

背景
在一次网上冲浪的过程中,无意发现了一个宝藏网站web.dev,这个网站由Google推出,其内容由Chrome团队的成员和外部专家共同编写,希望帮助用户构建美观、易用、快速且安全的网站。 其中的内容囊括:
- 技术博客:Google内外部专家提供的技术分享
- 学习:提供PWA、CSS、HTML等内容的学习
- 探索:提供性能、构建优秀的网站、框架、探索等方面的内容
- 模式:一组用于处理动画、剪切板、布局等内容的常见模式
- Case studies:了解其他开发者为何以及如何利用网络为他们的用户创建了出色的网络体验。
这么丰富且优秀的网站,我“啪的一下!很快啊!”就放进了收藏夹,期待日后品读。然而我读着读着就有一种想分享的冲动,但其原文为英文,读起来不是那么顺畅,于是我就想将其翻译后再分享给大家。
工具与技术
- Node.js:爬虫等以下各种技术的运行环境
- Cheerio:一个用于解析和操作HTML字符串的js库,提供类似dom操作的方式对文档进行处理
- Turndown.js:转换HTML到Markdown格式
- OpenAI GPT-4:提供给第三方进行调用的API接口
- Prettier:对代码/文档进行格式化的工具
步骤
爬取网站内容
定义爬取目标与策略
我们进入博客列表,打开控制台对网页进行检查会发现,此网站是SSR直出的,且语义化做得相当不错
数据采集策略如下
- 分析DOM结构
- 获取特定类名对应的数据信息
数据提取与处理
我们发现博客列表的DOM结构是一系列的卡片,因此针对这些卡片的特定类名可以获取到所有的文章信息
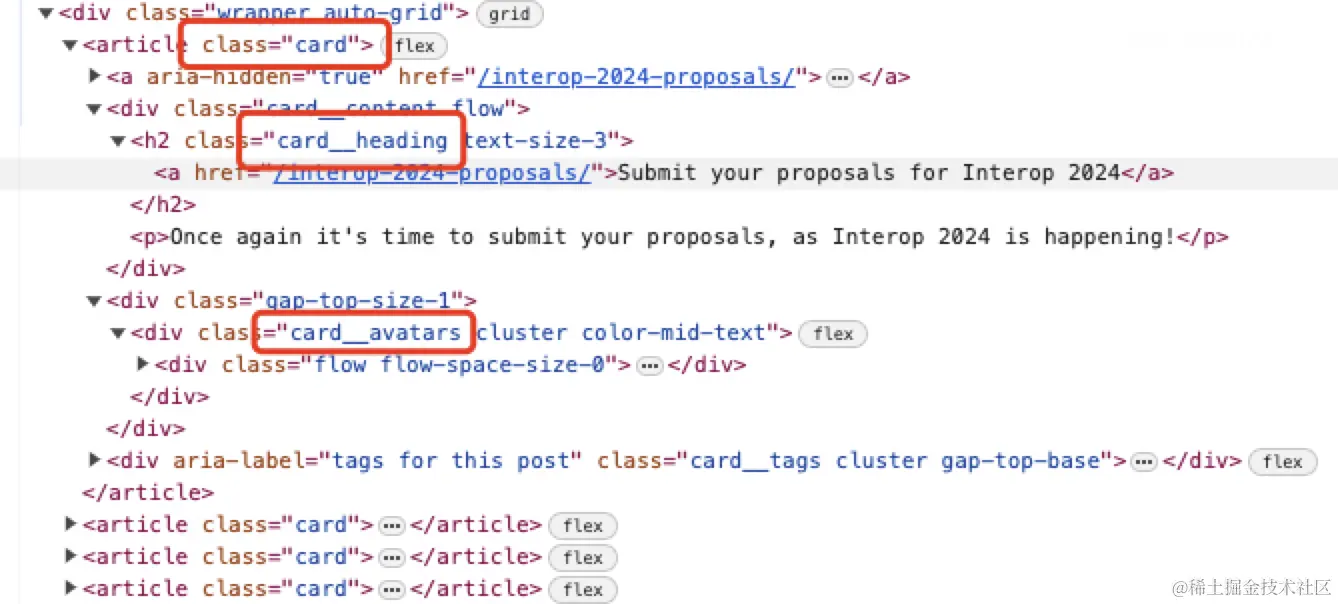
以下代码可以获取到对应DOM中的所有文章的链接、标题、发布日期等信息
ts复制代码export const getAllArticles = (html: string) => {
const $ = load(html);
const articles: { title?: string; href?: string; time?: string }[] = [];
// 获取每个文章卡片信息
$('article.card').each((i, ele) => {
let title = '';
let href = '';
let time = '';
$('.card__heading', ele).each(function () {
title = $('a', this).text();
href = $('a', this).attr('href') ?? '';
});
$('.card__avatars', ele).each(function () {
time = $('time', this).text();
});
articles.push({
title,
href,
time,
});
});
return articles;
};
我们拿到所有标题和链接后,就可以针对某一篇文章进行处理
ts复制代码get(articlePath).then((res) => {
const prefix = `发布时间:${article.time}n
原文链接:[${article.title}](${articlePath})n
Translated by GPT-4 with ❤️(翻译过程中若有错误或遗漏,欢迎评论区指出👏)
`;
saveHtml2MD(res, prefix).catch((e) => {
console.error(`[${articlePath}]n`, e);
});
});
OpenAI接入
- 首先你需要可以访问外网,一些公司提供外网访问,没有的则需要自己挂梯子
- 你需要注册OpenAI的账号,风控力度很大,国内邮箱目前似乎注册不了,注册流程参考OpenAI 推出超神 ChatGPT 注册攻略来了
- 新用户有5美元的试用资格,过期后需要使用国外银行卡进行充值
- 申请新的API key,点击
Create new secret key按钮创建一个API key
转换与翻译
Turndown.js转MD
我们拿到html原文内容后,需要对其进行转换处理,通过分析发现每一篇博客都是通过article标签进行包裹的,因此我们只需要拿到这部分内容进行转换
ts复制代码export const saveHtml2MD = async (html: string, prefix: string) => {
const $ = load(html);
const article = $('article').first();
const title = article.find('header h1').text();
article.find('header, details').remove(); // 移除不需要的内容
article.find('.docked-actions, a.button').remove(); // 移除不需要的内容
const md = turndownService.turndown(article.html() as string);
...
};
OpenAI GPT-4翻译
基于GPT-4强大的模型,我们翻译出来的内容是相当准确且有逻辑的,并且不会对专业术语进行翻译,也不会对代码块进行翻译
ts复制代码export const saveHtml2MD = async (html: string, prefix: string) => {
...
let offset = 0;
let output = '';
while (offset < lines.length) {
const chunk = await chatWithGPT(
`请把以下内容翻译成中文:n${lines.slice(offset, offset + 50).join('n')}`
);
output += `${chunk}n`;
offset += 50;
}
output = `${prefix}nn${output}`;
const formated = await prettier.format(output, {
parser: 'markdown',
});
if (!fs.existsSync(MD_DIR)) {
fs.mkdirSync(MD_DIR, { recursive: true });
}
fs.writeFile(
`${MD_DIR}/${title.split(/s+/g).join('-')}.md`,
formated,
(err) => {
console.log(err);
}
);
};
需要注意的是,openai计算价格时,通常会考虑输入文本和生成文本中的 Token 数量之和。例如,如果输入有 10 个 Token,而输出有 20 个 Token,则总共会计算 30 个 Token 的价格。1000个Token约等于750个英文单词或者400~500个汉字。
经过实验,我翻译一篇博客的费用在0.6美元左右(好心人为本文点点赞吧😭)
格式化与输出
为了让文章更美观,我们利用Prettier进行格式化,然后将格式化后的内容保存到特定文件夹中
ts复制代码export const saveHtml2MD = async (html: string, prefix: string) => {
...
const formated = await prettier.format(output, {
parser: 'markdown',
});
if (!fs.existsSync(MD_DIR)) {
fs.mkdirSync(MD_DIR, { recursive: true });
}
fs.writeFile(
`${MD_DIR}/${title.split(/s+/g).join('-')}.md`,
formated,
(err) => {
console.log(err);
}
);
};
至此,我们就完成了对一篇文章的翻译
总结
- 从发现web.dev这个网站开始,我们就在脑海里构思了整套流程
- 爬取该网站SSR内容,使用成熟的Cheerio进行数据解析
- 使用Turndown.js将内容转换为Markdwon格式
- 使用OpenAI GPT-4对内容进行翻译
- 使用Prettier对输出内容进行格式化
- 将翻译的内容分享到社区,互利共赢
- 站在巨人的肩膀上,先构思、设计方案,再找可用的轮子、实现自己的方案
仓库地址
(分享不易、渴望点赞和star😭)
目前已经翻译了三篇文章,一篇已经发表在掘金【译/Blog】提升你的HTML5应用程序的性能
