

LLM 的提示写法很重要,好的提示可以比差的提示得到更好的效果。但是提示、提示工程和如何改善我给 LLMs 的内容是什么意思呢?这些问题是本章和下一章要回答的。
生成式人工智能可以根据用户的需求创建新的内容(比如文本、图像、音频、代码等)。它利用 LLMs 来达到这个目的,比如 OpenAI 的 GPT 模型系列,这些模型是用自然语言和代码来训练的。
用户现在可以用他们熟悉的语言(比如聊天)和这些模型互动,不需要任何技术专业知识或培训。这些模型是基于提示的——用户发送文本输入(提示)并得到人工智能的回应(完成)。然后,他们可以在多轮对话中不断地“和人工智能聊天”,改进他们的提示,直到回应符合他们的期望。
“提示”现在成为生成式人工智能应用程序的主要编程界面,告诉模型要做什么并影响回应的质量。“提示工程”是一个快速发展的研究领域,专注于提示的“设计和优化”,以提供一致和高质量的回应。
提示工程是什么?
在本章中,我们把提示工程定义为设计和优化文本输入(提示)的过程,以便为指定的应用程序目标和模型提供一致和高质量的回应(完成)。我们可以把它看作一个两步过程:
- 设计适合模型和目标的初始提示
- 通过反复的方式精简提示语来提高回应质量
这是一个需要用户的直觉和努力的试验过程,才能得到最好的结果。那么为什么它很重要呢?要回答这个问题,我们首先需要了解三个概念:
- Tokenization = 模型如何“看待”提示
- Base LLMs = 基础模型如何“处理”提示
- Instruction-Tuned LLM = 模型现在如何看待“任务”
Tokenization
LLM 把提示看作是标记序列,不同的模型(或模型的版本)可能会用不同的方式把同一个提示分成标记。因为 LLM 是根据标记(而不是原始文本)来训练的,所以提示的标记化方式会直接影响生成的回应的质量。
要直观地理解标记化是怎么工作的,请尝试使用像 OpenAI Tokenizer 这样的工具。复制你的提示 – 看看它是如何被转换成标记的,注意空白字符和标点符号是如何处理的。请注意,这个例子显示的是较旧的 LLM (GPT-3) – 所以用较新的模型试试这个操作可能会有不同的结果。

概念: 基础模型
当提示被标记化后,“Base LLM”的主要功能(或基础模型)是预测序列中的标记。因为 LLMs 接受过大量的文本数据集的训练,所以它们对标记之间的统计关系有很好的理解,并且可以自信地做出预测。并不是说它们不理解提示或标记中单词的含义,它们只是看到了一个可以通过下一个预测“完成”的模式。它们可以继续预测序列,直到被用户干预或某些预设的条件停止。
想知道基于提示的补全是怎么工作的吗?用默认设置把上面的提示输入到 Azure OpenAI Studio Chat Playground。系统配置会把提示当作信息请求 – 所以你应该看到符合这个上下文的补全。
但是,如果用户想要看到满足一些标准或任务目标的特定内容怎么办?这就是 LLMs 中的指令调整发挥作用的地方。
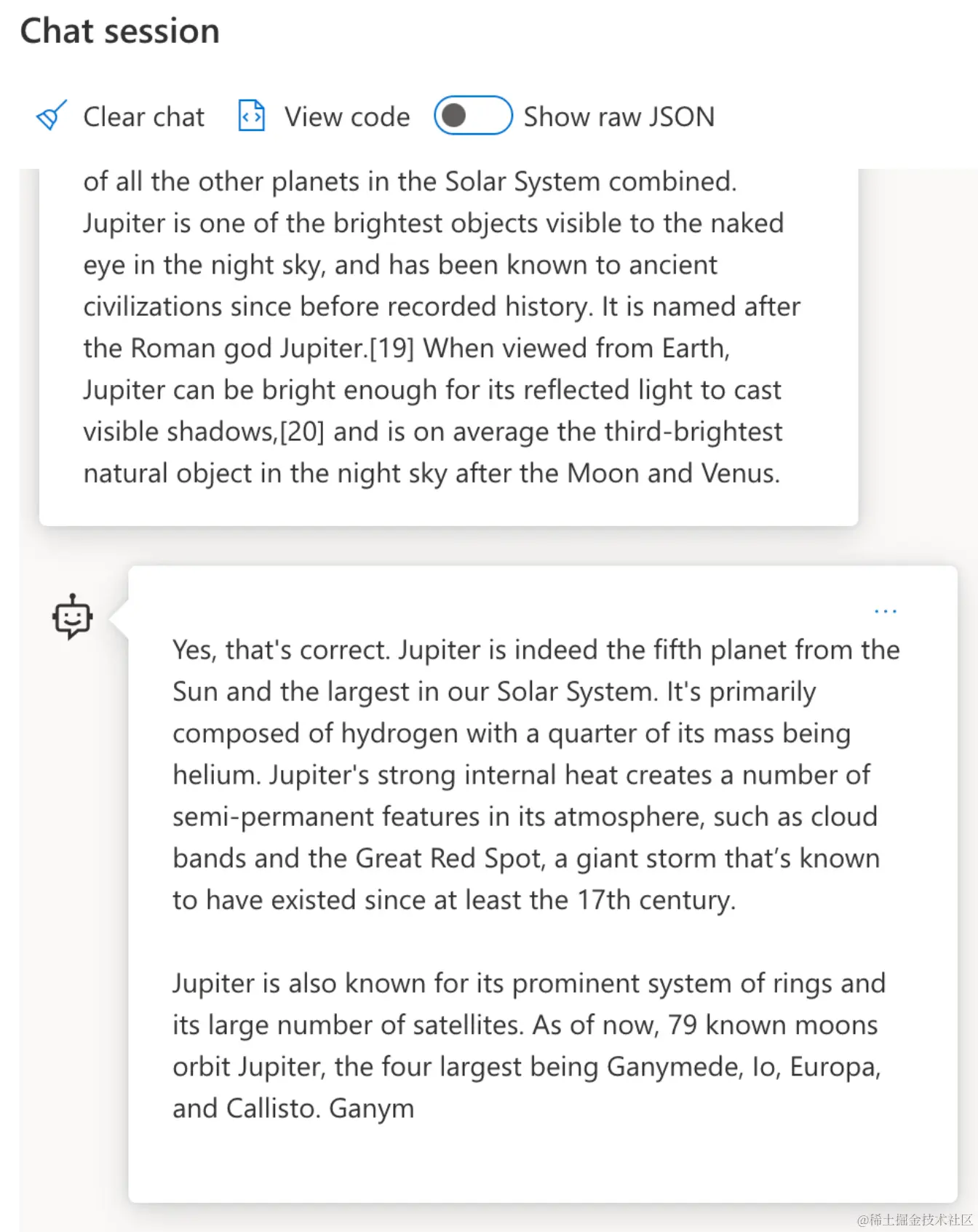
概念: LLMs 中的指令调整
LLMs 中的指令调整 从基础模型开始,并用以下参数对其进行微调 可以包含明确指令的例子或输入/输出对(比如多轮“消息”),以及人工智能试图遵循这个指令的回应。
它使用像人类反馈强化学习 (RLHF) 这样的技术,可以训练模型“遵循指令”并“从反馈中学习”,从而产生更适合实际应用和与用户目标更相关的回应。
让我们试试吧 – 重新访问上面的提示,但现在改变系统消息,提供以下指令作为上下文:

看看现在结果是如何调整的,以反映所需的目标和格式?教育工作者现在可以直接在这门课的 ppt 中使用这个结果。
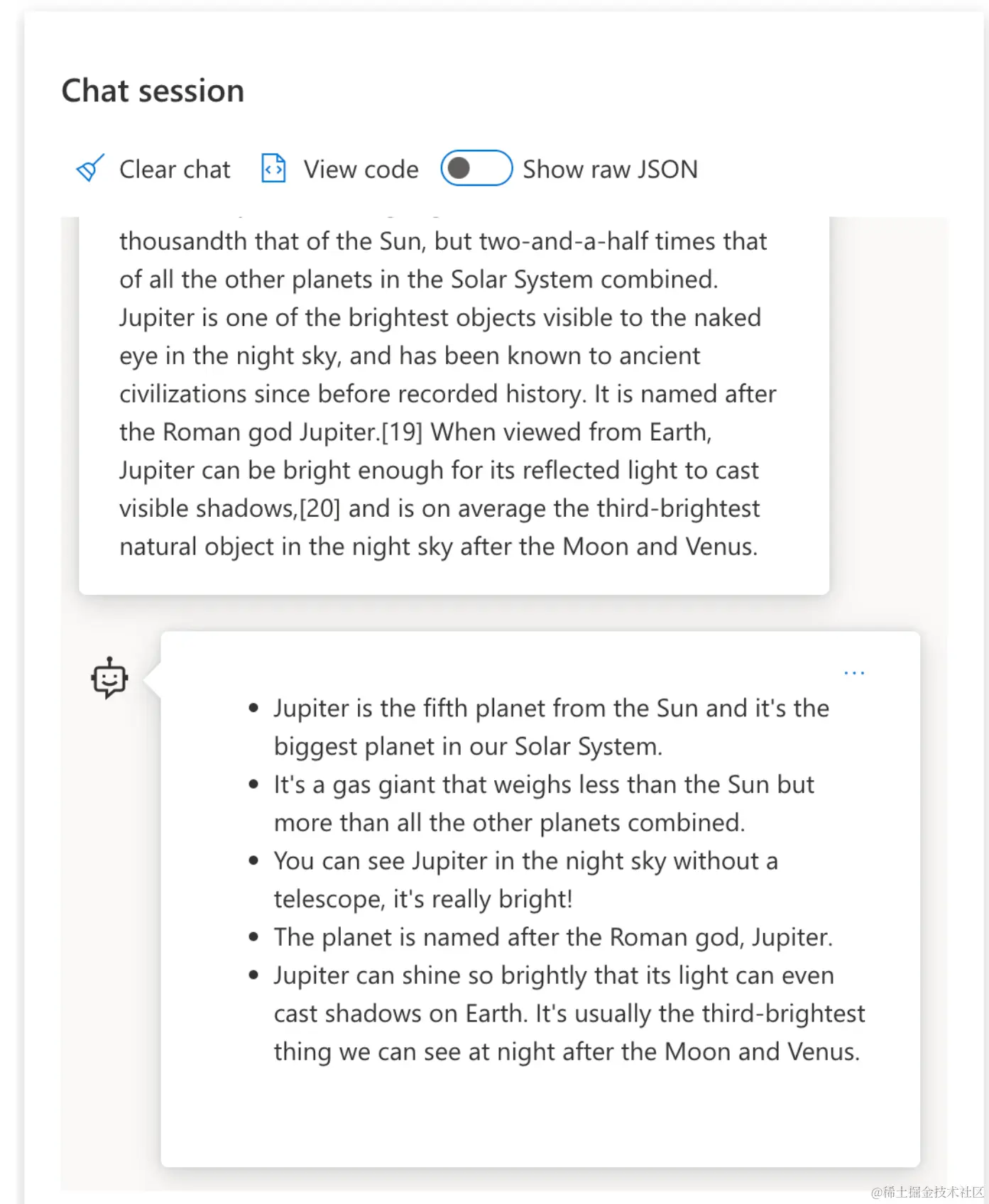
为什么我们需要提示工程
现在我们知道了 LLMs 是如何处理提示的,让我们谈谈为什么我们需要提示工程。答案在于,现在的 LLMs 的算法也有很多挑战,如果不及时优化,就很难实现“可靠和一致的补全”。比如:
模型的回应是随机的。 同样的提示可能会对不同的模型或模型版本产生不同的回应。甚至可能在不同的时间用同样的模型产生不同的结果。提示工程技术可以通过提供更好的提示来帮助我们尽量减少这些变化的影响。
模型可能会产生幻觉的回应。 模型是用大型但有限的数据集来预训练的,这意味着它们缺乏对训练范围之外的概念的知识。因此,它们可能会产生不正确、虚构或与已知事实直接冲突的完成结果。提示工程技术可以帮助用户识别和减轻幻觉,比如通过向人工智能询问来源或推理过程。
模型的功能不尽相同。 更新的模型或模型版本会有更多的功能,但也会有一些特殊的问题,以及成本和复杂性方面的权衡。提示工程可以帮助我们制定最佳实践和流程,以便以可扩展和无缝的方式消除差异并适应模型特定的需求。
让我们看看 OpenAI 或 Azure OpenAI Playground 中的实际情况:
- 用相同的提示对不同的 LLM 部署(例如 OpenAI、Azure OpenAI、Hugging Face)进行测试 – 你看到了什么差异?
- 用相同的提示对相同的 LLM 部署(例如 Azure OpenAI Playground)进行多次测试 – 生成的结果有什么不同?
构建提示的方法
我们已经了解了提示工程的重要性 – 现在让我们了解提示是如何构建的,以便我们可以评估不同的技术来实现更有效的提示设计。
基础提示
让我们从基础提示开始:发送到模型的文本输入,没有其他的上下文。这是一个例子 – 当我们把美国国歌的前几个单词发送到 OpenAI Completion API 时,它会立即生成下一个单词的回应 几行,说明了基本的预测行为。

复杂的提示
现在让我们给基础提示添加一些上下文和说明。Chat Completion API 让我们可以把复杂的提示构建成一组 messages 包括:
- 反映用户输入和助理回应的输入/输出对。
- 系统消息设置助理的行为或个性化。
这个请求现在采用以下的形式,其中标记化有效地从上下文和对话中捕获相关的信息。现在,改变系统的上下文对补全质量的影响和提供的用户输入一样。

指令式的提示
在上面的示例中,用户的提示是一个简单的文本查询,可以解释为信息请求。通过指令式的提示,我们可以用这个文本更详细地指定任务,从而给人工智能提供更好的指导。这是一个例子:

主要内容
在上面的示例中,提示还是比较开放的,让 LLMs 决定它们的预训练数据集的哪一部分是相关的。使用主要内容的设计模式,输入文本分成两部分:
- 指令(动作)
- 相关内容(影响回应)
下面是一个示例,其中的指令是“用 2 句话总结这一点”。

主要内容片段可以用多种方式来驱动更有效的指令:
- 示例 – 不要用明确的指令告诉模型要做什么,而是给它提供一些做什么的示例,并让它进行推断。
- 暗示 – 遵循带有“暗示”的说明,引导补全,引导模型做出更相关的回应。
- 模板 – 这些是带有占位符(变量)的提示的可重复的“配方”,可以用特定用例的数据来定制。
用例方式
这种方法中,你用主要内容来“给模型提供”一些给定指令所需输出的示例,并让它推断所需输出的模式。根据提供的示例的数量,我们可以有零样本提示、单样本提示、少样本提示等。
提示现在由三个部分组成:
- 任务描述
- 一些所需输出的示例
- 新示例的开始(成为隐式任务描述)

请注意,我们如何必须在零样本提示中提供明确的指令(“翻译成西班牙语”),但它是在单样本提示示例中推断出来的。这个少样本示例展示了如何添加更多的示例来让模型在不添加指令的情况下做出更准确的推断。
暗示提示
使用主要内容的另一种技术是提供暗示而不是示例。在这种情况下,我们通过使用反映所需回应格式的片段开始来让模型朝着正确的方向进行推理。然后,模型“接受提示”,继续按照这种思路进行。

提示模板
提示模板是预定义的提示配方,可以根据需要进行存储和重用,以大规模推动更一致的用户体验。最简单的形式是,它只是一组提示示例的集合,比如 OpenAI 中的这个例子,它提供了交互式提示组件(用户和系统消息)和 AP 驱动请求格式来支持重用。
在它更复杂的形式中,比如 LangChain 的这个例子,它包含占位符,可以替换为来自各种来源的数据(用户输入、系统上下文、外部数据源等)来动态生成提示。这使我们能够创建一个可重用的提示库,可用于大规模地以编程方式驱动一致的用户体验。
