

openai提供两种对话方式,一种是使用现成的模型,例如gpt-3.5-turbo、gpt-4,另一种就是在现有的基础上,通过投喂数据集来训练自己的模型,也就是Fine-tuning,微调OpenAI文本生成模型可以使它们在特定应用场景中更好地发挥作用,但需要投入时间和精力。
一些常见的微调可以改善结果的用例包括:
- 设置风格、语气、格式或其他定性方面
- 提高生成期望输出的可靠性
- 以特定方式处理许多边缘情况
- 执行难以用提示清楚表达的新技能或任务 本人是期望能够用AI代替人工客服,所以尝试了一下openai的微调模型,本职前端,文章中部分直接翻译的官网文档,其余话术仅供参考,不是专业人士,所以如果有什么概念或者术语说错了的欢迎指正。
准备数据集
“需要创建一组多样化的演示对话,这些对话类似于要求模型在生产中的推理时响应的对话。”
json复制代码{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
“要微调模型,您需要提供至少 10 个示例。我们通常会看到对 50 到 100 个训练示例进行微调会带来明显的改进,但正确的数量根据具体的用例而有很大差异。”
训练模型时需要上传两个.jsonl文件,一个训练集和一个校验集,其中训练集用于训练模型,验证集用于评估模型的性能和调整超参数。校验集数据条数一般是训练集的10%-30%。建议一开始就多准备一些数据,并把数据都清理一下,避免影响最后的结果。
校验
校验每条数据中的token数不超过限制,token数量的限制取决于您选择的型号。对于gpt-3.5-turbo-0125,最大上下文长度为 16,385,因此每个训练示例也限制为 16,385 个token。超过的部分会直接被截取。
附token校验、计数和计费的脚本:token_conter.py
python复制代码import json
import tiktoken
import numpy as np
from collections import defaultdict
# 从 jsonl 文件中读取消息列表
def read_messages_from_jsonl(jsonl_file):
messages = []
with open(jsonl_file, 'r', encoding='utf-8') as f:
for line in f:
message = json.loads(line.strip())
messages.append(message)
return messages
# 读取你的 jsonl 文件并将其转换为消息列表
jsonl_file = './Training.jsonl' # 修改为你的 jsonl 文件路径
dataset = read_messages_from_jsonl(jsonl_file)
# Format error checks
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
if not content or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")
# Token counting functions
encoding = tiktoken.get_encoding("cl100k_base")
# not exact!
# simplified from https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens
def num_assistant_tokens_from_messages(messages):
num_tokens = 0
for message in messages:
if message["role"] == "assistant":
num_tokens += len(encoding.encode(message["content"]))
return num_tokens
def print_distribution(values, name):
print(f"n#### Distribution of {name}:")
print(f"min / max: {min(values)}, {max(values)}")
print(f"mean / median: {np.mean(values)}, {np.median(values)}")
print(f"p5 / p95: {np.quantile(values, 0.1)}, {np.quantile(values, 0.9)}")
# Warnings and tokens counts
n_missing_system = 0
n_missing_user = 0
n_messages = []
convo_lens = []
assistant_message_lens = []
for ex in dataset:
messages = ex["messages"]
if not any(message["role"] == "system" for message in messages):
n_missing_system += 1
if not any(message["role"] == "user" for message in messages):
n_missing_user += 1
n_messages.append(len(messages))
convo_lens.append(num_tokens_from_messages(messages))
assistant_message_lens.append(num_assistant_tokens_from_messages(messages))
print("Num examples missing system message:", n_missing_system)
print("Num examples missing user message:", n_missing_user)
print_distribution(n_messages, "num_messages_per_example")
print_distribution(convo_lens, "num_total_tokens_per_example")
print_distribution(assistant_message_lens, "num_assistant_tokens_per_example")
n_too_long = sum(l > 4096 for l in convo_lens)
print(f"n{n_too_long} examples may be over the 4096 token limit, they will be truncated during fine-tuning")
# Pricing and default n_epochs estimate
MAX_TOKENS_PER_EXAMPLE = 4096
TARGET_EPOCHS = 3
MIN_TARGET_EXAMPLES = 100
MAX_TARGET_EXAMPLES = 25000
MIN_DEFAULT_EPOCHS = 1
MAX_DEFAULT_EPOCHS = 25
n_epochs = TARGET_EPOCHS
n_train_examples = len(dataset)
if n_train_examples * TARGET_EPOCHS < MIN_TARGET_EXAMPLES:
n_epochs = min(MAX_DEFAULT_EPOCHS, MIN_TARGET_EXAMPLES // n_train_examples)
elif n_train_examples * TARGET_EPOCHS > MAX_TARGET_EXAMPLES:
n_epochs = max(MIN_DEFAULT_EPOCHS, MAX_TARGET_EXAMPLES // n_train_examples)
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in convo_lens)
print(f"Dataset has ~{n_billing_tokens_in_dataset} tokens that will be charged for during training")
print(f"By default, you'll train for {n_epochs} epochs on this dataset")
print(f"By default, you'll be charged for ~{n_epochs * n_billing_tokens_in_dataset} tokens")
print("See pricing page to estimate total costs")
# base cost per 1k tokens * number of tokens in the input file * number of epochs trained
def calculate_price_per_epoch(token_price_per_k, num_tokens, num_epochs):
# 计算每个 epoch 的价格
price_per_epoch = token_price_per_k * (num_tokens / 1000) * num_epochs
return price_per_epoch
# Token 价格(每个 token)
token_dollar_per_k = 0.0080 # $0.0080 / 1K tokens
# 计算总价格
total_dollar = calculate_price_per_epoch(token_dollar_per_k, n_billing_tokens_in_dataset, n_epochs)
print(f"Total price: $~{total_dollar}")
运行效果:

开始训练
可以使用图形化训练或者用代码创建,这里我选择了图形化训练
1.上传数据集
可以提前上传,也可以在创建训练任务时上传
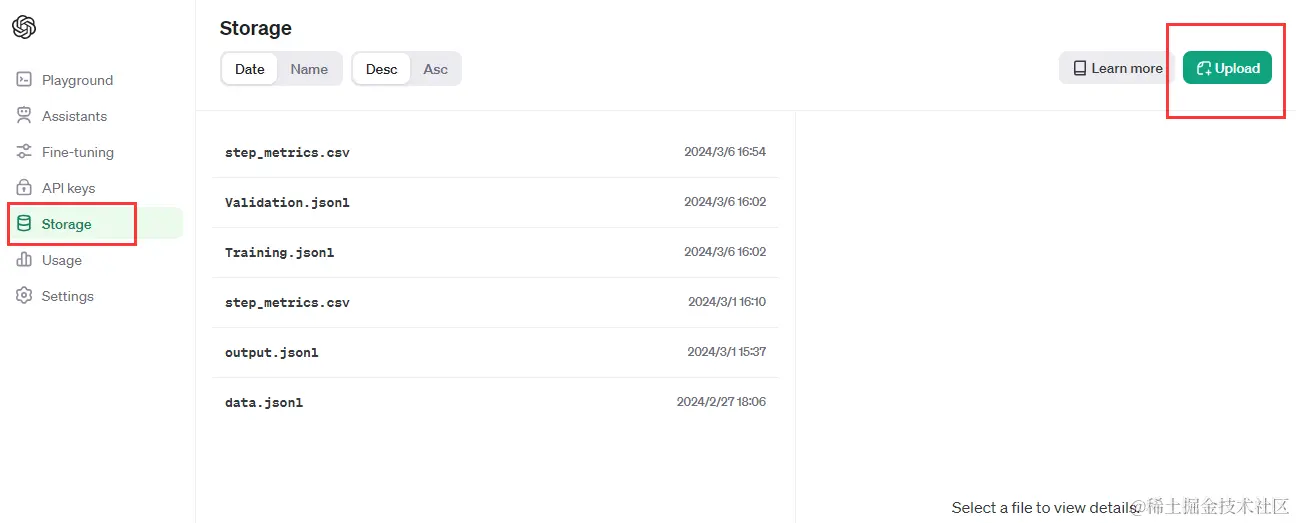
2.创建训练任务
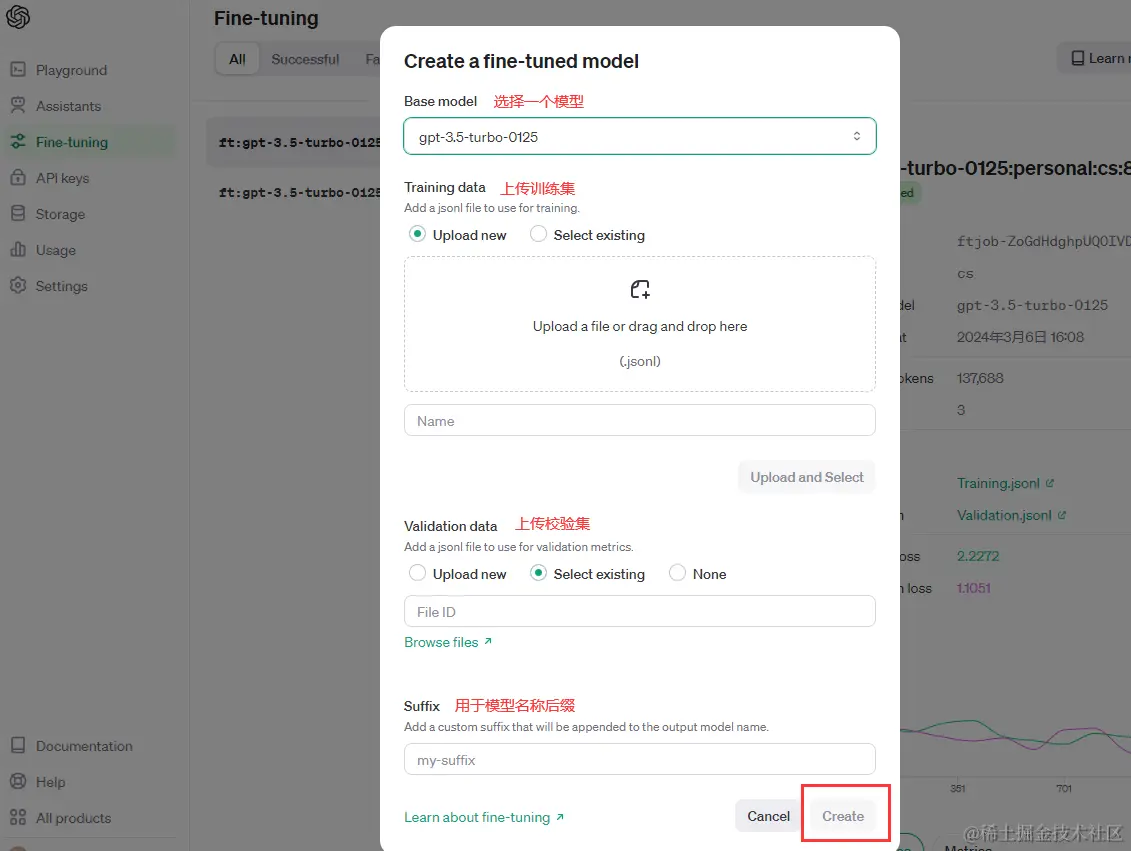
运行
中途忘截图了,需要等模型跑一会
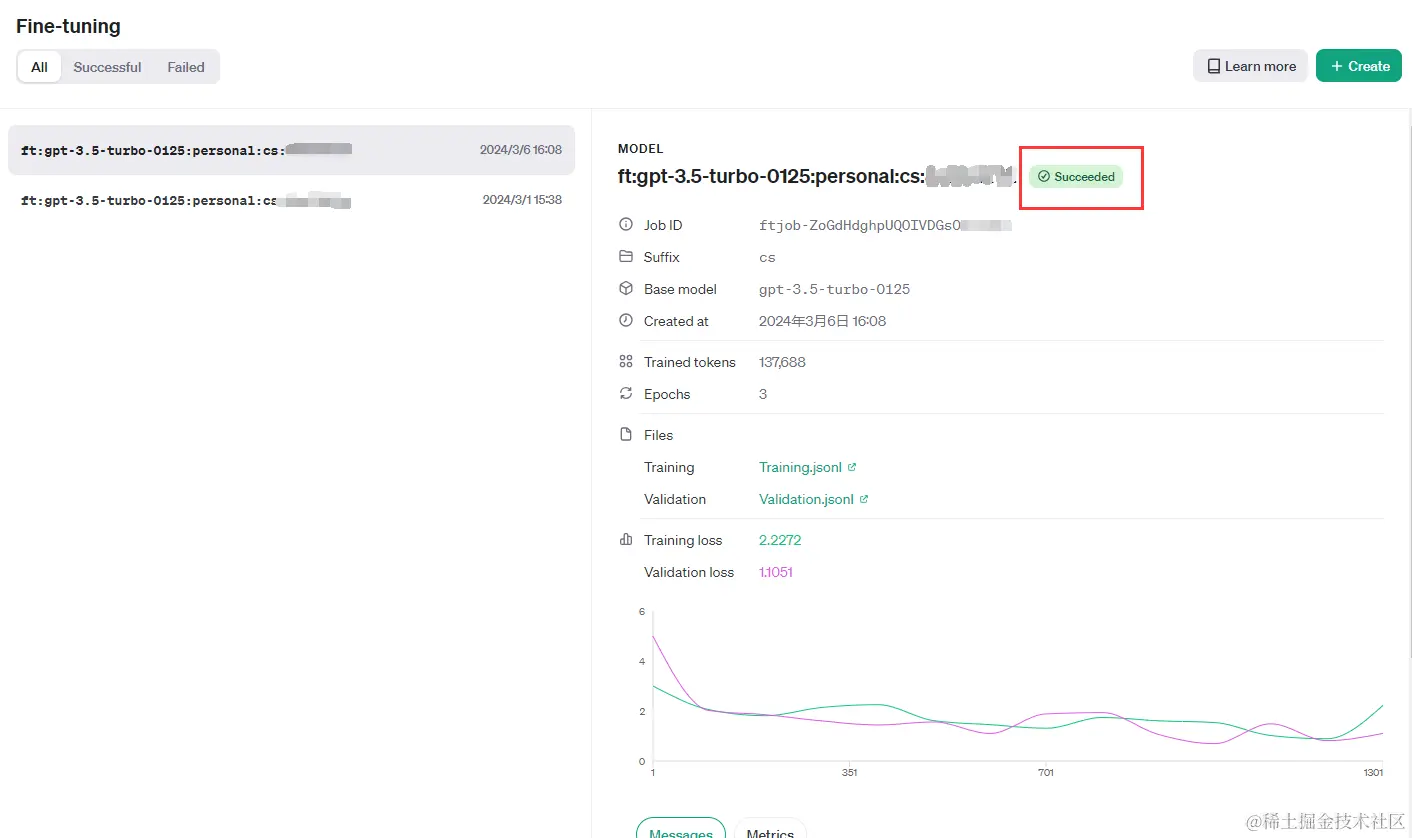
成功之后就可以试用了
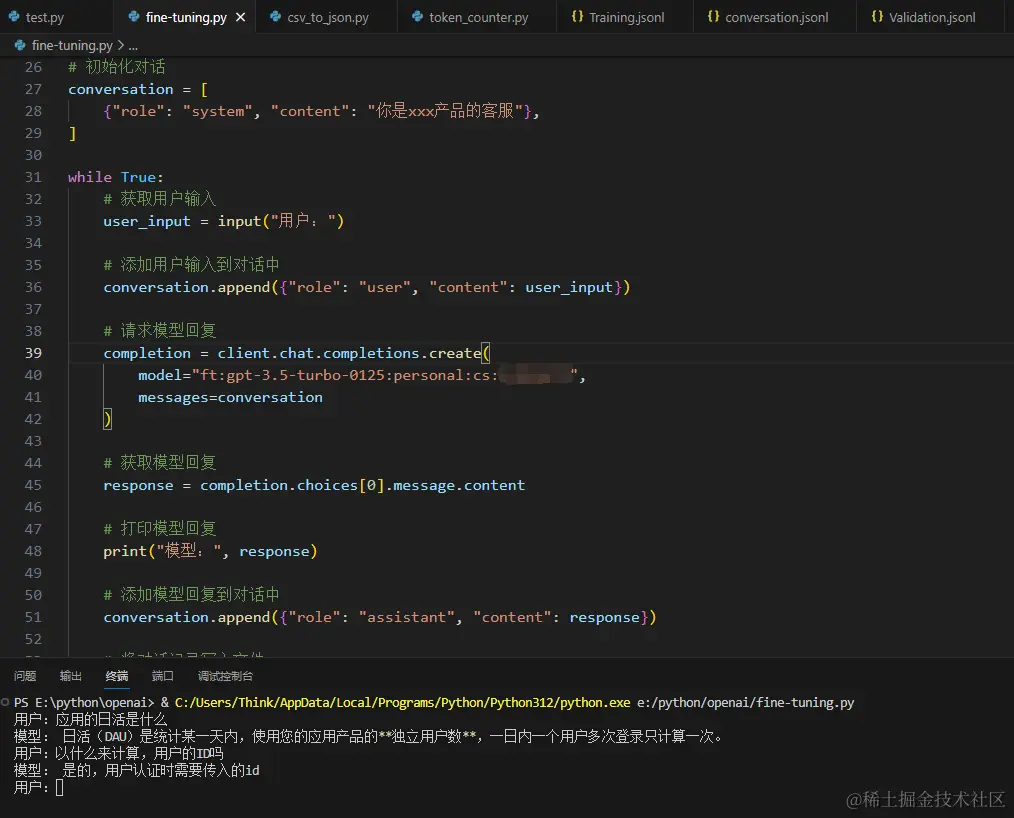
附:fine-turning.py
python复制代码from openai import OpenAI
import json
client = OpenAI()
# 创建
# client.fine_tuning.jobs.create(
# training_file="file-krCDQKRmCzcYxiOAMxef69nK",
# model="gpt-3.5-turbo",
# hyperparameters={
# "n_epochs":3
# }
# )
import openai
# 初始化对话
conversation = [
{"role": "system", "content": "xxx"},
]
while True:
# 获取用户输入
user_input = input("用户:")
# 添加用户输入到对话中
conversation.append({"role": "user", "content": user_input})
# 请求模型回复
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:xxx:xx:xxx", # 训练成功后的模型名称
messages=conversation
)
# 获取模型回复
response = completion.choices[0].message.content
# 打印模型回复
print("模型:", response)
# 添加模型回复到对话中
conversation.append({"role": "assistant", "content": response})
运行效果:
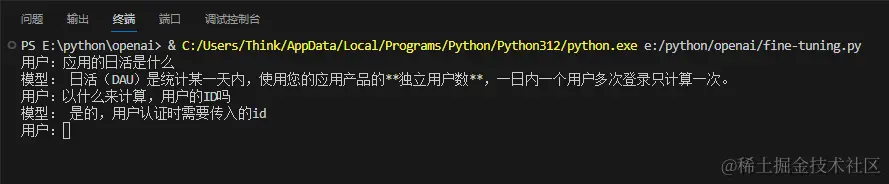
结尾
搞了两次感觉效果不是很理想,Training loss两次都很高,第一次以为是数据集给得太少了,200多条数据,且没有上传校验集,第二次增加了三倍,校验集也准备了,依旧很高,可能这种微调模型不太适用于我的使用场景(中文、客服)
