背景
基于chatGPT来做翻译,不是什么新鲜事,如果你有使用chatGPT的习惯,很可能你已经在使用chatGPT进行翻译。但本次讨论的,或者说AI翻译需要解决的问题,和我们平常理解的翻译有所不同。
我们需要翻译的内容是游戏内道具、物品、任务、技能、对话、背景介绍等游戏内容的文案翻译,这种翻译对于翻译质量、本地化程度都有非常高的要求,因为这已经可以定义为核心资产。基于此,我们需要对GPT有针对性的优化,才能达成我们的目的。故,本次讨论的翻译,是质量高、本地化程度高的精准翻译。
问题&难点
尽管我们使用了GPT,加上自己的一些优化和方法论,翻译效果有明显提升。但比较遗憾的是,我们不得不得出,目前纯机翻依然无法替代专业翻译这样子的结果。主要有以下一些问题和难点。
一、前后翻译不一致。
对于同样一个词语,在多个语料中重复出现,但GPT每次翻译都不一致。
二、翻译的准确率,怎么提升?
如果只告诉GPT你需要翻译,那么准确率其实和通用的翻译工具的准确率,没有太大差别,如何发挥出GPT的优势?
三、GPT机翻的效果,怎么快速评定?
当我们尝试使用GPT来做翻译工具,那么它翻译的结果如何?我们每次的调整,效果如何?翻译质量评定的速度,决定了你调优的速度。
解决问题的方法论
一、前后翻译不一致。
1、术语
在翻译中,有个名词–【术语】,指将某个词语固定翻译成某个词。那么这里又会延伸出两个问题:
- 如何快速确定哪些词要作为术语
- 如何让GPT知道术语的存在
将待翻译内容,进行分词(用开源分词工具)之后,统计每个词的词频,之后将词频较高的和词语需要特殊翻译的作为术语,之后由专业翻译人员翻译成对应语言,即为术语。
这里我使用的是jieba分词:
bash复制代码github.com/wangbin/jiebago
在大批量的翻译中,分词完定出术语表,那么这个术语表其实也挺大的,少的几百个,多的上千,取决于你的语料多少。那么,如此庞大的词库都作为提示词,在prompt中给到GPT,明显是不可行的。所以,我们采用的是,当需要翻译的语料中有出现术语表中的词语时,才将这个词语作为术语,在prompt中给到GPT。大概的形式如下:
css复制代码以下为专有名词:
遇到[%s]请翻译成[%s]
2、上下文
由前面可知,定术语其实不是一件容易的事,需要有人工的参与。是否有其它更智能的方法来解决问题呢?答案就是上下文,事实上,不仅仅是翻译,GPT几乎所有的应用场景都可以用上下文来提升效果。
那么何为上下文呢?在中译英的翻译场景中,我举个例子吧。假设你有一批旧语料,其中有,【黄白之术】->【Midas Touch】。那么现在有一个语料:【黄白之术不是万能的,还需要一些其它的办法。】,这个怎么保证【黄白之术】按照之前的翻译结果来翻译呢?最好的方法就是通过将【黄白之术】的翻译结果当成上下文,如下:
arduino复制代码curl https://api.openai.com/v1/chat/completions
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "system",
"content": "Please translate the following into English."
},
{
"role": "user",
"content": "黄白之术"
},
{
"role": "system",
"content": "Midas Touch"
},
{
"role": "user",
"content": "黄白之术不是万能的,还需要一些其它的办法。"
}
]
}'
以上,就可以让GPT知道【黄白之术】的翻译已经固定,参照之前翻译即可。但,这又引出了一个新问题:我怎么知道待翻译的语料【黄白之术不是万能的,还需要一些其它的办法。】,在已有的旧语料中,已有【黄白之术】
这个翻译呢?这里就需要引入两个概念:
- Embeddings:详情可以看GPT官方的文档(platform.openai.com/docs/api-re…)。说白了就是所有的文本都可以转换出一个向量值,这个向量值在GPT中,由1536个浮点数组成的数组表示。
- 向量数据库:常见的有PostgreSQL 、Qdrant等。可以存储向量值,并且可以检索某个向量值与数据库中已有的向量的关系。
除了旧有已知翻译的语料可以当做上下文意外,为了保持每次翻译的前后一致,其实也可以把先机翻出来的结果,当做上下文。举个例子,如果【黄白之术1】先进行机翻被翻译成【Midas Touch1】,那么在翻译【黄白之术2】时,也可以将【黄白之术1】的翻译结果作为上下文,这样子就可以保证前后翻译一致。
3、热度/概率
如果了解GPT的基础原理,很容易就知道,GPT其实是个文本接龙游戏,它根据已有的文本,推算出下个字出现概率最大的文本集。然后再跟你传参的热度/概率:temperature或top_p从文本集中给出最终一个结果,之后,循环这个过程。
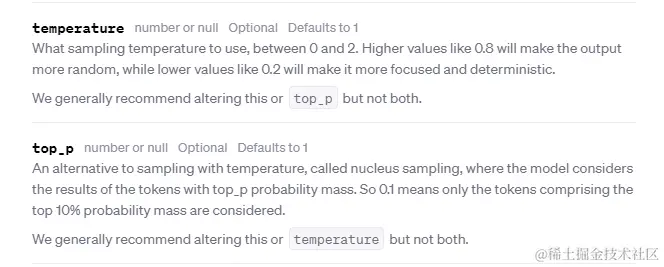
由上可知,在翻译的场景,如果想尽可能保持前后的翻译一致,以temperature为例,则是尽量低为好。推荐为0.1以下。
二、翻译的准确率,怎么提升?
1、prompt优化
在所有GPT的应用场景中,大家都在说prompt优化,都知道要优化prompt。但是,很少人会告诉你,应该怎么优化,优化到什么程度,怎么验证效果。对于这个,我有以下一些方法:
- 给例子:所有对GPT的要求,尽量给出2~3个例子,GPT会更好的理解。比如我要翻译的时候,注意首字母大写:
css复制代码 大小写:
示例:【开始游戏】 → 【Start Game】
示例:【返回主菜单】 → 【Return to Main Menu】
-
如果可以,用英文写prompt。
-
调整prompt,最好有现成的语料和正确的翻译,这样子可以在调整prompt后,快速机翻出结果,对比正确翻译,从而知道prompt的调整是否是正向。而,如何评定机翻效果,在下一节会详细讲解。
2、人工抽检
我们已经知道,机翻无法完全替代人工。说白了,机翻更多是提升人工翻译的效率,或者替代部分人工。那么,很容易就可以知道,由人工逐步抽检,比如先机翻出10%,然后再人工校对这10%,然后将这10%作为正确翻译语料,理论上下一次机翻,准确率是会有提升。那么就会引出一个问题,如何最大限度的,提升人工抽检之后的准确率。答案显而易见,让抽检的样本具有代表性。什么意思呢?
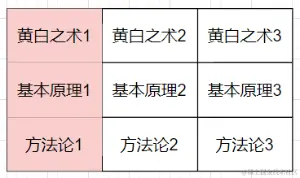
假设有9条待翻译语料,如上图所示。理论上来说,红色框的3条语料,如果已经人工校对过,或者说已经翻译准确,那么剩下的所有文本,则可以全部翻译正确。那么红色框中的语料,则称为具有代表性的语料。
那么,在实际的翻译场景中,我们如何实现上面的例子。其实就是将每条待翻译的语料,通过向量,查找与它相似度高的语料,最后做统计。拥有相似度高语料数的语料,则为具有代表性语料。
理论上而言,每次机翻之后都人工抽检一部分之后,得到抽检部分的正确翻译,再应用这部分正确翻译进行下一轮机翻,准确率会一直提升,直到全部翻译完成。
3、合并翻译
对于无关联的语料在进行翻译时,一般都是逐条进行翻译。而对于人物对话、背景介绍、剧情介绍这样子的内容,则最好将整段对话合并一起翻译,GPT能更好的理解前因后果,增加翻译的准确性。
三、GPT机翻的效果,怎么快速评定?
在【prompt优化】部分已经提到,在对prompt进行调优时,提前将待翻译语料,进行人工翻译,得出正确翻译,再将机翻结果与正确翻译进行对比,就可以得出,promept调整是否为正向。那么,机翻结果,如何与正确翻译进行对比呢?
ruby复制代码<https://arxiv.org/ftp/arxiv/papers/2202/2202.11027.pdf>
以上是一篇比较专业的论文《关于机器翻译评测研究的综述性报告》。与我们需要解决的问题非常贴合。我总结一下,大概有以下几种方法:
hLEPOR/nLEPOR 这是文章作者提出的方法,在WMT历年的评测竞赛中屡次获得好成绩。hLEPOR融合了长度惩罚、精确度、召回率、词序差异惩罚等多方面指标,nLEPOR进一步采用n-gram模型。这类方法表现稳定优异。
BLEU
BLEU方法由于简单易用,已经被广泛应用于机器翻译的评测。尽管有一些已知缺陷,但经过多年发展,仍然是一种比较可靠的评测基准。
BERTscore
基于BERT等预训练语言模型的BERTscore方法,利用神经网络强大的语义建模能力,能够更准确地评估翻译质量。这类预训练模型方法是当前的研究热点。
METEOR
METEOR同时考虑精确度和召回率,并使用语言学特征,能够相对全面地评估翻译质量。它与人工评价的相关性较好。
COMET
COMET方法结合多语言预训练模型与源语言文本,拟合人工评分,是当前效果最好的基于深度学习的评测模型之一。
而目前比较通用的,就是hlepor/nlepor和BLEU。
通过机翻结果与正确翻译结果,跑出hlepor分值或者BLEU分值,对比prompt调优前后的分值,即可知,调整是否为正向。BLEU分值达到多少靠谱呢?这里有一份腾讯的实验报告,仅供参考:arxiv.org/pdf/2301.08…
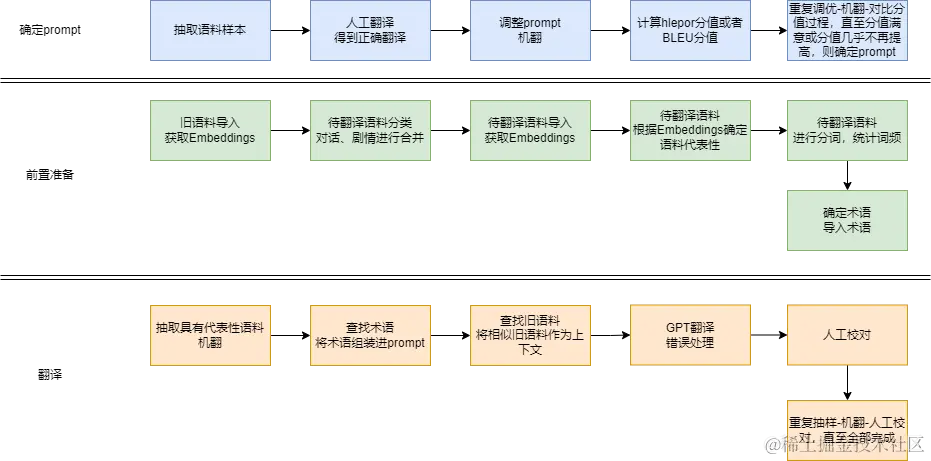
翻译流程图