

诞生
Transformer架构的模型在过去几年里逐渐成为了图像领域的一个主流研究方向。发表了GPT和Whisper的OpenAI也不甘落后,就拿4亿张互联网上找到的图片,以及图片对应的ALT(Alternative)文字训练了一个叫做CLIP(Contrastive Language-Image Pretraining)的多模态模型。这个模型,不仅可以拿来做常见的图片分类、目标检测,也可能够用来优化业务场景里面的商品搜索和内容推荐。
多模态的CLIP
所谓“多模态”,就是多种媒体形式的内容。我们可以拿GPT模型来做数学试题,那么如果遇到一个平面几何题的话,光有题目的文字信息是不够的,还需要把对应的图形一并提供给AI才可以。这也是通往通用人工智能的必经之路,因为真实的世界就是一个多模态的世界。
CLIP模型,它不仅能够分别理解图片和文本,还通过对比学习建立了图片和文本之间的关系。这个也是未来我们能够通过写几个提示词就能用AI画图的一个起点。
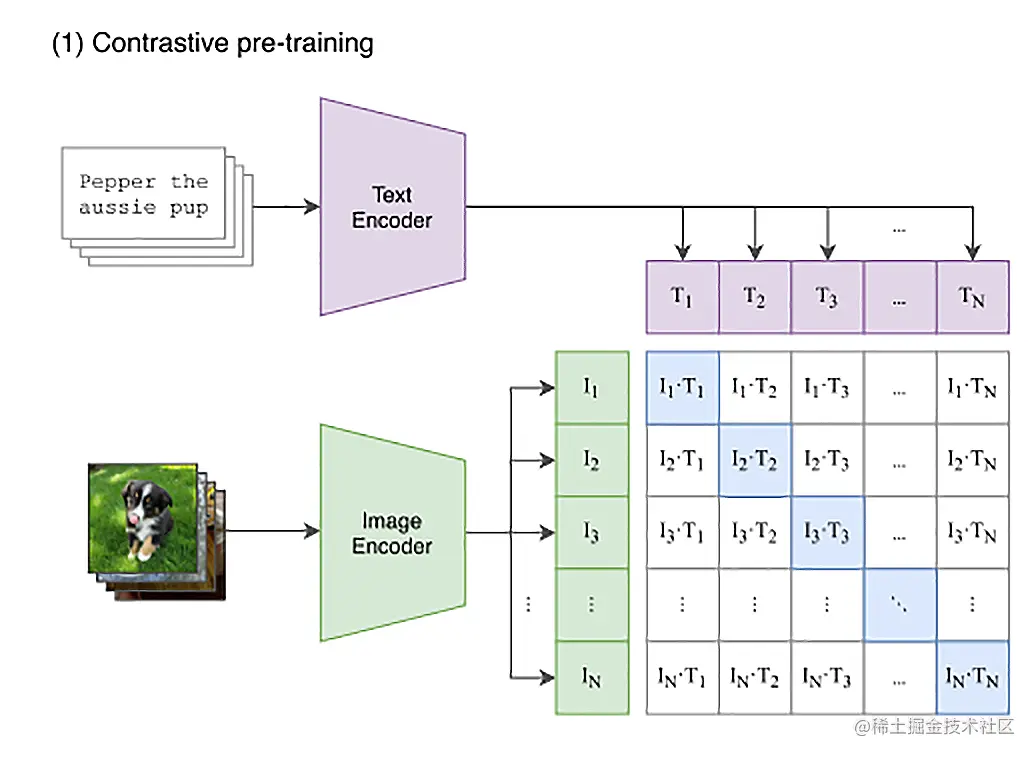
CLIP的思路并不复杂,就是利用互联网上已有的大量公开的图片数据。其中有很多已经通过HTML标签里面的title或者alt字段,提供了对图片的文本描述。那我们只要训练一个模型,将文本转换成一个向量,也将图片转换成一个向量。图片向量应该和自己的文本描述向量的距离尽量近,和其他的文本向量要尽量远。那么这个模型,就能够把图片和文本映射到同一个空间里。我们就能够通过向量同时理解图片和文本了。
图片的零样本分类
js复制代码
import torch
from PIL import Image
from IPython.display import display
from IPython.display import Image as IPyImage
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def get_image_feature(filename: str):
image = Image.open(filename).convert("RGB")
processed = processor(images=image, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
image_features = model.get_image_features(pixel_values=processed["pixel_values"])
return image_features
def get_text_feature(text: str):
processed = processor(text=text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
text_features = model.get_text_features(processed['input_ids'])
return text_features
def cosine_similarity(tensor1, tensor2):
tensor1_normalized = tensor1 / tensor1.norm(dim=-1, keepdim=True)
tensor2_normalized = tensor2 / tensor2.norm(dim=-1, keepdim=True)
return (tensor1_normalized * tensor2_normalized).sum(dim=-1)
image_tensor = get_image_feature("./data/cat.jpg")
cat_text = "This is a cat."
cat_text_tensor = get_text_feature(cat_text)
dog_text = "This is a dog."
dog_text_tensor = get_text_feature(dog_text)
two_cats_text = "There are two cats."
two_cats_text_tensor = get_text_feature(two_cats_text)
truck_text = "This is a truck."
truck_text_tensor = get_text_feature(truck_text)
couch_text = "This is a couch."
couch_text_tensor = get_text_feature(couch_text)
display(IPyImage(filename='./cat.jpg'))
print("Similarity with cat : ", cosine_similarity(image_tensor, cat_text_tensor))
print("Similarity with dog : ", cosine_similarity(image_tensor, dog_text_tensor))
print("Similarity with two cats : ", cosine_similarity(image_tensor, two_cats_text_tensor))
print("Similarity with truck : ", cosine_similarity(image_tensor, truck_text_tensor))
输出结果:

代码解释:
- 通过Transformers库的CLIPModel、CLIPProcessor,加载了clip-vit-base-patch32这个模型,用来处理我们的图片和文本信息。
- get_image_features方法里,所做事情:
- 通过CLIPProcessor对图片进行预处理,变成一系列的数值特征表示的向量。预处理过程,就是把原始的图片,变成一个个像素的RGB值;然后统一图片的尺寸,以及对于不规则的图片截取中间正方形的部分,最后进行数值的归一化。
- 通过CLIPModel,把上面的数值向量,推断成一个表达了图片含义的张量。
- get_text_features类似,先把文本通过CLIPProcessor转换成Token,然后再通过模型推断出文本的张量。
- 定义了一个cosine_similarity函数,用来计算两个张量之间的余弦相似度。
- 就是利用上面的这些函数,来计算图片和文本之间的相似度。
从输出结果可以看到,“There are two cats.”的相似度最高,因为图里有沙发,所以“This is a couch.”的相似度也要高于“This is a dog.”。而Dog和Cat相似,所以相似度也比完全不相关的Truck要高。可以得到,CLIP模型对图片和文本的语义理解是非常准确的。
通过CLIP进行目标检测
除了能够实现零样本的图像分类之外,我们也可以将它应用到零样本下的目标检测中。目标检测其实就是是在图像中框出特定区域,然后对这个区域内的图像内容进行分类。因此,我们同样可以用 CLIP 来实现目标检测任务。
js复制代码from transformers import pipeline
import cv2
from matplotlib import pyplot as plt
detector = pipeline(model="google/owlvit-base-patch32", task="zero-shot-object-detection")
detected = detector(
"./cat.jpg",
candidate_labels=["cat", "dog", "truck", "couch", "remote"],
)
# Read the image
image_path = "./cat.jpg"
image = cv2.imread(image_path)
# Convert the image from BGR to RGB format
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Draw the bounding box and label for each detected object
for detection in detected:
box = detection['box']
label = detection['label']
score = detection['score']
# Draw the bounding box and label on the image
xmin, ymin, xmax, ymax = box['xmin'], box['ymin'], box['xmax'], box['ymax']
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
cv2.putText(image, f"{label}: {score:.2f}", (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# Display the image in Jupyter Notebook
plt.imshow(image)
plt.axis('off')
plt.show()
输出结果如下:
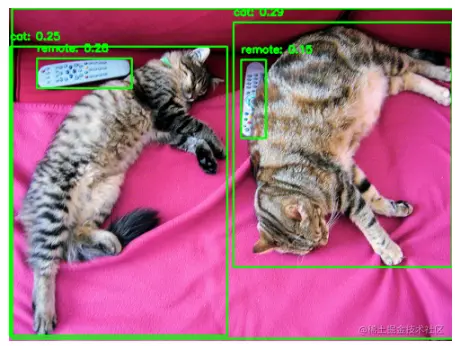
从最后的输出结果来看,无论是猫咪、遥控器还是沙发,都被准确地框选出来了。
总结
通过 CLIP 模型,我们可以对任意物品名称进行零样本分类。进一步地,我们还能进行零样本的目标检测。而文本和图片在同一个向量空间的这个特性,也能够让我们直接利用这个模型进一步优化我们的商品搜索功能。我们可以拿文本的向量,通过找到余弦距离最近的商品图片来优化搜索的召回过程。我们也能直接拿图片向量,实现以图搜图这样的功能。
CLIP 这样的多模态模型,进一步拓展了我们 AI 的能力。我们现在写几个提示语,就能让 AI 拥有绘画的能力,这一点也可以认为是发端于此的。
