

把大象装冰箱里需要三步,使用 whisper 做一个语音聊天 bot 也是如此。
整体的思路比较直观,一录音、二转写、三聊天:
- 使用
pyaudio监听麦克风输入,每 30 毫秒采样一次,然后把一定时长的采样数据存储成音频文件; - 调用
faster-whisper对音频文件进行转写,获取文本; - 将文本发送给
ChatGPT生成回复。重复以上过程,就实现了一个简单的语音聊天模式。
项目的流程如下图所示:
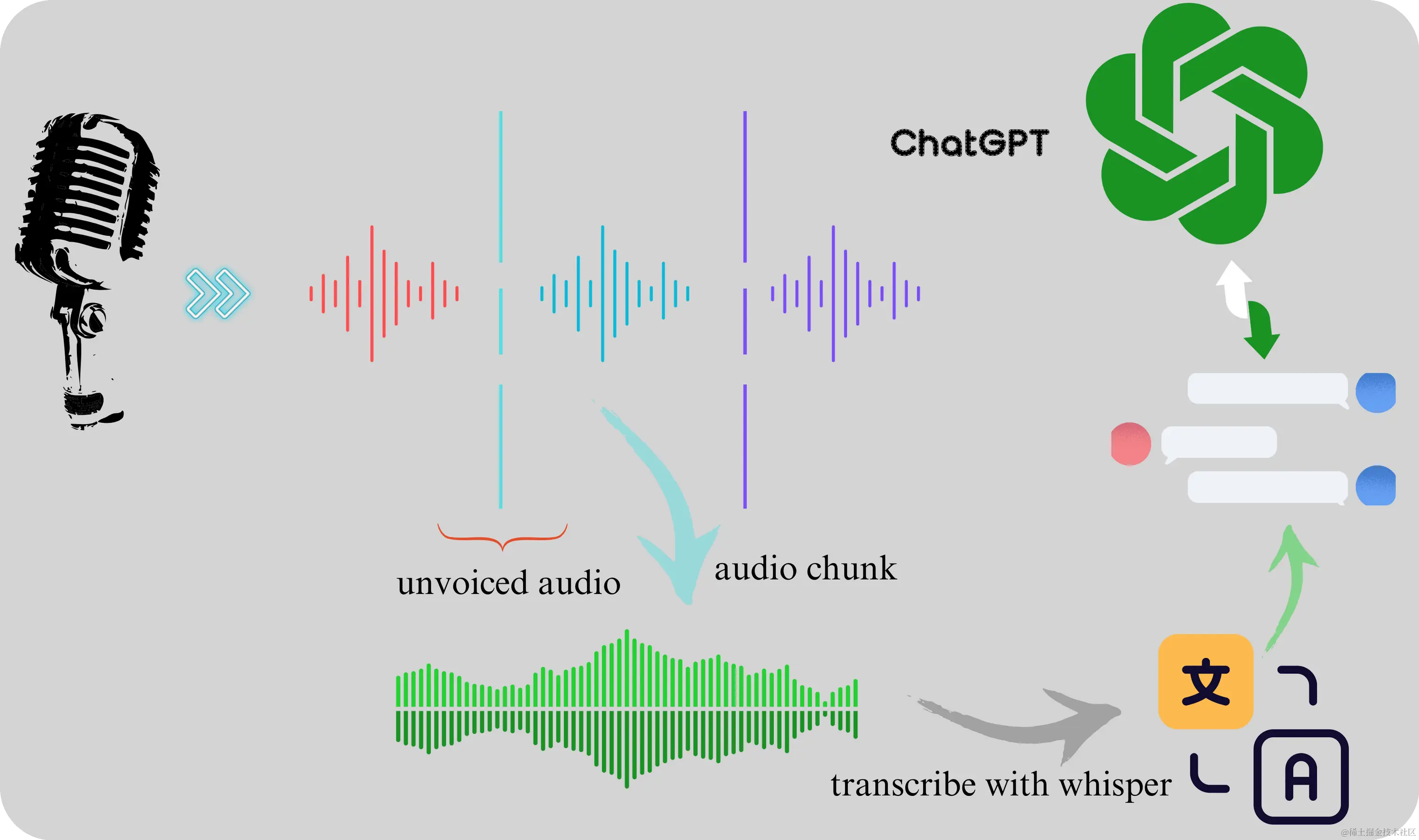
低延迟语音转写
语音转写底层模型是 OpenAI 开源的 whisper,效果最好的版本是 large v3。这个版本的英文字错率在 5% 左右,中文的字错率约在 10% 左右,这个水平勉强够用。实际体验下来,多数情况下也都能正确转写,但发音不够清晰时,就可能识别错误,比如“三国演义”转写成“三观演义”。
Whisper 的转写效果在开源模型中算是比较好的,但是速度不够快。 一段时长 13 分钟的音频使用 Tesla V100S 大约需要 4m30s,最大显存占用也有 13GB。Faster-whiper 模型是在 whisper 的基础上使用 Ctranslate2 进行了重写,速度上有 4 倍的提升,内存占用上也有显著减少。比如同样 13 分钟的音频,faster-whisper 的转写时间减少到 50s 左右,显存占用也降至 4.7GB。
使用 Kaggle 的 T4x2 GPU,实测采用 faster-whisper 去转写一句 10 秒左右的语音,时间约在 0.7 秒以内,这个速度已经可以满足(伪)实时转写的需求了。
如上所述,音频是通过采样得到的,但音频信号的输入是连续的,whisper 只能离线转写,不支持流式。为了模拟流式转写,需要把音频信号转换成一小段一小段的音频,然后再传递给 whisper。
音频的截取考虑了两种方案,一种是按固定时长截断音频输入,另一种是整句截取。前一种延迟有保证,但转写效果差;第二种转写效果好,但延迟不好控制。因为这个项目不是一个严格的实时转写,延迟 2 秒也好,5 秒也好,对体验影响不大,权衡转写效果与延迟,最终选择了第二种方案。
方案一:按时长截断音频输入
使用 pyaudio 监听麦克风输入,每 30 毫秒采样一次,如果检测到音频超过预设时长,则截断音频,输出 wav 文件,然后调用 faster-whisper 进行转写。
这种方案的好处是实现简单,延时可以做到很低,比如每 0.5 秒截断并转写一次,那理论上延迟可以低到 0.5 秒。当然,前提是机器性能足够好,比如有一块 4090 GPU,这种情况下转写的延迟可以忽略不计。
但缺点也很明显,就是转写错误比较多。因为截断的时间点很有可能位于一句话中间,这会导致音频转写时缺少上下文,转写错误率会更高。说到这里,刚好最近在 YouTube 上看到一个类似的项目,视频主声称搞了一个超低延迟的语音转写服务,但我分析了一下视频,发现转写出来的结果中有明显的漏字现象,而且有后期剪辑的痕迹,我猜测他可能是用了这种方案,导致转写效果并不理想。
方案二:整句截取
借用 webrtcvad 监听麦克风输入,当检测到语音输入时,就开始录音,直到检测到有一段连续的静音时间,比如 0.5 秒,就认为一句话结束,然后输出 wav 文件,然后再调用 faster-whisper 进行转写。
这种方案的好处是可以保证音频的完整性,拿到的音频基本是完整的一句话。 但缺点是:
- 延迟高:实现起来比较复杂,而且会带来一定的延迟,特别是在一句话比较长且中间没有长停顿时,这种延迟就会更加明显。
- 上下文信息仍然不足:虽然可以保证一句话的完整性,但这一句话的前后上下文信息还是缺失的,转写效果还是会受到影响。
算力不够的困扰
理想情况下,获取到音频后,立即调用 faster-whisper 进行转写,然后再调用 ChatGPT 生成回复。但实际上录音设备(比如手机、旧笔记本)可能性能有限,无法满足这个需求。比如我手里的这台 2015 款 MacBook Pro,光是把 faster-whisper 跑起来,CPU 就到 100%,而且还间歇性卡顿。无奈只能把音频录制与转写服务分开,录制完音频后,先把音频同步给转写模块,再调用 faster-whisper。

转写模块使用了 Kaggle 的 T4 GPU,录音时按最长 0.5 秒的静音进行截断,本地录制完音频先同步到 redislabs 上的 redis 实例上,Kaggle 端的转写模块从 redis 上拉取音频,然后进行转写。
实际用起来,多数情况下延迟都能控制在 2 秒左右。但有时候为了迎合这个“静音检测”,说完一句话,需要刻意停顿一下。
当然,关于降低延迟还有其他的优化方向,也都是一些算力换体验的方法。如果 GPU 强劲,可以结合划窗录制音频的方案,录制完之后立即转写。监控到长时间的静音时,其实静音开始前的那一段已经转写完成了,直接返回对应的结果即可。
这种模拟方案的整体效果依赖于几个方面:一是音频数据获取方案,二是转写模型的性能,三是数据传输的效率。优化的极限也只是在零点几秒的范围内,把一句话尽可能转写正确,这对于专业的实时转写场景来说是不行的
,但对于一些简单的场景,比如语音聊天 bot,这个方案已经足够了。
语音聊天 bot
拿到文本之后,后面的事情就简单了,调用聊天 bot 接口传入文本即可。Bot 的智能程度,取决于背后模型的能力,目前 GPT-4 还是当之无愧的 No.1,就是费用上有点高。
这个项目里采用的模型是 ChatGPT,免费且效果佳。将 ChatGPT 转成支持 RESTful API 的服务参考了最近比较热门的一个 ChatGPT api wrapper 项目 pandoranext,这个项目可以将 ChatGPT 背后的 GPT 模型代理成一个 API。可惜的是,由于多种原因,项目作者即将放弃后续维护,依赖的一些服务也将于本月底关停。
如果聊天服务这部分一定要采用开源模型,英文模型可以部署 mixtral 7x8b,中文模型可以考虑零壹万物开源的 Yi-34B-Chat。 截止到 2024/01/29,Yi-34B-Chat 在 LMSYS Chatbot Arena Leaderboard 排行第 13,是中文模型中最好的。
代码与相关资源
- faster-whisper github 页面:github.com/SYSTRAN/fas…
- openai/whisper: github.com/openai/whis…
- 代码仓库:github.com/ultrasev/st…
