
AI发展与现状
人工智能(AI)的发展历史可以概括如下:
- 起步阶段(20世纪中叶):AI的概念首次提出,早期关注逻辑和符号处理。
- 推理系统(1950s-1960s):开始研究推理系统,包括早期AI项目和Dartmouth会议(Wiki地址)。

大家对这个游戏是否有印象?人机象棋游戏使用就是该推理系统 - 知识表示和专家系统(1970s-1980s):研究知识表示和专家系统,模仿专家决策。
- 机器学习兴起(1980s-1990s): 机器学习成为焦点,包括监督学习和无监督学习。
- 神经网络复兴(2000s-现在): 深度学习和神经网络在计算机视觉和自然语言处理中成功。
为什么现在各厂都在构建巨大的神经网络计算资源呢?

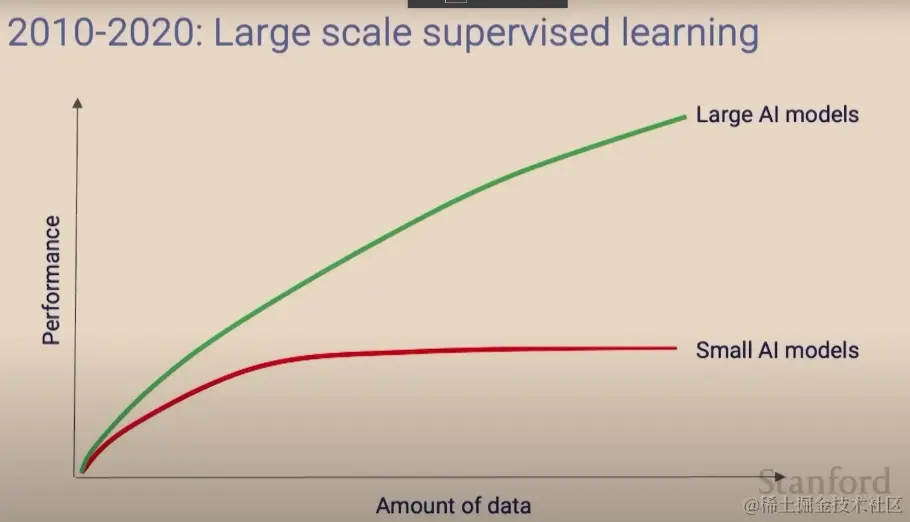
由下图可见在一个性能不是很强大的计算资源下去投喂数据,数据到一定规模之后AI性能会达到一个瓶颈,但如果投入大量的计算资源和数据,AI性能将越来越好
机器学习
上文提到的机器学习,那么什么事机器学习呢?
机器学习是人工智能的一个重要分支,它关注如何设计和开发算法和模型,使计算机能够从数据中学习,改进其性能和执行任务,而不需要明确的编程指导。在AI中,机器学习是实现智能行为和决策的关键技术之一。
主要有以下特征:
- 模型:机器学习模型是数学和统计算法的表示,用于捕获数据中的模式和关系。常见的机器学习模型包括线性回归、决策树、支持向量机、神经网络等。这些模型可以用于分类、回归、聚类、降维、异常检测等任务。
- 训练和评估:机器学习模型需要通过训练数据来学习,然后使用测试数据来评估其性能。常见的性能指标包括准确度、均方误差、精确度、召回率等,这些指标用于衡量模型的质量。
KNN算法
机器学习算法分为多个类别,包括监督学习、无监督学习、半监督学习和强化学习。我们通过监督学习中K最近邻算法 (K-Nearest Neighbors, KNN)来了解机器学习 KNN邻近算法概要: 目的:确定测试样本属于哪一类 方式:寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类。
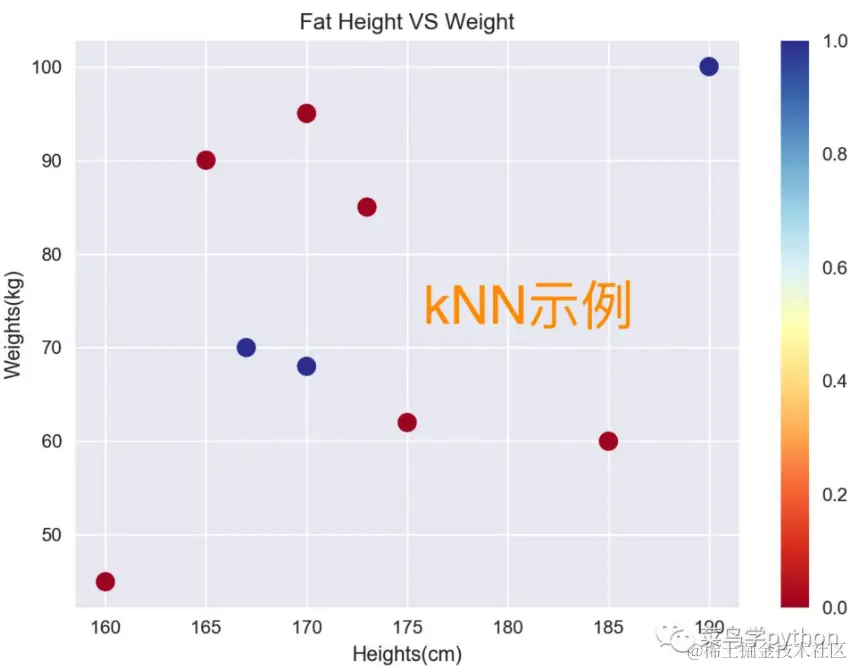
KNN算法判定 个体体重是否正常
3个维度:身高,体重,是否正常
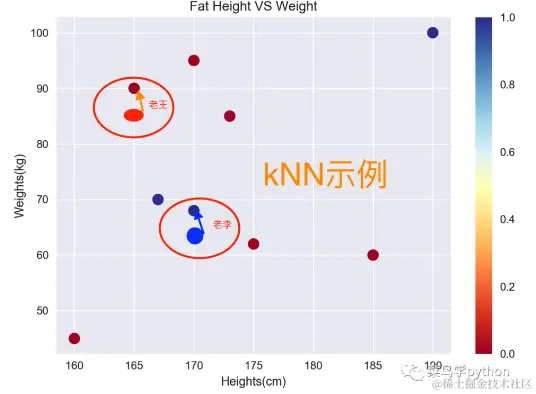
老王:165cm,85kg,看最近的距离为k=1的是谁,发现是165/90这个点,那么我们就认为老王和距离他最近的点是一类人,把他划分为胖的
老李:170cm,65kg,同理计算距离为k=1的点是谁,发现是170/69这个点,那么我们就认为老李和距离他最近的点是一类人,把他划分为正常的
KNN训练鸢尾花iris数据集

Talk is cheap. Show me the code. 代码是一门手艺,具象理论是一门艺术 ,这里通过python 结合上文提到的KNN算法来做个识别鸢尾花的例子
鸢尾花数据:
属性:4 个输入特征:花萼长、花萼宽、花瓣长、花瓣宽 ;
类别:作为标签 0 代表狗尾草鸢尾,1 代表杂色鸢尾,2 代表弗吉尼亚鸢尾
- 安装用于机器学习和数据挖掘的开源Python库:sklearn
复制代码pip3 install scikit-learn
2. 输出sklearn库中的iris数据集
python复制代码from sklearn.datasets import load_iris
from pandas import DataFrame
import pandas as pd
import matplotlib.pyplot as plt
# 载入sklearn库中的iris数据集
iris = load_iris()
x_data = iris.data # .data返回iris数据集所有输入特征
y_data = iris.target # .target返回iris数据集所有标签
print("x_data from datasets: n", x_data)
print("y_data from datasets: n", y_data)
x_data = DataFrame(x_data, columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']) # 为表格增加行索引(左侧)和列标签(上方)
pd.set_option('display.unicode.east_asian_width', True) # 设置列名对齐
print("x_data add index: n", x_data)
x_data['类别'] = y_data # 新加一列,列标签为‘类别’,数据为y_data
print("x_data add a column: n", x_data
输出:总有150条数据集,类别有:0(狗尾草鸢尾),1(杂色鸢尾),2(弗吉尼亚鸢尾) 每个类别50条
sql复制代码[150 rows x 4 columns]
x_data add a column:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2
通过花萼长度,花萼宽度区分出特征
ini复制代码# 获取花卉三四列特征数据集 (花瓣特征)
DD = iris.data
X = [x[2] for x in DD]
print (X)
Y = [x[3] for x in DD]
print (Y)
#plt.scatter(X, Y, c=iris.target, marker='x')
# 第一类 前50个样本
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa')
# 第二类 中间50个样本
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor')
# 第三类 后50个样本
plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica')
# 图例
plt.legend(loc=2) #左上角
plt.show()
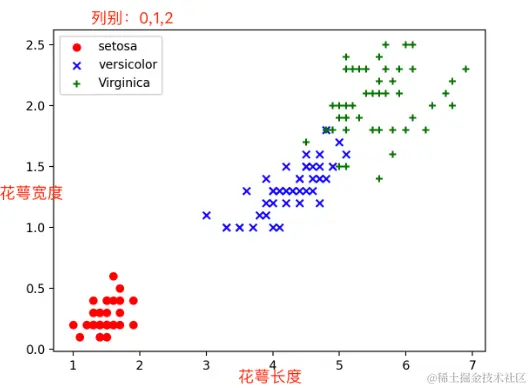
通过花萼长度,花萼宽度能比较直观的分辨出鸢尾花类别
使用 KNN最近邻分类器模型,输出 鸢尾花特征数值验证测试结果
ini复制代码from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
# 加载鸢尾花数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 创建K最近邻分类器模型
model = KNeighborsClassifier(n_neighbors=3) # 使用3个最近邻居
# 在整个数据集上拟合模型
model.fit(X, y)
# 用户输入特征值
sepal_length = float(input("请输入花萼长度 (cm): "))
sepal_width = float(input("请输入花萼宽度 (cm): "))
petal_length = float(input("请输入花瓣长度 (cm): "))
petal_width = float(input("请输入花瓣宽度 (cm): "))
# 构建输入特征的数组
input_features = [[sepal_length, sepal_width, petal_length, petal_width]]
# 使用模型进行预测
predicted_class = model.predict(input_features)[0]
predicted_species = iris.target_names[predicted_class]
# 输出预测结果
print(f"预测的鸢尾花类别为: {predicted_speci
cmd中输入:

金融类投资管理类开源库
当涉及到投资管理算法的学习和开发,以下是一些开源库,它们提供了强大的工具和资源:
- QuantLib是一个广泛用于金融工程的开源库,提供了用于定价、风险管理和资产估值的工具。
- PyAlgoTrade是一个用Python编写的开源算法交易库,支持事件驱动的交易和技术指标分析。
- Zipline是Quantopian开发的Python库,用于算法交易和量化金融研究,包括回测和实时交易功能。
- Backtrader是另一个Python库,用于开发和测试算法交易策略,支持多种数据源、技术指标和风险管理方法。
监督学习与生成式AI
了解简单的机器学习算法后,我们来看当前不同机器学习方法的比例
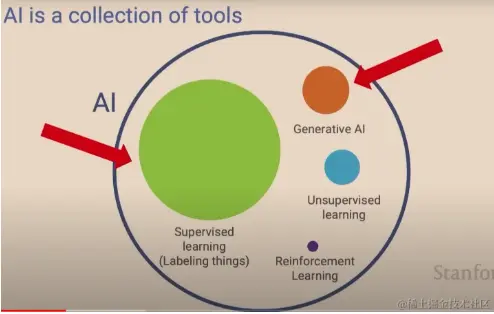
从图中 监督学习(Supervised Learning)在人工智能领域是主力,而最近火热的生成式AI也在不断增长 ,就此两种方式展开
监督学习
监督学习关注如何从有标签的数据中学会进行预测,例如根据图像来分类物体。我们以餐厅评价训练模型为例: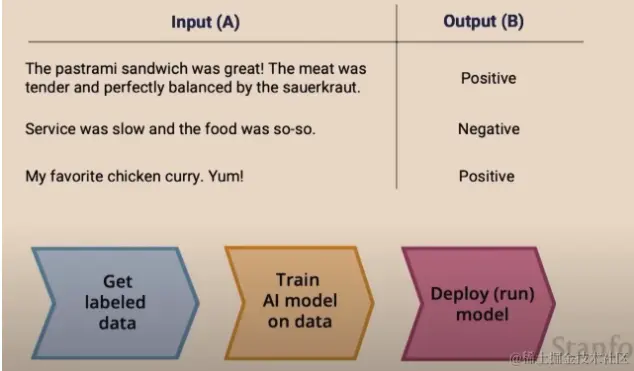
- 人工区分评价数据,标识 该数据“Positive” 或者 “Negative”
- 使用标识数据训练 AI模型
- 部署AI模型,对模型进行验证,比如输入“这个牛排真好吃” ,验证结果是否为积极评论
生成式AI
通过互联网获取的文本和输入输出的监督学习来反复预测下一个单词,通过万亿巨量的单词能得到一个大语言模型比如:chatGPT 3
大语言模型不仅可以用在对话还可以用于开发(后文将阐述)
专注于学习数据的模式,以创造新的数据,如生成图像或文本,下图为简单的阐述
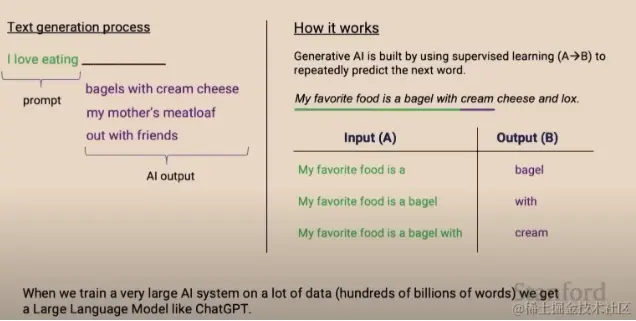
生成式AI使用
chatGPT
chatGPT 无疑是现在生成式AI中焦点,那么在程序开发中如何提高效率呢?
chatGPT 注册:
由于chatGPT 不支持中国地区,需要使用 “小飞机”切换网络节点到国外比如:美国节点
- 常规邮箱、apple注册
- 手机号码验证,这里可以去第三方短信平台购买 ,价格一般在2美分左右,不同国家价格略有不同

辅助开发生成需要的代码
输入:生成个node 函数,输入文件路径,输出包括改文件内所有文件的size
chatgpt 输出的代码:
ini复制代码const fs = require("fs");
const path = require("path");
// 递归计算文件夹大小的函数
function calculateFolderSize(folderPath) {
let totalSize = 0;
// 读取文件夹内的所有文件和子文件夹
const items = fs.readdirSync(folderPath);
items.forEach((item) => {
const itemPath = path.join(folderPath, item);
const stats = fs.statSync(itemPath);
if (stats.isFile()) {
// 如果是文件,累加文件大小
totalSize += stats.size;
} else if (stats.isDirectory()) {
// 如果是文件夹,递归计算文件夹大小
totalSize += calculateFolderSize(itemPath);
}
});
return totalSize;
}
// 使用示例
const folderPath = "../public/pdf"; // 替换为你的文件夹路径
const totalSize = calculateFolderSize(folderPath);
console.log(
`文件夹 ${folderPath} 内所有文件的总大小为 ${
totalSize / 1024 / 1024
} MB
这时候再要求上述功能输出python的写法
chatGPT输出:
ini复制代码import os
# 递归计算文件夹大小的函数
def calculate_folder_size(folder_path):
total_size = 0
# 遍历文件夹内的所有文件和子文件夹
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
total_size += os.path.getsize(file_path)
return total_size
# 使用示例
folder_path = "../public/pdf" # 替换为你的文件夹路径
total_size = calculate_folder_size(folder_path)
print(f"文件夹 {folder_path} 内所有文件的总大小为 {total_size / 1024 / 1024:.2f} MB
copt api 文档字段生成ts文件
前端很多时候需要把API接口文档中response数据结构转换成.ts文件,写起来简单但是繁琐,可以通过chatgpt帮忙完成。
需要生成typescript的API接口文档结构:

sources:
c复制代码 companyId string 必须 主体id
entityName string 必须 主体名称
....
输入要求chatgpt记录一段 “template 1” 代码:
csharp复制代码Remember this code template 1:
sources:
entityName string 必须 主体名称
Ignore “必须” and output typescript code:
interface RowInfo{
/**
* 主体名称
*/
entityName?: string
....
(The rest of the code is write here)
}
输入”sources”要求chatgpt按照”template 1″ 生成代码:
csharp复制代码 sources:
companyId string 必须 主体id
entityName string 必须 主体名称
Create a TypeScript definition based on these sources by template 1
chatgpt输出: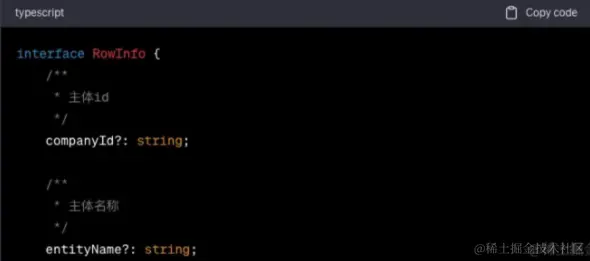
csharp复制代码interface RowInfo {
/**
* 主体id
*/
companyId: string;
/**
* 主体名称
*/
entityName: string;
// Add other properties here as needed
}
chatGPT极大提高了开发人员的效率。
昨天举办的首届OpenAI开发者大会发表了GPT-4 Turbo, 自定义chatGPT, GPT Store,和更低的api调用费用能耗等,能看出来chatGPT在加速了商业化和大众化
Midjourney
AI 不是现实世界的复刻,而是人类想象力的延伸,Midjourney 能让我们的想象力延伸到AI中
通过在对话的形式提示Midjourney 开始我们的想象之旅吧
输入:/imagine The Terra-cotta warriors typing code ( 敲代码的兵马俑 ) 
输入:/imagine Playing DJ’s Terra-cotta warriors More lively more colorful (会dj的兵马俑生动多彩)


再到 输入框黏贴复制内容得到:
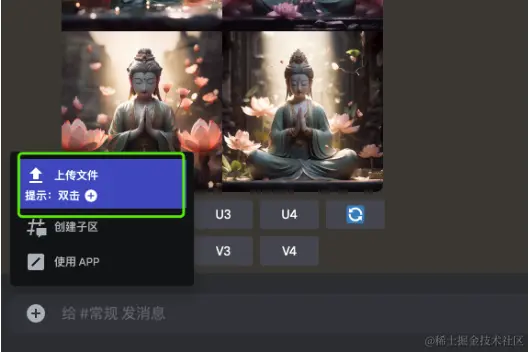
如果有自己中意的图片也可以上传并让 midjourney生成对应画风的图片 步骤:
- 上传图片
上传成功后点击大图 复制图片地址
再次输入:/imagine 复制的图片地址 + Beautiful illustration, a lotus in front of Buddha, commercial photography –ar 1:1 –v 5.2 –s 250 (在explore 复制的提示词)
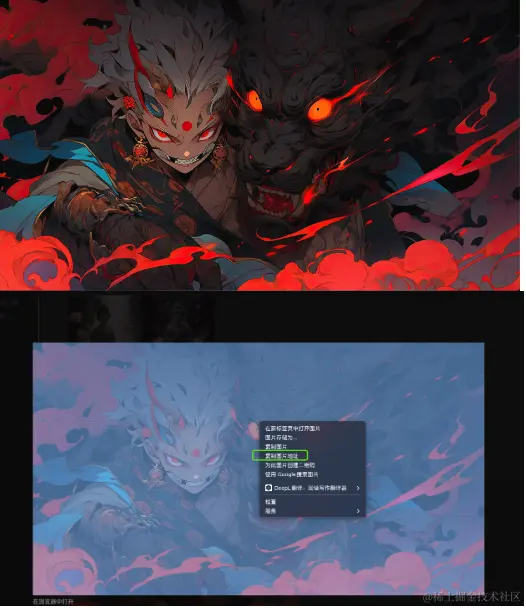
再次生成的图片如下 还是蛮酷的:


