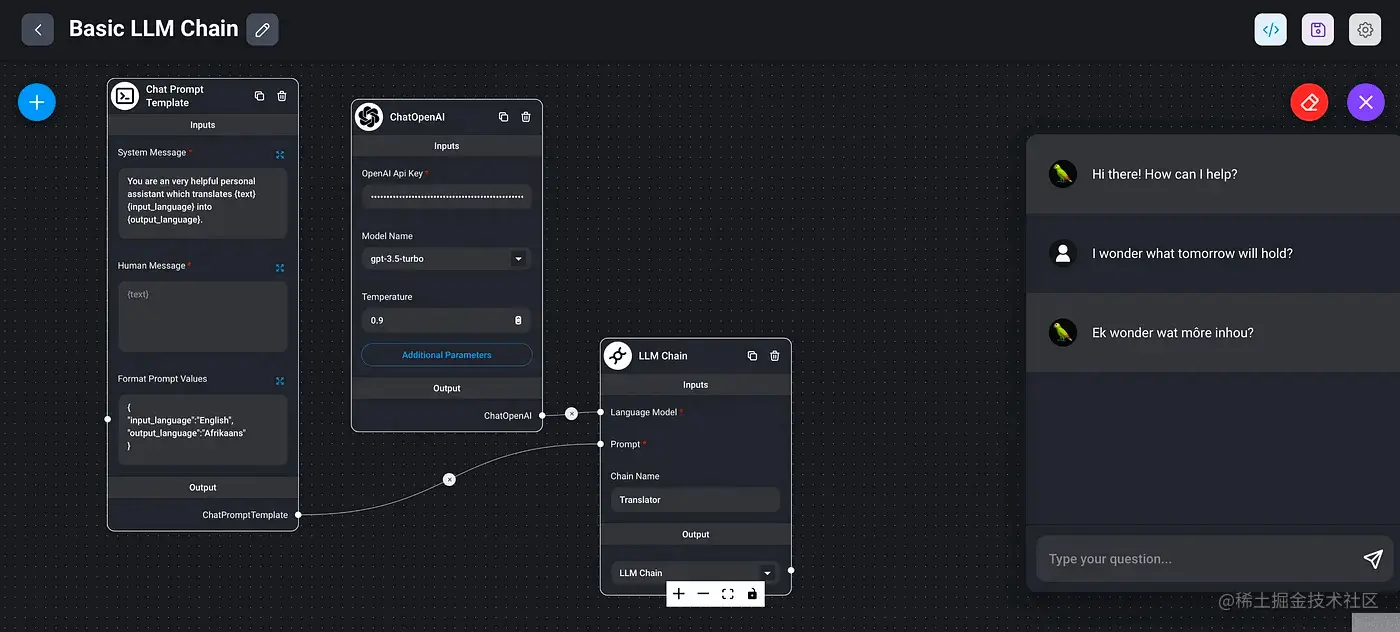
Flowise是基于🦜️🔗 LangChainJS构建的可免费供商业和个人使用的免费开源项目,它有着一个非常易用的图形用户界面,旨在让人们轻松地可视化和构建LLM应用程序,也就是nocode开发LLM应用。类似的工具比这个还早的有langflow,但是因为Flowise它有着好看的UI界面以及这个项目就是js开发的,因此我选择Flowise。举个例子,下面的应用程序展示了一个基本的翻译机器人,同时也演示了如何格式化提示值,而实现下面这个你只需要简单拖拽就可以完成。
而本文要构建网站聊天机器人,本质上和很常见的与已有pdf或者doc文档对话原理是一致的,这里引用一篇文章的示例图片
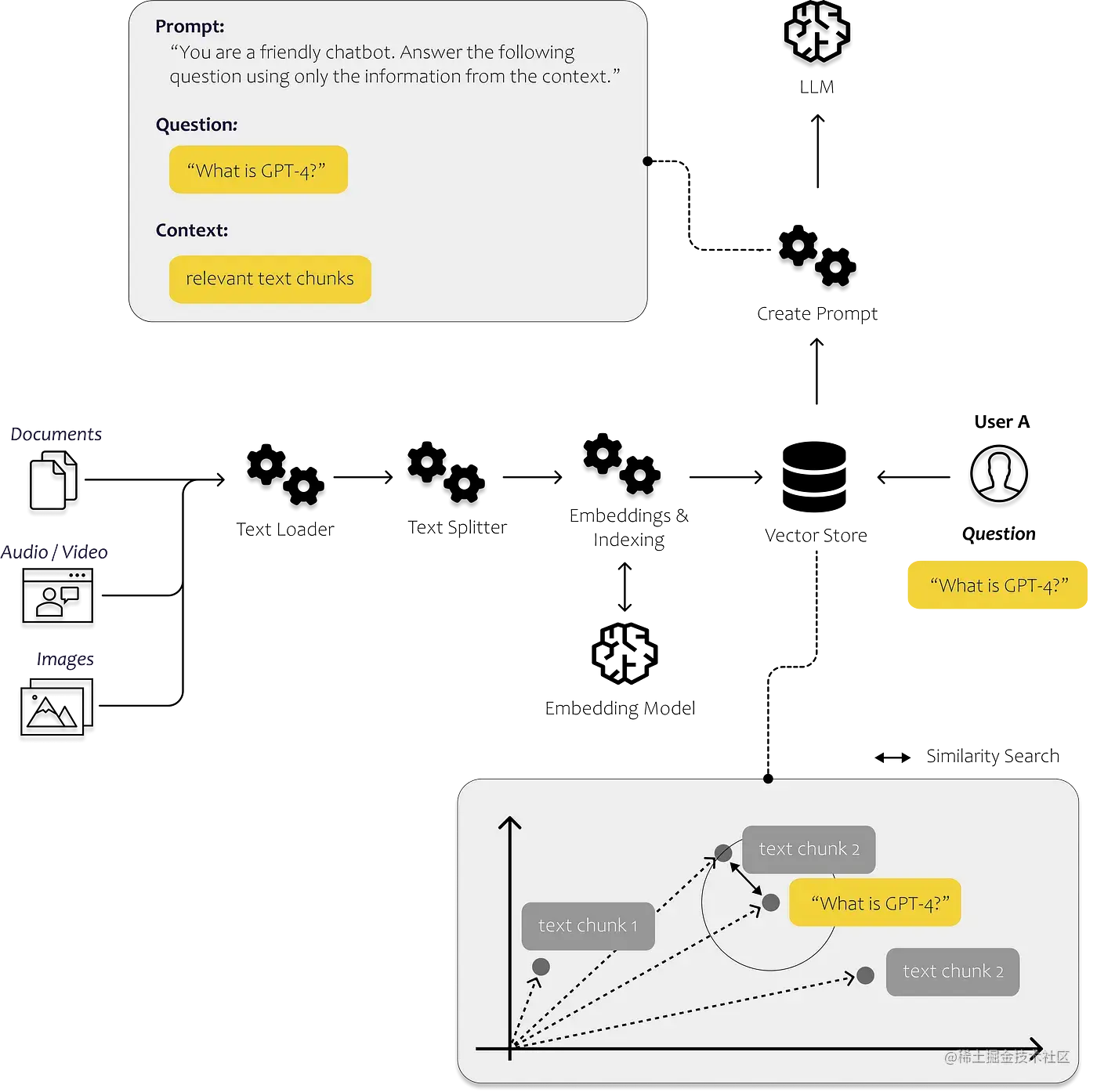
本质上原理大致是:
- 将源文件切成多个文本片段,创建**
Embeddings** 然后存到向量数据库 - 将用户提问也创建**
Embeddings** ,将它和上一步创建好的向量对比,通过相近搜索找到最相关的文本片段,它的特点是能发现文本相关性,比如汽车和公路 - 把问题和历史聊天还有相关片段一起发送给
**LLM**它便能从中总结出回答
自部署
使用Flowise很简单,注意:node要求是最新版18
jsx复制代码npm install -g flowise npx flowise start
执行上面命令后,打开 http://localhost:3000 就可以使用了,但是如果是生产环境使用,就需要自己部署一份了,官方文档提供了多种部署方式,包括Render、Railway、Replit等云服务商各自部署方式,对于无服务器可以尝试下。
如果是使用云服务商部署,因为项目使用了
SQLite,所以需要查阅其文档了解持久化数据的方式,避免服务在重启时数据部分数据丢失,同时向量数据库也推荐也使用云服务商的比如[Supabase pgvecto](https://supabase.com/docs/guides/database/extensions/pgvector)r或者[pinecone](https://www.pinecone.io/)
因为我有腾讯云服务器,并且上面提到的suapabase与pinecone会在你一周没有使用或者说是没有请求调用时,会关闭或者或删除你数据库,所以这里我直接使用docker自己部署,首先clone代码
bash复制代码git clone https://github.com/FlowiseAI/Flowise.git
进入docker目录,创建.env文件,并填入下面环境变量,其中port是服务暴露端口,用户名和密码是为网页访问添加认证
bash复制代码PORT=3000 FLOWISE_USERNAME=admin FLOWISE_PASSWORD=你的密码
然后在这个docker目录执行下面命令启动,我的是docker最新版,因此和文档有点小区别
bash复制代码docker compose up -d
启动后就可以通过ip:3000访问了,参考我之前的文章,通过Nginx Proxy Manage工具,可以轻松为该服务分配一个可访问域名,这里我设置好后,就可以通过域名 flowise.codefe.top/ 来访问了。
流程图
左侧选择Chatflows,点击新增流程,在画布左侧添加节点。流程需要6个节点,分别找到每一个并拖放到画布上,请参阅下面的完整画布,他们的作用分别是:
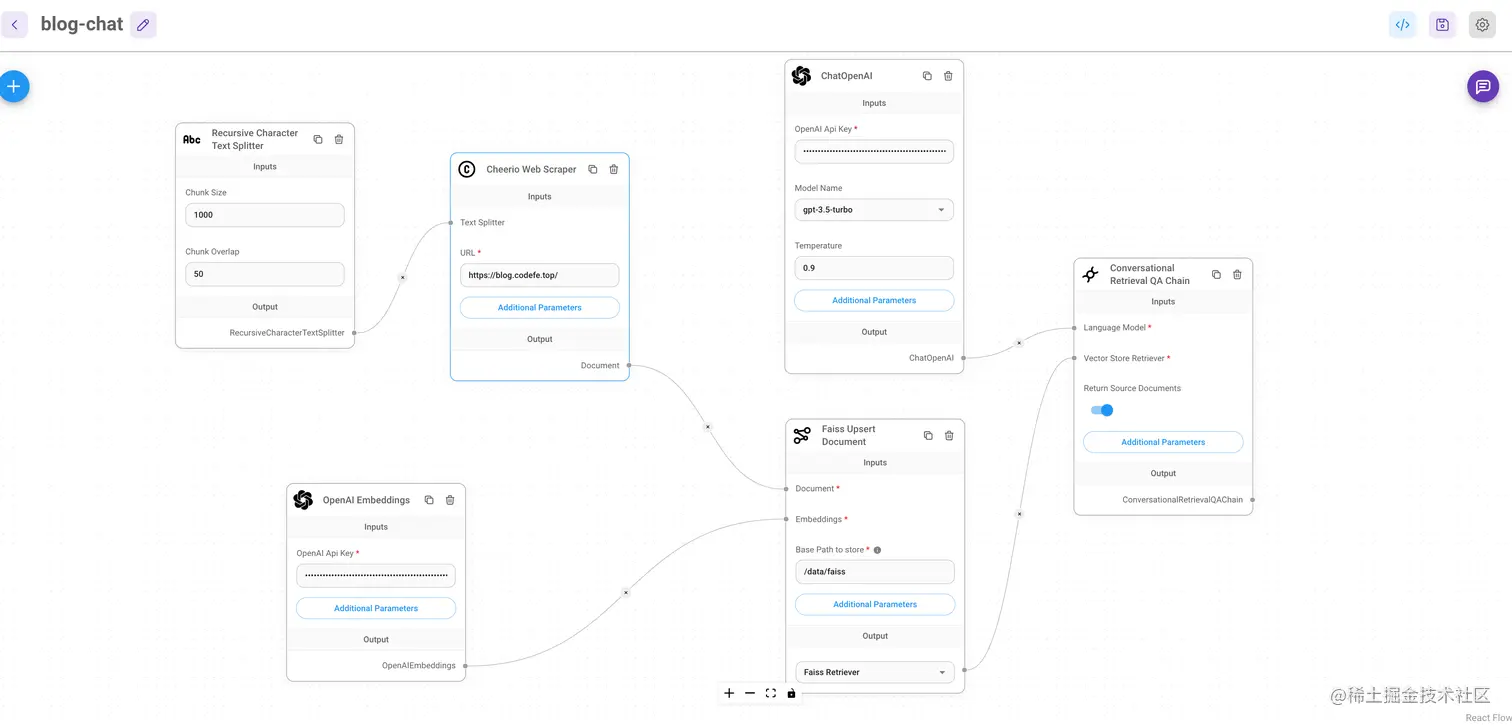
RecursiveCharacterTextSplitter:文本拆分,用于将我们收集的文本数据分解为小块,这些小块稍后将提供给我们的聊天机器人以帮助其正确回答问题Cheerio Web Scrapper:此节点用于读取所选网站中的所有文本。填写您要用作训练数据的URL。在本教程中,我将使用我的博客地址https://blog.codefe.top/,如果您想阅读所有页面而不仅仅是主页面,请单击附加参数,然后选择“相关链接的网页内容”,将链接限制更改为允许的最大页面数。因为OpenAI API按使用的数据量付费。OpenAI Embeddings:Embeddings是一种将单词或句子转换为数学表示的方法,AI工具可以通过它进行自然语言处理任务的搜索和使用。Faiss Upsert Document: Faiss是facebook开源的向量数据库,这里是将上面Embeddings后的向量数据存储,后续会根据提问内容从中最近邻搜索到最匹配的内容ChatOpenAI:ChatGPT语言模型,相似的还有Azure对话模型。Conversational Retriever QA Chain:这个可以基于已有内容和历史聊天记录进行对话
将上面模块根据各自的输入输出关系通过连接线链接起来,其中OpenAI Embeddings和OpenAI对话模型都依赖OpenAI API 密钥,需要正确填写,右上角保存并为此流程选择一个名称。
💡 值得注意的是,
Flowise集成好了LangChain很多loader,比如confluence、docx、folder with files、github、figma、json等多种数据格式和数据源处理,基本可以满足各种场景了。
调试
超时
测试运行时,第一个报错就是504超时
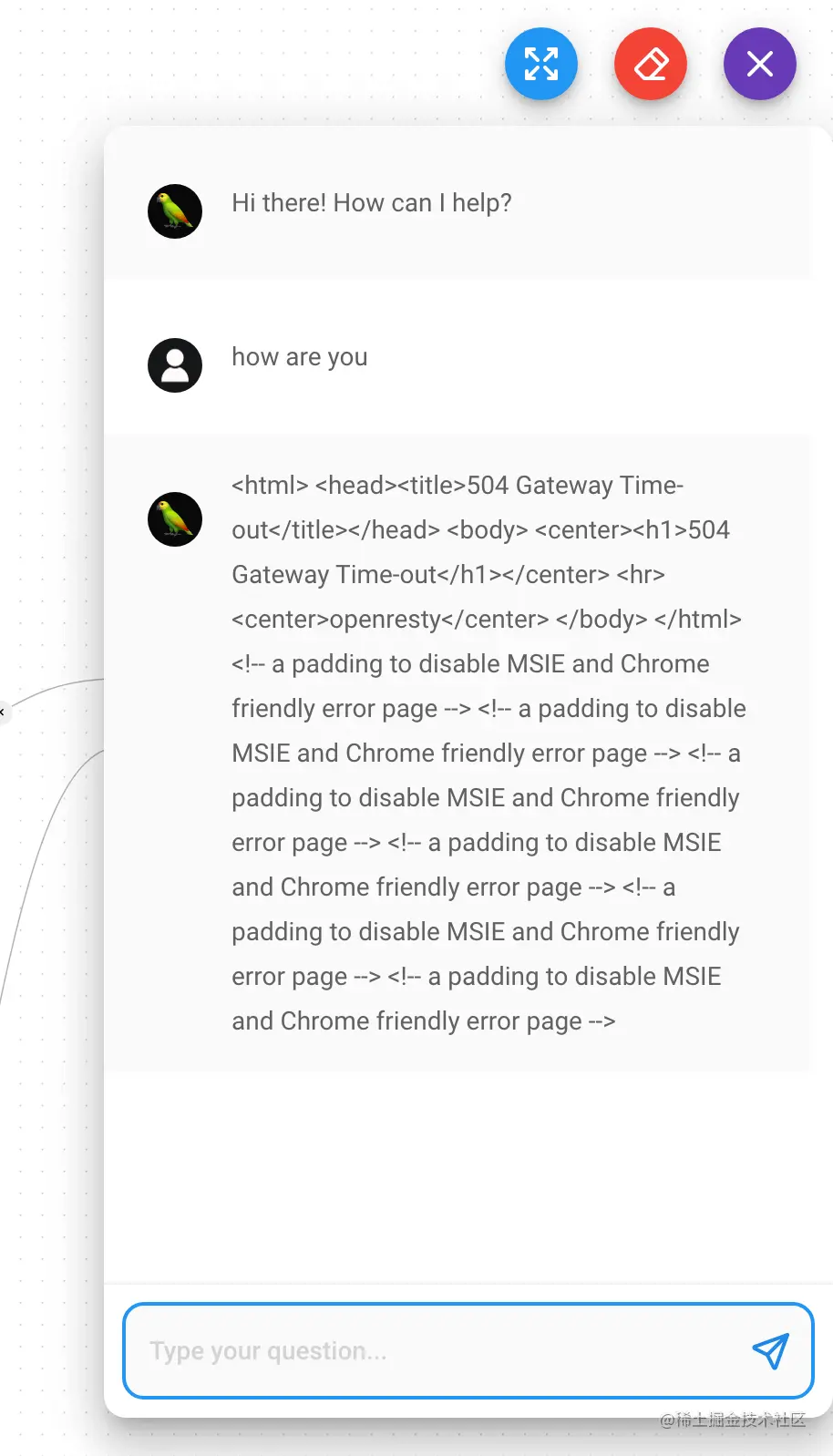
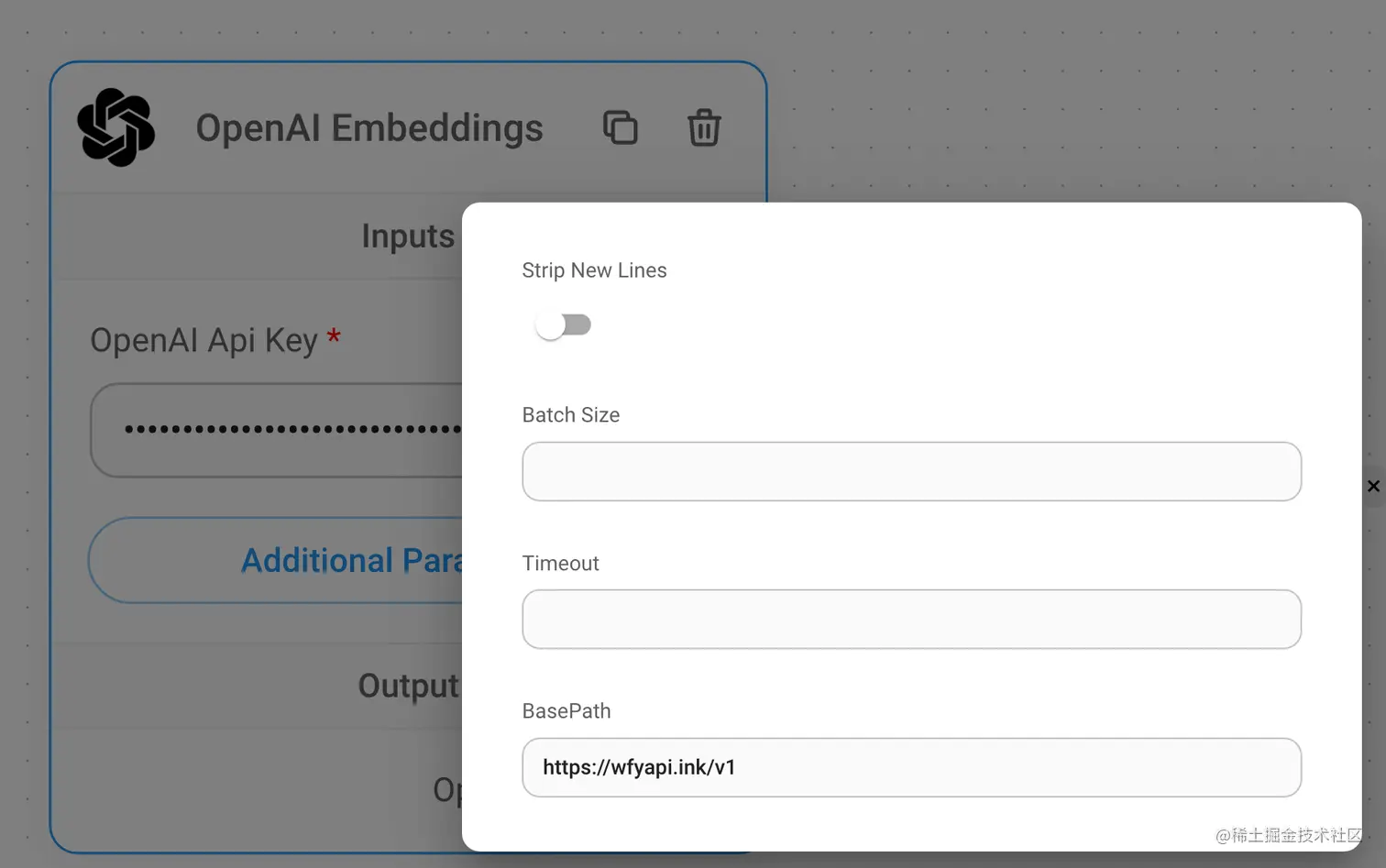
原因是我的机器在广州,所以直接访问Openai Api是访问不通的,因此这里需要设置一个代理地址,搭建代理访问方式很多,这里不在赘述,我之前是通过Cloudflare Worker来代理的,比如我的代理地址是wfyapi.ink/v1 ,将这个地址填写到OpenAI Embeddings和ChatOpenAI这两处用到api的节点,点击节点的Additional Parameters并填入BasePath输入框,如下图所示。
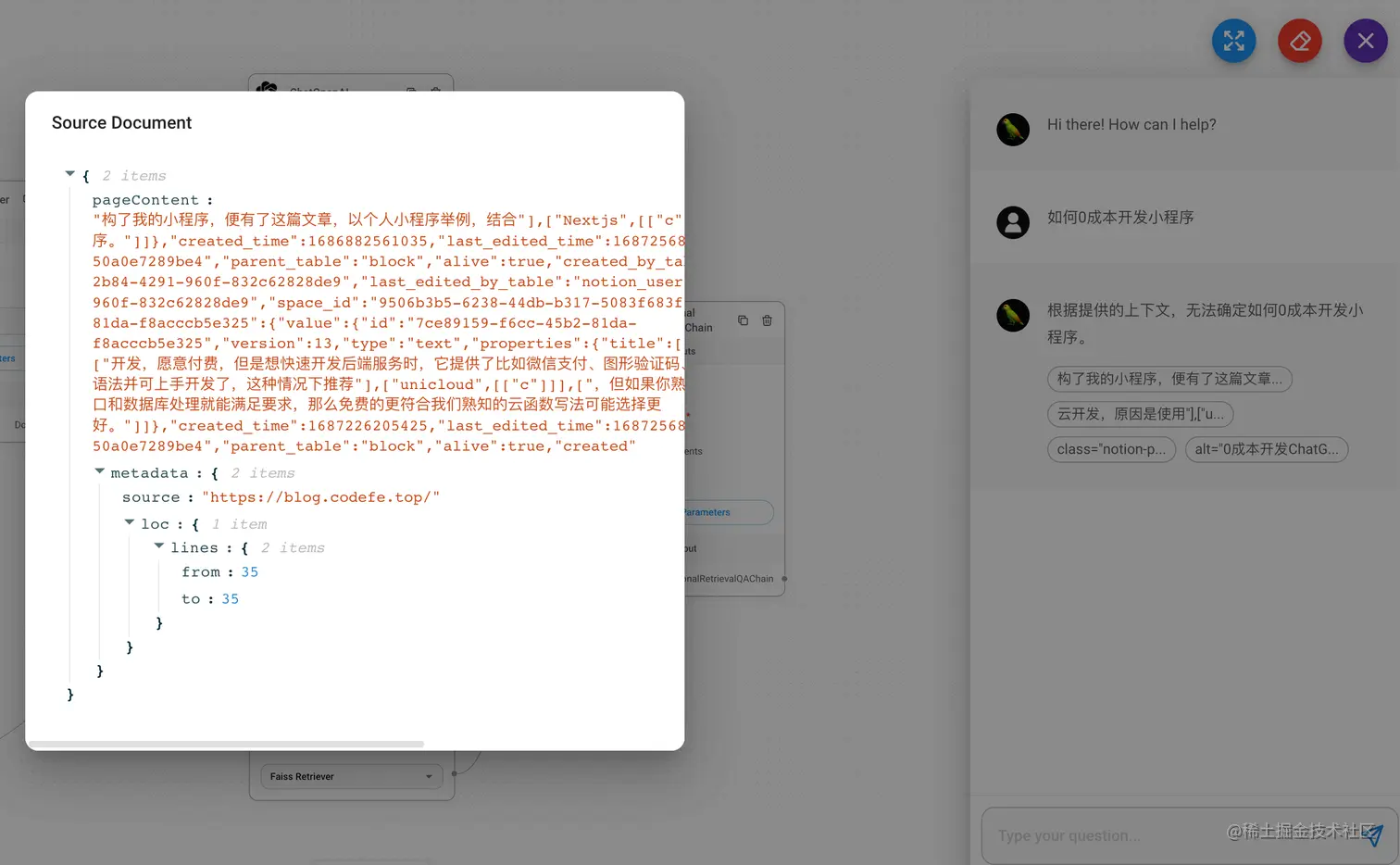
设置好后保存重试,但是并不能很好地检索到内容回答,如下图,查看其匹配到的原内容,可以看到,分割后的内容有大量的无关信息或者说是未经清理的脏数据,这个原因是是这些文本是通过Notion Api返回的,原Notion文本被转换成了特定的结构,并且为了标识每个块是加粗还是斜体格式,也加了大量的字段,这样就导致了下图中的文本多次分割、内容不连贯的问题,因此无法总结。
知道问题所在,同时文档在Web Loader章节中有一个Notion Database Loader可用于从Notion页面和数据库加载文档,同时博客内容的数据源也是来自Notion数据库,因此这里使用Notion Database Loader更合适。
Notion Database Loader
在画布中拖入Notion Database Loader替换掉Cheerio Web Scrapper 按照指引如下设置:
-
获取Notion Database Id
我的Notion页面地址为 wangfengyuan.notion.site/3fdac180303… 那么 3fdac18030394399ae73a019054ce28f 就是这个database id
-
获取Notion Integration Token 参考Notion文档生成一个
-
关联Token
然后在第一步页面设置中,点击Connections绑定第二步申请的token

当我们提问: prisma有哪些优势时,可以看到这时候总结回答的还是挺好的,查看匹配到到源文件也是全部是连贯干净的文本。
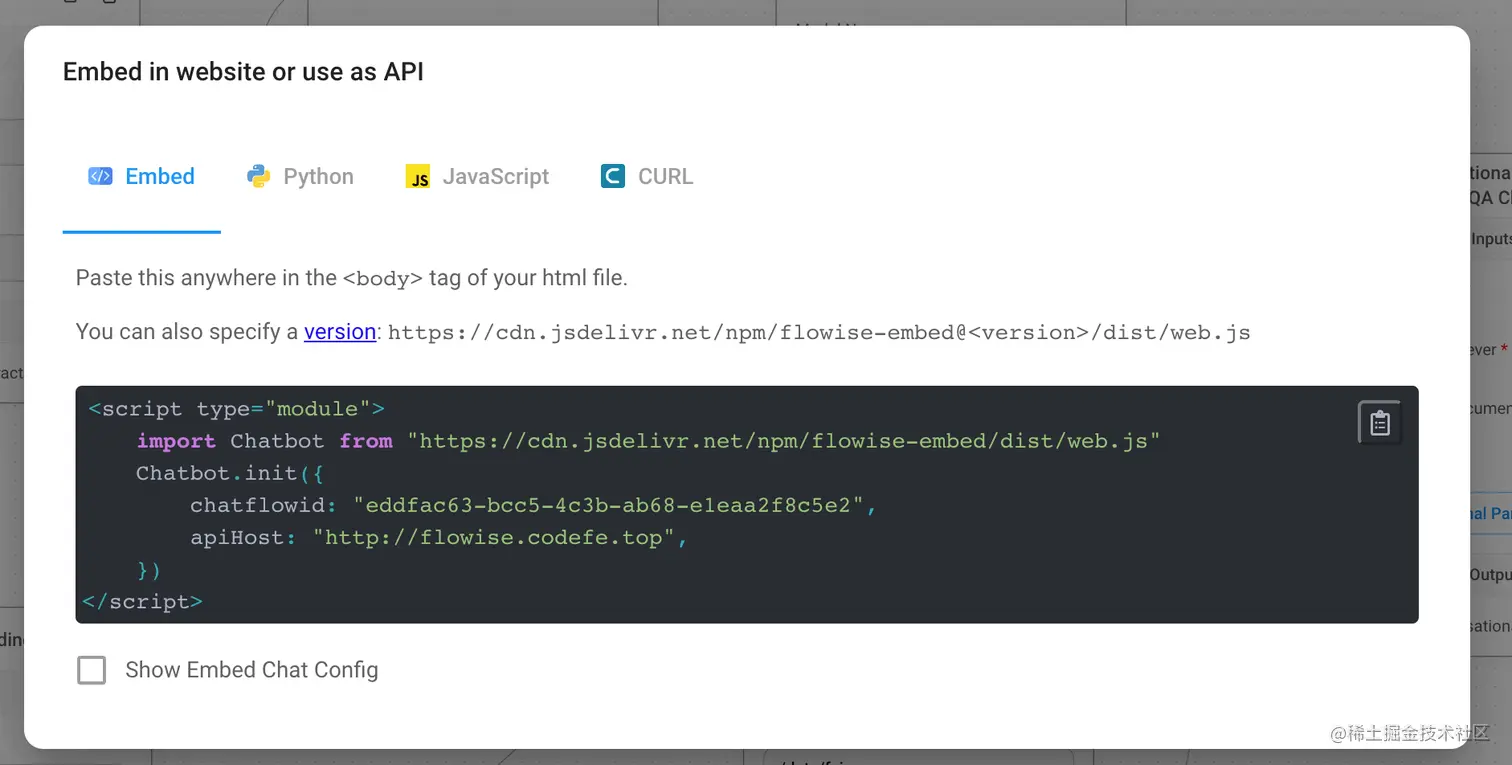
集成到网页
点击右上角代码图标,可以看到它提供了直接嵌入你网站的方法,并且可以通过下方Chat Config覆盖默认参数来定制部分展示。
同时也提供了API的调用方式,那么你可以结合自己场景,赋予了更高的自由度。
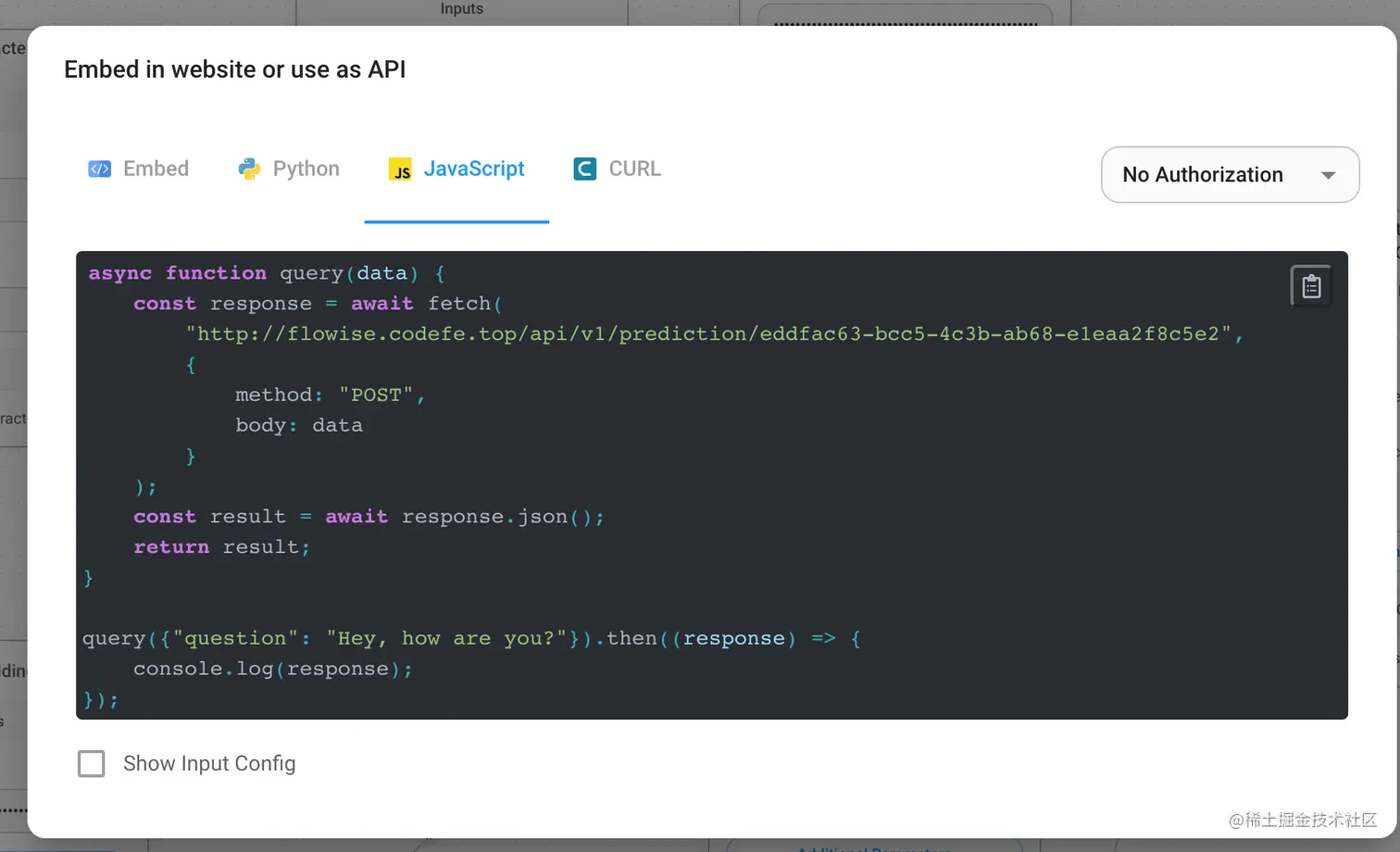
但是从它的github上可以找到其实有一个对应的[React版本的npm包](github.com/FlowiseAI/F…
bash复制代码pnpm install flowise-embed flowise-embed-react
bash复制代码import { BubbleChat } from "flowise-embed-react";
<BubbleChat
chatflowid="eddfac63-bcc5-4c3b-ab68-e1eaa2f8c5e2"
apiHost="https://flowise.codefe.top"
/>
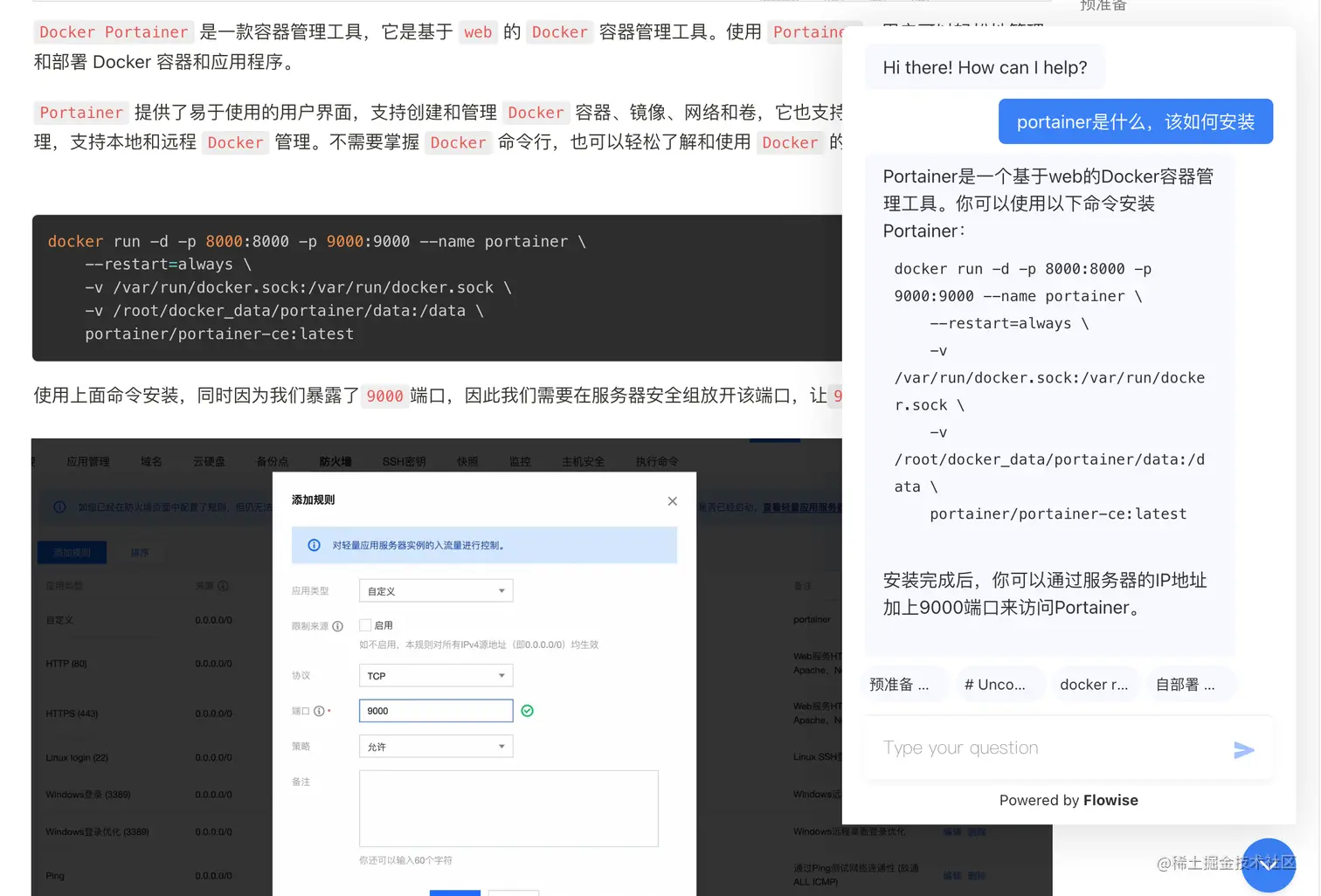
然后就成功的集成到了博客网页,但是当再次提问时,如下图
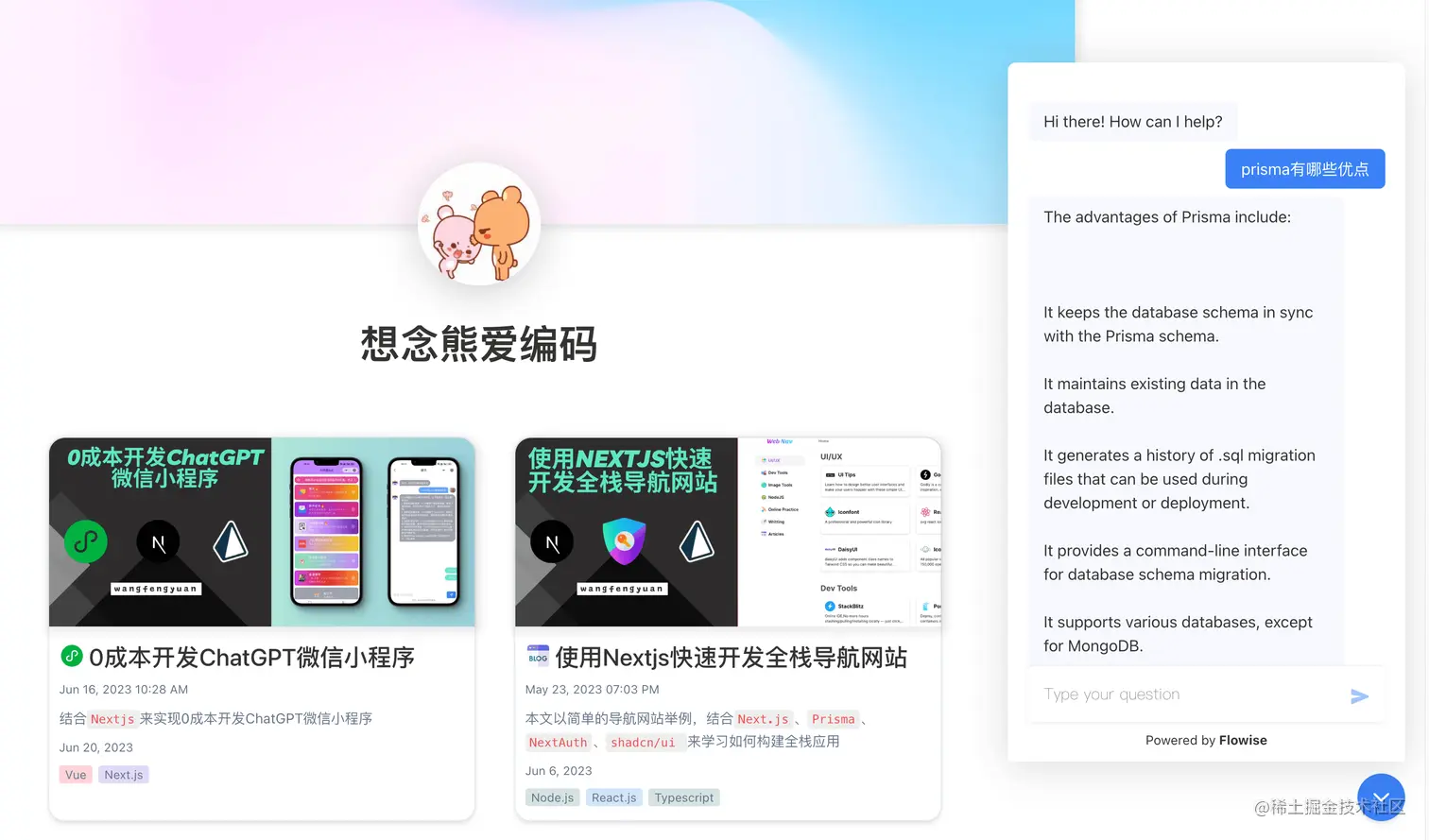
同样的问题,之前回答一直是用的文章的中文,但是集成后回答被转换成了英文的,也不知道是为啥,然后这里我的办法是,在预置的prompt后面加一句让其用中文回答,如下图:
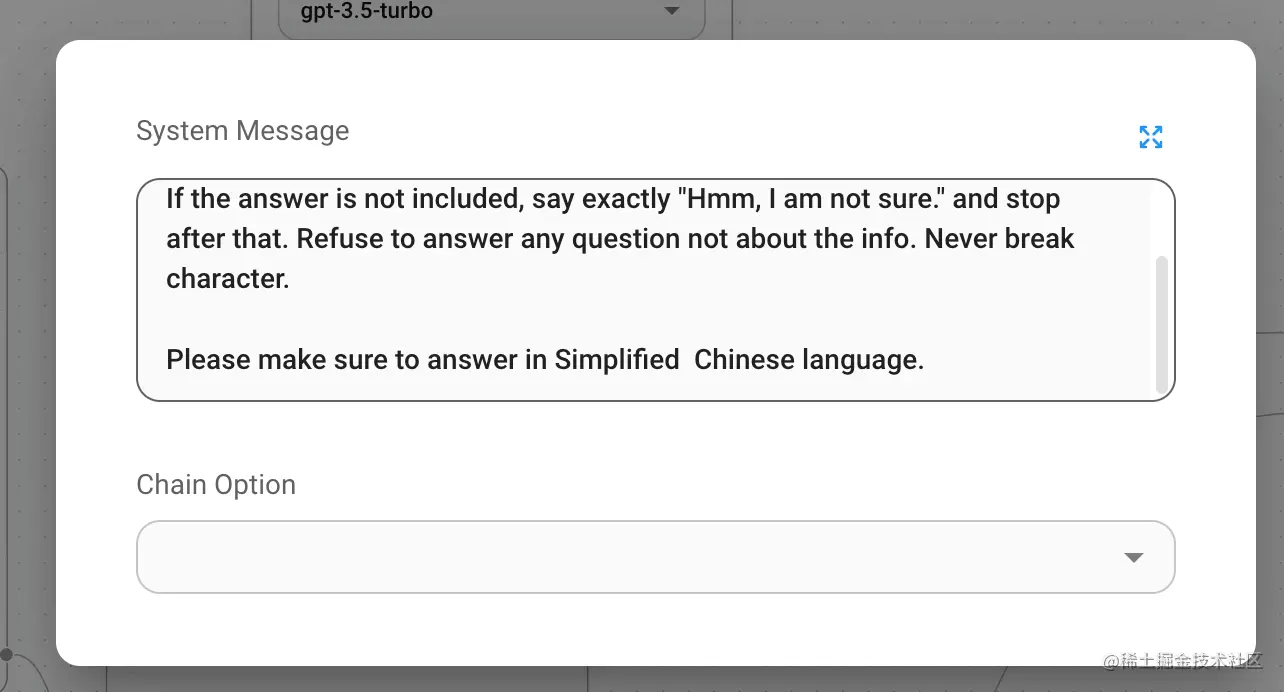
修改后就达到了与之前画布测试差不多一致的效果,你可以在这体验。
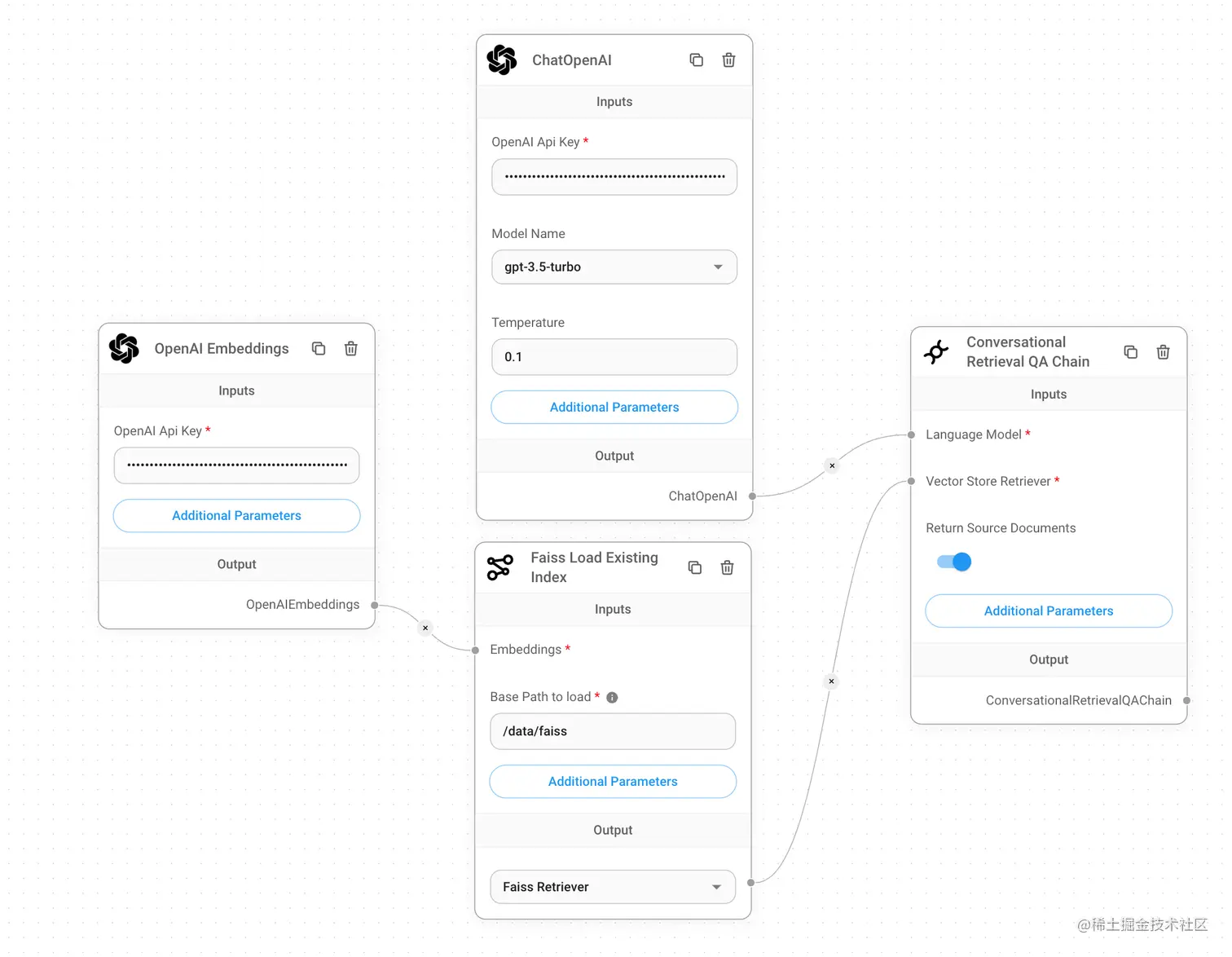
训练和使用独立
最好的生产实践是使用两个流程。一个用于训练机器人,另一个用于使用机器人,这样就可以多次运行训练部分。上面的流程,使用的是Faiss Upsert Document ,是将向量插入向量数据库,所以这其实是用来训练数据的,这一步无需每次都执行,这样也耗费tokens,因此我们可以再新建一个chatflow并将Faiss Upsert Document替换为Faiss Load Existing Index节点,并填写设置信息。如下图,就从已有的向量数据库执行查询就行,在使用时就用这个流程。
最后将文章中的几种FlowChat流程图对应的文件贴一下地址,需要的可以直接点击下面链接导入使用
总结
本文介绍了无需编写任何代码仅靠拖拽便可轻松构建AI应用的Flowise这一强大工具的部署和使用方式,并以自己博客网站为例,教大家如何在几分钟内训练网站或者文档数据,创建自己的网页聊天机器人。
