

概述
上文 OpenAI 函数调用(1) – ChatGPT Plugin 是如何实现的? 我们提到了 OpenAI Functions Calling(函数调用)功能的基本概念以及使用流程,本文会基于上文内容进行展开,主要包括 2 个方向:
- 补充
Functions Calling功能使用中的高级的用法,如多轮对话及精准控制函数调用与否; - 补充更多的
Functions Calling的使用场景,如本地数据库的 SQL 查询;
好的,下面就继续使用查询天气的场景来详细讲解下 Functions Calling 的一些高级功能。
Functions Calling 高级用法
在开始高级用法之前,先简单回顾下 Functions Calling 的使用流程:
- 声明函数并请求 API:定义当前函数的名称,描述,以及对应的参数信息,并执行 OpenAI 的 Chat 接口;
- 执行本地函数:接受接口返回,并解析对应的函数参数信息,根据对应的参数信息调用本地函数;
- 上报执行结果:将本地函数执行的结果上报给 OpenAI Chat 接口进行汇总、总结;
整体的时序图大致如下:
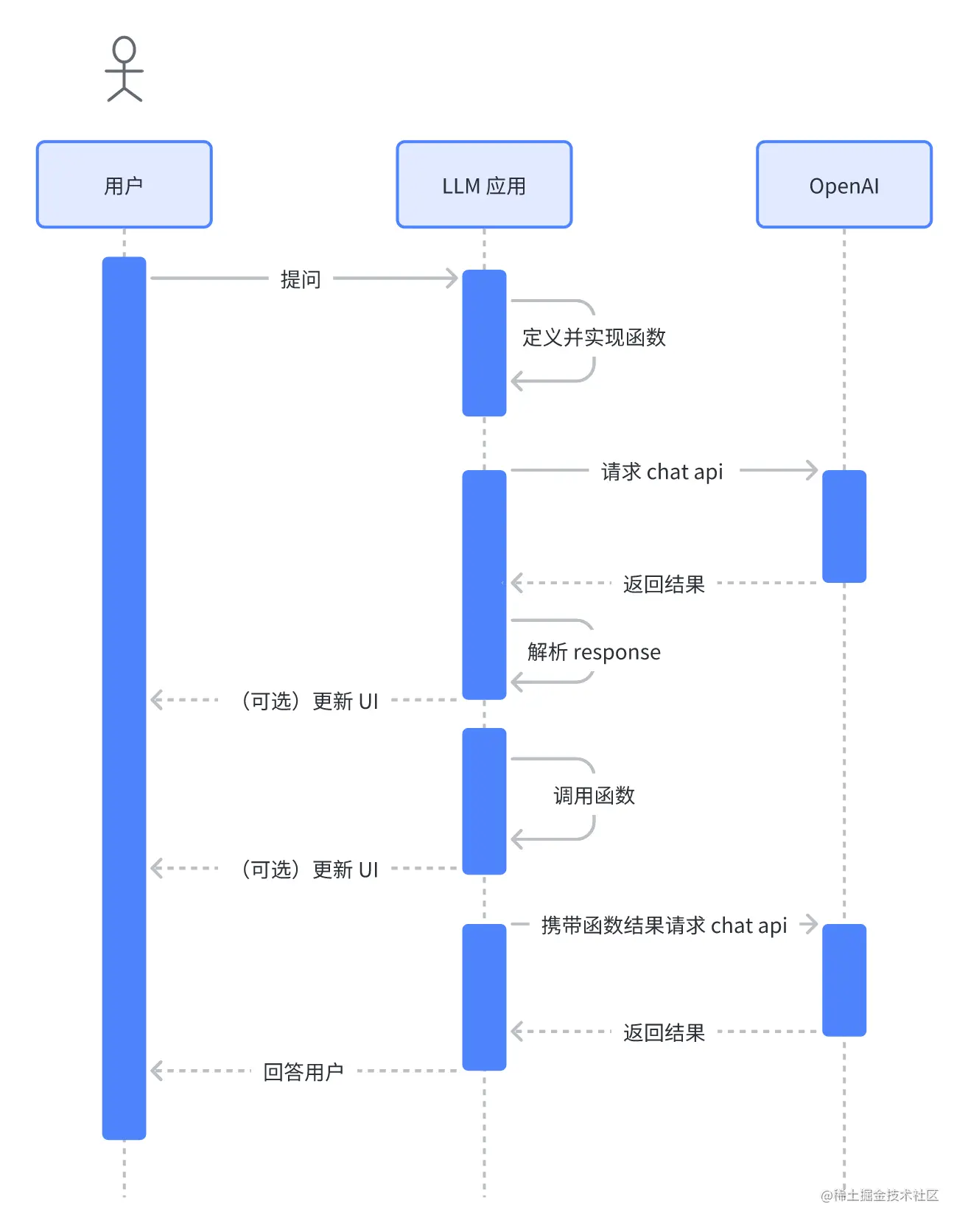
下面会使用查询天气的这个案例来讲解下一些高级用法,首先我们先封装一些基础的函数。
基础函数封装
首先封装一个 chat 函数,可以传入对话内容,functions,function_call 信息,定义大致如下:
python复制代码@retry(wait=wait_random_exponential(min=1, max=40), stop=stop_after_attempt(3))
def chat_completion_request(messages, functions=None, function_call=None, model=GPT_MODEL):
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + openai.api_key,
}
json_data = {"model": model, "messages": messages}
if functions is not None:
json_data.update({"functions": functions})
if function_call is not None:
json_data.update({"function_call": function_call})
try:
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers=headers,
json=json_data,
)
return response
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
为了方便查看结果,我们在封装一个日志打印的函数,如下:
python复制代码def pretty_print_conversation(messages):
role_to_color = {
"system": "red",
"user": "green",
"assistant": "blue",
"function": "magenta",
}
formatted_messages = []
for message in messages:
if message["role"] == "system":
formatted_messages.append(f"system: {message['content']}n")
elif message["role"] == "user":
formatted_messages.append(f"user: {message['content']}n")
elif message["role"] == "assistant" and message.get("function_call"):
formatted_messages.append(f"assistant: {message['function_call']}n")
elif message["role"] == "assistant" and not message.get("function_call"):
formatted_messages.append(f"assistant: {message['content']}n")
elif message["role"] == "function":
formatted_messages.append(f"function ({message['name']}): {message['content']}n")
for formatted_message in formatted_messages:
print(
colored(
formatted_message,
role_to_color[messages[formatted_messages.index(formatted_message)]["role"]],
)
)
其打印效果大致如下,每一种角色都使用不同的颜色打印出来(不用关注具体的打印内容,下文会详细讲解):
多轮对话
当我们定义的函数需要多个必传字段,并且用户在一轮对话中没有提供足够多的信息的时候,GPT 会询问用户,直到用户提供了必要的信息后才会触发函数调用。
下面还是用查询天气为例来详细说明下,首先需要先定义下对应查询天气的函数:
get_current_weather:查询当前的天气情况,需求传入对应的位置信息以及天气的格式;get_n_day_weather_forecast:获取最近 N 天的天气情况,需求传入对应的位置信息、天气的格式以及查询的天数;
函数声明如下:
python复制代码functions = [
{
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
},
{
"name": "get_n_day_weather_forecast",
"description": "Get an N-day weather forecast",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
"num_days": {
"type": "integer",
"description": "The number of days to forecast",
}
},
"required": ["location", "format", "num_days"]
},
},
]
但用户询问当前天气,并且没有告知询问哪里的天气时,GPT 回询问需要查询哪里的天气,代码如下:
python复制代码messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "What's the weather like today"})
chat_response = chat_completion_request(
messages, functions=functions
)
assistant_message = chat_response.json()["choices"][0]["message"]
messages.append(assistant_message)
pretty_print_conversation(messages)
对话内容大致如下:
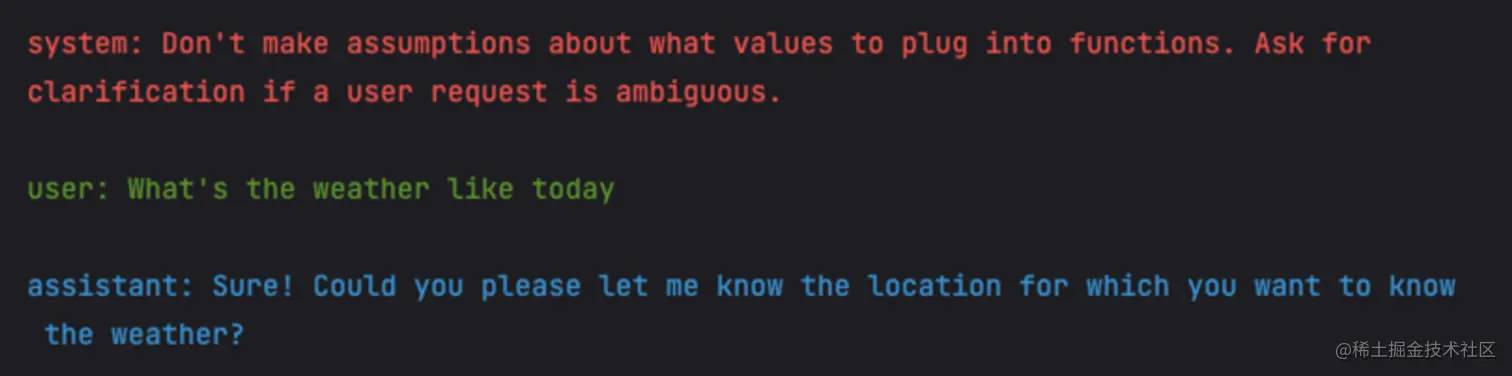
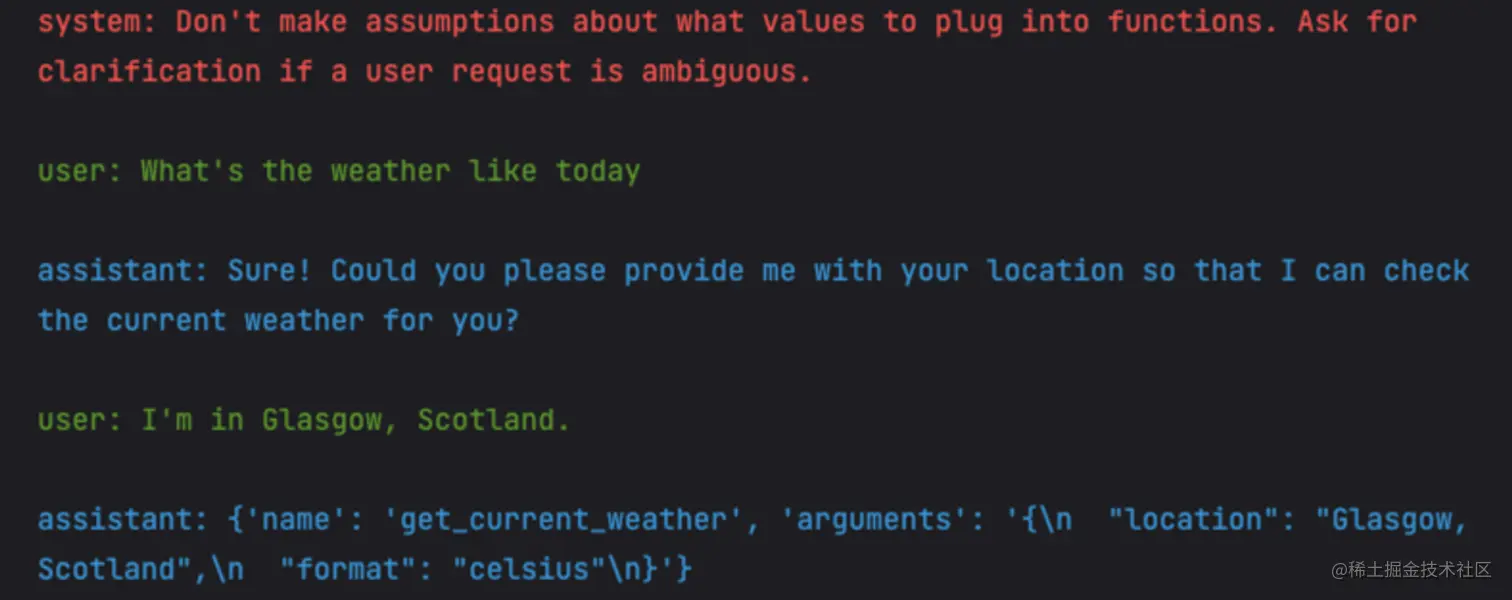
这就是所谓的多轮对话,当需要传入的参数没有提供时,会询问用户对应的信息,直到用户回答了所有的信息。这是 Chat 接口就会返回对应的 function_call 字段,返回内容大致如下:
json复制代码{
"role": "assistant",
"content": null,
"function_call": {
"name": "get_current_weather",
"arguments": "{n "location": "Glasgow, Scotland",n "format": "celsius"n}"
}
}
完整的对话过程大致如下:
我们定义的 get_n_day_weather_forecast 函数也是通用的逻辑,大家可以自行尝试。
精准控制函数调用
上述的对话过程中,我们询问了和天气相关内容并且补全了对应的信息,GPT 最终会调用对应的函数。正常情况下,我们询问无关的问题时并不会出发对应的函数定义,如下对话内容:
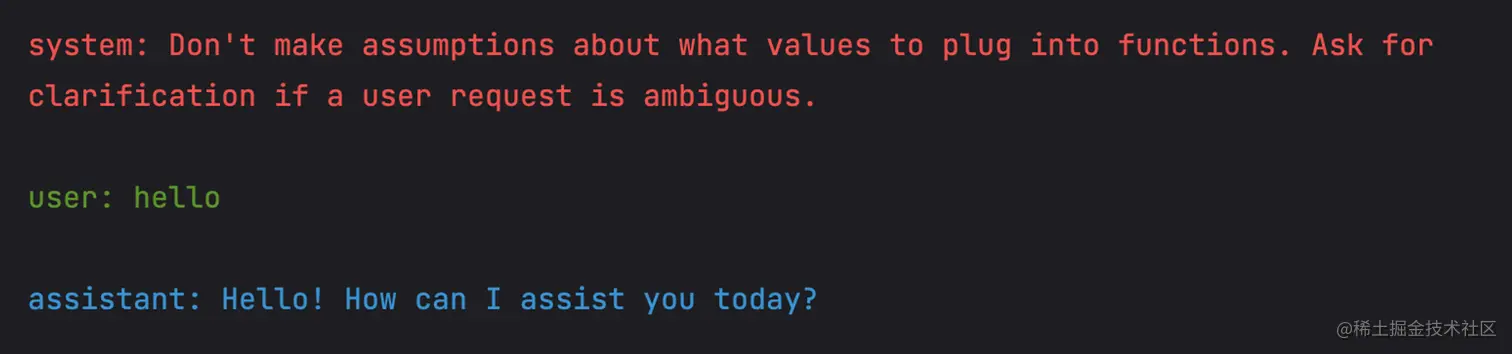
我们可以在请求接口的时候使用 function_call 字段强制 GPT 调用对应的函数,代码如下:
json复制代码messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "hello"})
chat_response = chat_completion_request(
messages, functions=functions, function_call={"name": "get_n_day_weather_forecast"}
)
assistant_message = chat_response.json()["choices"][0]["message"]
messages.append(assistant_message)
pretty_print_conversation(messages)
至于缺失的参数 GPT 会自动生成,返回的结果大致如下:
json复制代码{
//...
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"function_call": {
"name": "get_n_day_weather_forecast",
"arguments": "{n "location": "San Francisco, CA",n "format": "celsius",n "num_days": 5n}"
}
},
"finish_reason": "stop"
}
]
}
完整的对话流程如下:
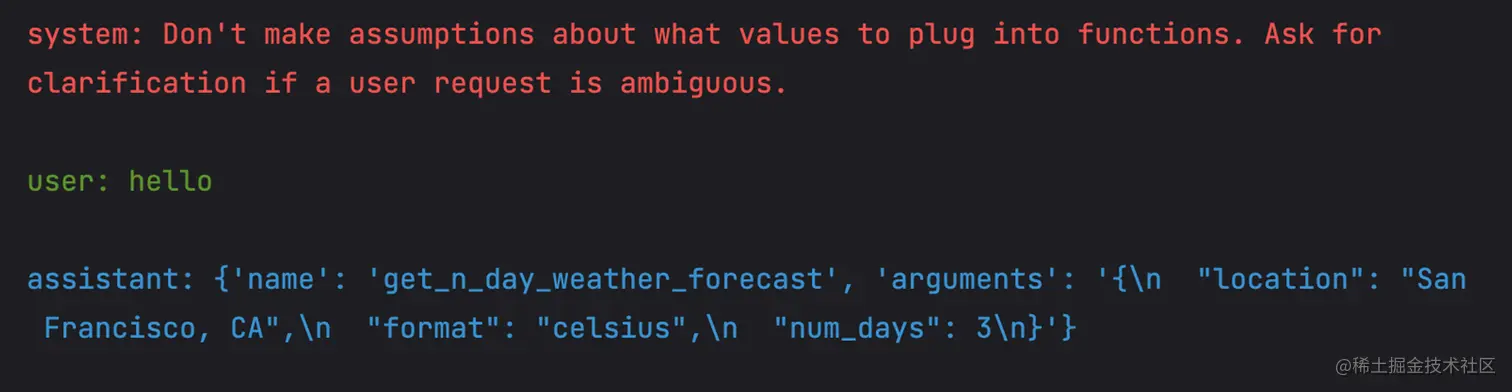
可知,GPT 自动生成需要的地址(San Francisco, CA)、天气格式(celsius)以及需要查询的天数(3)。
关于始终被调用的这个特性在一些 LLM 应用中将会变得非常实用,我们可以始终要求返回对应的 JSON 结构,而不再是处理一些纯文本对话了。比如,返回 command 和 payload 形式内容,我们就可以很好的去处理对应的逻辑了。当然,这属于函数调用的 hack 用法了,这种场景返回的内容不是参数,而是对应的 Response 了。
精准控制函数不被调用
可以通知 GPT 始终调用函数,同样的也可以设置始终不调用函数,将对应的 function_call 设置为 none 即可。如下:
python复制代码messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "Give me the current weather (use Celcius) for Toronto, Canada."})
chat_response = chat_completion_request(
messages, functions=functions, function_call="none"
)
assistant_message = chat_response.json()["choices"][0]["message"]
messages.append(assistant_message)
pretty_print_conversation(messages)
assistant_message 对应的 JOSN 内容如下:
python复制代码{
"role": "assistant",
"content": "{n "location": "Toronto, Canada",n "format": "celsius"n}"
}
注意,上述并没有调用函数,只是 content 的内容返回的 JSON 格式。对话流程大致如下:
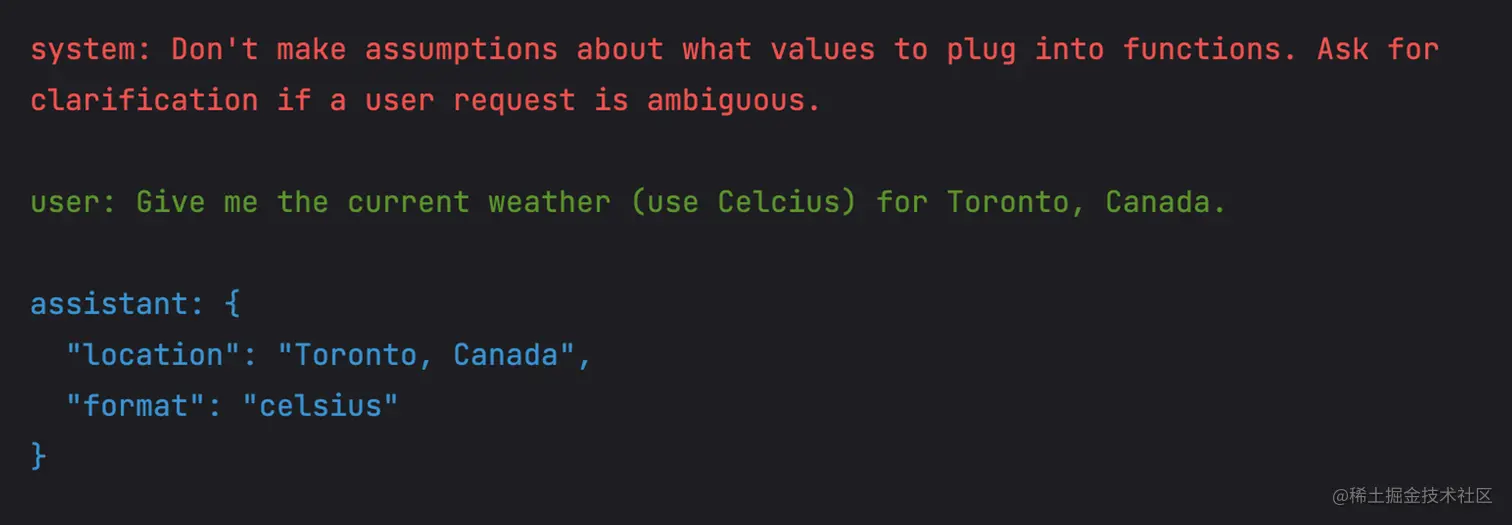
当然,不传入 functions 参数也可以达到同样的效果。
上述的内容都在围绕着 OpenAI 的 Chat 接口如何调用,关于 get_current_weather 与 get_n_day_weather_forecast 函数的具体定义以及执行的并没有展开阐述,这部分其实就是本地的函数定义部分,与具体的业务逻辑有关,与 OpenAI 接口关系不大。
由于查询天气本质上就是网络接口请求,大家应该都比较熟悉,这部不再描述详细的实现细节,下面会以查询本地数据库的场景,来详细阐述下 OpenAI Factions Calling 于本地函数执行的完整逻辑。
案例讲解: SQL 查询
数据库定义
假设现在有一个名为 Chinook.db 的数据库文件,其中包含多张表,每张表中又包含多个字段信息。大致定义如下:
yaml复制代码Table: Album
Columns: AlbumId, Title, ArtistId
Table: Artist
Columns: ArtistId, Name
Table: Customer
Columns: CustomerId, FirstName, LastName, Company, Address, City, State, Country, PostalCode, Phone, Fax, Email, SupportRepId
Table: Employee
Columns: EmployeeId, LastName, FirstName, Title, ReportsTo, BirthDate, HireDate, Address, City, State, Country, PostalCode, Phone, Fax, Email
Table: Genre
Columns: GenreId, Name
Table: Invoice
Columns: InvoiceId, CustomerId, InvoiceDate, BillingAddress, BillingCity, BillingState, BillingCountry, BillingPostalCode, Total
Table: InvoiceLine
Columns: InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity
Table: MediaType
Columns: MediaTypeId, Name
Table: Playlist
Columns: PlaylistId, Name
Table: PlaylistTrack
Columns: PlaylistId, TrackId
Table: Track
Columns: TrackId, Name, AlbumId, MediaTypeId, GenreId, Composer, Milliseconds, Bytes, UnitPrice
想要 GPT 帮我们生成一些查询数据库的参数,必须要告诉 GPT 我们数据库的一些结构信息,否则它并不会生成准确的信息。所以下面就是定义一些基础函数来生成一些数据库的描述信息,并将其传递给 GPT 。
数据信息生成
首先我们需要定义一些函数来生成类似上述的数据库描述信息(表结构),首先定义获取数据库信息的函数,大致代码如下:
python复制代码def get_table_names(conn):
"""Return a list of table names."""
table_names = []
tables = conn.execute("SELECT name FROM sqlite_master WHERE type='table';")
for table in tables.fetchall():
table_names.append(table[0])
return table_names
def get_column_names(conn, table_name):
"""Return a list of column names."""
column_names = []
columns = conn.execute(f"PRAGMA table_info('{table_name}');").fetchall()
for col in columns:
column_names.append(col[1])
return column_names
def get_database_info(conn):
"""Return a list of dicts containing the table name and columns for each table in the database."""
table_dicts = []
for table_name in get_table_names(conn):
columns_names = get_column_names(conn, table_name)
table_dicts.append({"table_name": table_name, "column_names": columns_names})
return table_dicts
然后我们将对应的数据描述信息整理成一段可理解的描述信息,代码大致如下:
python复制代码import sqlite3
conn = sqlite3.connect("data/Chinook.db")
print("Opened database successfully")
database_schema_dict = get_database_info(conn)
database_schema_string = "n".join(
[
f"Table: {table['table_name']}nColumns: {', '.join(table['column_names'])}"
for table in database_schema_dict
]
)
打印出 database_schema_string 信息如下:
makefile复制代码Table: Album
Columns: AlbumId, Title, ArtistId
Table: Artist
Columns: ArtistId, Name
Table: Customer
Columns: CustomerId, FirstName, LastName, Company, Address, City, State, Country, PostalCode, Phone, Fax, Email, SupportRepId
Table: Employee
Columns: EmployeeId, LastName, FirstName, Title, ReportsTo, BirthDate, HireDate, Address, City, State, Country, PostalCode, Phone, Fax, Email
Table: Genre
Columns: GenreId, Name
Table: Invoice
Columns: InvoiceId, CustomerId, InvoiceDate, BillingAddress, BillingCity, BillingState, BillingCountry, BillingPostalCode, Total
Table: InvoiceLine
Columns: InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity
Table: MediaType
Columns: MediaTypeId, Name
Table: Playlist
Columns: PlaylistId, Name
Table: PlaylistTrack
Columns: PlaylistId, TrackId
Table: Track
Columns: TrackId, Name, AlbumId, MediaTypeId, GenreId, Composer, Milliseconds, Bytes, UnitPrice
有了对应的信息之后,我们就可以声明对应的 functions 了。
Function Calling 声明与定义
想要 GPT 帮我们生成一些查询数据库的参数,必须要告诉 GPT 我们数据库的一些结构信息,对应的定义如下:
name:函数名为 ask_database,可以查询数据库的一些信息;description:详细描述下函数的作用以及期望的格式;parameters:函数接受一个名为query的参数,将对应的自然语言转换成对应的 SQL 语句,而对query的描述就需要添加上对应的数据库信息了;
对应的声明大致如下:
python复制代码functions = [
{
"name": "ask_database",
"description": "Use this function to answer user questions about music. Output should be a fully formed SQL query.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
SQL query extracting info to answer the user's question.
SQL should be written using this database schema:
{database_schema_string}
The query should be returned in plain text, not in JSON.
""",
}
},
"required": ["query"],
},
}
]
下面就是需要定义一个 ask_database 这个函数的真实逻辑了。
本地函数定义
下面就是一个查询本地数据库的具体实现,该函数会接受对应的 SQL 语句,并返回对应的查询结果,代码如下:
python复制代码def ask_database(conn, query):
"""Function to query SQLite database with a provided SQL query."""
try:
results = str(conn.execute(query).fetchall())
except Exception as e:
results = f"query failed with error: {e}"
return results
def execute_function_call(message):
if message["function_call"]["name"] == "ask_database":
query = json.loads(message["function_call"]["arguments"])["query"]
results = ask_database(conn, query)
else:
results = f"Error: function {message['function_call']['name']} does not exist"
return results
Chat 完整流程
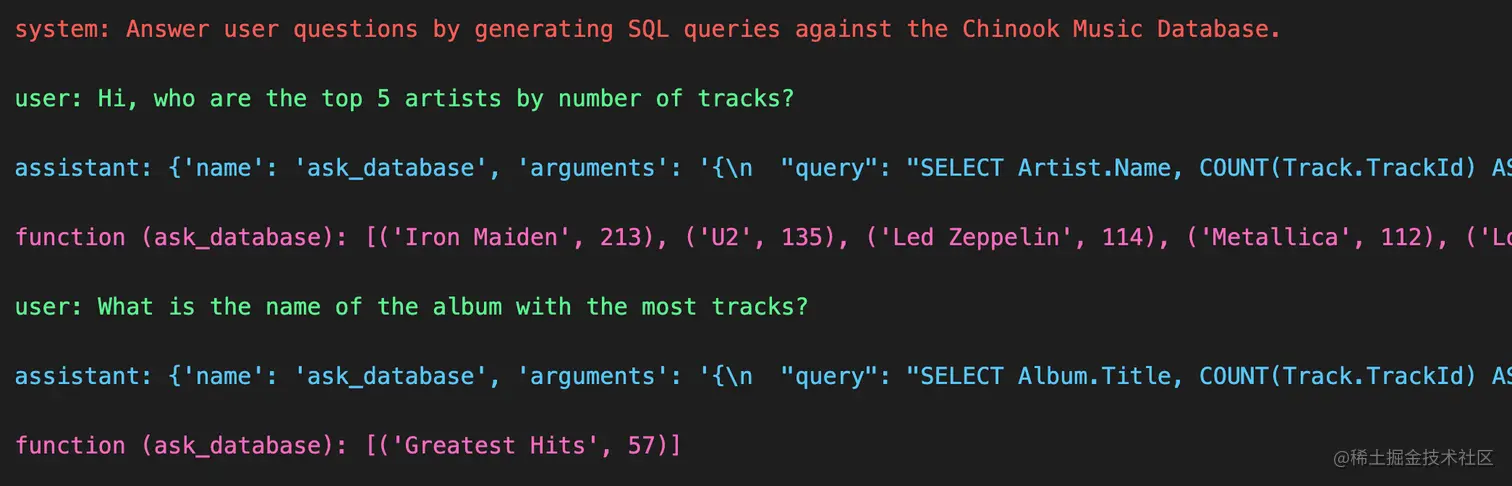
所有的准备工作都已经完成了,我们看一下完成流程的效果,用户正常对话的过程中会有什么效果。比如我们想要查询歌曲量前 5 的歌手都有哪些,代码如下:
python复制代码messages = []
messages.append({"role": "system", "content": "Answer user questions by generating SQL queries against the Chinook Music Database."})
messages.append({"role": "user", "content": "Hi, who are the top 5 artists by number of tracks?"})
chat_response = chat_completion_request(messages, functions)
assistant_message = chat_response.json()["choices"][0]["message"]
# 解析对应的结果,并添加到对话历史中
messages.append(assistant_message)
if assistant_message.get("function_call"):
# 执行本地的数据库查询逻辑
results = execute_function_call(assistant_message)
# 将执行结果添加对话历史中
messages.append({"role": "function", "name": assistant_message["function_call"]["name"], "content": results})
pretty_print_conversation(messages)
这个过程中产生的对话历史如下:
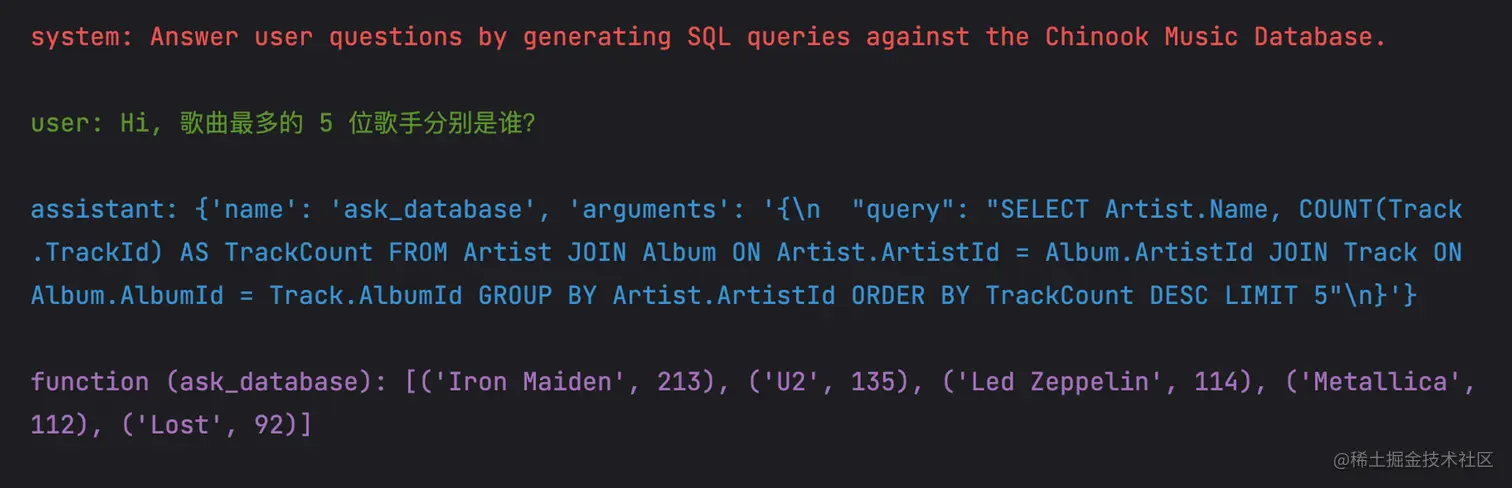
到这里整个环节还没有完成,我还需将上述的对话历史请求 OpenAI 的 Chat 接口,GPT 会根据函数的结果整理成容易理解的自然语言。代码如下:
python复制代码# 使用上述的对话历史再次请求 Chat 接口
chat_response = chat_completion_request(messages, functions)
# 将 GPT 返回的那天添加到对话历史中
assistant_message = chat_response.json()["choices"][0]["message"]
messages.append(assistant_message)
pretty_print_conversation(messages)
整个过程完整的对话历史如下:

可见,GPT 的确是将数据库的查询结果转换成容易理解的自然语言了。
总结
本文介绍了 Function Calling 的一些高级用法,如:
- GPT 的多轮对话机制,来询问用户提供必要的关键信息(通过 Prompt 控制);
- 强制要求 GPT 使用指定函数,并生成一些参数信息;
- 也可以要求 GPT 不用使用函数;
为了演示完整真实的使用场景,我们以查询本地数据库的具体案例讲解了 Function Calling 声明的细节(一定要将对应的信息完整的给到GPT,否则它并不能完全理解“参数”传递的合理性),以及函数执行的完整流程。
后面会讲解打造自己的 Plugin 商店的一些思路,可以无缝的将现有的 ChatGPT Plugin 接入到自己的业务中。
