

Lora
LoRA,根据我查资料,完整的名字应该叫做Low-Rank Adaptation of Large Language Models,翻译成汉语是大语言模型的低阶适应,从资料上看是微软的研究人员为了解决大语言模型微调而开发的一项技术。
实战
这一期的目的是为了实战, 我们用到的工具是Kohya_ss,Github的地址是github.com/bmaltais/ko…
为此,我买了个腾讯云的GPU。具体训练的方式方法可以参考我以前的文章
采集资源
这次使用的资源是之前那篇文章生成的图片,图片大小1024X1024,一共4张图片。
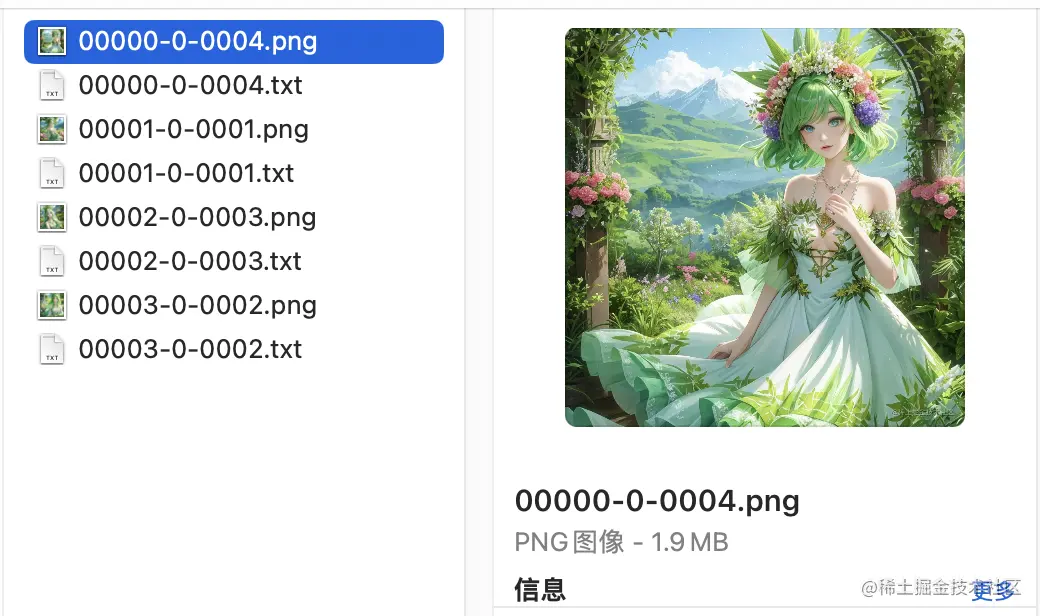
简单的调整了下标注文件,也就是以txt为结尾的文本文件,删除了一些用不到的标签。
这时候资源算是准备就绪了。
资源上传服务器
将资源上传到服务器,只有的目录结构大致如下
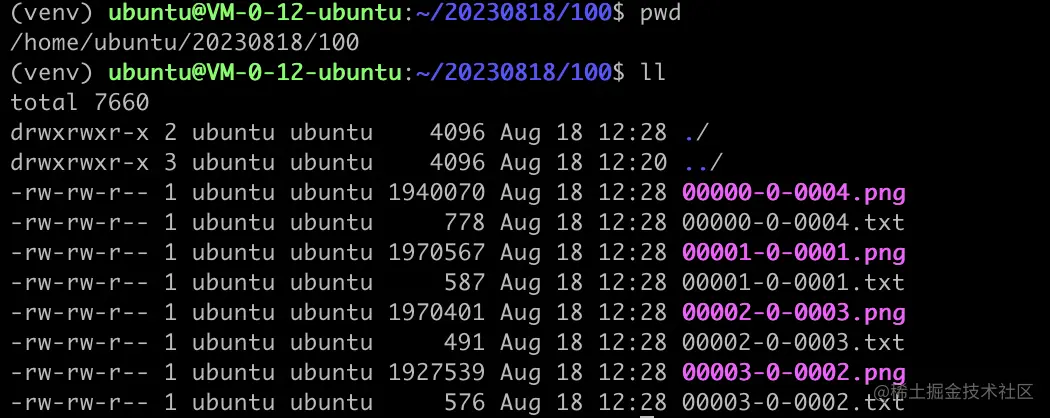
其中文件夹路径是 /home/ubuntu/20230818/100 ,其中的文件夹100是以训练循环的次数命名的,也就是会循环100次。
本次训练创建的文件夹如下
- /home/ubuntu/20230818/100:用于存储训练的图片和标记文件;
- /home/ubuntu/lora:训练结束后,将模型文件存储在这个地方;
- /home/ubuntu/log:日志文件放在这个地方;
Kohya_ss 配置
我们要训练的是Lora,所以选择的Tab是Lora。
设置训练用的主模型
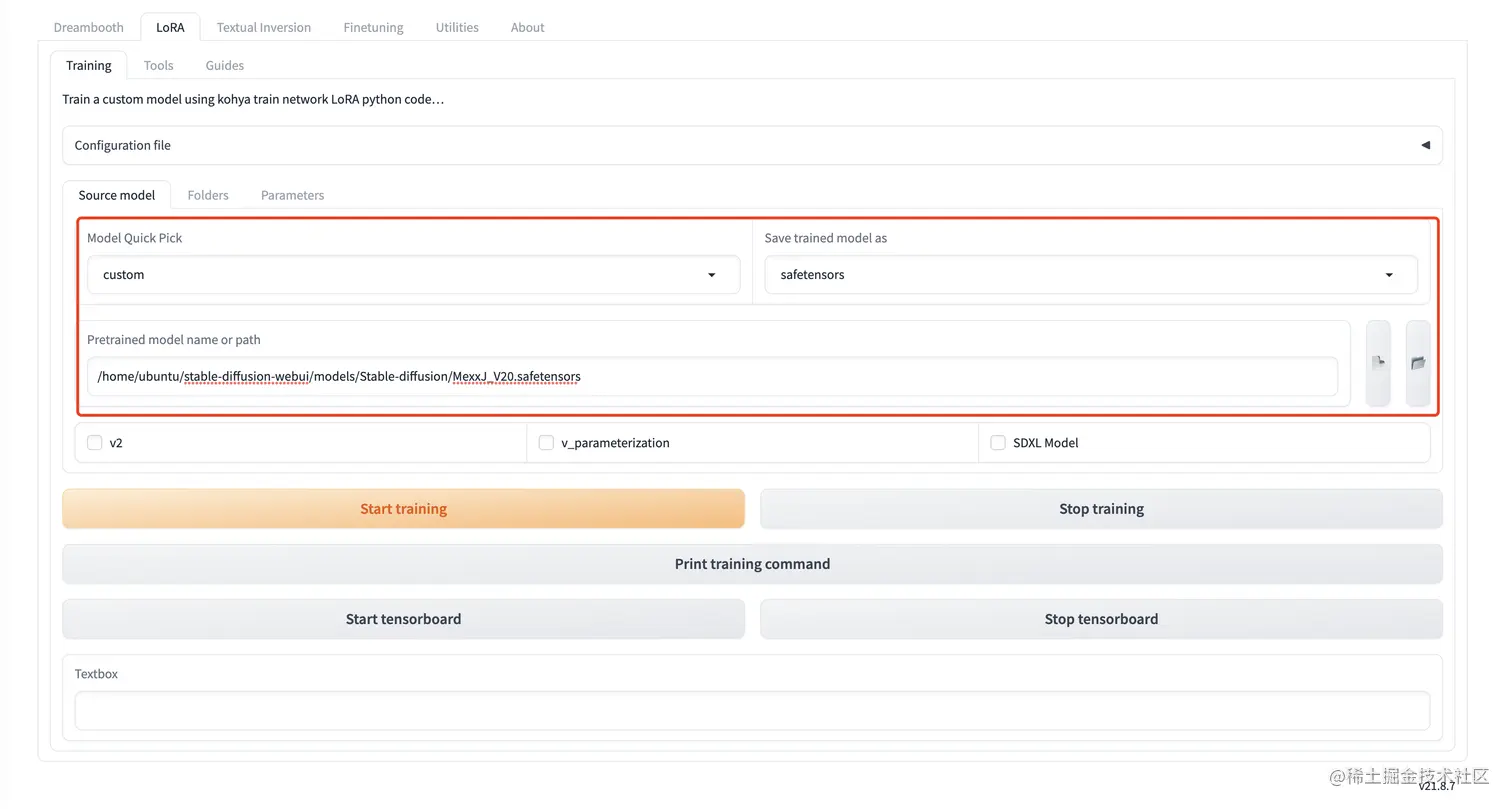
可以选择一个自己喜欢的模型,可以是二次元的,也可以是写实的。
设置文件夹
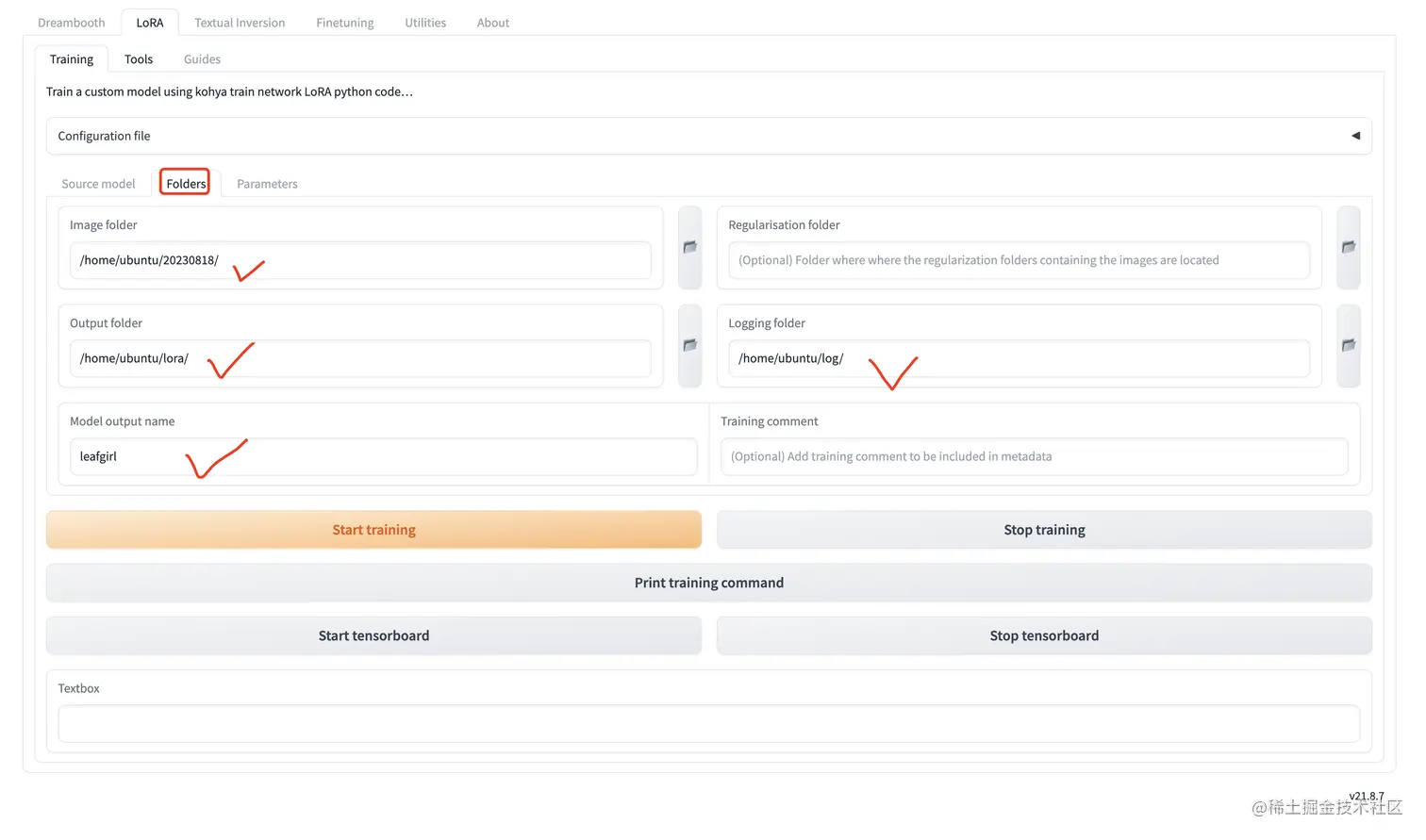
这个文件夹用到了我们之前设置的目录,对号入座即可。
参数设置
通常,我会简单的修改几个参数,当然这和你的训练诉求有直接关系。
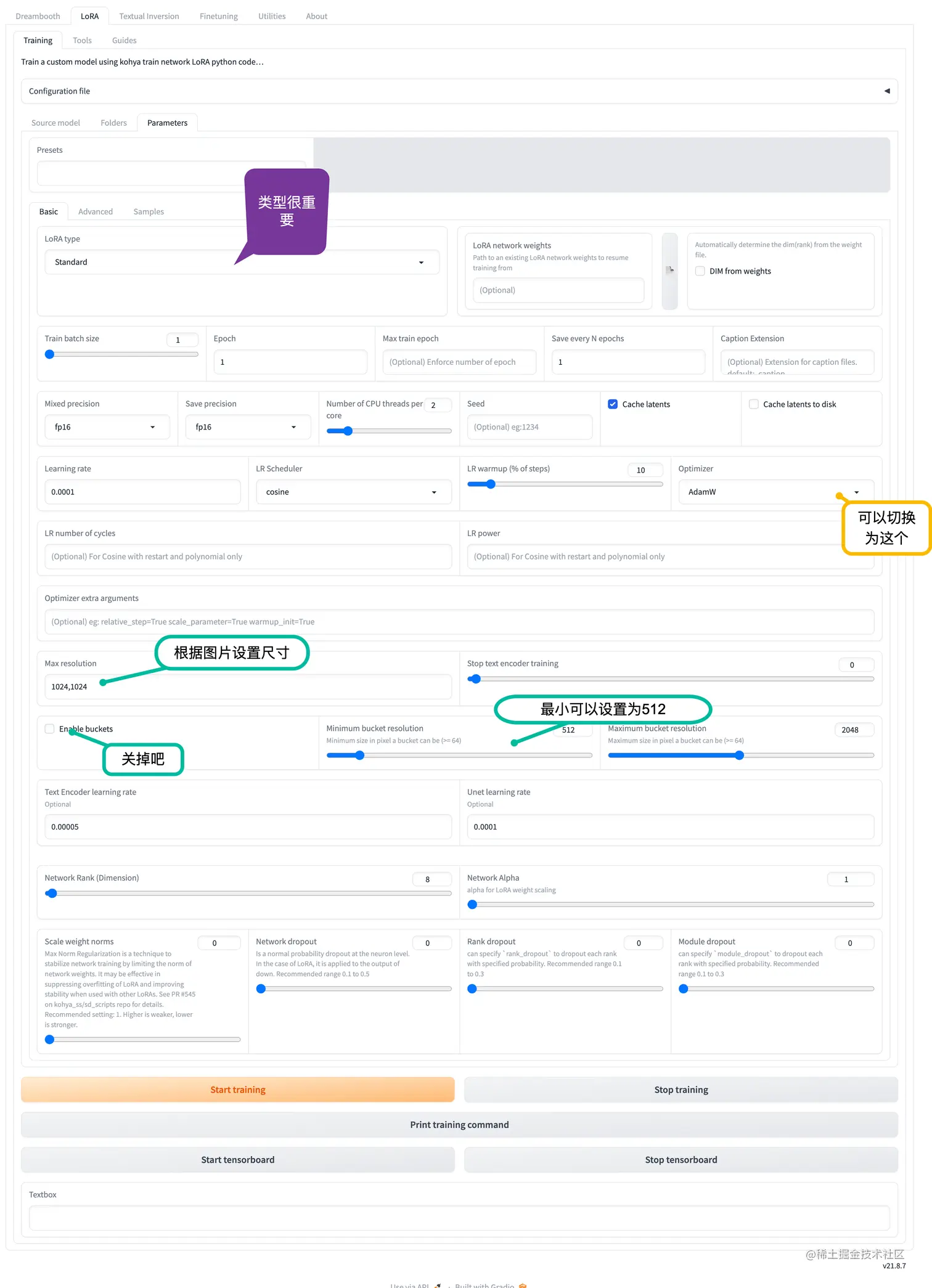
其中训练图片的大小很重要的,需要和我们的训练图片的尺寸对应上,当然更重要的是训练图片的质量啦。
开始训练
当这一切的一切都设置完毕之后,我们需要勇敢的点击下开始训练的按钮。对,就是下面这个按钮。
在控制台,我们可以看到整个训练过程。
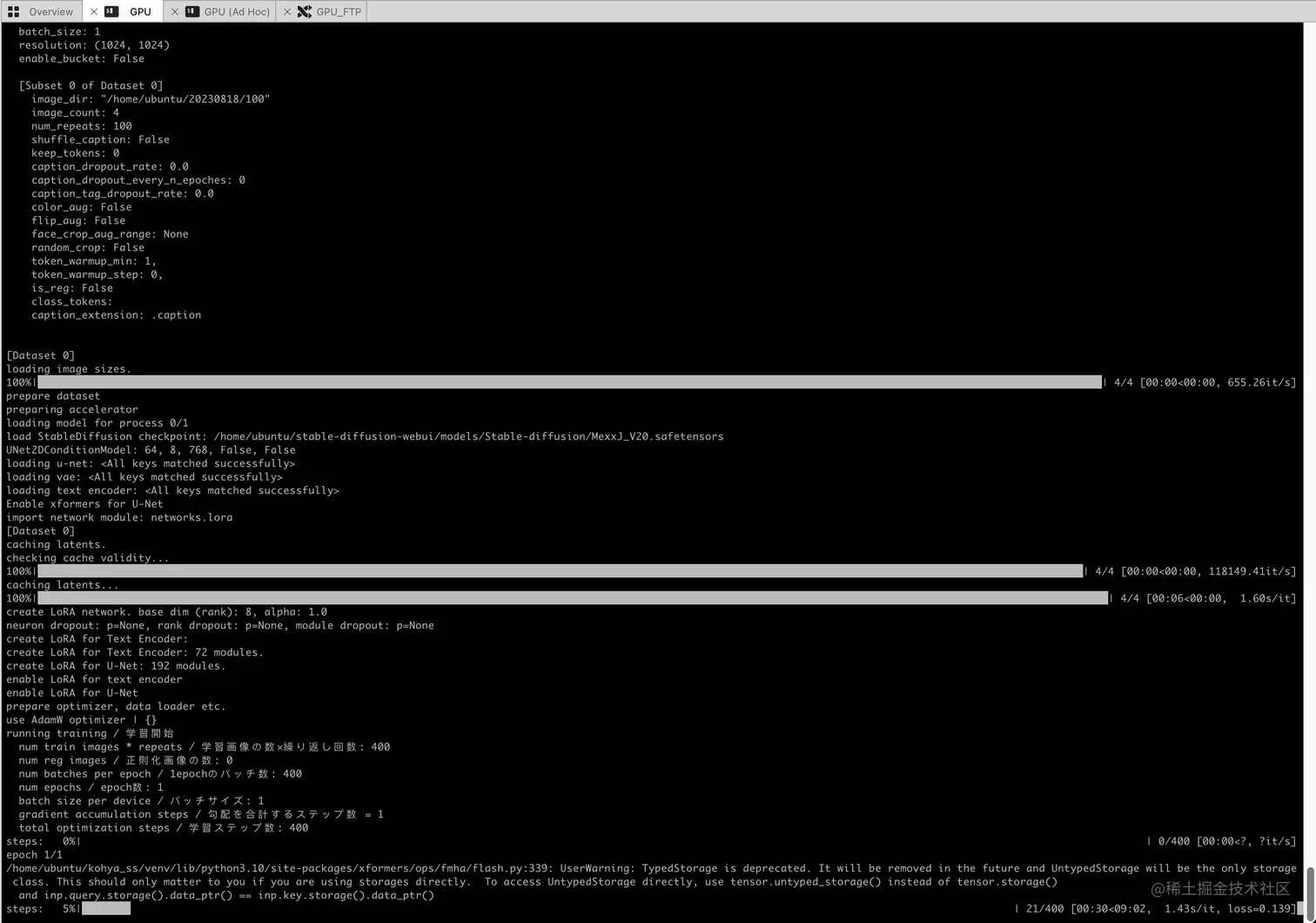
1024x1024的训练图片下,T4的GPU的性能大致是 1.52s/it, 大致经过了10分钟,我们的模型终于出炉了。
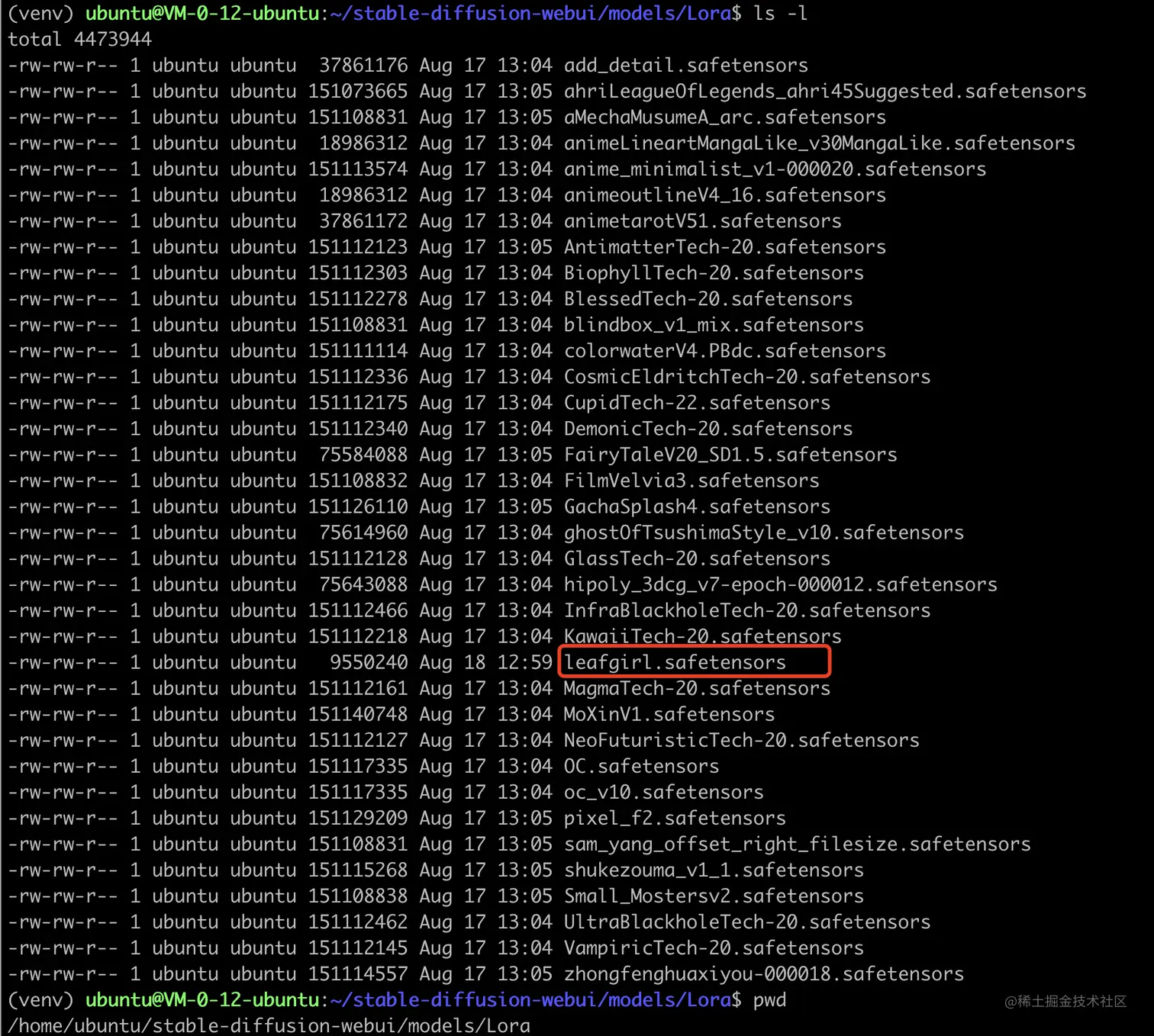
训练结果
在之前配置的目录里,可以看到我们训练完的模型,是不是迫不及待想看下效果啦?

我们的Lora模型效果
我们把训练完的Lora模型(leafgirl.safetensors),放到Stable Diffusion WebUI对应的目录下
启动Stable Diffusion WebUI,然后设置参数大致如下,采用的是一个1:2的宽高比例。
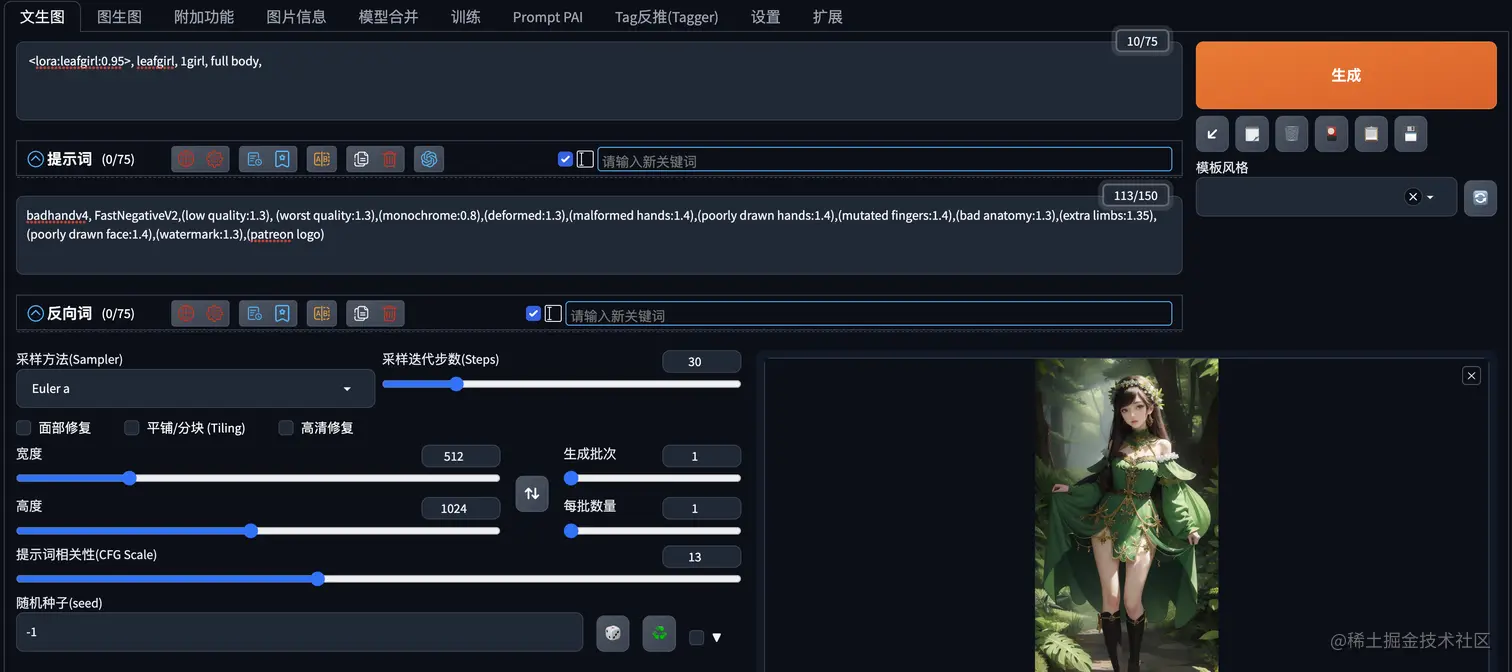
为了减少干扰,我们只使用了1个Lora模型,大致Prompt如下: <lora:leafgirl:1>, leafgirl, 1girl, full body,
反向提示词用了一个通用的,一般影响不大。
开始出图
由于出图比较多,所以就放到C站了,具体可以查看下面的参考资料中的链接。
