
Langchain 可能是目前在 AI 领域中最热门的事物之一,仅次于向量数据库。

它是一个框架,用于在大型语言模型上开发应用程序,例如 GPT、LLama、Hugging Face 模型等。
它最初是一个 Python 包,但现在也有一个 TypeScript 版本,在功能上逐渐赶上,并且还有一个刚刚开始的 Ruby 版本。
为什么需要 Langchain?
但是,为什么首先需要它呢?我们是否可以简单地发送一个 API 请求或模型,然后就可以结束了?你是对的,对于简单的应用程序这样做是可行的。
但是,一旦您开始增加复杂性,比如将语言模型与您自己的数据(如 Google Analytics、Stripe、SQL、PDF、CSV 等)连接起来,或者使语言模型执行一些操作,比如发送电子邮件、搜索网络或在终端中运行代码,事情就会变得混乱和重复。

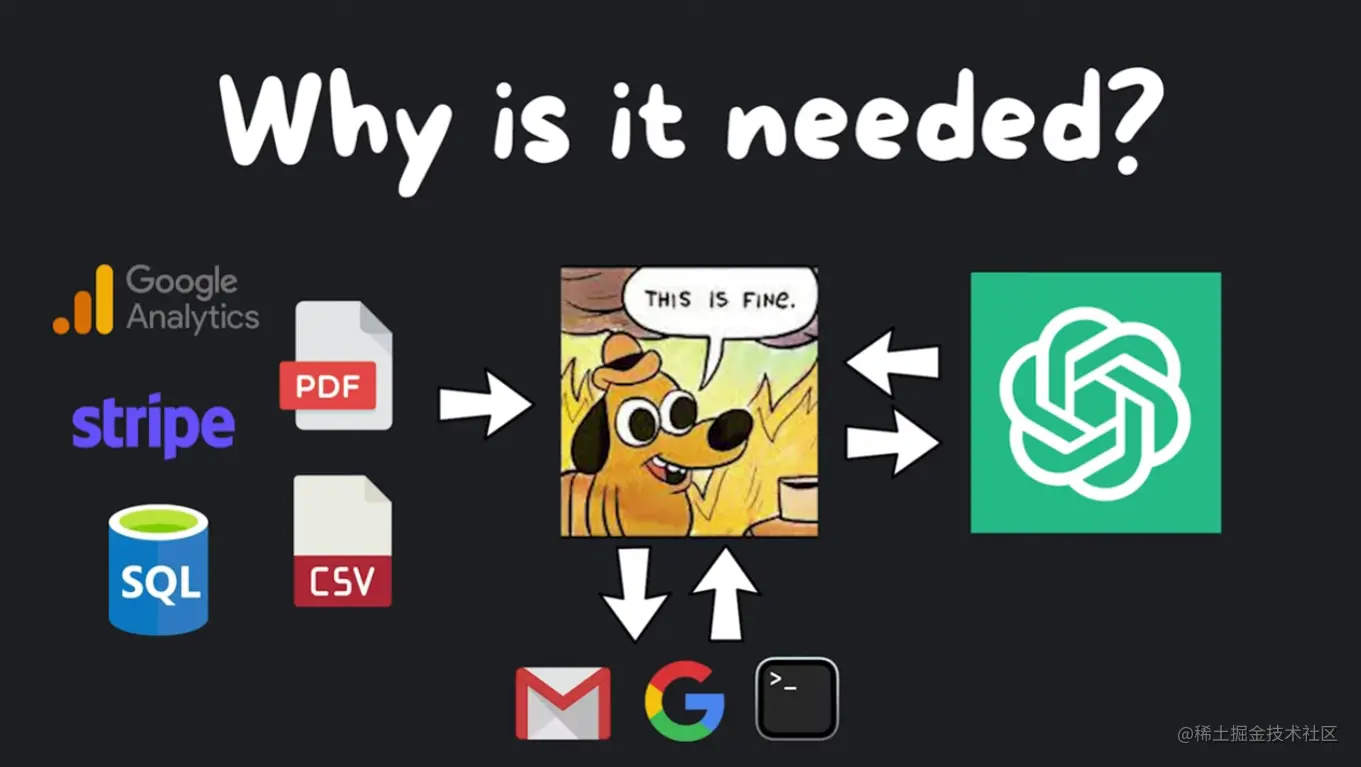

如果您对将语言模型与自己的数据和外部世界连接的强大之处感兴趣,可以查看与 LangChain 发布时间相近的研究论文,例如 Self-Ask、With Search 和 ReAct。
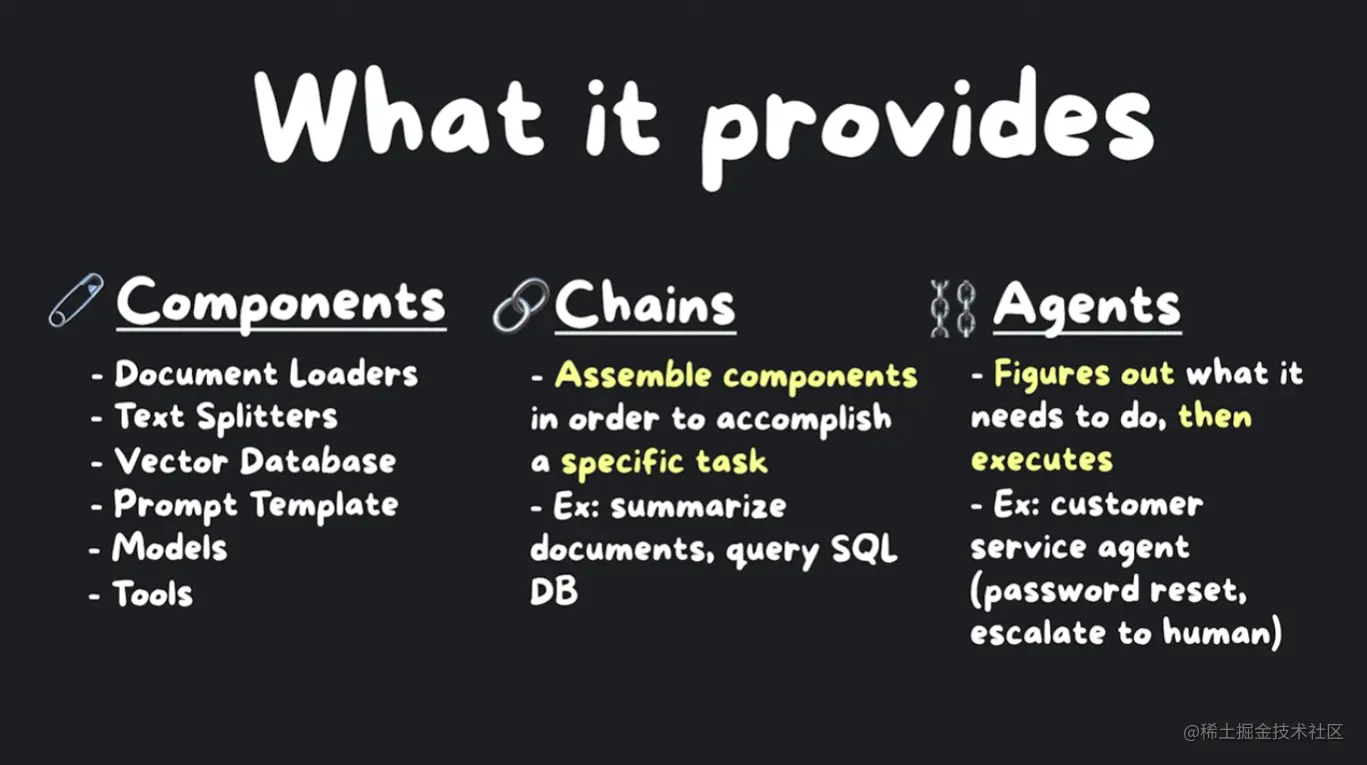
新手应该了解哪些模块?
现在让我们来看看幕后的真实情况。目前有七个模块在 LangChain 中提供,新手应该了解这些模块,包括模型(models)、提示(prompts)、索引(indexes)、内存(memory)、链(chains)和代理(agents)。
核心模块的概述
模型在高层次上有两种不同类型的模型:语言模型(language models)和文本嵌入模型(text embedding models)。嵌入模型将文本转换为数字数组,然后我们可以将文本视为向量空间。

例如,OpenAI 的文本嵌入模型可以精确地嵌入大段文本,具体而言,8100 个标记,根据它们的词对标记比例 0.75,大约可以处理 6143 个单词。它输出 1536 维的向量。

我们可以使用 LangChain 与多个嵌入提供者进行接口交互,例如 OpenAI 和 Cohere 的 API,但我们也可以通过使用 Hugging Faces 的开源嵌入在本地运行,以达到 免费和数据隐私 的目的。

LLMs 和 Chat Models
接下来是语言模型,它有两种不同的子类型:LLMs 和 Chat Models。LLMs 封装了接受文本输入并返回文本输出的 API,而 Chat Models 封装了接受聊天消息输入并返回聊天消息输出的模型。尽管它们之间存在细微差别,但使用它们的接口是相同的。我们可以导入这两个类,实例化它们,然后在这两个类上使用 predict 函数并观察它们之间的区别。但是,您可能不会直接将文本传递给模型,而是使用提示(prompts)。
提示(prompts)
提示(prompts)是指模型的输入。我们通常希望具有比硬编码的字符串更灵活的方式,LangChain 提供了 Prompt Template 类来构建使用多个值的提示。提示的重要概念包括提示模板、输出解析器、示例选择器和聊天提示模板。

提示模板(PromptTemplate)
提示模板是一个示例,首先需要创建一个 Prompt Template 对象。有两种方法可以做到这一点,一种是导入 Prompt Template,然后使用构造函数指定一个包含输入变量的数组,并将它们放在花括号中的模板字符串中。如果您感到麻烦,还可以使用模板的辅助方法,以便不必显式指定输入变量。
无论哪种情况,您都可以通过告诉它要替换占位符的值来格式化提示。
在内部,默认情况下它使用 F 字符串来格式化提示,但您也可以使用 Ginger 2。
但是,为什么不直接使用 F 字符串呢?提示提高了可读性,与其余生态系统很好地配合,并支持常见用例,如 Few Shot Learning 或输出解析。
Few Shot Learning 意味着我们给提示提供一些示例来指导其输出。

让我们看看如何做到这一点?首先,创建一个包含几个示例的列表。
python复制代码from langchain import PromptTemplate, FewShotPromptTemplate
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
]
然后,我们指定用于格式化提供的每个示例的模板。
python复制代码example_formatter_template = """Word: {word}
Antonym: {antonym}
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_formatter_template,
)
"""
最后,我们创建 Few Shot Prompt Template 对象,传入示例、示例格式化器、前缀、命令和后缀,这些都旨在指导 LLM 的输出。
此外,我们还可以提供输入变量 examples, example_prompt 和分隔符 example_separator="n",用于将示例与前缀 prefix 和后缀 suffix 分开。现在,我们可以生成一个提示,它看起来像这样。
python复制代码few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="Give the antonym of every inputn",
suffix="Word: {input}nAntonym: ",
input_variables=["input"],
example_separator="n",
)
print(few_shot_prompt.format(input="big"))
这是一种非常有用的范例,可以控制 LLM 的输出并引导其响应。
输出解析器(output_parsers)
类似地,我们可能想要使用输出解析器,它会自动将语言模型的输出解析为对象。这需要更复杂一些,但非常有用,可以将 LLM 的随机输出结构化。
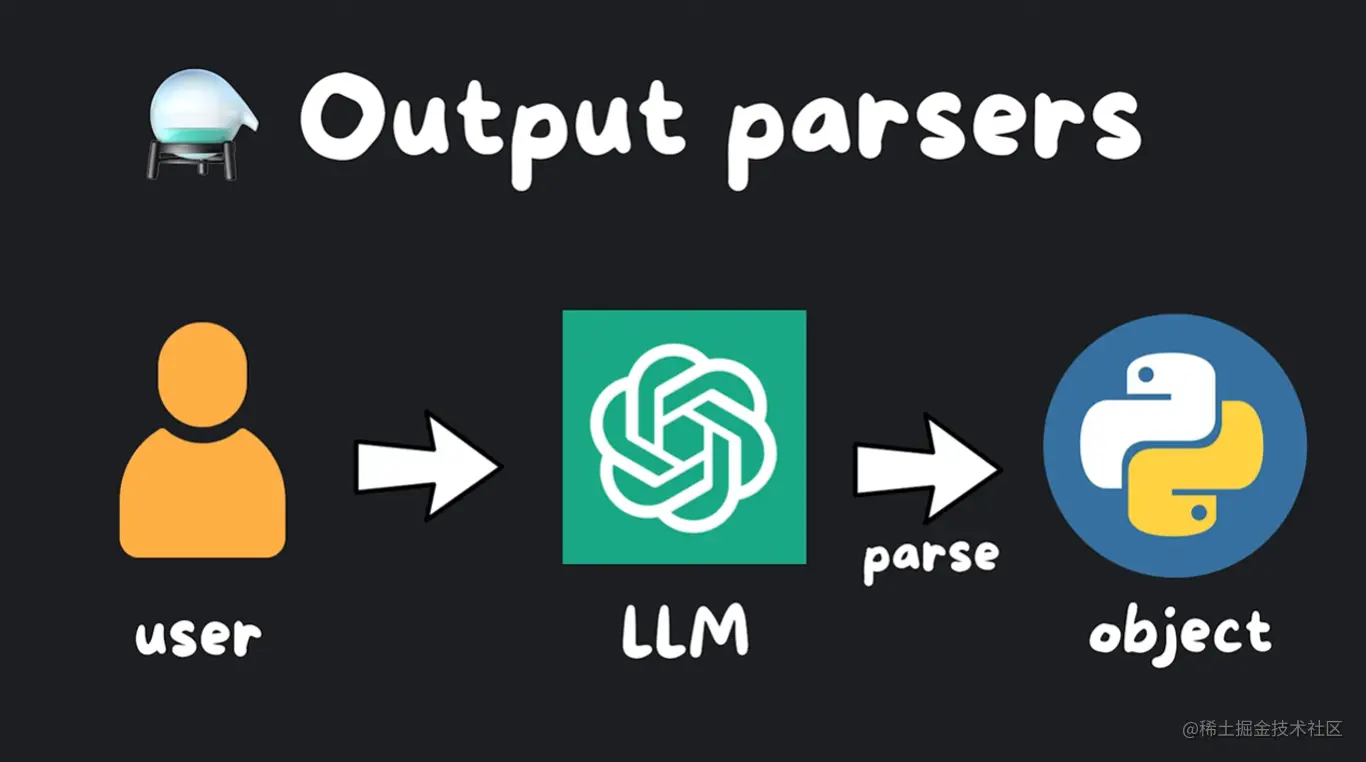
假设我们想要使用 OpenAI 创建笑话对象,我们可以定义我们的 Joke 类以更具体地说明笑话的设置和结尾。我们添加描述以帮助语言模型理解它们的含义,然后我们可以设置一个解析器,告诉它使用我们的 Joke 类进行解析。
我们使用最强大且推荐的 Pydantic 输出解析器,然后创建我们的提示模板。
python复制代码from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
parser = PydanticOutputParser(pydantic_object=Joke)
让我们传递模板字符串和输入变量,并使用部分变量字段将解析指令注入到提示模板中。然后,我们可以要求 LLM 给我们讲一个笑话。
现在,我们已经准备好发送它给 OpenAI 的操作是这样的:首先从我们的.env 文件中加载 OpenAI 的 API 密钥,然后实例化模型,调用其调用方法,并使用我们实例化的解析器解析模型的输出。
python复制代码from langchain.llms import OpenAI
from dotenv import load_dotenv
load_dotenv()
model = OpenAI(model_name="text-davinci-003", temperature=0.0)
然后,我们就拥有了我们定义了设置和结尾的笑话对象。生成的提示非常复杂,建议查看 GitHub 以了解更多信息。
python复制代码prompt = PromptTemplate(
template="Answer the user query.n{format_instructions}n{query}n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
joke_query = "Tell me a joke."
formatted_prompt = prompt.format_prompt(query=joke_query)
print(formatted_prompt.to_string())
打印的结果是:
text复制代码Answer the user query. The output should be formatted as a JSON instance that conforms to the JSON schema below. As an example, for the schema { "properties": { "foo": { "title": "Foo", "description": "a list of strings", "type": "array", "items": { "type": "string" } } }, "required": [ "foo" ] } the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted. Here is the output schema:
{ “properties”: { “setup”: { “title”: “Setup”, “description”: “question to set up a joke”, “type”: “string” }, “punchline”: { “title”: “Punchline”, “description”: “answer to resolve the joke”, “type”: “string” } }, “required”: [ “setup”, “punchline” ] }
vbnet复制代码Tell me a joke.
"""
我们给 model 传入 prompt 模板,并且用输出解析器解析结果:
python复制代码output = model(formatted_prompt.to_string())
parsed_joke = parser.parse(output)
print(parsed_joke)
我们之前讲过 Few Shot Prompt 学习,我们传递一些示例来显示模型对某种类型的查询的预期答案。我们可能有许多这样的示例,我们不可能全部适应它们。而且,这可能很快就会变得非常昂贵。这就是示例选择器发挥作用的地方。
示例选择器(example_selector)
为了保持提示的成本相对恒定,我们将使用基于长度的示例选择器 LengthBasedExampleSelector。就像以前一样,我们指定一个示例提示。这定义了每个示例将如何格式化。我们策展一个选择器,传入示例,然后是最大长度。
默认情况下,长度指的是格式化器示例部分的提示使用的单词和新行的数量 max_length。
python复制代码from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
{"word": "energetic", "antonym": "lethargic"},
{"word": "sunny", "antonym": "gloomy"},
{"word": "windy", "antonym": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template="Word: {word}nAntonym: {antonym}",
)
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25,
)
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Word: {adjective}nAntonym:",
input_variables=["adjective"],
)
print(dynamic_prompt.format(adjective="big"))
那么,与聊天模型互动如何呢?这就引出了我们之前提到的聊天提示模板。聊天模型以聊天消息列表为输入。这个列表被称为提示。
它们的不同之处在于,每条消息都被预先附加了一个角色,要么是 AI,要么是人类,要么是系统。模型应紧密遵循系统消息的指示。一开始只有一个系统消息,有时它可能听起来相当催眠。
“你是一个善良的客服代理人,对客户的问题做出逐渐的回应”……
类似于这样,告诉聊天机器人如何行事。AI 消息是来自模型的消息,人类消息是我们输入的内容。角色为 LLM 提供了对进行中的对话的更好的上下文。
模型和提示都很酷,标准化了。
索引(indexes)
但我们如何使用我们自己的数据呢?这就是索引模块派上用场的地方。
数据就是新的石油,你肯定可以在任何地方挖掘,并找到大量的。
Langchain 提供了钻机,通过提供文档加载器,文档是他们说的文本的花哨方式。有很多支持的格式和服务,比如 CSV、电子邮件、SQL、Discord、AWS S3、PDF,等等。它只需要三行代码就可以导入你的。这就是它有多简单!
首先导入加载器,然后指定文件路径,然后调用 load 方法。这将在内存中以文本形式加载 PDF,作为一个数组,其中每个索引代表一个页面。

文本分割器 (text_splitter)

这很好,但是当我们想构建一个提示并包含这些页面中的文本时,它们可能太大,无法在我们之前谈过的输入令牌大小内适应,这就是为什么我们想使用文本分割器将它们切成块。
读完文本后,我们可以实例化一个递归字符文本分割器 RecursiveCharacterTextSplitter,并指定一个块大小和一个块重叠。我们调用 create_documents 方法,并将我们的文本作为参数。
然后我们得到了一个文档的数组。
python复制代码from langchain.text_splitter import RecursiveCharacterTextSplitter
with open("example_data/state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
)
texts = text_splitter.create_documents([state_of_the_union])
print(f"nFirst chunk: {texts[0]}n")
print(f"Second chunk: {texts[1]}n")
现在我们有了文本块,我们会想要嵌入它们并存储它们,以便最终使用语义搜索检索它们,这就是为什么我们有向量存储。
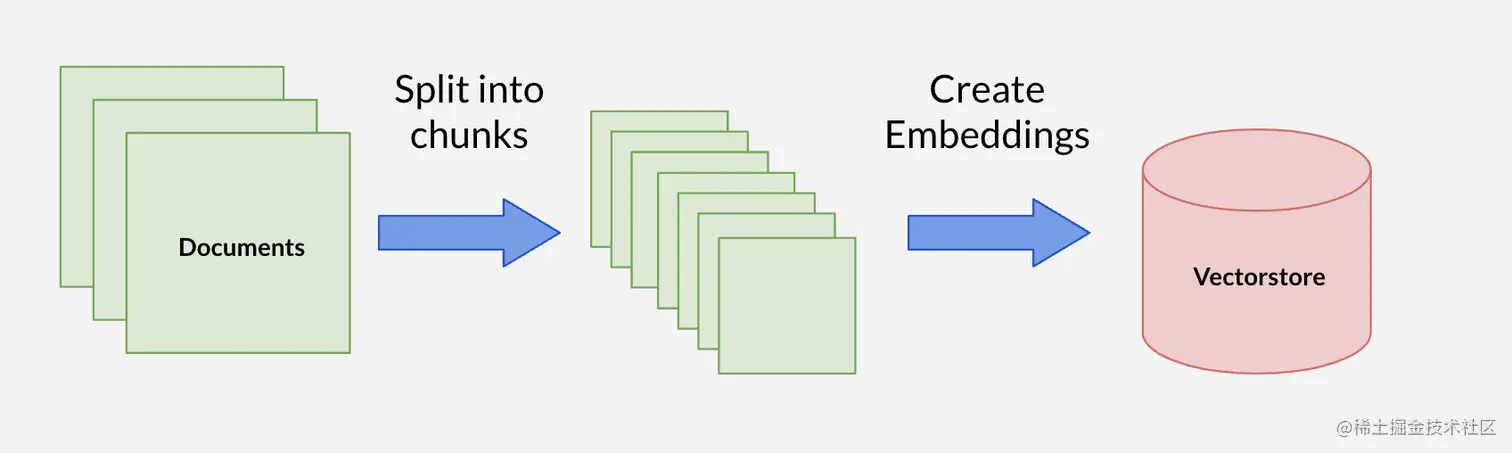
与向量数据库的集成
索引模块的这一部分提供了多个与向量数据库的集成,如 pinecone、redis、Super Bass、chroma DB 等等。
向量空间中进行搜索
一旦你准备好了你的文档,你就会想选择你的嵌入提供商,并使用向量数据库助手方法存储文档。
现在我们可以写一个问题,在向量空间中进行搜索,找出最相似的结果 similarity_search,返回它们的文本。
python复制代码from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
with open("example_data/state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
)
texts = text_splitter.create_documents([state_of_the_union])
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
docs = docsearch.similarity_search(query)
print(docs[0].page_content)
从构建提示到索引文档,再到在向量空间中进行搜索,都可以通过导入一个模块并运行几行代码来完成。

希望你喜欢这个旅程,让我们开始我们的聊天机器人之旅吧!
如果你有任何问题或想要查看更详细的实例,你可以在加入社群提问。我期待着你的反馈和你在社区中分享的任何创新。
🔗 Links
Source code: github.com/edrickdch/l…
LangChain: python.langchain.com.cn
Self-Ask Paper: ofir.io/self-ask.pd…
ReAct Paper: arxiv.org/abs/2210.03…
