

我们已经将文档分割成了更小的、且语义明确的块,接下来要做的就是将这些块放入到一个索引中,这样当我们要回答某个数据集相关的问题时,就能轻松地检索到对应的块。
要实现这一目标,我们需要用到两个技术:嵌入(Embedding)和向量存储(Vector Store)。
我们在前面的课程里已经介绍过这两个技术,这里先只做简单的复习。
向量存储和嵌入

嵌入是将一段文本转化为数值形式。具有相似内容的文本在数值空间中会有相似的向量,这就意味着我们可以通过比较这些向量,来找出相似的文本片段。
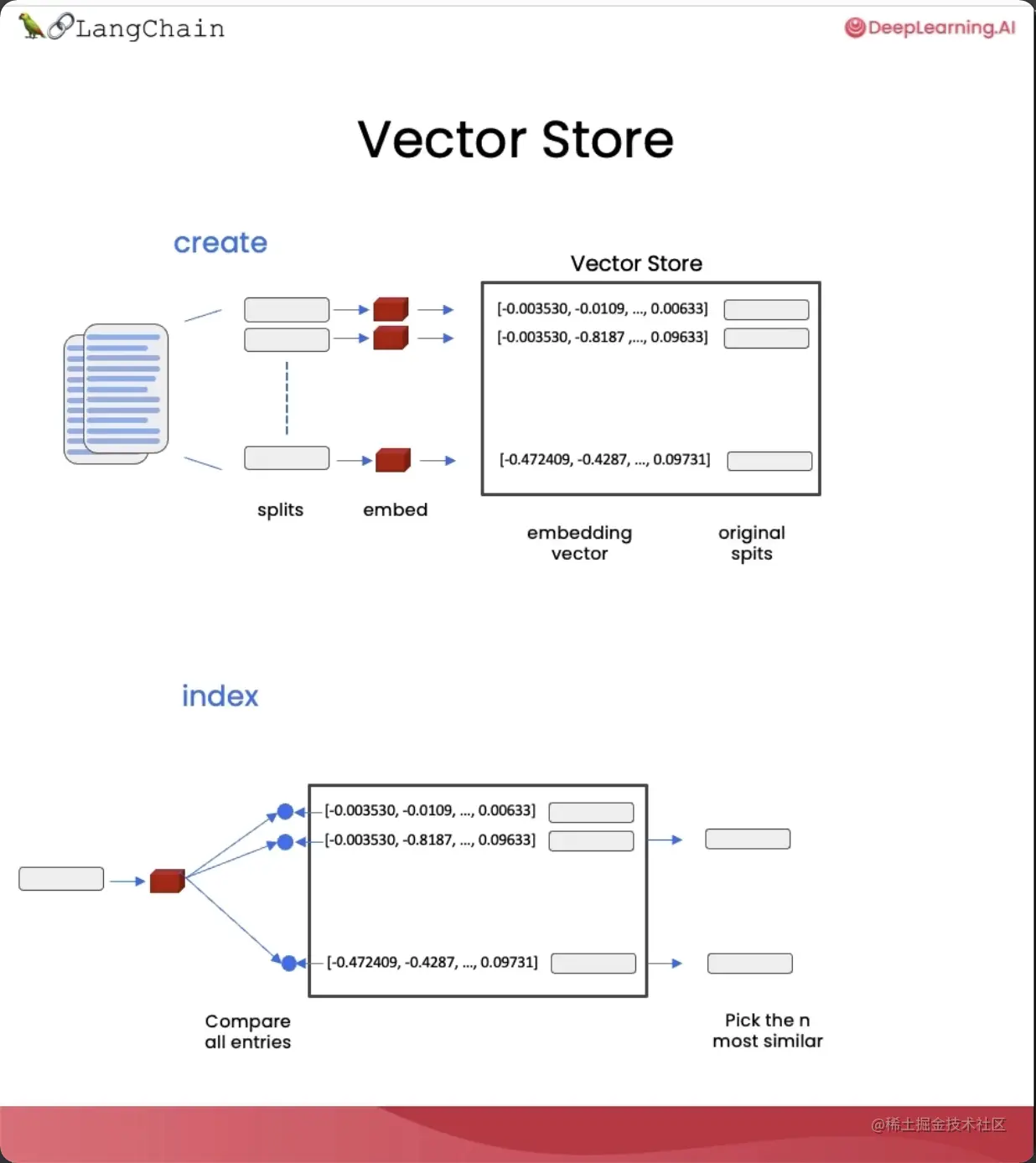
而向量存储是一种数据库,它用来存储分割后的文档片段以及它们对应的嵌入,方便我们后续根据问题查找相关的文档。
整个过程如下:
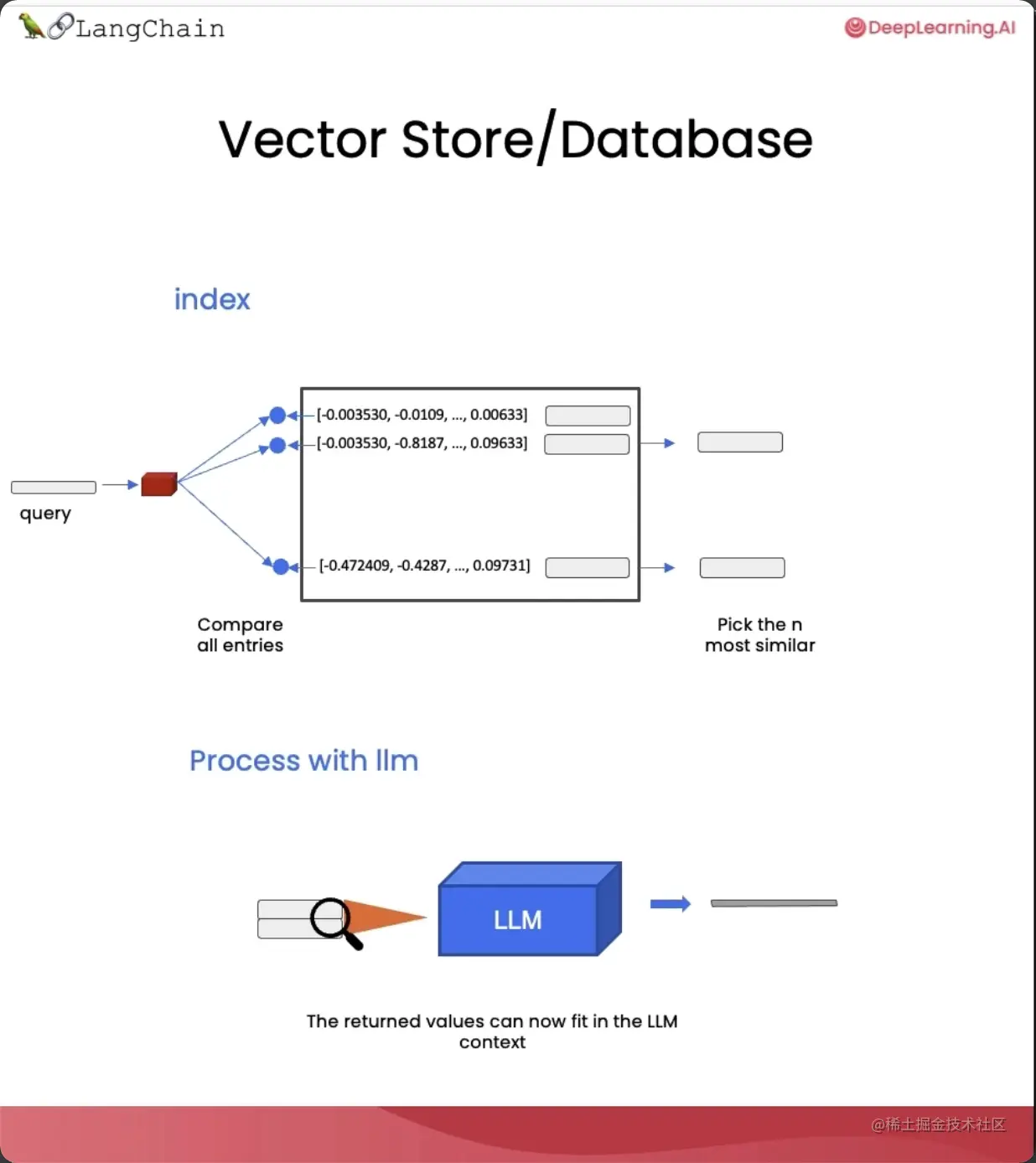
- 提出一个问题,并为它生成一个嵌入;
- 将它跟向量存储里的所有不同的向量进行比较;
- 选出最相似的前n个片段;
- 将选出的片段和问题一起输入到LLM里,得到一个答案。
为了帮助理解,我们先看一个简单的例子:
步骤1:提供一些例句,其中前两句非常相似,第三句则与前两句关联不大
ini复制代码sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"
步骤2:使用Embbeding类为每个句子生成一个嵌入
ini复制代码from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)
步骤3:用点积(dot product)来计算两两之间的嵌入相似度
python复制代码import numpy as np
np.dot(embedding1, embedding2)
# 0.9631853877103518
np.dot(embedding1, embedding3)
# 0.7709997651294672
np.dot(embedding2, embedding3)
# 0.7596334120325523
点积的值越大,代表相似度就越高。
再来看一个实际的例子:
目标是为提供的所有PDF文档生成嵌入,并把它们存储在一个向量存储里。
步骤1:加载PDF文档
ini复制代码from langchain.document_loaders import PyPDFLoader
# 加载 PDF
loaders = [
# 重复加载第一个文档,模拟一些脏数据
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:
docs.extend(loader.load())
步骤2:用递归字符文本分割器来把文档分成块
ini复制代码# 分割
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
步骤3:为每个块生成嵌入,并创建Chroma向量存储
这里用到的向量存储是Chroma。Chroma是一种轻量级、基于内存的向量存储,使用起来很方便。
ini复制代码from langchain.vectorstores import Chroma
# 可先用[rm -rf ./docs/chroma]移除可能存在的旧数据库数据
persist_directory = 'docs/chroma/'
# 传入之前创建的分割和嵌入,以及持久化目录
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory
)
步骤4:用相似性搜索方法来查找文档
ini复制代码question = "is there an email i can ask for help"
# K=3用于指定返回的文档数量
docs = vectordb.similarity_search(question,k=3)
可以打印文档的长度和内容来检查:
scss复制代码len(docs)
# 3
docs[0].page_content

步骤5:持久化向量数据库,以便以后使用
scss复制代码vectordb.persist()
接下来我们将讨论一些边缘案例,展示几种可能出现失败情况:
失败情况1:重复的块导致重复的冗余信息
ini复制代码question = "what did they say about matlab?"
docs = vectordb.similarity_search(question,k=5)
docs[0]
docs[1]
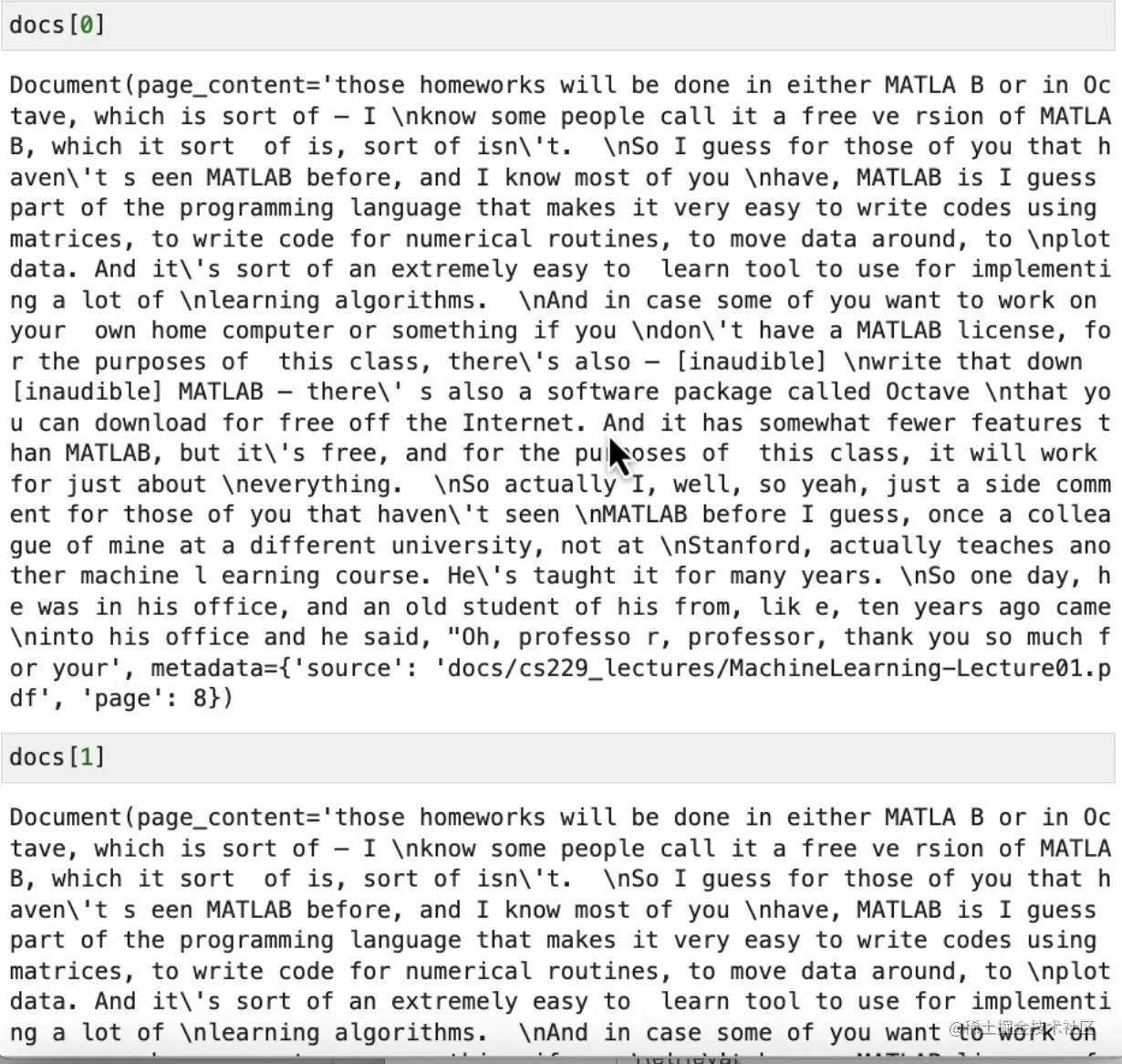
其中,docs[0] 和 docs[1] 得到的结果是相同的,这是因为我们在一开始就有意重复加载了第一个文档。
这样做的结果是,我们把两个内容相同的分块都传给了语言模型。而第二个分块是没有价值的,如果换成一个内容不同的分块会更好,这样至少语言模型可以从中获取更多信息。
在下一课中,我们将讨论如何在保证检索到相关的块的同时,也能保证每个块都是唯一的。
失败情况2:无法完整捕捉到问题中的关键信息
比如下面这个问题,“第三堂课里他们讲了什么关于回归的内容?”
ini复制代码question = "what did they say about regression in the third lecture?"
docs = vectordb.similarity_search(question,k=5)
一般来说,我们应该能看出,问题的提问者是想要从第三堂课里找到答案的。
但实际上,当我们遍历所有文档,并打印出元数据后会发现,结果里实际上混合了多个文档的内容。
shell复制代码for doc in docs:
print(doc.metadata)
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 0}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 14}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture02.pdf', 'page': 0}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 6}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf', 'page': 8}
这是因为,我们只是基于嵌入做了一个语义搜索,它为整个句子生成了一个嵌入,并且可能会更关注于“回归”这个词。
当我们查看第五个文档时,就会发现它确实提到了“回归”这个词。
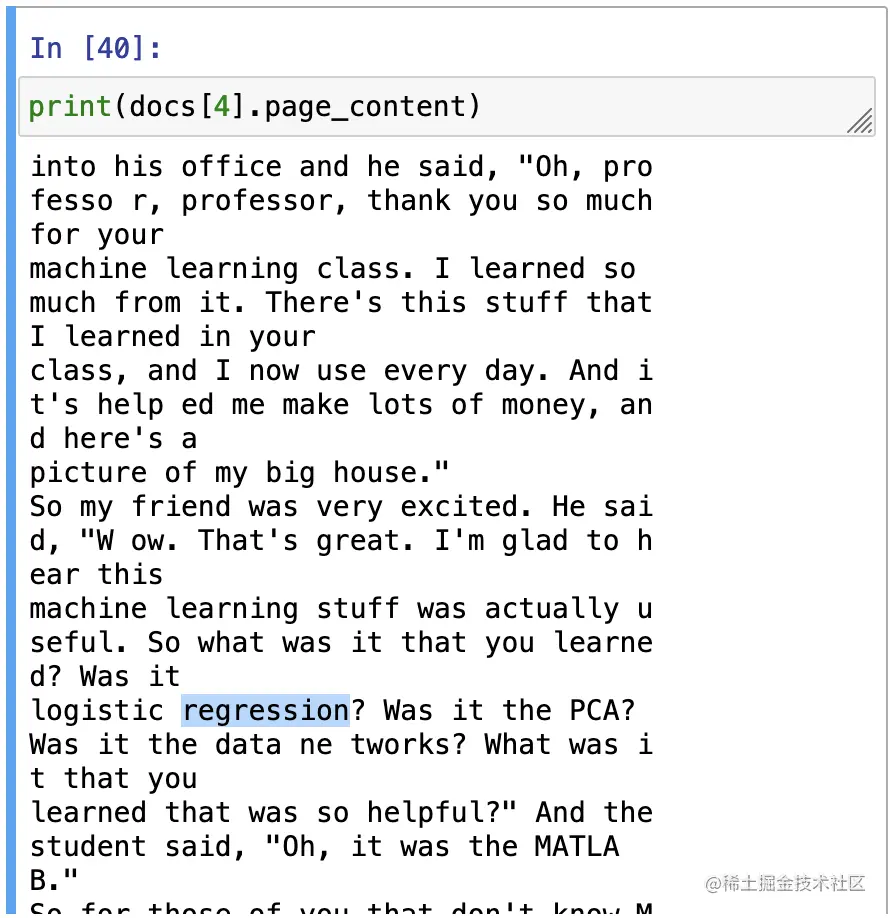
失败情况3:随着检索文档数量的增加,相关性逐渐降低
当我们尝试改变k值,也就是检索的文档数量时,我们会得到更多的文档,但结果列表后面的文档可能没有前面的那些相关性强。
检索
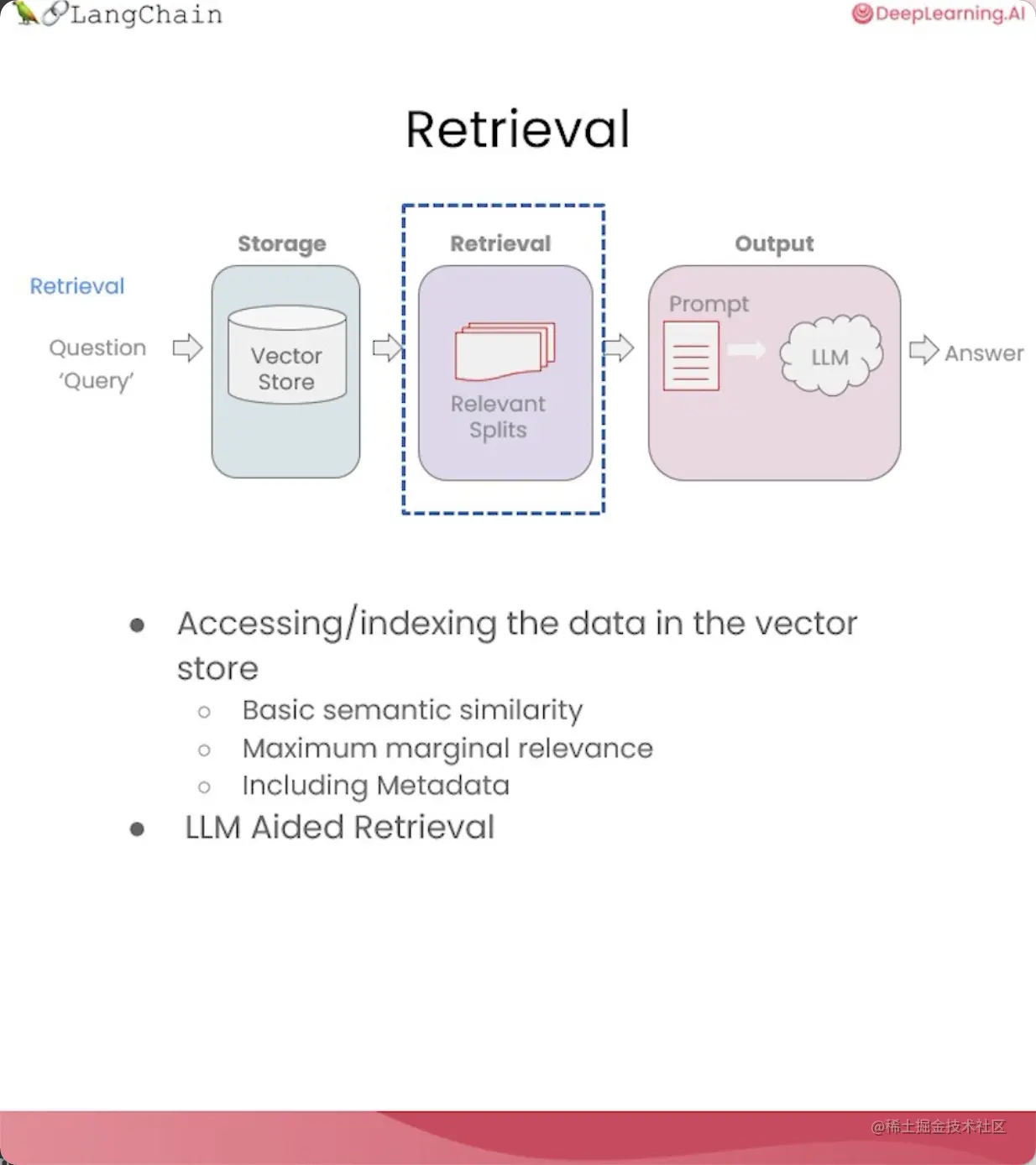
在这一课中,我们将深入探讨「检索」技术,并介绍一些更先进的方法来克服上一课的边缘情况。
检索是检索增强生成(RAG)流程的核心。
解决多样性:最大边缘相关性
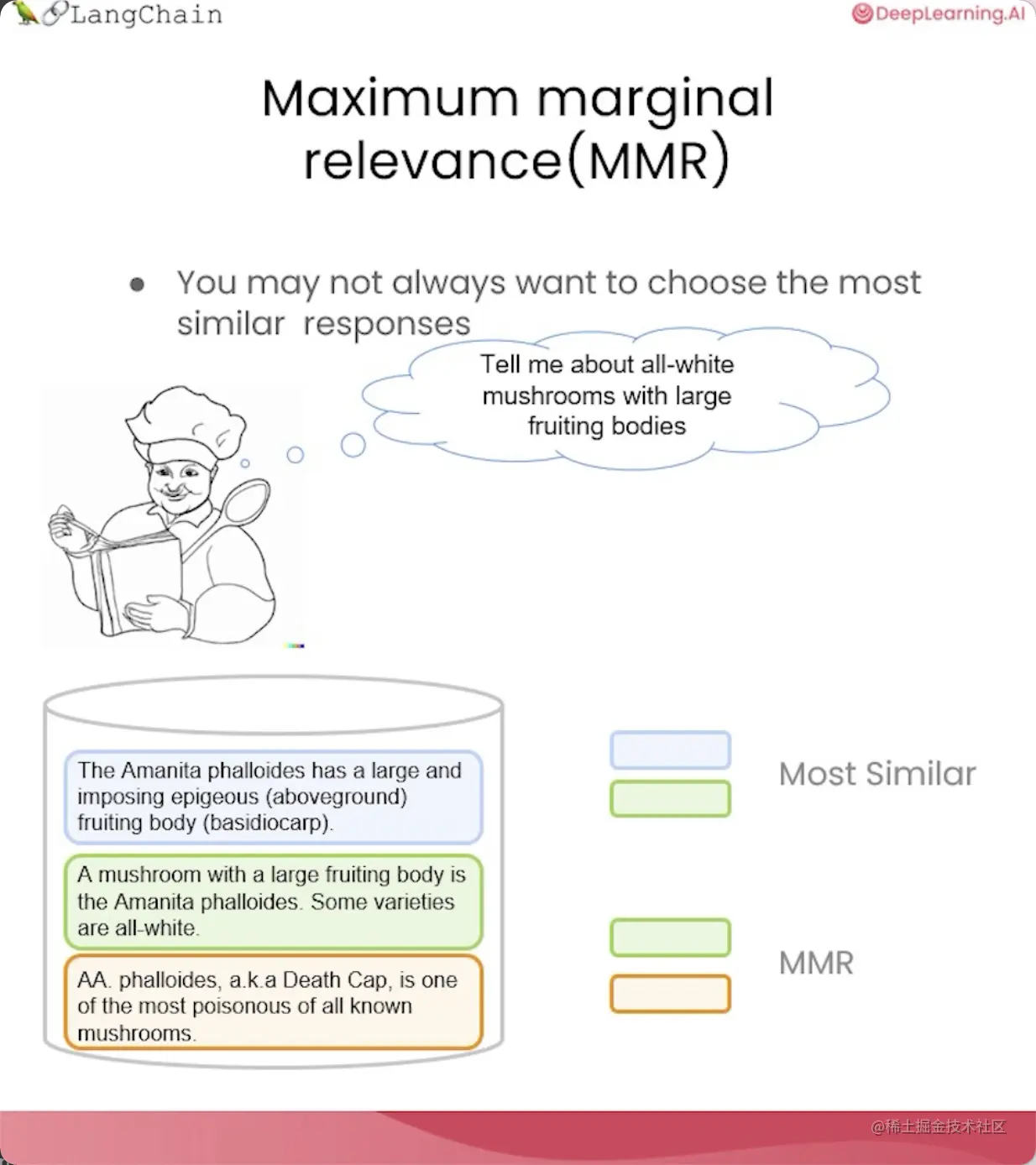
最大边缘相关性(MMR, Maximum Marginal Relevance)背后的理念是,如果我们总是选择与查询在嵌入空间中最相似的文档,我们可能会错过一些多元化的信息。
MMR可以帮助我们选择一个更多样化的文档集合。
MMR在保持查询相关性的同时,尽量增加结果之间的多样性,它的做法是:
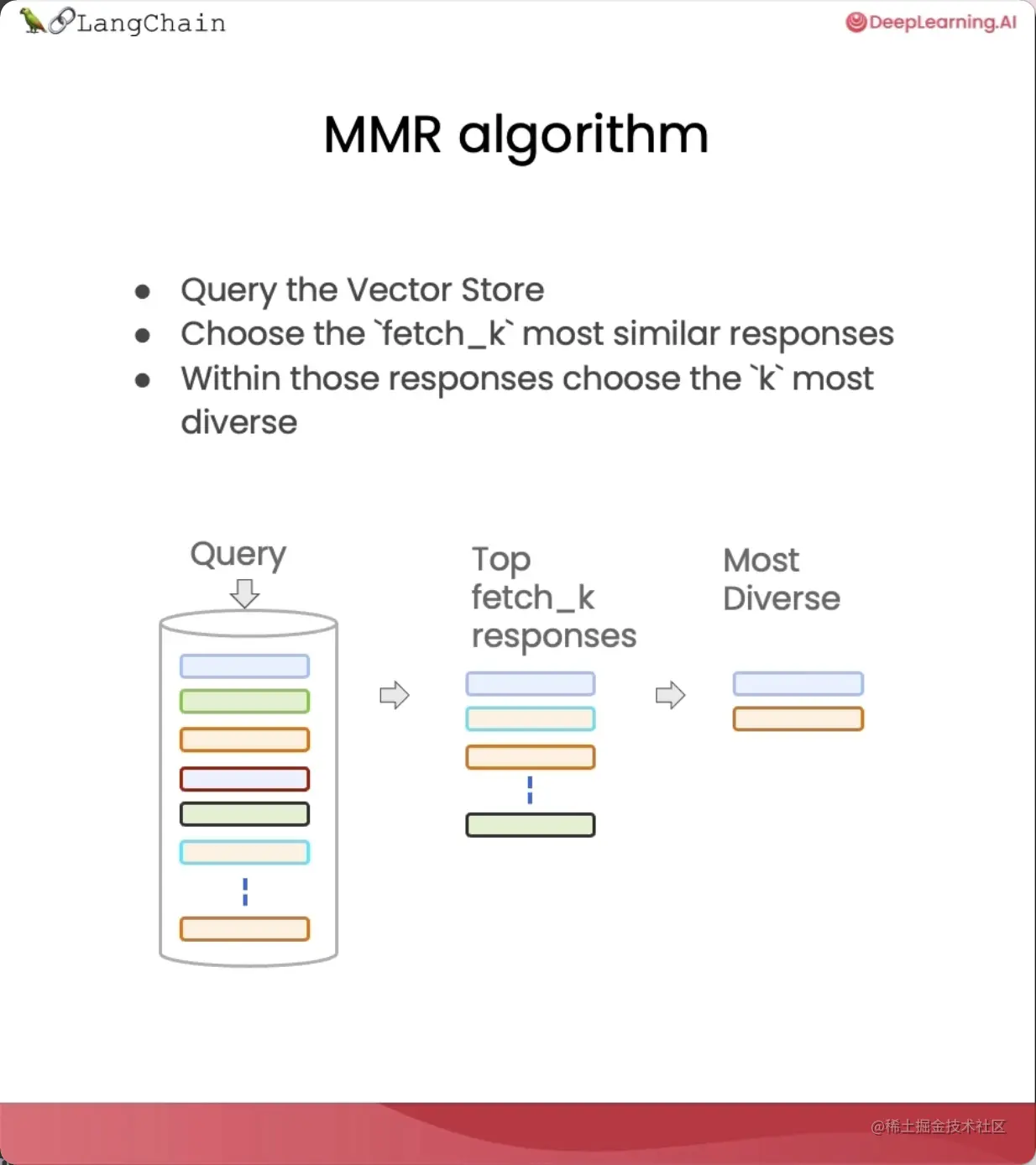
- 首先发送一个查询,得到一组回答;
- 用”fetch_k”参数指定我们想要获取的响应数量,这完全基于语义相似性;
- 然后,针对这个较小的文档集合,从多样性方面进行优化;
- 最后从这组文档中,选择”k”个响应返回给用户。
我们用一个简单的例子来帮助理解:
目标是查询有指定特征的蘑菇信息。
步骤1:创建Chroma向量存储
ini复制代码from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
步骤2:用少量信息创建一个小型数据库
ini复制代码# 鹅膏菌有一个巨大而雄伟的子实体(地上部分)。
# 有大子实体的蘑菇是鹅膏菌。有些品种是全白色的。
# 鹅膏菌,又叫死亡帽,是所有已知蘑菇中毒性最强的一种。
texts = [
"""The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""",
"""A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""",
"""A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.""",
]
smalldb = Chroma.from_texts(texts, embedding=embedding)
步骤3:进行相似性搜索
ini复制代码# 告诉我有关带有大子实体的全白蘑菇的信息
question = "Tell me about all-white mushrooms with large fruiting bodies"
smalldb.similarity_search(question, k=2)
# [Document(page_content='A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.', metadata={}),
# Document(page_content='The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).', metadata={})]
可以看到,它根据k值返回了两个最相关的文档,但没有提到它们有毒的事实。
步骤4:进行MMR搜索
ini复制代码smalldb.max_marginal_relevance_search(question,k=2, fetch_k=3)
# [Document(page_content='A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.', metadata={}),
# Document(page_content='A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.', metadata={})]
这里我们传入了”k=2″,表示仍然想返回两个文档,但我们设置了”fetch_k=3″,表示想获取三个文档。然后我们就可以看到,返回的文档中包含了它们有毒的事实。
现在我们试着用这个方法来处理上一节课中的失败情况1:
ini复制代码question = "what did they say about matlab?"
docs_mmr = vectordb.max_marginal_relevance_search(question,k=3)
docs_mmr[0].page_content[:100]
# 'those homeworks will be done in either MATLA B or in Octave, which is sort of — I nknow some people '
docs_mmr[1].page_content[:100]
# 'algorithm then? So what’s different? How come I was making all that noise earlier about nleast squa'
可以看到,第一个文档跟之前一样,因为它最相关。而第二个文档这次就不同了,这说明MMR让回答中增加了一些多样性。
解决特殊性:使用自查询检索器处理元数据
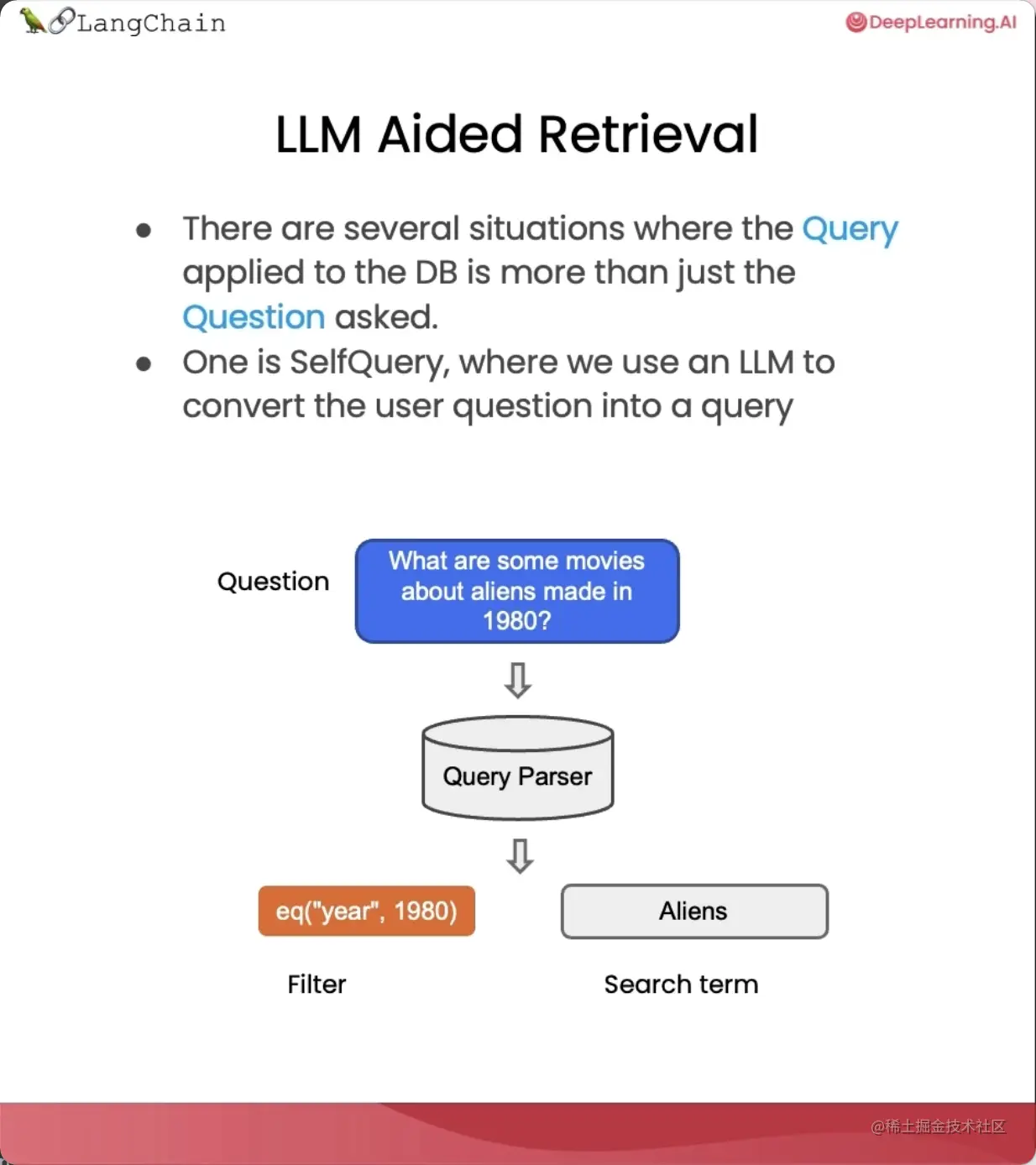
自查询使用语言模型将原始问题分割为两个独立的部分,一个过滤器和一个搜索项。
搜索项就是我们在语义上想要查找的问题内容。
过滤器则是包含我们想要过滤的元数据。
比如,“1980年制作的关于外星人的电影有哪些”,语义部分就是“关于外星人的电影”,元数据部分则是“电影年份应为1980年”。
我们先手动指定一个元数据过滤器来验证它的效果。
目标是处理上一节课的失败情况2:
ini复制代码question = "what did they say about regression in the third lecture?"
# 指定源为第三堂课的PDF文档
docs = vectordb.similarity_search(
question,
k=3,
filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"}
)
for d in docs:
print(d.metadata)
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 0}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 14}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 4}
可以看到,现在检索到的文档都来自那一堂课了。
我们还可以使用SelfQueryRetriever,从问题本身推断出元数据。
步骤1:提供元数据字段信息
python复制代码from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="source",
description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the lecture",
type="integer",
),
]
这个例子中的元数据只有两个字段,源(source)和页(page)。我们需要填写每个字段的名称、描述和类型。这些信息会被传给语言模型,所以需要尽可能描述得清楚。
步骤2:初始化自查询检索器
ini复制代码# 指定文档实际内容的信息
document_content_description = "Lecture notes"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)
步骤3:运行自查询检索器搜索问题
shell复制代码question = "what did they say about regression in the third lecture?"
docs = retriever.get_relevant_documents(question)
for d in docs:
print(d.metadata)
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 0}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 14}
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 4}

可以看到,语义部分表明这是一个关于回归的查询。过滤器部分表明我们只想看那些source值为指定值的文档。
而从打印出的元数据看,它们都来自指定的那一堂课,说明自查询检索器确实可以用来精确地进行元数据过滤。
解决相关性:使用上下文压缩提取出与查询最相关的部分
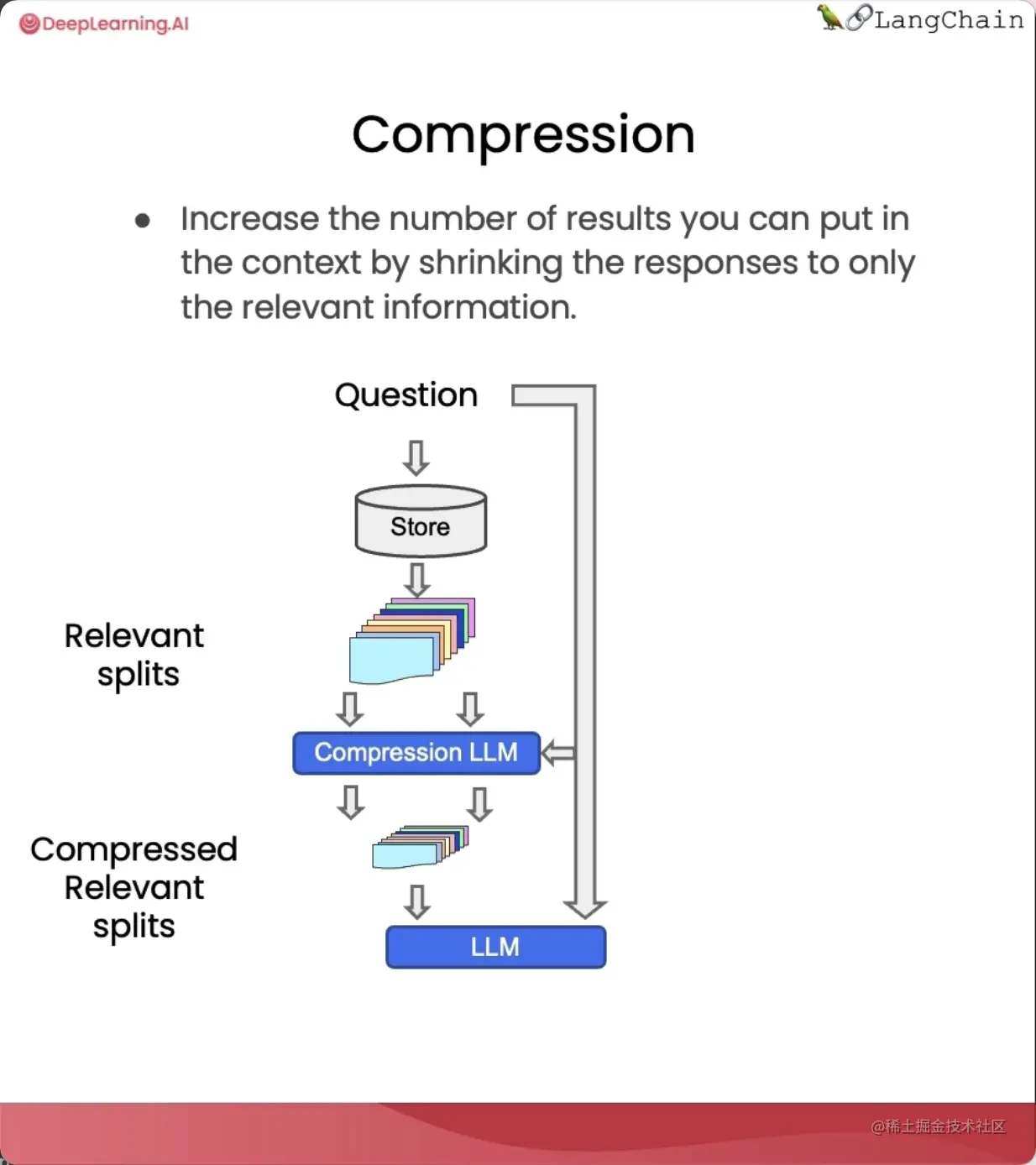
提高检索文档质量的另一种方法是压缩。
当你提出一个问题时,你会得到整个存储的文档,但可能只有其中一小部分是跟问题相关的。
也就是说,与查询最相关的信息可能被隐藏在包含大量无关文本的文档里。
上下文压缩就是为了解决这个问题的。
通过压缩,你可以先让语言模型提取出最相关的片段,然后只把最相关的片段传给最终的语言模型调用。
这会增加语言模型调用的成本,但也会让最终的答案更集中在最重要的内容上,这需要我们自己权衡。
步骤1:创建上下文压缩检索器
ini复制代码from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 包装我们的向量存储
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever()
)
步骤2:提出问题,检索压缩后的相关文档
ini复制代码question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
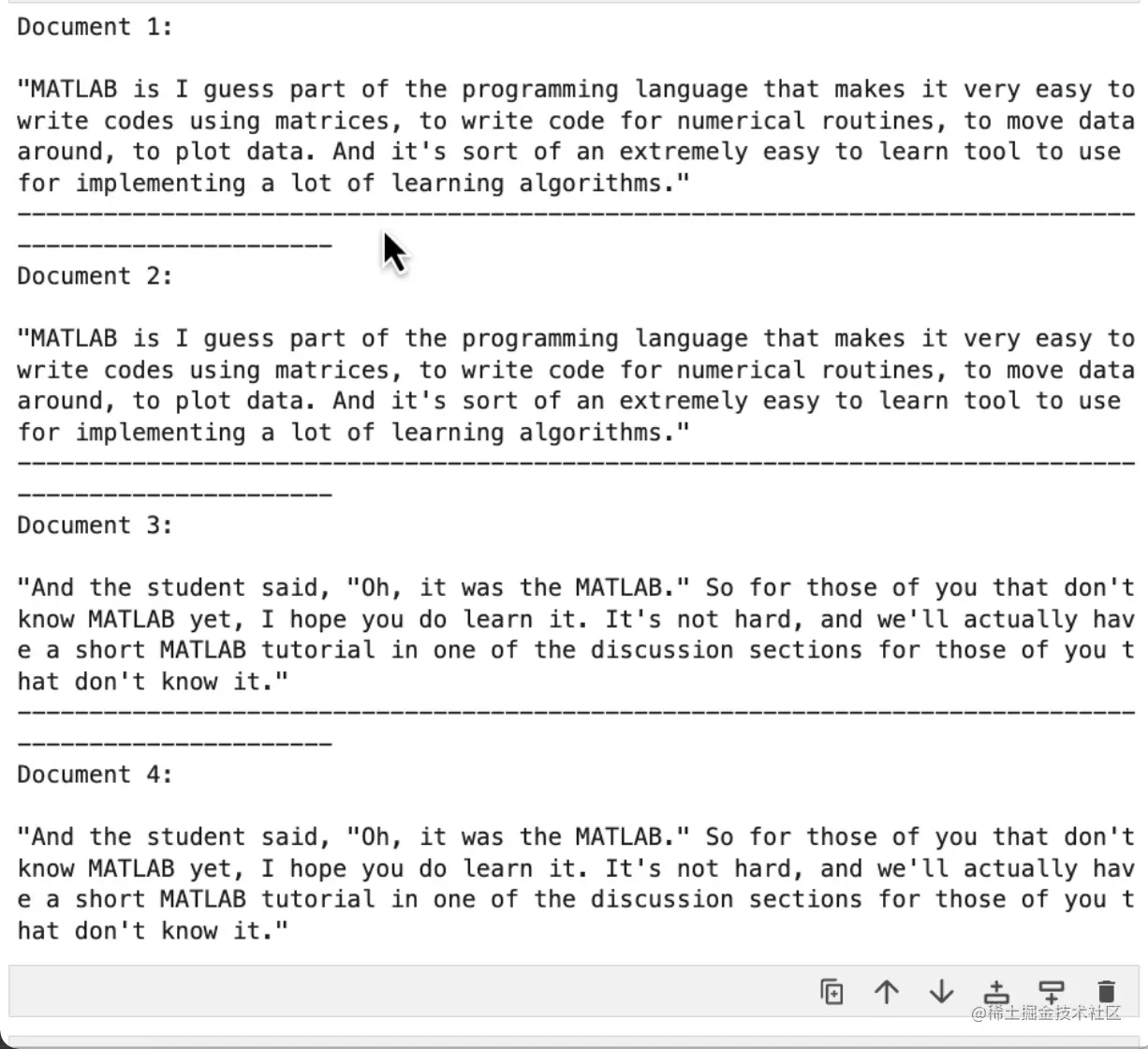
从压缩后的文档我们可以看到, 一,它们比普通的文档短得多; 二,仍然有重复的内容,这是因为底层我们还是用的语义搜索算法。
为了解决内容重复的问题,我们可以在创建检索器时,结合前面的内容,把搜索类型设置为MMR。
ini复制代码compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever(search_type = "mmr")
)
question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
重新运行之后,我们得到的就是一个没有任何重复信息的过滤后的结果集了。

下一步,我们将讨论如何使用这些检索到的文档来回答用户的问题。
