

前言
在工作中总会遇到种种不期而至的需求,比如前段时间突然要修复所有 Sonar Bug,涉及各种琐碎的代码风格问题,包括但不限于语法不规范、废弃注释等问题。这些项目都已经持续开发几年了,Sonar 上的问题层出不穷,各种问题已经累积到了上万个,手动修复不但费时费力,而且过程异常枯燥。
好在IT界的每个困境都可能激发一丝灵感。在折腾一番后,我们开始思考:是否可以借助 AI 来拯救这个烂摊子?
注意: 这并不是传统成功故事里的一篇教程,因为最后AI的修复效率并不如预期中的那么亮眼,这篇文章主要围绕解决问题的思路和方法。
AI 修复之路
其实很早之前我们就曾动过利用 AI 生成代码的念头,同事甚至尝试过让 AI 批量添加注释、修正代码甚至生成单元测试等等,但有些生成效果不错,而有些因效果不理想而不了了之。
我们在接到修复 Bug 的当天也讨论过用 AI 修复 Sonar Bug 的可能性,但考虑到之前单元测试的失败经历,我们最初还是放弃了这个念头。
思路之初
虽然我们一开始放弃了使用 AI 修复 Bug 的设想,但问题始终需要解决。在一天中午吃饭时,我意识到既然 SonarQube 能在本地扫描代码并展示详尽的错误信息,它在扫描过程中一定记录了诸如文件名、出错行数和错误信息等关键详情。
我发现 SonarQube 扫描结束后会留下一个 .scannerwork 目录。最初,我在想 SonarQube 是否把错误信息存储在了本地的某个缓存中,从而我能直接读取这些信息。虽然最终在本地并未找到直接解析 SonarQube 信息的方法,但这个追问最终引导我发现了一个更佳的解决方案:SonarQube 的 Web API。
Sonar 接口信息
通过 SonarQube 的 Web API,我可以程序化地获取扫描结果,它不仅包含了所有报告出的详细 Bug 信息,还能允许进行更高级别的交互,比如自定义查询、修改项目设置等。因此,下一步的工作将包括深入研究如何利用这个 API 来优化和自动化我们的代码修复流程。
以下是一个 API 返回的 issue 示例:
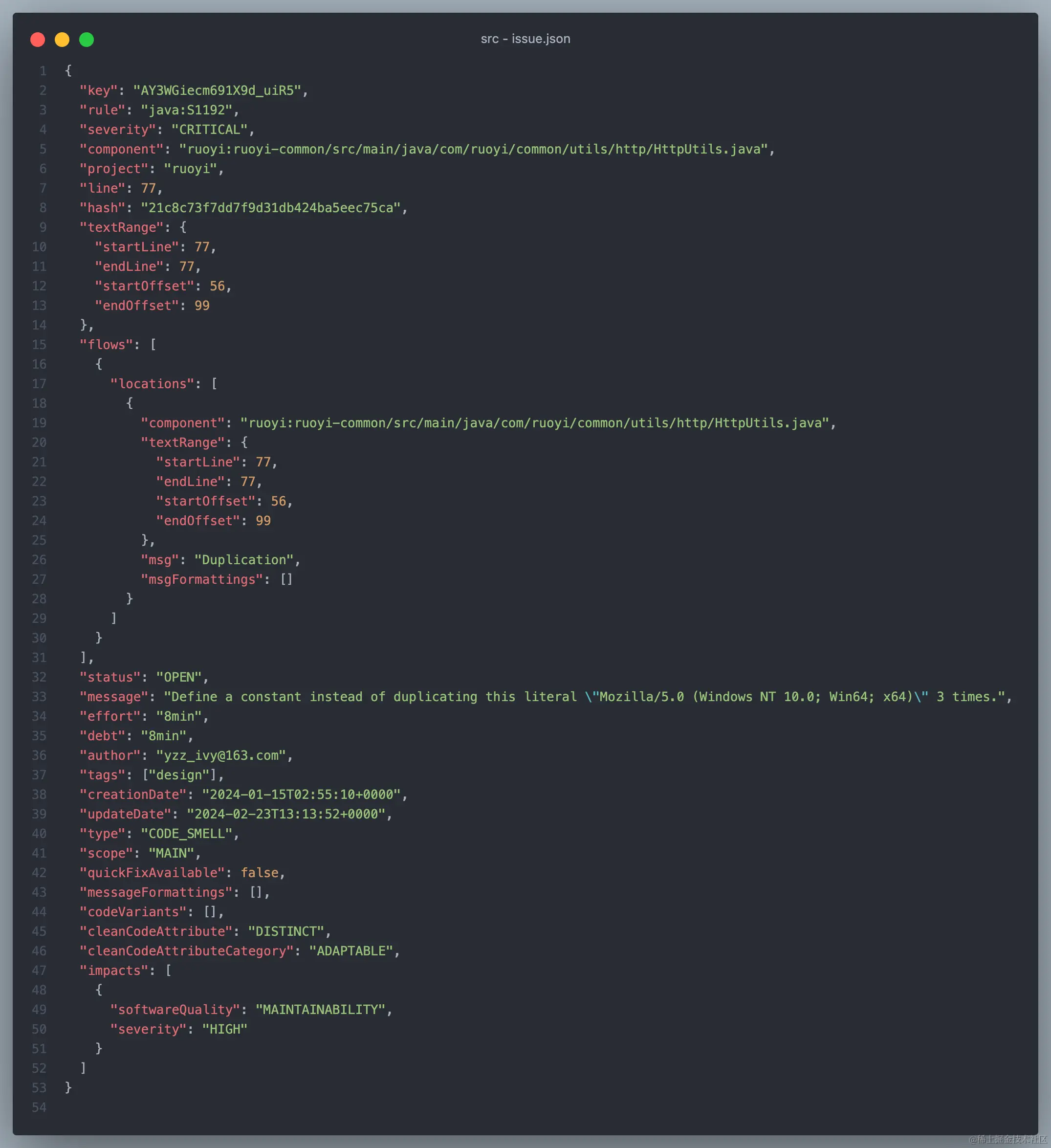
我们可以从中看到该 API 为我们提供了足够的信息来定位到具体错误。后面我会介绍如何使用 Sonar 的 Web API。
修复思路一
我们现在已经证实能够通过 SonarQube 的 Web API 准确获得错误信息,以及错误的具体位置。
那么,一个基本的解决方案框架浮现出来:在确定好提示词后,我们利用 Sonar Web API 拉取所有问题(issue)列表,根据其中包含的文件路径读取本地代码。然后,我们把这些问题按文件分类并进行汇总。完成这些准备工作之后,我们便可以将读取的代码连同相关的问题列表提交给 AI,并提供详细的错误行与描述信息。
提示词大致如下:
bash复制代码你是一个软件开发专家,有丰富的 JAVA 开发与 Sonar 问题修复经验。
根据下面提供的代码和 SonarQube 扫描出来的错误信息修复代码中的问题,
要求只返回代码内容,不能胡编乱造,不能改变原始业务含义,代码必须严谨,不能有语法错误。
注意:你修改后的代码必须可以运行,假设是变量名重复等问题,你如果修改了变量名也要将涉及到的上下文代码进行修改
源码:
<source code> 这里传入源码
Sonar 信息:
在 1 到 10 行之间存在 Sonar 错误:xxxxxxxxxxx
在 3 到 6 行之间存在 Sonar 错误:xxxxxxxxxxx
在 8 到 20 行之间存在 Sonar 错误:xxxxxxxxxxx
在 30 到 40 行之间存在 Sonar 错误:xxxxxxxxxxx
在 50 到 70 行之间存在 Sonar 错误:xxxxxxxxxxx
这个方法最简单也最粗暴,但存在一个明显的问题:AI 输入输出的 token 有数量限制。尤其是输出的 token,只有几千字符,这意味着对于过大的文件,输出会被截断。
修复思路二
为了解决文件内容过大的问题,我们开始思考如何让 AI 尽可能多的返回代码。毕竟,如果没有足够的上下文,AI 难以做出精确判断。好在当前的 AI 接口 token 数量完全满足大文件上传,这让我们决定继续全量提交代码。
问题的关键在于如何有效地利用 AI 的处理能力。我们发现,不必一股脑把所有问题都甩给 AI,取而代之的是,我们将聚焦于一小部分问题——为什么呢?因为 AI 处理并返回结果通常要花费一些时间,我们需要尽可能减少接口请求次数。我们注意到 Sonar 报告中会出现诸如 1-10 行、3-6 行、8-20 行这样的重叠问题区间。基于这一发现,我们采用贪心算法将这些重叠区间合并,然后把这一整个区域的问题一次性提交给 AI,这样做的好处是 AI 一次性解决多个问题,同时减少了需要返回的代码量。
提示词改进后大致如下:
bash复制代码你是一个软件开发专家,有丰富的 JAVA 开发与 Sonar 问题修复经验。
根据下面提供的代码和 SonarQube 扫描出来的错误信息修复代码中的问题,
要求只返回代码内容,不能胡编乱造,不能改变原始业务含义,代码必须严谨,不能有语法错误。
注意:你修改后的代码必须可以运行,假设是变量名重复等问题,你如果修改了变量名也要将涉及到的上下文代码进行修改
请只返回源文件 1 - 20 行修改后的代码,且保证代码可以直接替换源码
源码:
<source code> 这里传入源码
Sonar 信息:
在 1 到 10 行之间存在 Sonar 错误:xxxxxxxxxxx
在 3 到 6 行之间存在 Sonar 错误:xxxxxxxxxxx
在 8 到 20 行之间存在 Sonar 错误:xxxxxxxxxxx
合并 Issue 重叠区间代码大致如下:
python复制代码def merge_overlapping_intervals(intervals):
"""
通过贪心算法合并重叠区间
:param intervals: 区间列表
:return: 合并后的区间列表
"""
if not intervals:
return []
# 按照起始行进行排序
intervals.sort(key=lambda x: x['textRange']['startLine'] if x.get('textRange') else math.inf)
merged_intervals = [intervals[0]]
for interval in intervals[1:]:
last_merged_interval = merged_intervals[-1]
# 如果当前区间没有 textRange,则直接添加到 merged_intervals
if not interval.get('textRange'):
merged_intervals.append(interval)
continue
# 如果当前区间的起始行在上一个区间内,则合并区间
if interval['textRange']['startLine'] <= last_merged_interval['textRange']['endLine']:
last_merged_interval['textRange']['endLine'] = max(last_merged_interval['textRange']['endLine'], interval['textRange']['endLine'])
else:
# 如果当前区间的起始行不在上一个区间内,则添加新的区间
merged_intervals.append(interval)
# 反转列表:按照起始行从从大到小的顺序
return merged_intervals[::-1]
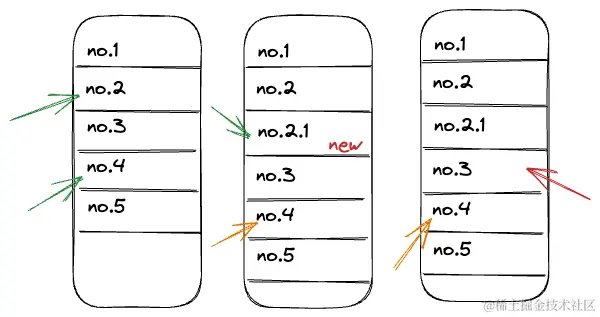
在逐行处理问题的过程中,我们要注意一个问题:若我们按照正序逐行修复代码中的问题,可能因为修改导致代码行数的增减,进而导致后续问题的代码行位置不再准确。这种情况就如同在 JavaScript 中用 for 循环正序操作数组元素一样——如果你在遍历过程中删除或添加元素,索引就会失效。
举个例子,如果我们有两个要修复的问题,一个在第二行,另一个在第四行。如果我们在修复第二行时插入了新的一行,那么当我们转向第四行时,问题实际上已经移到了第五行。为了应对这个问题,我们采取倒序解决方案——即先解决下方的问题,再向上修复。这种策略确保每次修改都不会影响到还未处理的代码行。
修复思路三
虽然我们已经找到了一种解决方案,但实际操作中还是发现了一些问题。有时我们只指定了需要修改代码的行数,但修复可能涉及到代码的其他部分。例如,可能需要修改全局变量名,或者发现某些问题的范围没有被完全包含。
为了解决这一问题,我们转而考虑让 AI 返回一个包含修改信息的 JSON 数据。这个 JSON 会详细记录每个修复动作的开始行和结束行,以及修复后的代码。一旦 AI 完成一处修复,就会在 JSON 中添加一条记录。最后,我们得到的是一个完整的修复记录集。
值得一提的是,为了避免 AI 在面对大量问题时做出发疯的修改,我们决定一次仅处理一个问题。这样做可以确保 AI 对每个问题都给予了足够的关注,并且可以有序地处理每个修复。
提示词大致如下:
css复制代码你是一个软件开发专家,有丰富的 JAVA 开发与 Sonar 问题修复经验。
根据下面提供的代码和 SonarQube 扫描出来的错误信息修复代码中的问题,
要求只返回代码内容,不能胡编乱造,不能改变原始业务含义,代码必须严谨,不能有语法错误。
注意:你修改后的代码必须可以运行,假设是变量名重复等问题,你如果修改了变量名也要将涉及到的上下文代码进行修改
你需要返回一个 JSON 数组, 包含需要在代码起始行和修改后的代码,如果有多处修改,就返回多个对象,
你的代码必须可以根据你的代码起始行和结束行进行替换,且语法正确,格式如下:
[{ "startLine": 10, "endLine": 20, "newCode": "修改后的代码"}]
即便没有修改,也需要返回一个空数组。
源码:
<source code> 这里传入源码
Sonar 信息:
在 1 到 10 行之间存在 Sonar 错误:xxxxxxxxxxx
不要返回 markdown 格式,只需要返回纯文本即可!
最终幻想
尽管我在调试中尝试了多种思路,并对指导语和代码逻辑进行了无数次优化,但最后的结果并不理想。最根本的问题是 AI 返回的代码修改并不总是准确的,而且对 AI 代码进行 Code Review 的工作量远比我们之前预想的要大得多。
当然造成这个结果的原因可能是我的提示词写的不太好,可能也是因为 Gemini Pro 还未足够成熟。我同样尝试了 ChatGPT 4,发现结果有所改善但仍不太满意。虽然这次的实验没有达到预期,但是我认为利用 AI 来辅助修复代码在未来应该可以实现。
关于这一系列实验故事,就先聊到这里。接下来,我会讲解一下 Sonar Web API 和 Google AI – Gemini Pro 模型的具体应用细节。
Sonar Web API
Sonar 提供了非常全面的 Web Api,我们几乎可以用 Web Api 操作我们想做的一切。
介绍
Sonar Web Api 的地址通常是:http://<sonar_address>/web_api,如果地址不对,也可以在页面底部找到 Web_API 的跳转链接。
我们这里只用到了 api/issues/search 这个接口,这一个接口足可以满足我们的需求,如果对其他接口感兴趣的可以自行尝试。
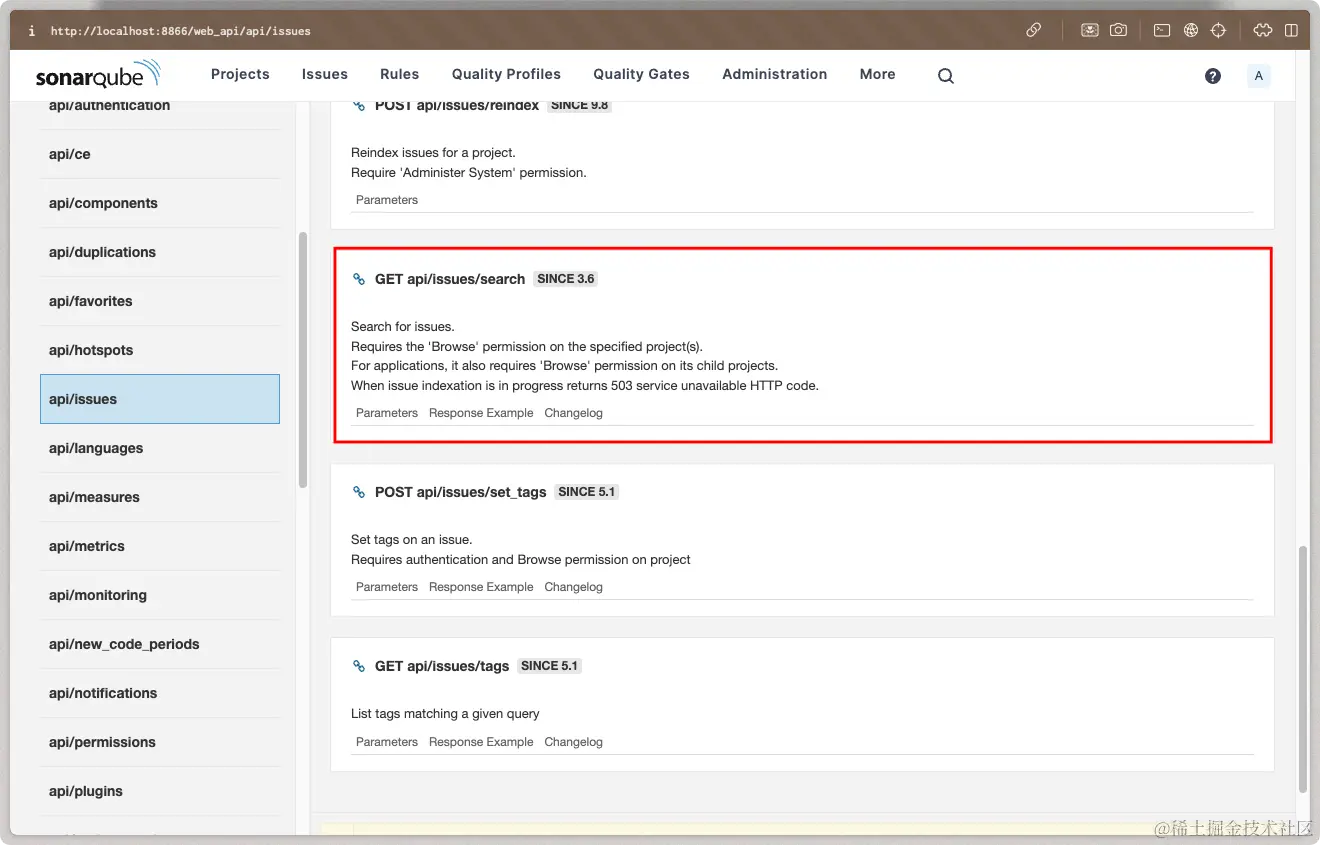
Sonar Web Api 提供了详细的参数列表和返回体示例,根据参数介绍我们可以很轻松的构建出请求数据。
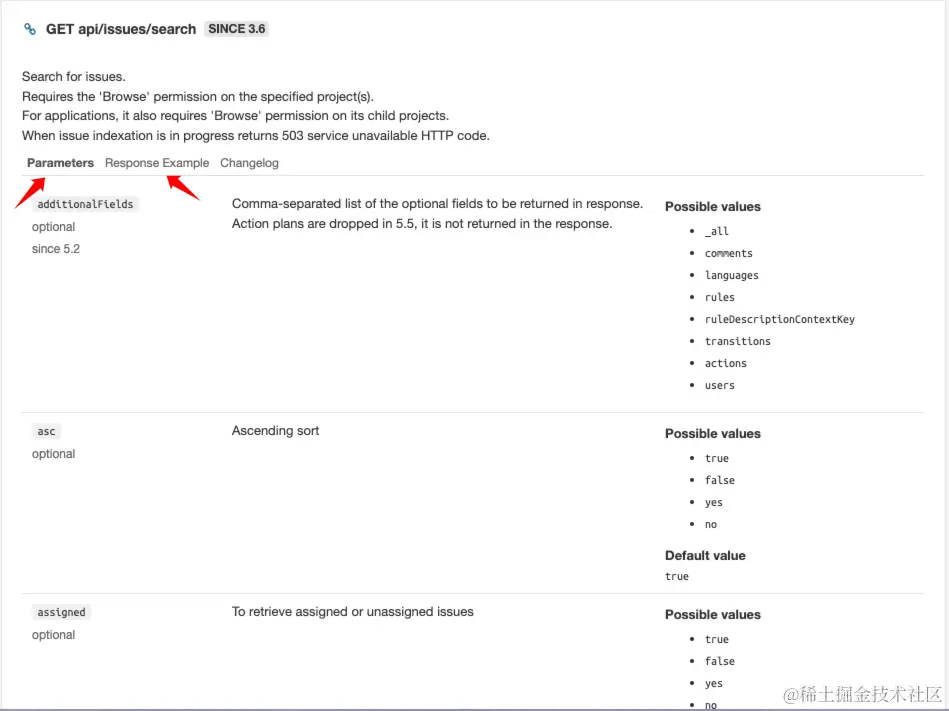
这里说几个关键的参数:
- p: 页码
- ps: 页面大小,必须大于 0 且小于或等于 500
- statuses:状态列表字符串,用逗号分割
- components:组件列表,组件可以是组合、项目、模块、目录或文件,用逗号分割,注意,低版本的 web api 中,这个字段叫
componentKeys - rules: 编码规则列表,用逗号分割。
Python 调用
申请 API Token
在编写代码之前,需要先上你部署的 sonarqube 平台创建一个 token, 用于接口身份验证
- 进入 sonar 平台,点击头像 ->
My Account
- 点击进入 Security 页面
- 给 Token 随便输入一个名字
- 选择 Token 类型,这里要选择 User
- 点击 generate 按钮生成 token
- 点击后下面列表多出一列数据,列表上方有刚生成好的按钮
- 注意,token 生成后需要立马复制,刷新后将会消失,只能重新生成
接口调用
这里简单讲一下如何调用,其实很简单。
python 有一个社区开发的包 python-sonarqube-api 可以用于简化 api 的请求,但是我只需要使用 issue/search 接口,就没必要安装一个包了,直接请求即可。
以下是请求的简化代码:
python复制代码# 部署的 sonarqube 服务器地址
sonarqube_url = 'your_sonarqube_service_url'
# sonarqube api key
api_token = 'your_api_token'
# 身份验证
auth = requests.auth.HTTPBasicAuth(api_token, '')
params = {
'p': page,
'ps': page_size,
'statuses': 'OPEN',
'components': 'ruoyi', # sonar 中的项目名
'branch': 'main' # sonar 中的分支名
}
# 构建请求
response = requests.get(f'{sonarqube_url}/api/issues/search', auth=auth, params=params)
# 请求成功返回 json
if response.ok:
return response.json()
else
print(f'请求失败: {response.code}')
return {}
Gemini Pro
我最初考量国内的 AI 模型,如文心一言、通义千问、云雀大模型等,但它们都需要付费使用且没有提供试用额度,这限制了我进行初步测试。而星火大模型虽提供免费额度,但在尝试官方 Demo 时遭遇了接口错误,而且因为只提供了 websocket 接口,我决定不再进一步研究。
反观 Google 开发的 Gemini Pro,它不仅提供免费的接口,而且除了单次请求的 token 数量有限制之外,并没有实质性的使用次数限制(尽管每分钟请求不得超过 60 次)。因此在项目初期,我选择了 Gemini Pro 作为我们的 AI 接口。
本文期起初是想包含有关如何调用 Gemini AI 的教程,但为了保持主题的清晰和内容的专注,我决定将这部分内容另行撰写。下一篇文章,我将详细介绍 Gemini AI 的使用方法。
结语
虽然在尝试使用 AI 解决代码问题的方法我们已经放弃了,但在编写的过程中,我忽然有了新的灵感,想到了一个新的可行思路:许多代码问题其实并不复杂,比如删除无用的代码行、重复字符串替换为常量等,这类规范性的问题处理起来相对简单。我开始思考,是否可以通过解析 Java 的抽象语法树(AST),再结合一系列规则来批量修复这些常见问题。
抱着这个思路,我接下来会撰写一篇文章,专门介绍如何利用 Python 批量修复 SonarQube 中标识出的 bug。这篇文章将详细说明整个过程,包括解析 Java AST 的技术细节和实际的修复步骤。
Demo 地址
我将 sonar-bugfix-ai 项目的代码抽离精简后,保留了主逻辑,提供一个 Demo 给大家测试学习使用。
GitHub 地址:github.com/Alessandro-…
注意:
- 该项目是一个被阉割的 Demo 项目, 仅用于演示思路
- 不能保证 Sonar Bug 都能被修复,甚至可能会直接导致代码异常
- 本项目仅用于学习,如果想要实际使用,请 fork 本项目并自行修改
- 本项目不对使用本项目导致的任何后果负责
注意
使用 AI 修复 Bug 有以下风险:
- 你调用 AI 接口后,你的代码很可能会被拿来训练,或者泄露。
- AI 的回复不总是一致的,也许刚开始回答的格式是一样的,后面自己就变了。
- AI 的修复结果不总是准确的,严格来讲,不准确的情况居多。
- 你需要 review 每一样AI 编写的代码,因为他很有可能写一些看似正确的代码。
相关资料
- SonarQube Web API 文档:docs.sonarsource.com/sonarqube/l…
- Google Gemini API 文档:ai.google.dev/docs?hl=zh-…
- openai API 文档:platform.openai.com/docs/overvi…
