
前言
随着人工智能技术的飞速发展,OpenAI的ChatGPT、Google的Gemini、讯飞的星火、百度的文心等等,已经成为当下最热门的话题。而这些大型语言模型,它能够生成类似人类的文本、代码、翻译语言,甚至还能写诗、编故事等等一系列操作。
我们将以小白的视角,从安装和配置开始,一步一步教你如何快速让你的微信、公众号具备这些大型语言模型功能。
OK!话不多说,直接开始!
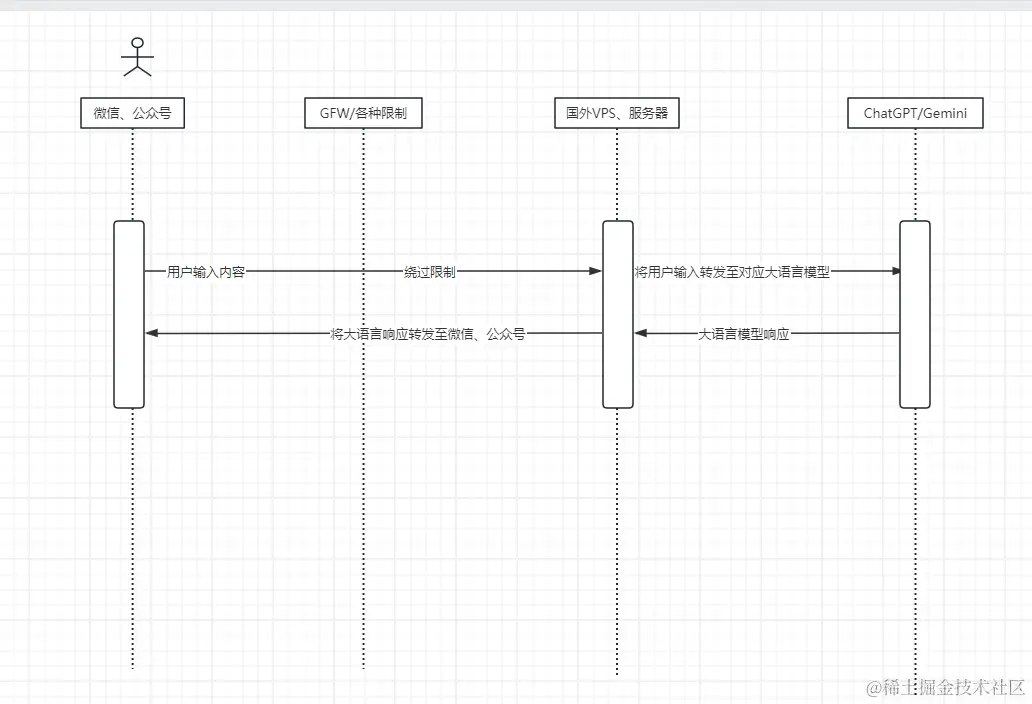
如图所示
微信、公众号要想具备这些大语言模型功能,则需要调用对应模型的API,而ChatGpt/Gemini不支持大陆访问
因此我们需要准备一些东西
- 要想跨过限制,注册登录并且生成对应的API_KEY,你需要一个科学上网工具 点我即可注册
- 我们还需要购买一个IP为国外并且不受限制的服务器。
1、如何购买国外服务器?
这里我以我经常用的服务商为例(我直接简称evo)
1.1 购买并使用evo服务器
-
点此该链接即可注册:点我注册。
-
注册登录后,即可显示对应的控制台页面

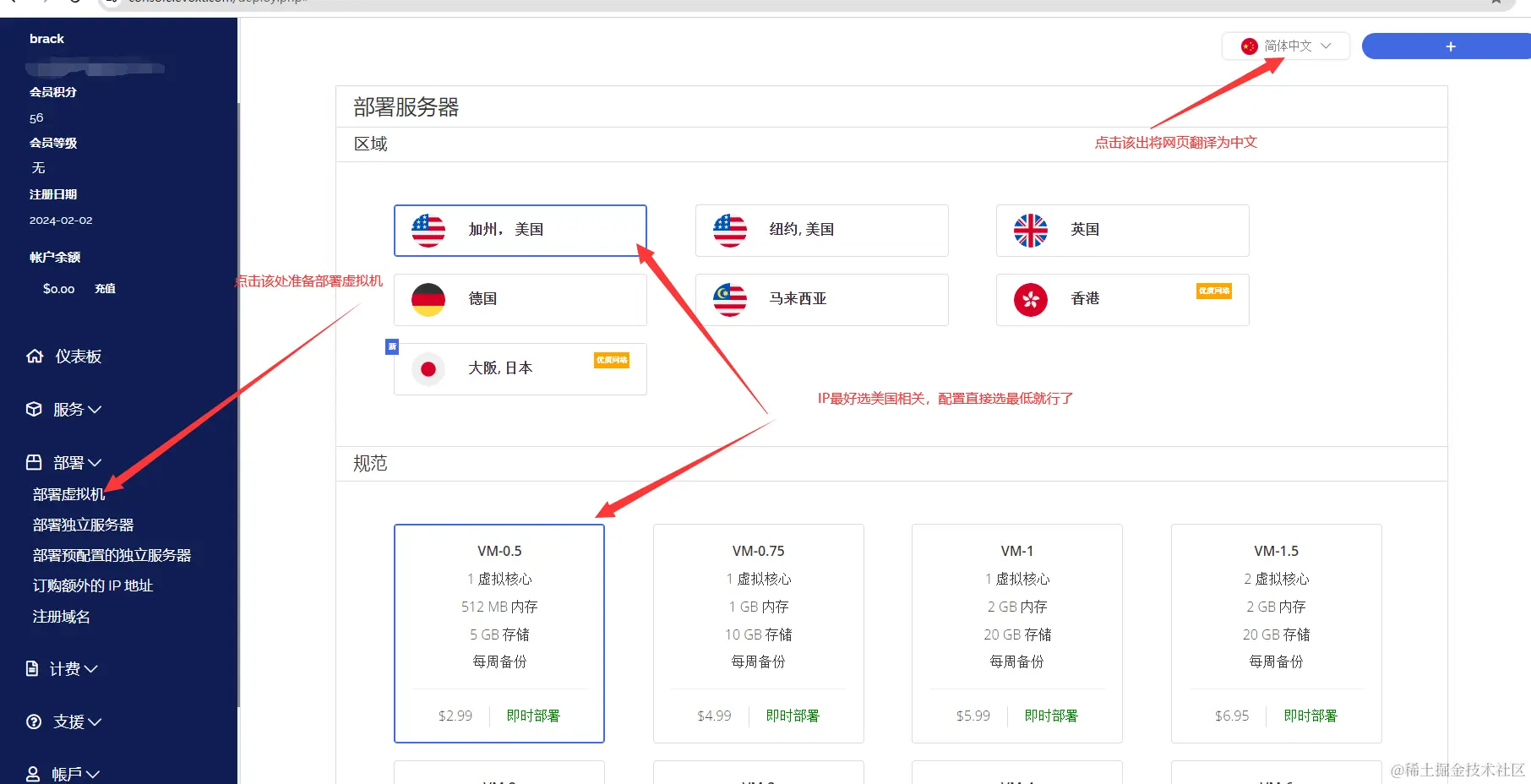
如图所示
- 点击右上角可切换语言
- 点击部署——部署虚拟机,即可显示可购买选项
- 最好选择美国相关服务器,服务器配置选最低即可
-
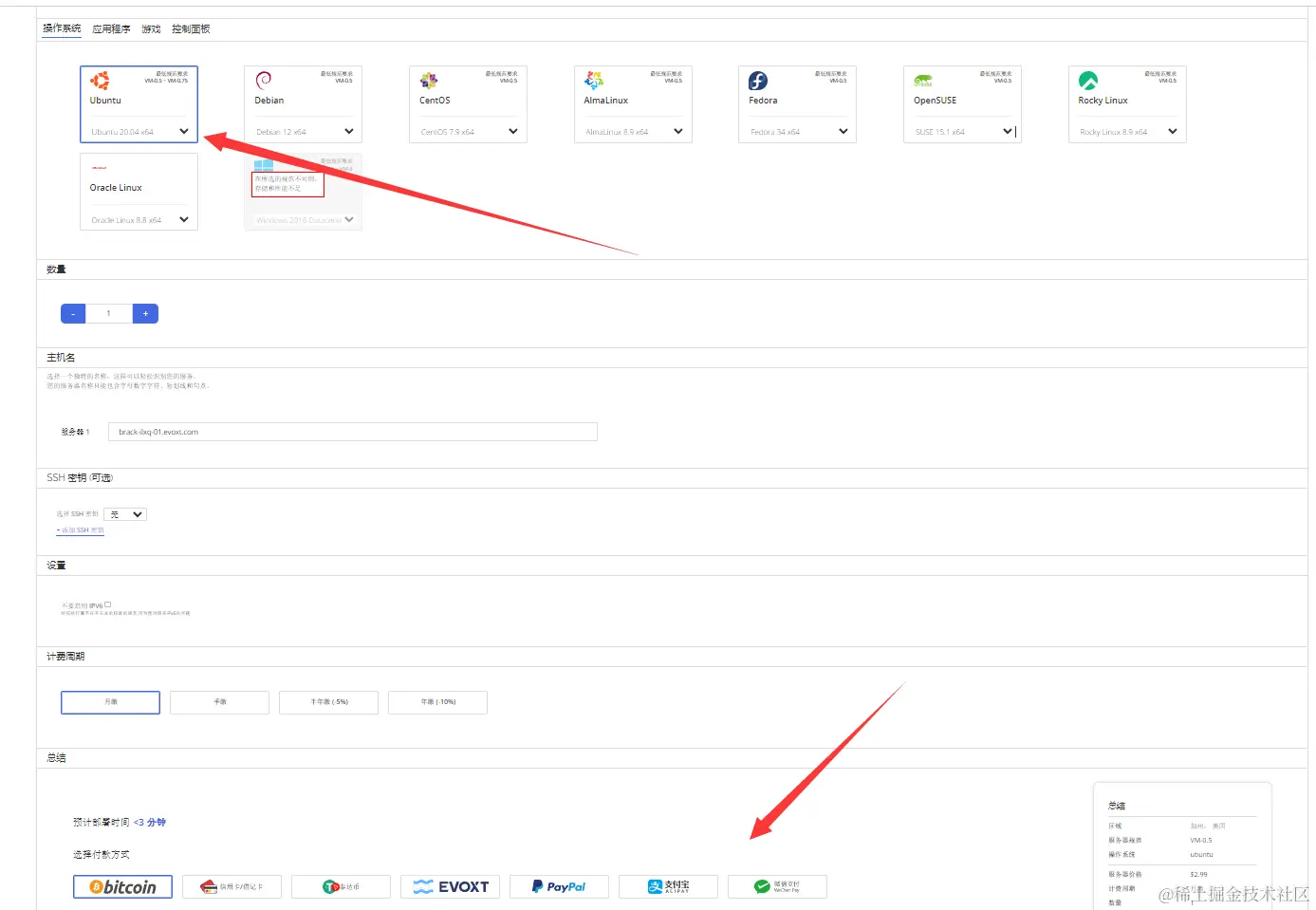
选择系统以及支付方式
如图所示
- 系统直接选择默认的Ubuntu20即可
- 下面支付方式可选择我们熟悉的支付宝/微信支付
- 当然我这还有个优惠码
AFF143-VPS234,虽然优惠不多,但能省一点就省点
-
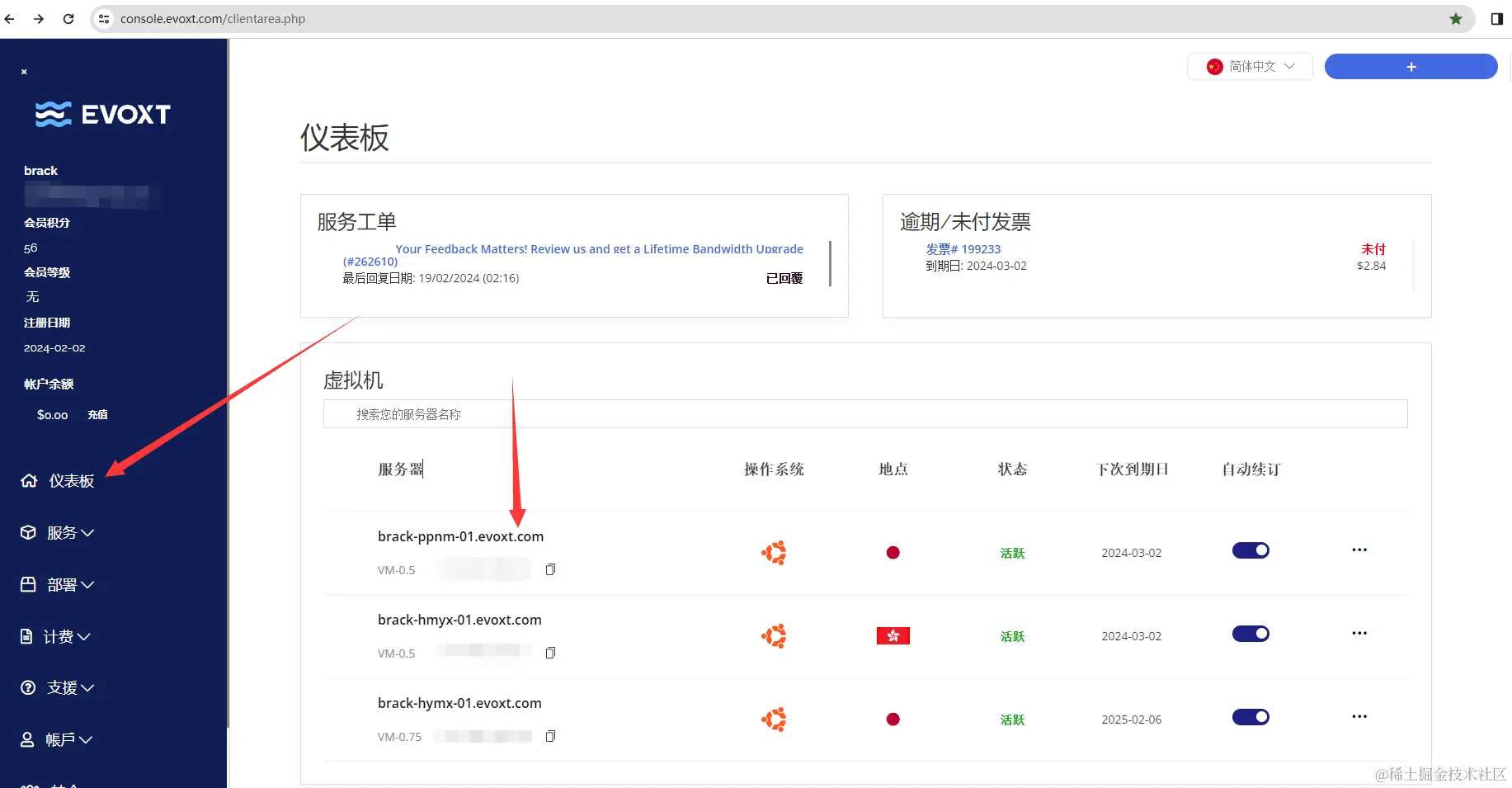
查看服务器
如图所示
- 当你服务器购买成功时,点击仪表盘,将会看到你对应购买的服务器
- 点击对应的服务器,就会展示对应的服务器详细信息
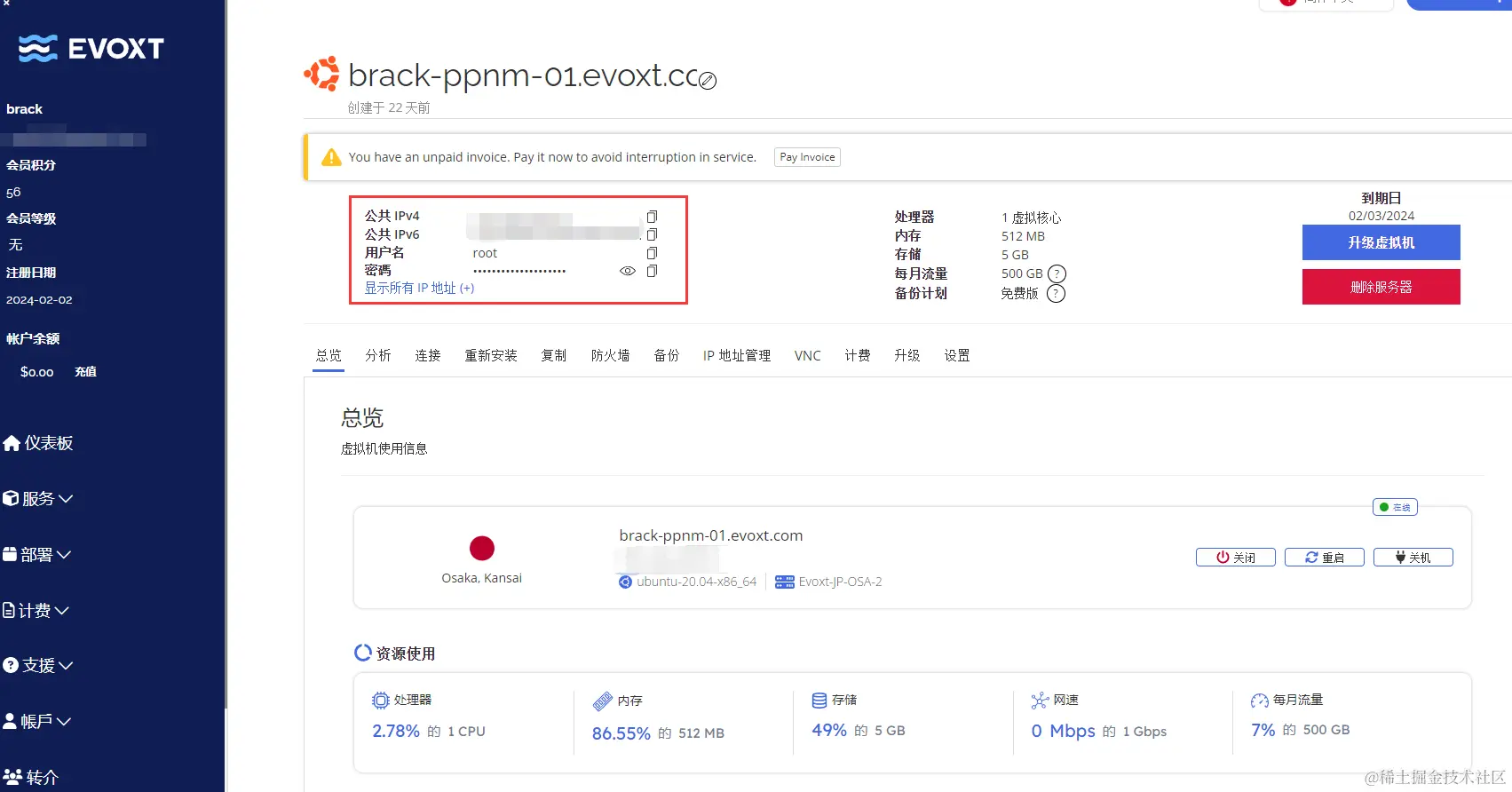
到这evo服务器已经购买完成。其他服务商购买流程如出一辙,几乎都是大同小异。这里就不再详细说明了。
接下来就是讲解,如何搭建服务了
2、服务器搭建
本文以FinallShell工具进行讲解:点我下载
1. 用FianllShell连接服务器
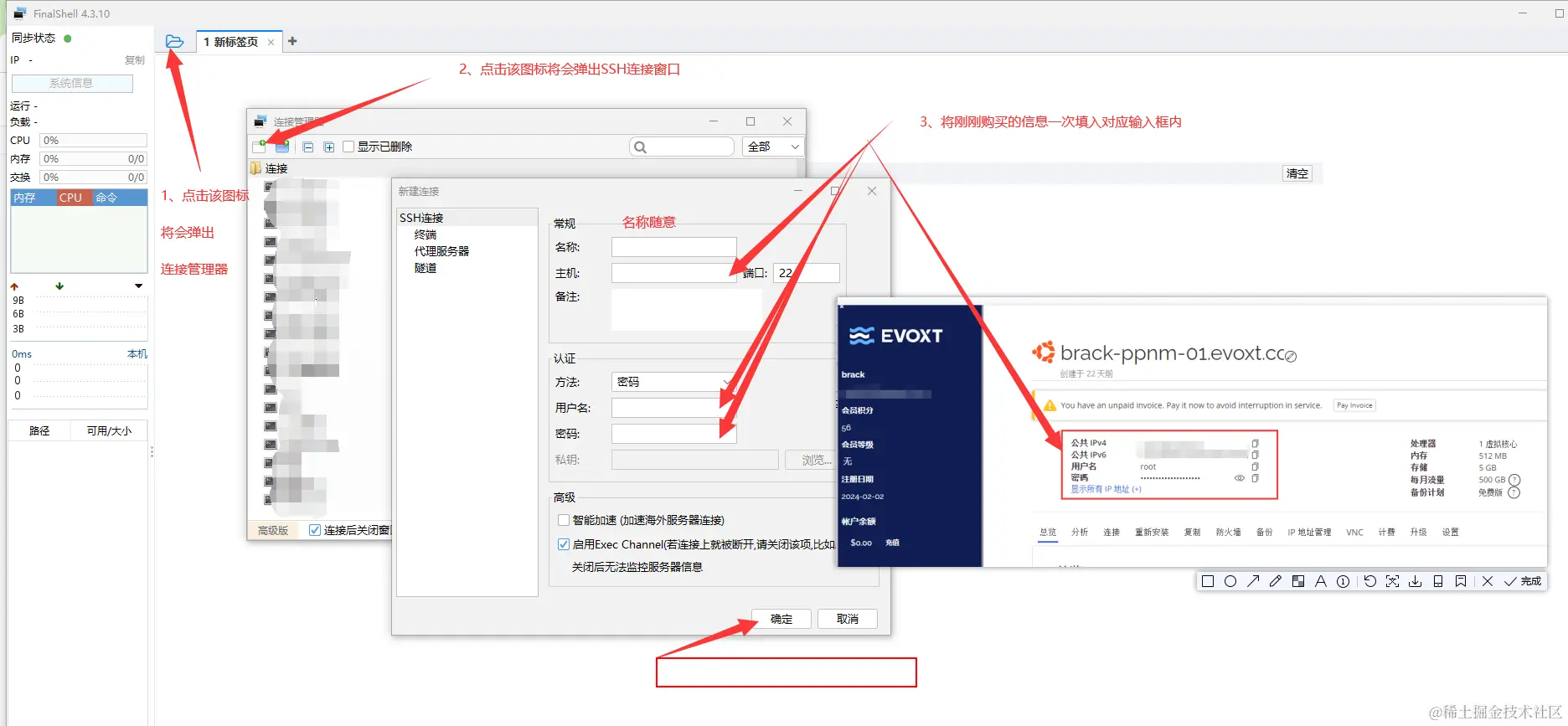
如图所示
- 点击对应的图标直至弹出新建链接
- 再将服务器详细信息依次填入对应输入框
- 最后确认无误后,点击确认即可
- 创建成功后,连接管理器将会显示你创建好的服务器
- 双击点击对应服务器即可进行连接
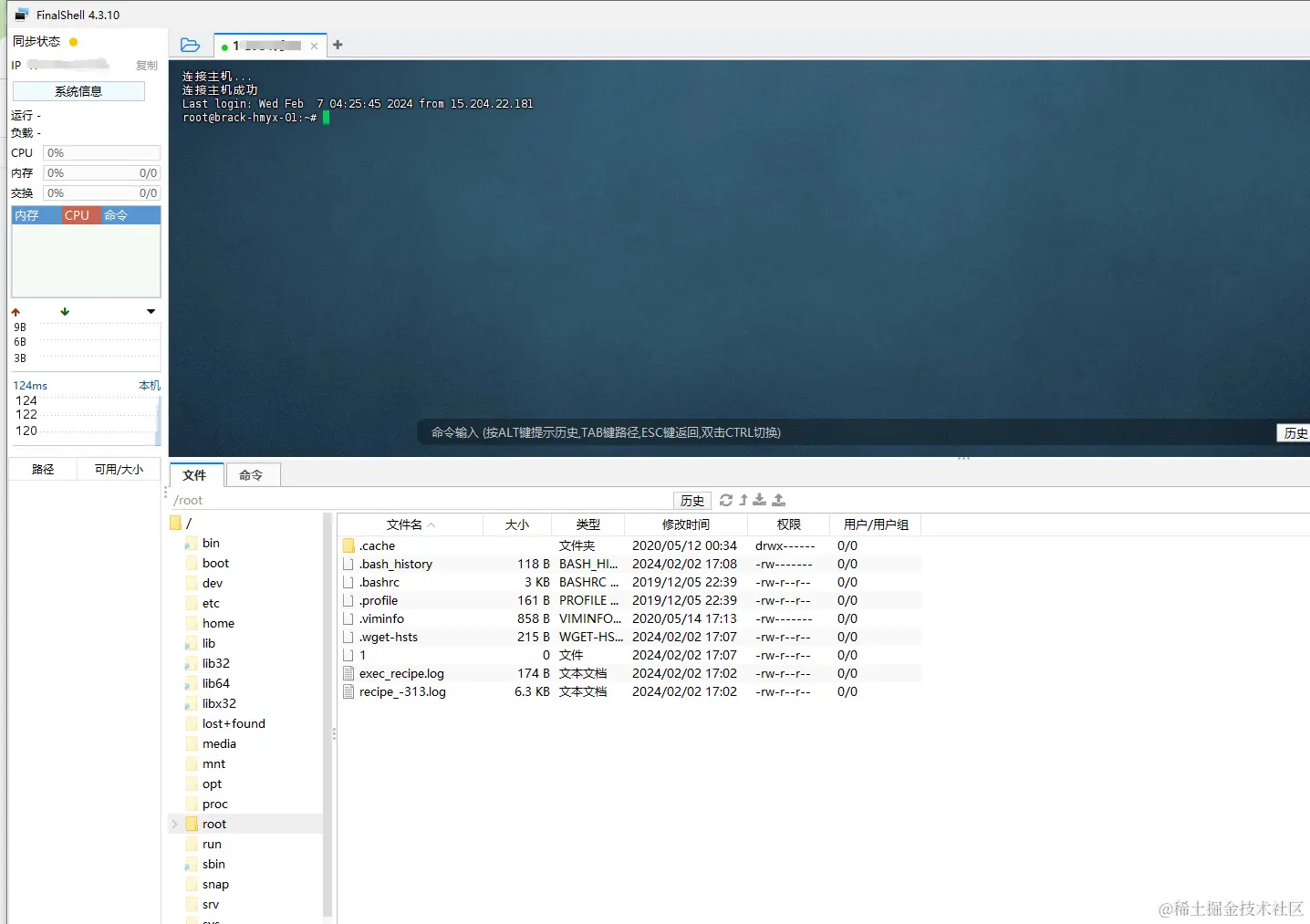
如图所示
这种没有任何错误就是链接成功了,如果报错了,可能是你的服务器信息填入有误。或者你的IP被GFW墙了,此时需要在对应服务商开工单,让他们给你更换IP地址。
2.服务器配置Python3环境
服务器安装配置Python3环境 (大多数服务器默认自带Python3,使用 python3 --version 命令如果显示了对应版本,那就可以忽略该步骤)
-
更新软件包列表并安装必备组件:
ssh复制代码$ sudo apt update $ sudo apt install software-properties-common
- 将Deadsnakes PPA添加到系统的来源列表中:
ssh复制代码$ sudo add-apt-repository ppa:deadsnakes/ppa
-
启用存储库后,请使用以下命令安装Python 3.8:
ssh复制代码$ sudo apt install python3.8
3. 使用命令搭建配置服务
- 使用
apt-get update命令更新服务器相关配置 - 下载源码并进入对应项目文件夹
ssh复制代码git clone https://github.com/zhayujie/chatgpt-on-wechat cd chatgpt-on-wechat/
-
安装对应依赖
ssh复制代码# 必选依赖 pip3 install -r requirements.txt # 可选依赖,语音、tool插件等功能需要(微信公众号使用的话,必选) pip3 install -r requirements-optional.txt
-
复制项目中的模板文件
config-template.json,来生成最终起效果的配置文件config.json,你可以通过执行以下命令完成:
ssh复制代码cp config-template.json config.json
- 打开
config.json
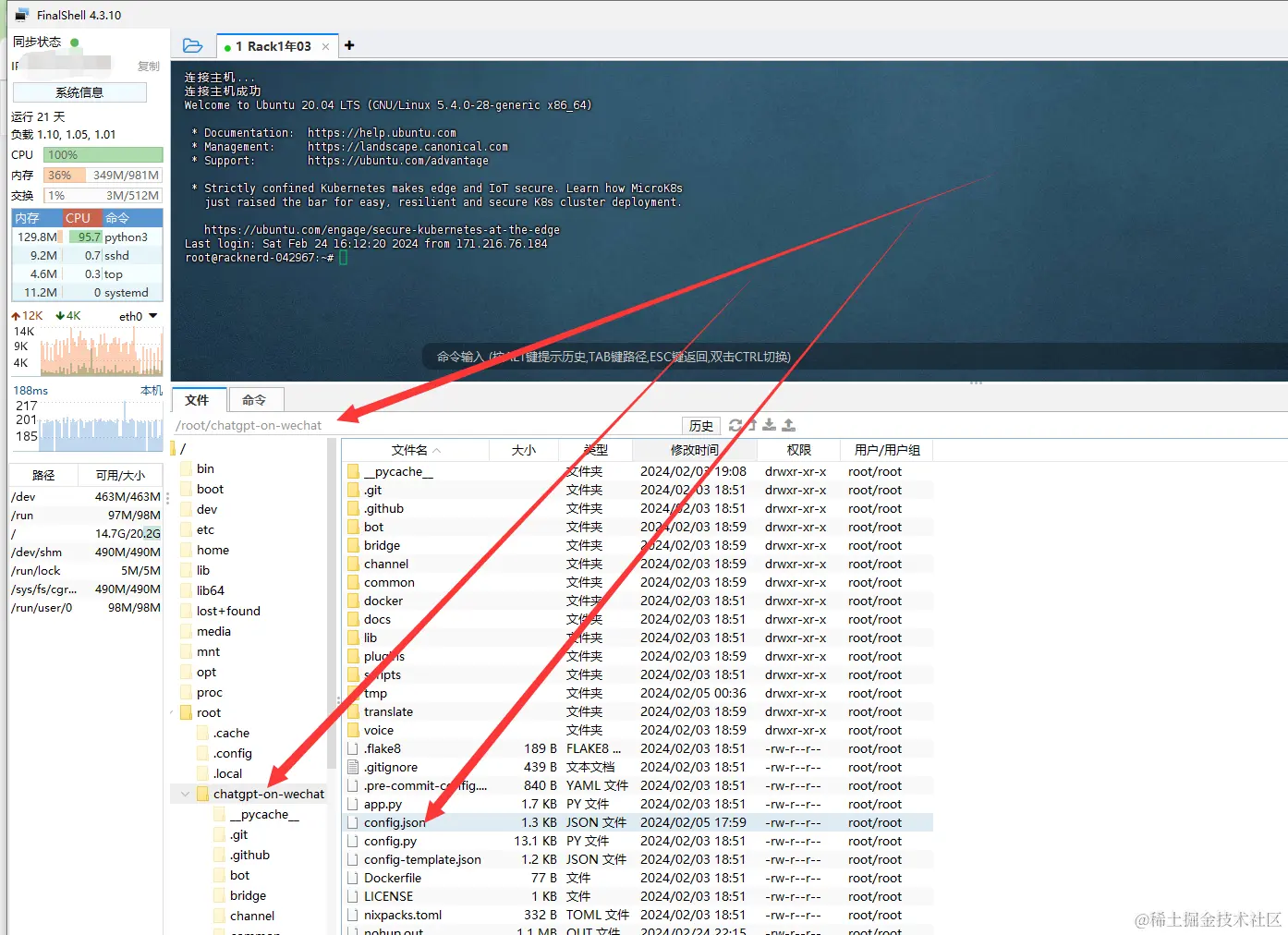
如图所示
在项目 chatgpt-on-wechat 里面双击 config.json 文件,将会自动下载并打开
-
编辑
config.json《个人微信使用》如图所示
-
channel_type表示通道类型,也就是说是个人微信使用还是公众号使用以及其他聊天平台使用只能配置一个 -
model表示使用哪个大语言模型,如果确定了对应的模型,那么对应模型的api_key必填 -
最下面的
LinkAI相关内容, 这个默认为不使用,没有特殊要求可以不用配置 -
gemini_api_key这是谷歌Gemini对应的api_key需要注册对应的谷歌账号,然后手动生成 点我生成ApiKey -
open_ai_api_key这是OpenAi对应的ApiKey,如若要对接ChatGpt,也需要注册对应的账号,然后手动生成点我生成ApiKey -
文章末会给出所有属性字段介绍
-
-
编辑
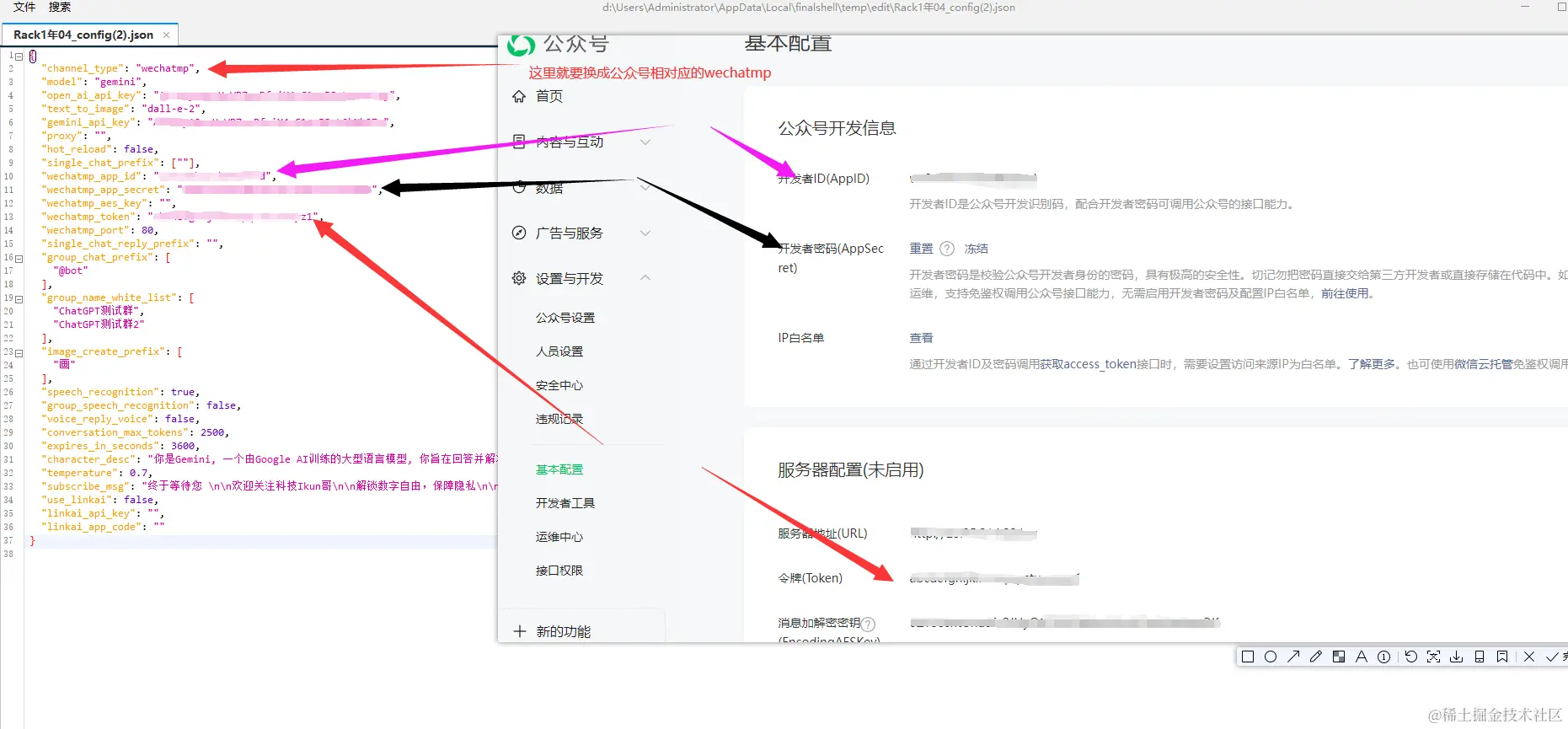
config.json《微信公众号使用》如图所示
- 当对接微信公众号时,对应的
channel_type换成了wechatmp - 新增了三个参数,对应的参数需要和公众号的保持一致
- 文章末会给出所有属性字段介绍
此时此刻
config.json已经配置完毕,接着就可以启动服务了 - 当对接微信公众号时,对应的
-
运行服务器程序《个人微信》
输入以下命令
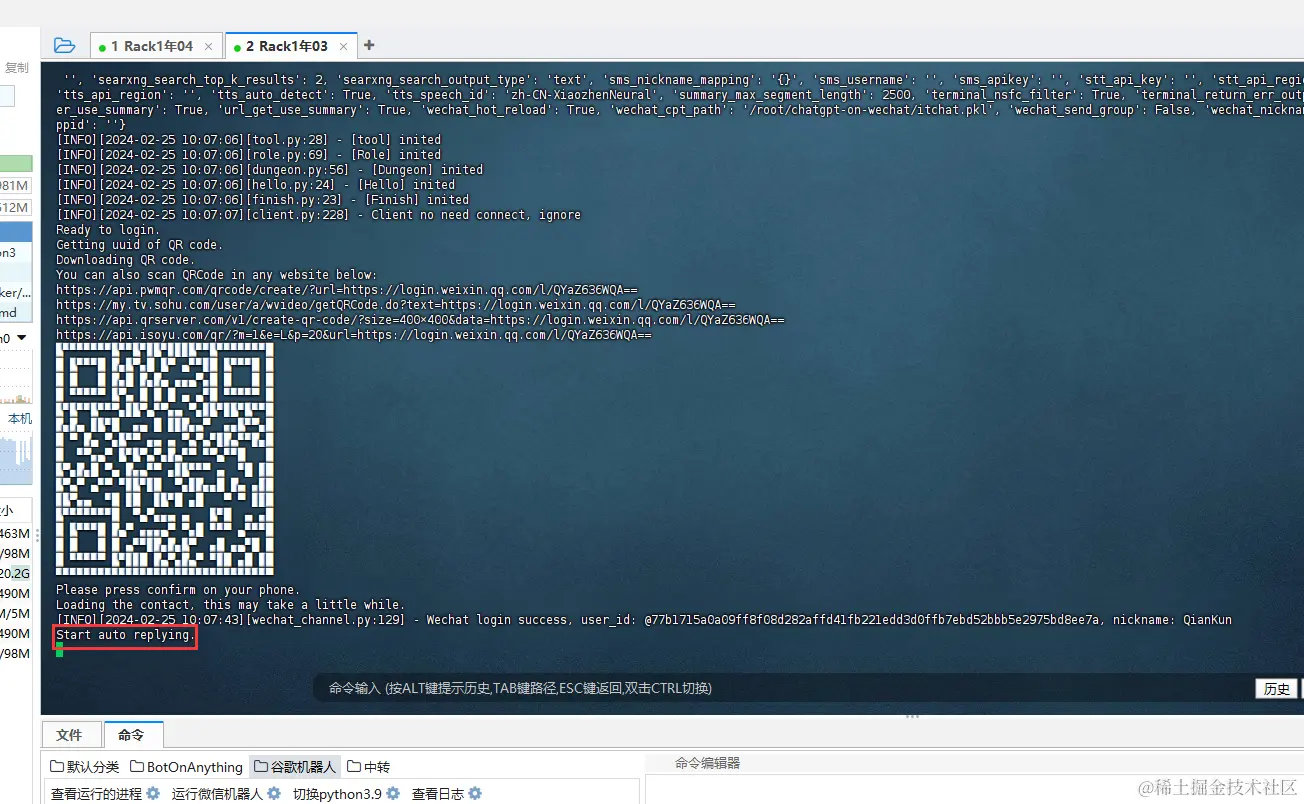
ssh复制代码touch nohup.out # 首次运行需要新建日志文件 nohup python3 app.py & tail -f nohup.out # 在后台运行程序并通过日志输出二维码如图所示
- 当出现二维码时,则说明命令运行成功了。此时此刻,需要用你的微信扫码并登录一下(想让哪个微信变成机器人就让哪个微信扫)
- 当出现
Start auto replying.英文提示时,则说明机器人已经成功运行了
-
运行服务器程序《微信公众号》
输入以下命令
ssh复制代码touch nohup.out # 首次运行需要新建日志文件 nohup python3 app.py & tail -f nohup.out # 在后台运行程序并通过日志输出二维码如图所示
- 微信公众号、个人微信以及其他平台运行的命令都一致,只不过返回的日志不一样
- 个人微信时需要对应微信扫码登录,公众号时不需要扫码登录
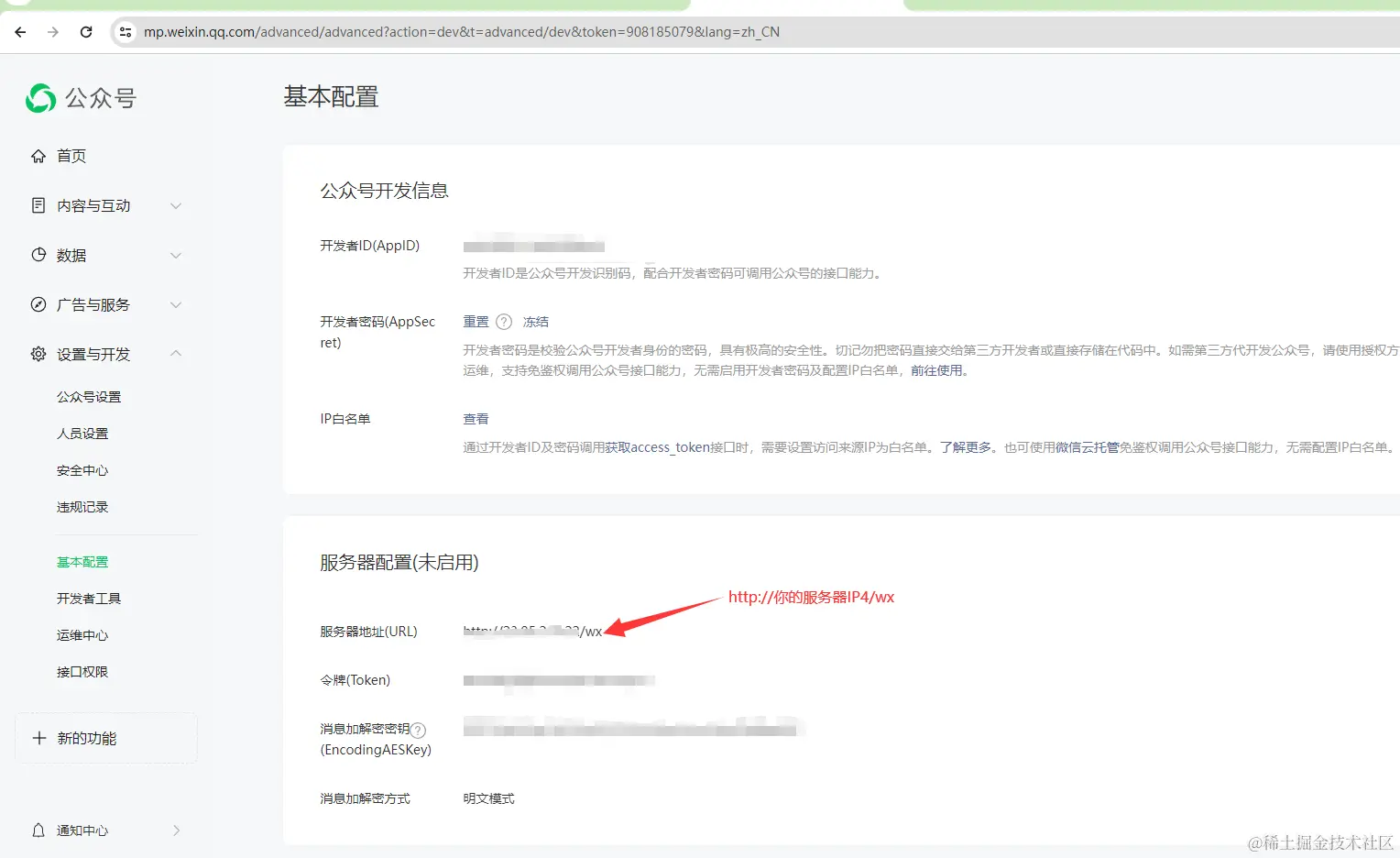
- 此时我们就需要将服务器相关信息配置在微信公众号里面 (格式:
http://你的服务器IP/wx)
到这服务器算是启动起来了,如果说要重新看日志 执行
tail -f nohup.out命令即可

4. 关闭对应服务
-
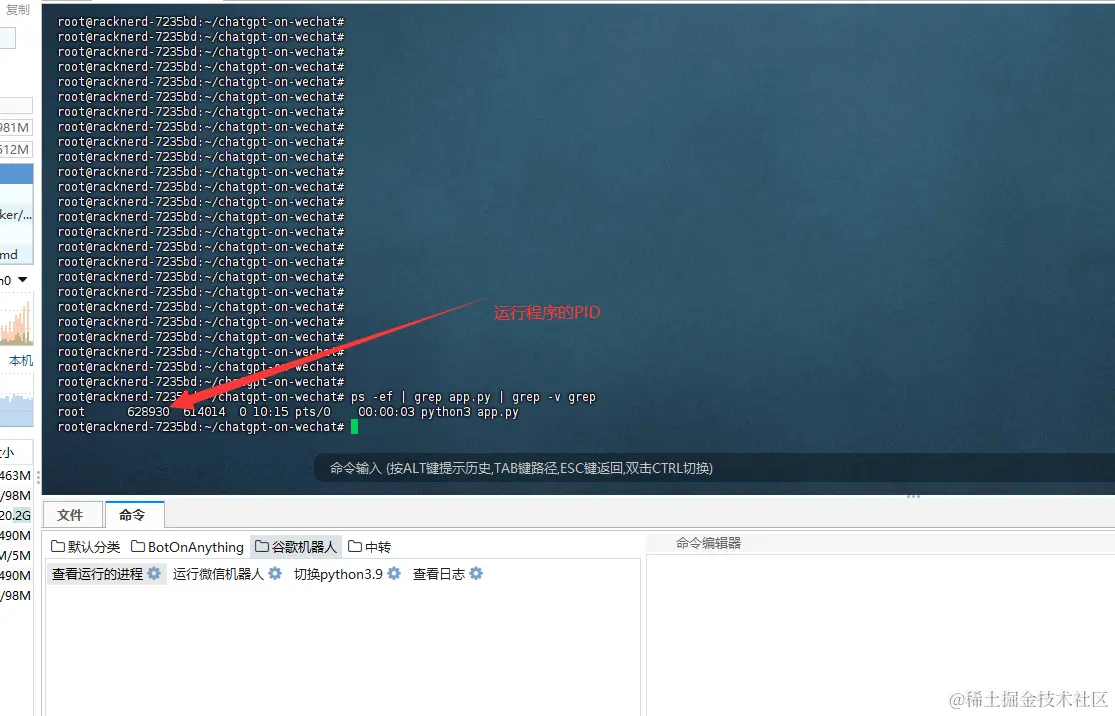
如果说想要关闭对应服务,那么得先查询服务器正在运行的服务
-
运行
ps -ef | grep app.py | grep -v grep命令查看对应的服务,
-
拿到PID后,执行
kill -9 PID即可关闭对应服务
OK,到这你的微信、公众号具备了ChatGpt相关功能,如果想要使用其他大语言模型,只需要更换关键性参数,重启服务器即可
3、config.json所有属性字段介绍
python复制代码
#--------------------大语言模型配置开始-------------------------------
# openai api配置
"open_ai_api_key": "", # openai api key
# openai apibase,当use_azure_chatgpt为true时,需要设置对应的api base
"open_ai_api_base": "https://api.openai.com/v1",
"proxy": "", # openai使用的代理
# Baidu 文心一言参数
"baidu_wenxin_model": "eb-instant", # 默认使用ERNIE-Bot-turbo模型
"baidu_wenxin_api_key": "", # Baidu api key
"baidu_wenxin_secret_key": "", # Baidu secret key
# 讯飞星火API
"xunfei_app_id": "", # 讯飞应用ID
"xunfei_api_key": "", # 讯飞 API key
"xunfei_api_secret": "", # 讯飞 API secret
# claude 配置
"claude_api_cookie": "",
"claude_uuid": "",
# 通义千问API, 获取方式查看文档 https://help.aliyun.com/document_detail/2587494.html
"qwen_access_key_id": "",
"qwen_access_key_secret": "",
"qwen_agent_key": "",
"qwen_app_id": "",
"qwen_node_id": "", # 流程编排模型用到的id,如果没有用到qwen_node_id,请务必保持为空字符串
# Google 谷歌 Gemini Api Key
"gemini_api_key": "",
#--------------------大语言模型配置结束-------------------------------
# chatgpt模型, 当use_azure_chatgpt为true时,其名称为Azure上model deployment名称
# 注意,上面你配置的哪个大语言模型,这个得model就需要配置对应的模型
"model": "gpt-3.5-turbo", # 还支持 gpt-4, gpt-4-turbo, wenxin, xunfei, qwen,gemini
"use_azure_chatgpt": False, # 是否使用azure的chatgpt
"azure_deployment_id": "", # azure 模型部署名称
"azure_api_version": "", # azure api版本
# Bot触发配置
"single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复
"single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人
"single_chat_reply_suffix": "", # 私聊时自动回复的后缀,n 可以换行
"group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复
"group_chat_reply_prefix": "", # 群聊时自动回复的前缀
"group_chat_reply_suffix": "", # 群聊时自动回复的后缀,n 可以换行
"group_chat_keyword": [], # 群聊时包含该关键词则会触发机器人回复
"group_at_off": False, # 是否关闭群聊时@bot的触发
"group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"], # 开启自动回复的群名称列表
"group_name_keyword_white_list": [], # 开启自动回复的群名称关键词列表
"group_chat_in_one_session": ["ChatGPT测试群"], # 支持会话上下文共享的群名称
"nick_name_black_list": [], # 用户昵称黑名单
"group_welcome_msg": "", # 配置新人进群固定欢迎语,不配置则使用随机风格欢迎
"trigger_by_self": False, # 是否允许机器人触发
"text_to_image": "dall-e-2", # 图片生成模型,可选 dall-e-2, dall-e-3
"image_proxy": True, # 是否需要图片代理,国内访问LinkAI时需要
"image_create_prefix": ["画", "看", "找"], # 开启图片回复的前缀
"concurrency_in_session": 1, # 同一会话最多有多少条消息在处理中,大于1可能乱序
"image_create_size": "256x256", # 图片大小,可选有 256x256, 512x512, 1024x1024 (dall-e-3默认为1024x1024)
"group_chat_exit_group": False,
# chatgpt会话参数
"expires_in_seconds": 3600, # 无操作会话的过期时间
# 人格描述
"character_desc": "你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。",
"conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数
# chatgpt限流配置
"rate_limit_chatgpt": 20, # chatgpt的调用频率限制
"rate_limit_dalle": 50, # openai dalle的调用频率限制
# chatgpt api参数 参考https://platform.openai.com/docs/api-reference/chat/create
"temperature": 0.9,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"request_timeout": 180, # chatgpt请求超时时间,openai接口默认设置为600,对于难问题一般需要较长时间
"timeout": 120, # chatgpt重试超时时间,在这个时间内,将会自动重试
# wework的通用配置
"wework_smart": True, # 配置wework是否使用已登录的企业微信,False为多开
# 语音设置
"speech_recognition": True, # 是否开启语音识别
"group_speech_recognition": False, # 是否开启群组语音识别
"voice_reply_voice": False, # 是否使用语音回复语音,需要设置对应语音合成引擎的api key
"always_reply_voice": False, # 是否一直使用语音回复
"voice_to_text": "openai", # 语音识别引擎,支持openai,baidu,google,azure
"text_to_voice": "openai", # 语音合成引擎,支持openai,baidu,google,pytts(offline),azure,elevenlabs
"text_to_voice_model": "tts-1",
"tts_voice_id": "alloy",
# baidu 语音api配置, 使用百度语音识别和语音合成时需要
"baidu_app_id": "",
"baidu_api_key": "",
"baidu_secret_key": "",
# 1536普通话(支持简单的英文识别) 1737英语 1637粤语 1837四川话 1936普通话远场
"baidu_dev_pid": "1536",
# azure 语音api配置, 使用azure语音识别和语音合成时需要
"azure_voice_api_key": "",
"azure_voice_region": "japaneast",
# elevenlabs 语音api配置
"xi_api_key": "", #获取ap的方法可以参考https://docs.elevenlabs.io/api-reference/quick-start/authentication
"xi_voice_id": "", #ElevenLabs提供了9种英式、美式等英语发音id,分别是“Adam/Antoni/Arnold/Bella/Domi/Elli/Josh/Rachel/Sam”
# 服务时间限制,目前支持itchat
"chat_time_module": False, # 是否开启服务时间限制
"chat_start_time": "00:00", # 服务开始时间
"chat_stop_time": "24:00", # 服务结束时间
# 翻译api
"translate": "baidu", # 翻译api,支持baidu
# baidu翻译api的配置
"baidu_translate_app_id": "", # 百度翻译api的appid
"baidu_translate_app_key": "", # 百度翻译api的秘钥
# itchat的配置
"hot_reload": False, # 是否开启热重载
# wechaty的配置
"wechaty_puppet_service_token": "", # wechaty的token
# wechatmp的配置
"wechatmp_token": "", # 微信公众平台的Token
"wechatmp_port": 8080, # 微信公众平台的端口,需要端口转发到80或443
"wechatmp_app_id": "", # 微信公众平台的appID
"wechatmp_app_secret": "", # 微信公众平台的appsecret
"wechatmp_aes_key": "", # 微信公众平台的EncodingAESKey,加密模式需要
# wechatcom的通用配置
"wechatcom_corp_id": "", # 企业微信公司的corpID
# wechatcomapp的配置
"wechatcomapp_token": "", # 企业微信app的token
"wechatcomapp_port": 9898, # 企业微信app的服务端口,不需要端口转发
"wechatcomapp_secret": "", # 企业微信app的secret
"wechatcomapp_agent_id": "", # 企业微信app的agent_id
"wechatcomapp_aes_key": "", # 企业微信app的aes_key
# 飞书配置
"feishu_port": 80, # 飞书bot监听端口
"feishu_app_id": "", # 飞书机器人应用APP Id
"feishu_app_secret": "", # 飞书机器人APP secret
"feishu_token": "", # 飞书 verification token
"feishu_bot_name": "", # 飞书机器人的名字
# 钉钉配置
"dingtalk_client_id": "", # 钉钉机器人Client ID
"dingtalk_client_secret": "", # 钉钉机器人Client Secret
# chatgpt指令自定义触发词
"clear_memory_commands": ["#清除记忆"], # 重置会话指令,必须以#开头
# channel配置
"channel_type": "wx", # 通道类型,支持:{wx,wxy,terminal,wechatmp,wechatmp_service,wechatcom_app}
"subscribe_msg": "", # 订阅消息, 支持: wechatmp, wechatmp_service, wechatcom_app
"debug": False, # 是否开启debug模式,开启后会打印更多日志
"appdata_dir": "", # 数据目录
# 插件配置
"plugin_trigger_prefix": "$", # 规范插件提供聊天相关指令的前缀,建议不要和管理员指令前缀"#"冲突
# 是否使用全局插件配置
"use_global_plugin_config": False,
"max_media_send_count": 3, # 单次最大发送媒体资源的个数
"media_send_interval": 1, # 发送图片的事件间隔,单位秒
# 智谱AI 平台配置
"zhipu_ai_api_key": "",
"zhipu_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
# LinkAI平台配置
"use_linkai": False,
"linkai_api_key": "",
"linkai_app_code": "",
"linkai_api_base": "https://api.link-ai.chat", # linkAI服务地址,若国内无法访问或延迟较高可改为 https://api.link-ai.tech
