

一、一觉醒来,AI 视频已变天
一觉醒来,AI 视频已变天。今年开年 AI 界最大的震撼事件:OpenAI 发布了他们的文生视频大模型 Sora。
OpenAI 文生视频大模型 Sora 的横空出世,预示着 AI 视频要变天了,相应的视频创作领域、影视、广告等领域都要重新洗牌了!
除了上面说的这些,还会潜移默化地影响更多领域。
自 Sora 的消息一放出,群里和朋友圈都被 Sora 的消息刷爆了。
啥都不说,先来感受一番:




上面的视频素材,完全由 OpenAI 的 Sora 生成,取自 OpenAI 官网。
你还能辨得出真假吗?
更多视频效果,大家可以去 OpenAI 的官网浏览。
传送门:openai.com/sora
看了 OpenAI 官网 Sora 做出的视频效果,说 Sora 目前是 AI 视频领域的地表最强,应该没有人反对吧。
二、OpenAI Sora 有哪些技术突破
一)视频时长的突破
首先要说 Sora 一大技术突破,就是视频时长的突破。
之前更新了一个 AI 视频工具的系列专栏,有的小伙伴私信找我说,为什么推荐的这些 AI 视频工具,都只能生成几秒的视频呀。
确实,在 OpenAI 的 Sora 横空出世之前,AI 视频工具还没有「突破视频时长的限制」。基本都只能生成几秒、十几秒的视频。
如果想通过 AI 视频工具生成视频,来做自媒体或其他用途,需要多次生成,再用一些剪辑、特效工具加工后,才能出片。
而 Sora 的出现,突破了 AI 视频领域的这一限制,可以直接生成长达一分钟的视频。
在视频时长方面,Sora 直接碾压之前的一众 AI 视频生成工具。
二)世界模型

除了视频时长有突破外,Sora 模型不仅了解用户在提示词中要求的内容,还了解这些东西在物理世界中的存在方式。
之前听过卡兹克大佬一个关于 AI 视频的分享,在分享中,也提到了物理规律这个概念。
比如一拳抡到一个怪物的头上,它是有一个物体的交互的,整个视频的呈现,都是要符合物理世界的规律。
但在 Sora 之前的 AI 视频工具中,这块并没有突破。
而这块如果没有突破,AI 生成的视频,是很难应用到影视或者工业这块的。
但 Sora 的出现,让我们看到了可能性。
比如官网上的这个示例视频,枕头和被子的凹陷,都呈现得非常真实。

提示词:一只猫叫醒熟睡的主人要求吃早餐。主人试图无视猫,但猫尝试了新的策略,最后主人从枕头下掏出一个秘密的零食藏匿处,让猫多呆一会儿。
三)单视频多角度镜头
另外,Sora 还可以在单个生成的视频中创建多个角度的镜头,且一致性和稳定性强得惊人。
这在之前的 AI 视频工具中,是远远达不到的。
可以看官网的视频示例。

三、OpenAI Sora 目前有哪些缺陷
虽然 OpenAI 的 Sora 已经在技术上有了很大突破,但依然存在一些缺陷。
比如,它可能难以准确地模拟复杂场景的物理现象,也可能无法理解因果关系的具体实例。
官方也举了一个例子。
比如,一个人可能咬了一口饼干,但是之后,饼干上可能没有咬痕。
除此之外,该模型还可能混淆提示的空间细节。
例如,左右混淆,并且可能难以精确描述随时间推移发生的事件,比如遵循特定的相机轨迹。
关于上面说的这些 Sora 的缺点,OpenAI 官方也放出了一些示例:
比如下面这个视频,吹蜡烛,但蜡烛的火苗却纹丝不动:

再比如,在这个例子中,Sora 未能将椅子建模为一个刚性物体,导致了不准确的物理交互:

四、OpenAI Sora 技术实现
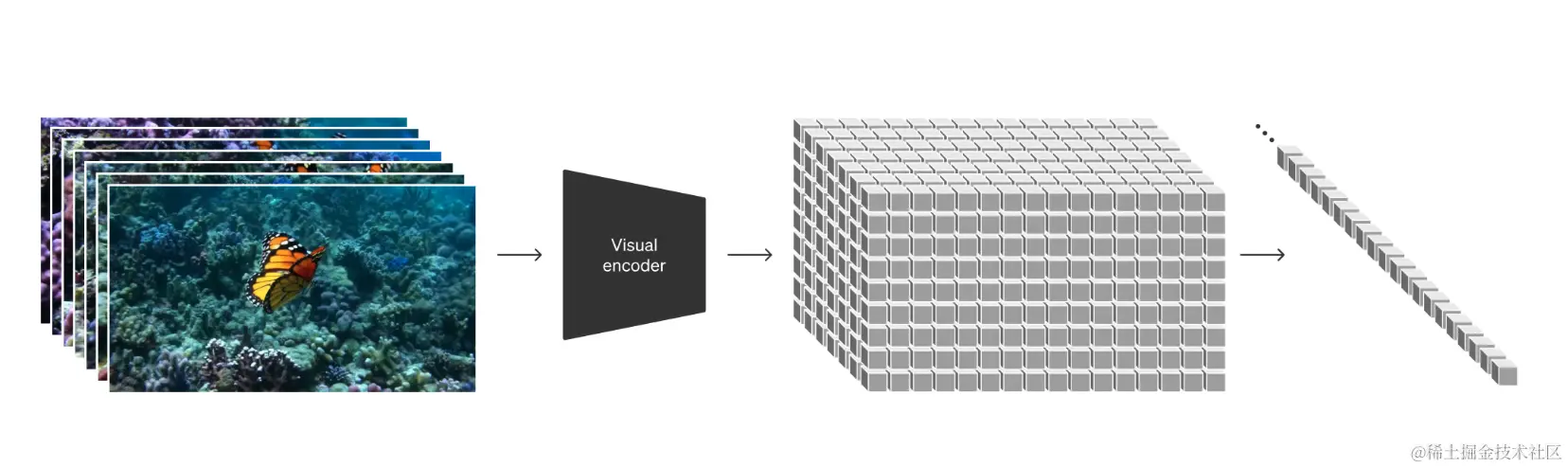
Sora 是一种扩散模型,它从看起来像静态噪声的视频开始生成视频,然后通过多个步骤消除噪声来逐渐转换视频。
Sora 能够一次生成整个视频或扩展生成的视频以使其更长。通过让模型一次看到许多帧,解决了一个具有挑战性的问题,即确保一个主题即使暂时离开视野也能保持不变。
与 GPT 模型类似,Sora 使用 transformer 架构,释放出卓越的扩展性能。

将视频和图像表示为称为补丁的较小数据单元的集合,每个补丁都类似于 GPT 中的一个 token。通过统一我们表示数据的方式,我们可以在比以前更广泛的视觉数据上训练扩散变压器,跨越不同的持续时间、分辨率和纵横比。

Sora建立在 DALL·E 和 GPT 模型上。它使用了 DALL·E 3,涉及为视觉训练数据生成高度描述性的标题。因此,该模型能够更忠实地遵循生成视频中用户的文本说明。
除了能够仅根据文本说明生成视频外,Sora 模型还能够获取现有的静止图像并从中生成视频,从而准确无误地对图像内容进行动画处理,并注重小细节。
该模型还可以拍摄现有视频并对其进行扩展或填充缺失的帧。
更多技术细节,请参考:
一觉醒来,Sora 已颠覆 AI 视频领域,视频、影视、广告等行业将重新洗牌,AGI 还远吗?
