问答
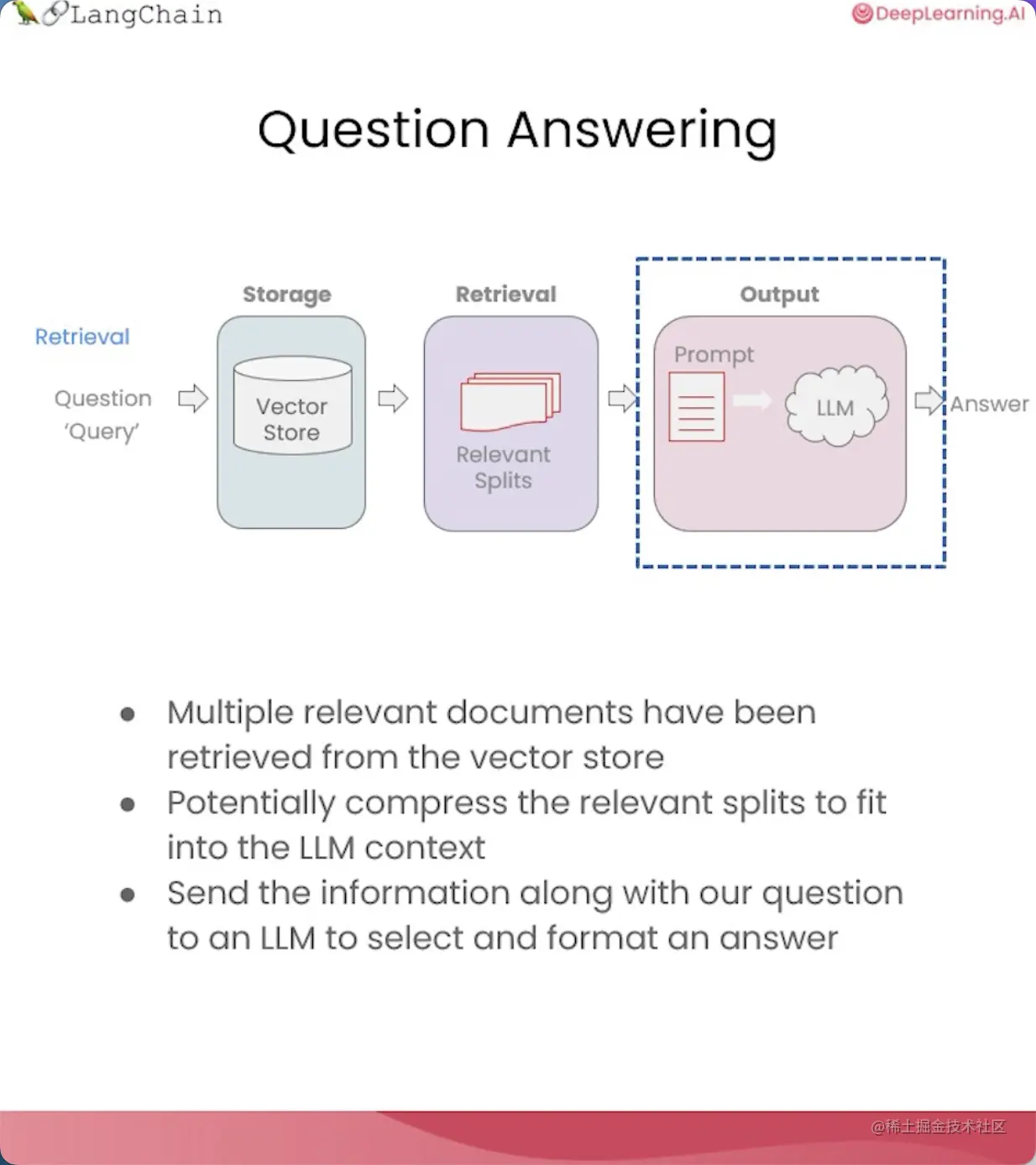
在这节课中,我们将学习如何利用检索到的文档来回答用户的问题。
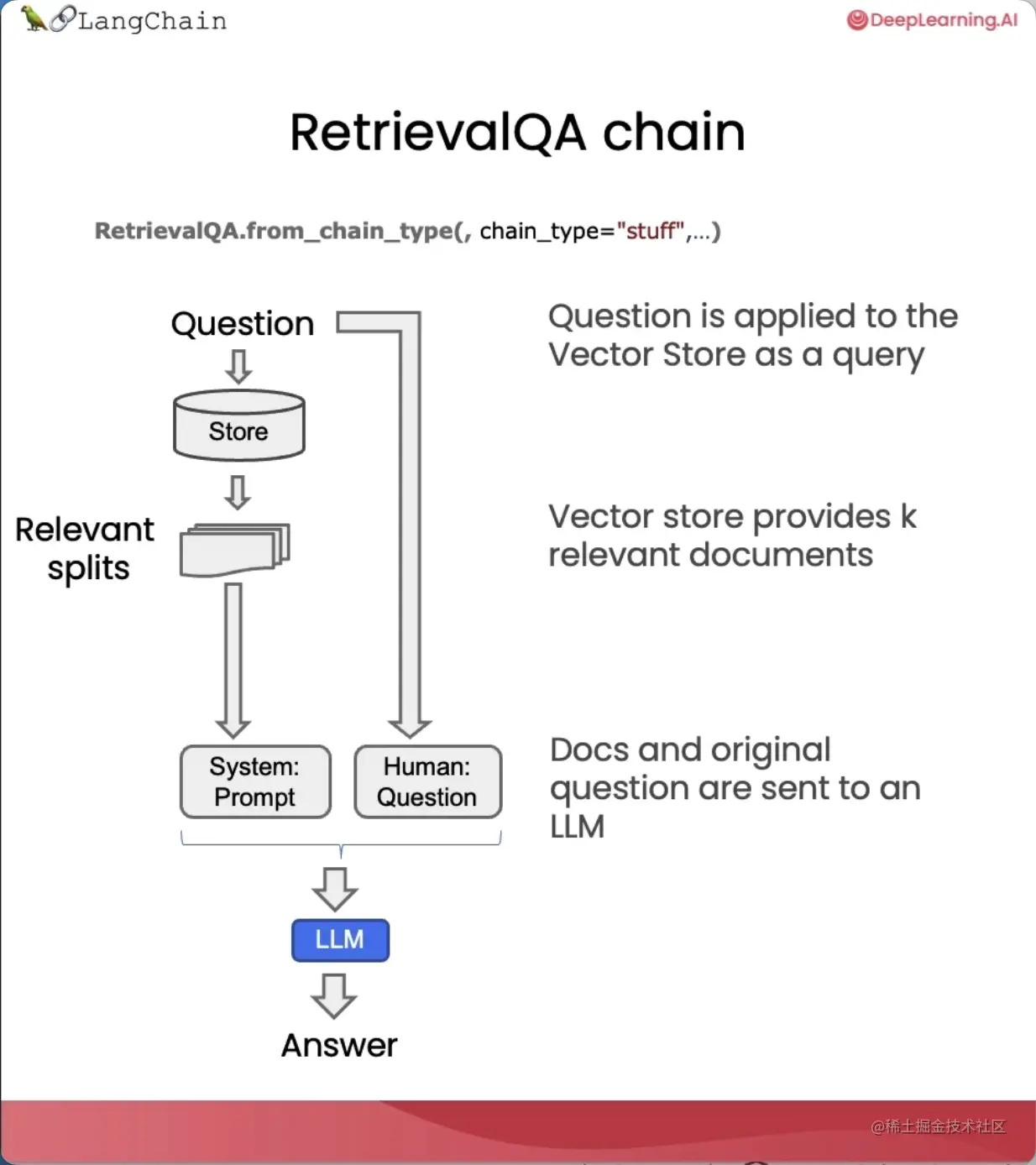
整个过程可以拆分为以下几个步骤:
- 用户输入一个问题(Question)
- 从向量存储(Store)中检索出与问题相关的文档分块(Relavant splits)
- 将这些分块连同系统提示(System:Prompt)和用户问题(Human:Question)一起作为输入传给语言模型(LLM)
- 语言模型根据输入生成答案(Answer)
默认使用的是stuff方法,其特点如下:
| 特点 | 优点 | 缺点 |
|---|---|---|
| 将所有检索到的分块放入同一个上下文窗口中,只需要对语言模型进行一次调用。 | 简单、廉价且效果不错。 | 当检索到的文档过多时,由于上下文窗口长度有限,可能无法将所有分块都传入。 |
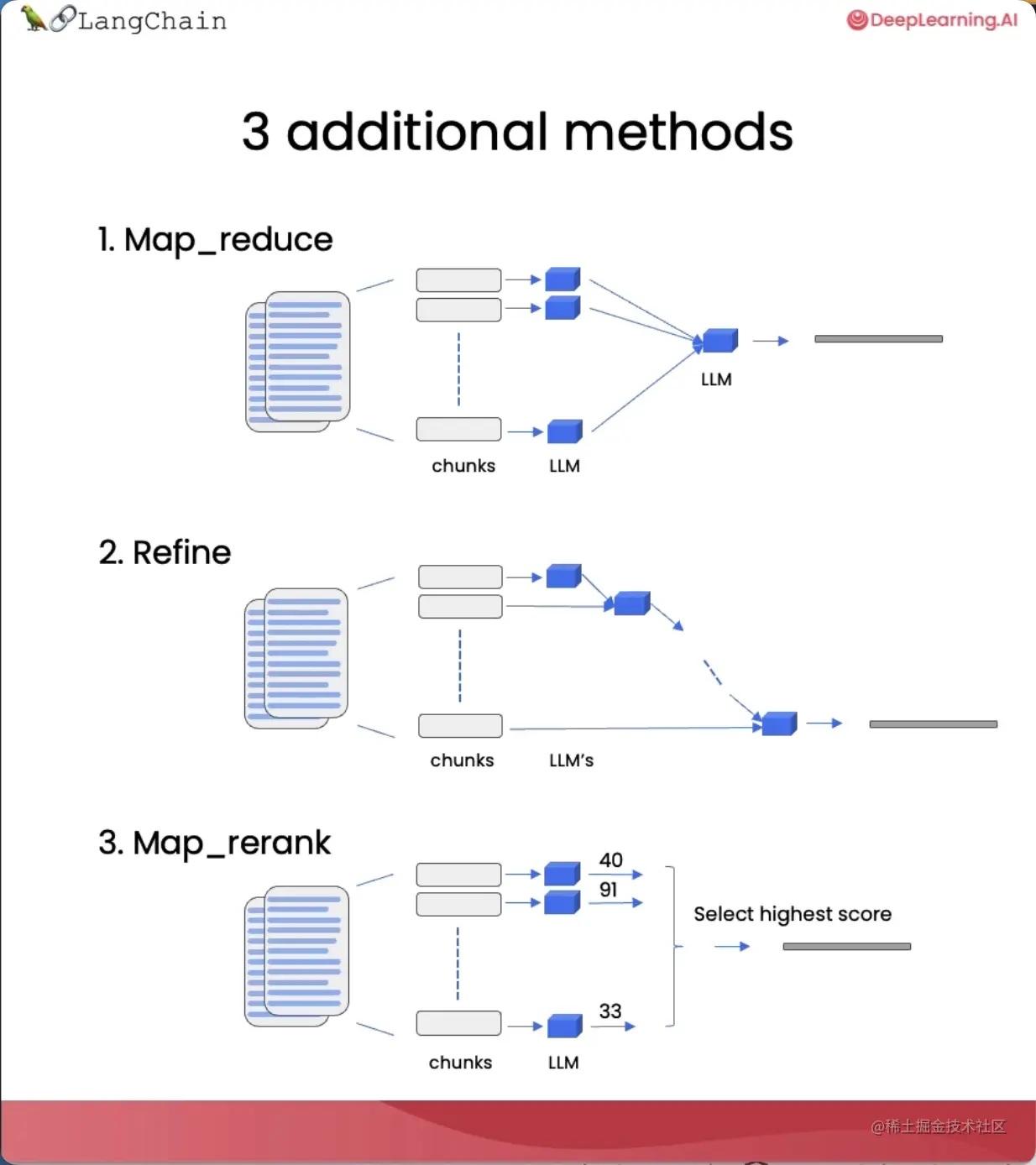
为了解决上下文窗口长度限制的问题,我们可以使用Map-reduce、Refine和Map-rerank三种方法,这些方法我们在之前的课程中已经简要介绍过了,今天我们将进一步深入了解。
stuff
步骤1:加载之前保存的向量数据库
ini复制代码from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
步骤2:初始化将用于回答问题的语言模型
ini复制代码llm_name = "gpt-3.5-turbo"
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name=llm_name, temperature=0)
temperature参数设置为0,可以帮助我们得到更准确的答案,因为它降低了语言模型的可变性,通常能给我们最高置信度、最可靠的答案。
步骤3:导入、创建、调用检索问答链,输入问题,并获取答案
ini复制代码question = "What are major topics for this class?"
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
result = qa_chain({"query": question})
result["result"]
‘The major topic for this class is machine learning. Additionally, the class may cover statistics and algebra as refreshers in the discussion sections. Later in the quarter, the discussion sections will also cover extensions for the material taught in the main lectures.’
步骤4:使用提示模板优化输出结果
提示模板是一种可以帮助语言模型生成更符合要求的输出结果的技巧,我们在上一门课中已经介绍过了。这里我们使用的提示模板主要是为了让输出结果更简洁、更少编造、更礼貌。
ini复制代码from langchain.prompts import PromptTemplate
# 构建提示词
# {context}:上下文占位符,用于放置文档内容
# {question}:问题占位符,放置要查询的问题
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
# 运行链
# return_source_documents=True用于支持查看检索到的文档
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
question = "Is probability a class topic?"
result = qa_chain({"query": question})
result["result"]
‘Yes, probability is assumed to be a prerequisite for this class. The instructor assumes familiarity with basic probability and statistics, and will go over some of the prerequisites in the discussion sections as a refresher course. Thanks for asking!’
步骤5:查看返回的源文档,理解其从哪里获取数据
css复制代码result["source_documents"][0]
Document(page_content=”of this class will not be very program ming intensive, although we will do some nprogramming, mostly in either MATLAB or Octa ve. I’ll say a bit more about that later. nI also assume familiarity with basic proba bility and statistics. So most undergraduate nstatistics class, like Stat 116 taught here at Stanford, will be more than enough. I’m gonna nassume all of you know what ra ndom variables are, that all of you know what expectation nis, what a variance or a random variable is. And in case of some of you, it’s been a while nsince you’ve seen some of this material. At some of the discussion sections, we’ll actually ngo over some of the prerequisites, sort of as a refresher course under prerequisite class. nI’ll say a bit more about that later as well. nLastly, I also assume familiarity with basi c linear algebra. And again, most undergraduate nlinear algebra courses are more than enough. So if you’ve taken courses like Math 51, n103, Math 113 or CS205 at Stanford, that would be more than enough. Basically, I’m ngonna assume that all of you know what matrix es and vectors are, that you know how to nmultiply matrices and vectors and multiply matrix and matrices, that you know what a matrix inverse is. If you know what an eigenvect or of a matrix is, that’d be even better. nBut if you don’t quite know or if you’re not qu ite sure, that’s fine, too. We’ll go over it in nthe review sections.”, metadata={‘source’: ‘docs/cs229_lectures/MachineLearning-Lecture01.pdf’, ‘page’: 4})
Map-reduce
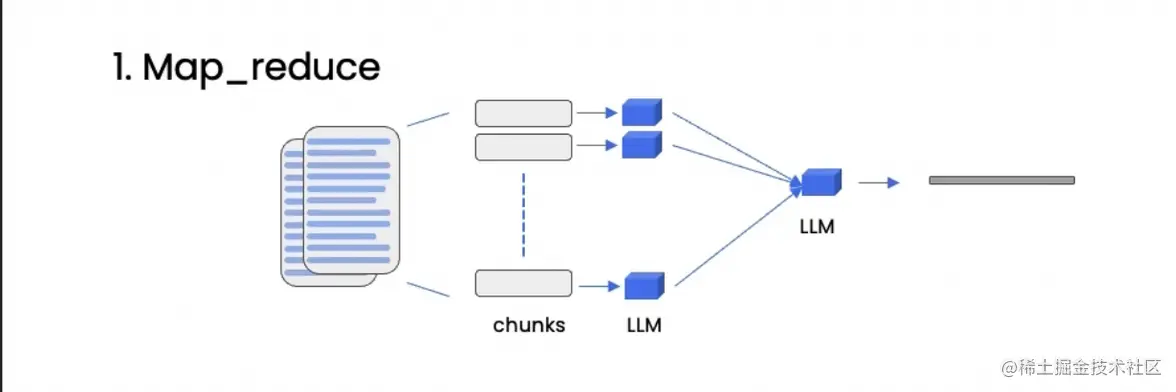
Map-reduce方法的特点如下:
| 特点 | 优点 | 缺点 |
|---|---|---|
| 1.将每个文档单独发送到语言模型中,根据单个文档生成答案; | 可以处理任意数量的文档。 | 1.涉及到对语言模型的多次调用,速度较慢; |
| 2.将所有这些答案组合在一起,再调用语言模型生成最终答案。 | 2.信息可能分散在不同的文档中,无法基于同一个上下文获取信息,结果可能不准确。 |
ini复制代码qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="map_reduce"
)
result = qa_chain_mr({"query": question})
result["result"]
‘There is no clear answer to this question based on the given portion of the document. The document mentions familiarity with basic probability and statistics as a prerequisite for the class, and there is a brief mention of probability in the text, but it is not clear if it is a main topic of the class.’
使用LangSmith平台了解这些链内部的调用情况
LangSmith 是一个用于构建生产级 LLM 应用程序的平台。
它可以让您轻松地调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理,并与使用 LLM 构建的开源框架 LangChain 完美集成。
要体验这个平台的功能,你需要:
- 前往LangSmith平台注册(可能需要排队)
- 创建 API 密钥
- 在以下代码中使用这个 API 密钥
- 取消注释以下代码,并重新运行MapReduce链
lua复制代码import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.langchain.plus"
os.environ["LANGCHAIN_API_KEY"] = "..." # 替换...为你的 API 密钥
之后,就可以切换到LangSmith平台,找到刚刚运行的RetrievalQA,查看输入、输出以及调用链了:
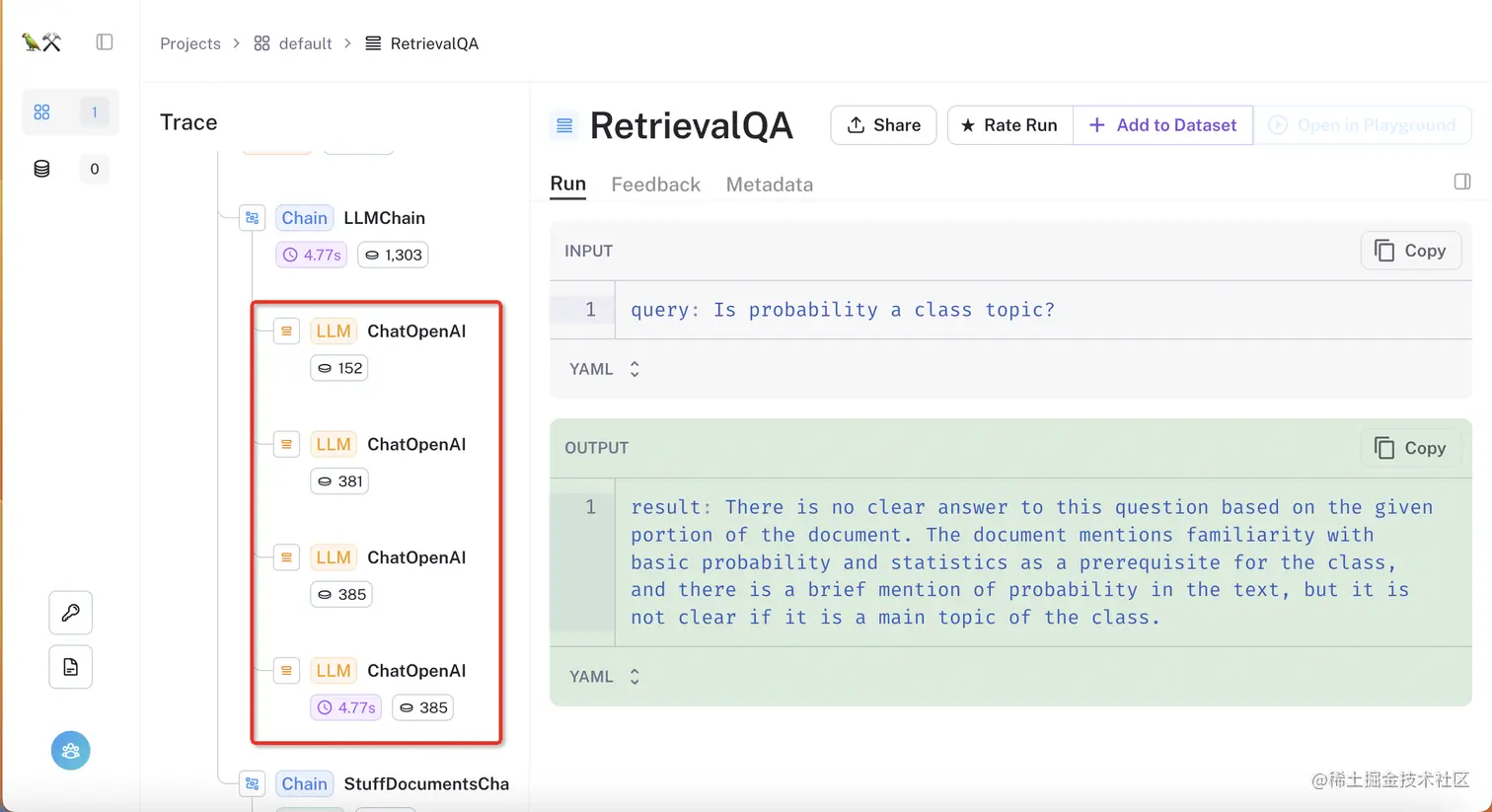
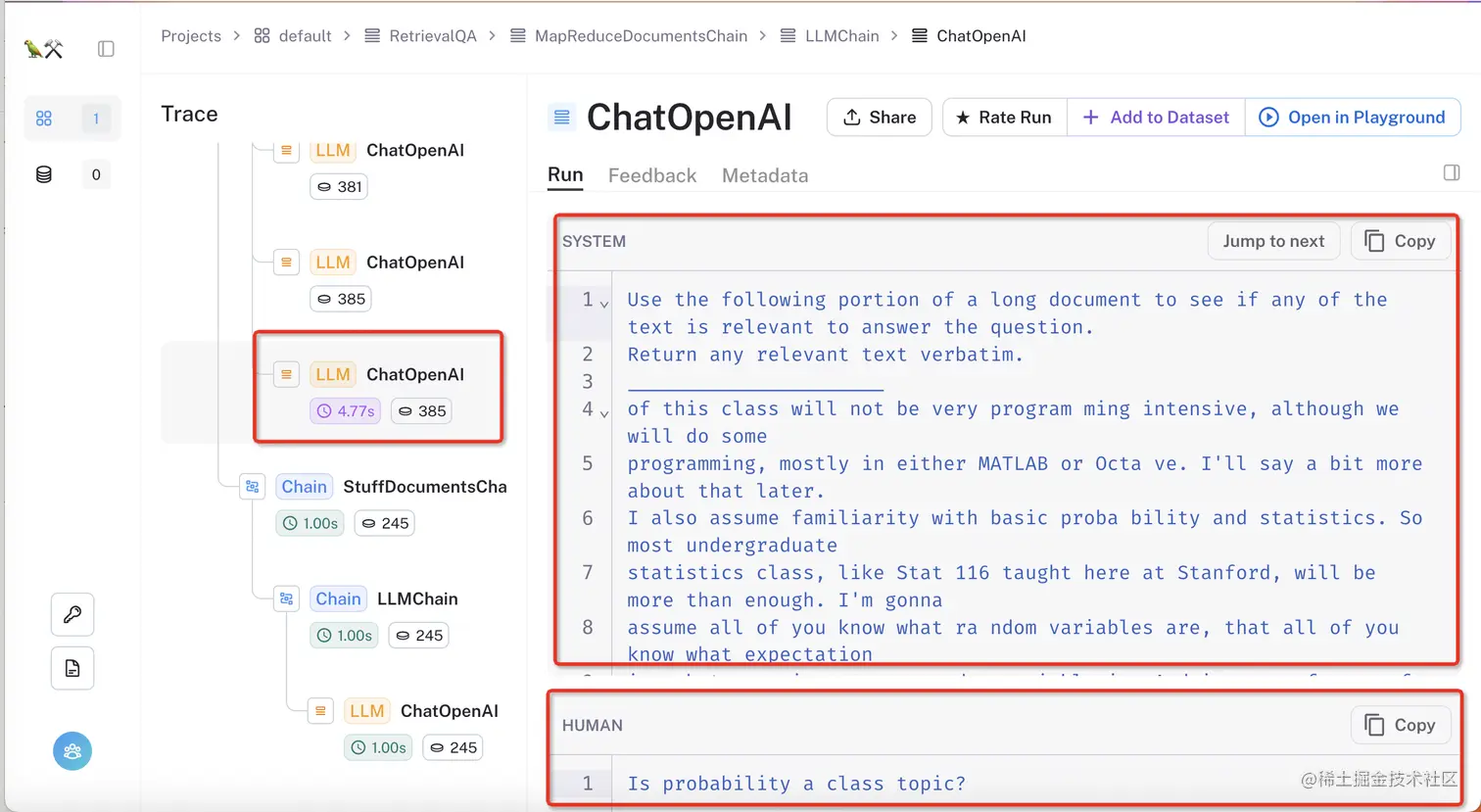
可以看到,MapReduceDocumentChain中涉及到了对语言模型的四次独立调用,点击其中一个,就可以看到每个文档的具体输入和输出:
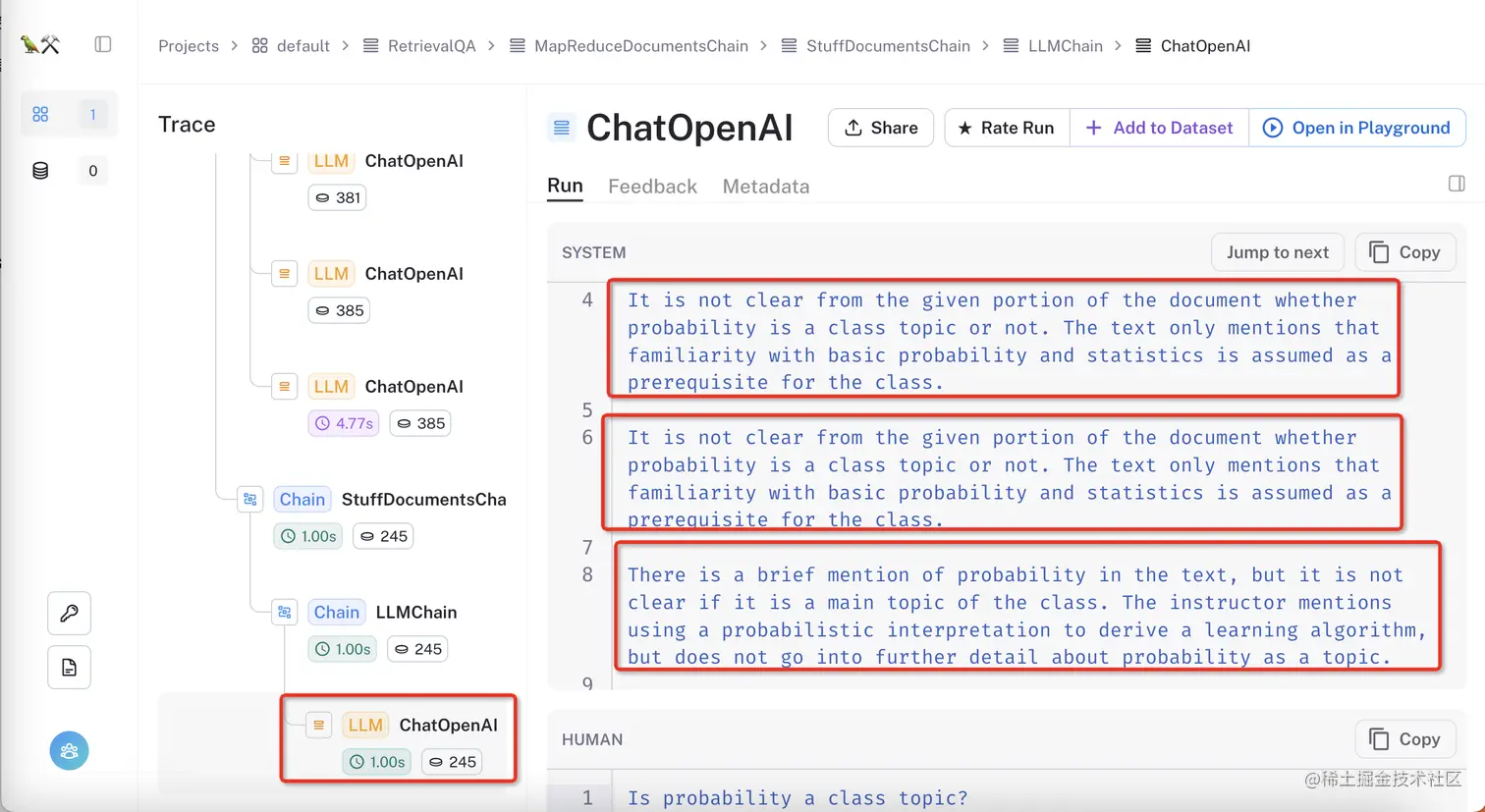
并且,可以看到,它们在最后的链中被合并为了StuffDocumentChain,也即把所有结果放到了最终调用中。点击进入就可以看到,系统消息中包含了来自前面文档的四个摘要:
Refine
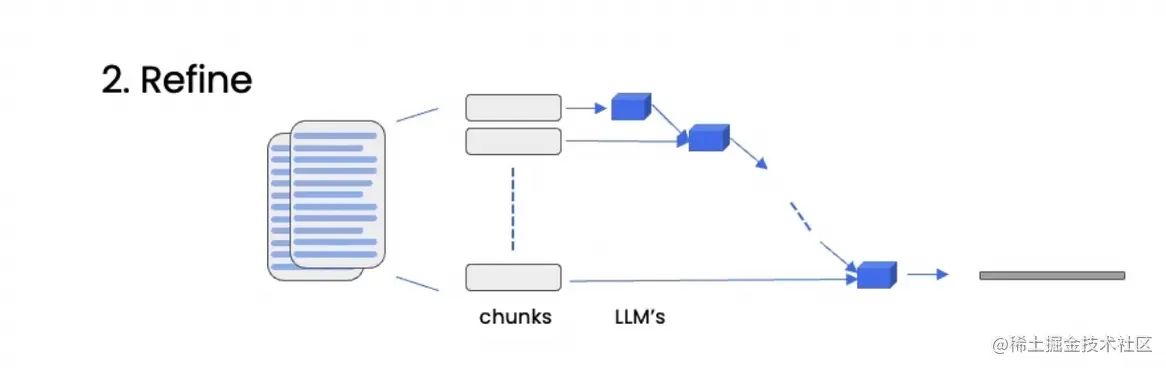
Refine方法的特点如下:
| 特点 | 优点 | 缺点 |
|---|---|---|
| 迭代地处理多个文档,基于前一个文档的答案来构建一个更好的答案。 | 允许组合信息,更鼓励信息的传递 | 速度较慢 |
ini复制代码qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="refine"
)
result = qa_chain_mr({"query": question})
result["result"]
“The main topic of the class is machine learning algorithms, including linear regression and classification. Basic probability and statistics, as well as linear algebra, are prerequisites for the class, but the instructor will provide a refresher course on these topics in some of the discussion sections. Later in the quarter, the discussion sections will also cover extensions for the material taught in the main lectures. The instructor will focus on a few important extensions that there wasn’t enough time to cover in the main lectures.”
现在还有一个问题,我们目前使用的链是没有“记忆”这个概念的,这就导致了它不会记住之前的问题或答案。为了解决这个问题,我们需要引入“记忆”功能,这就是我们下一节要讲的内容。
Chat
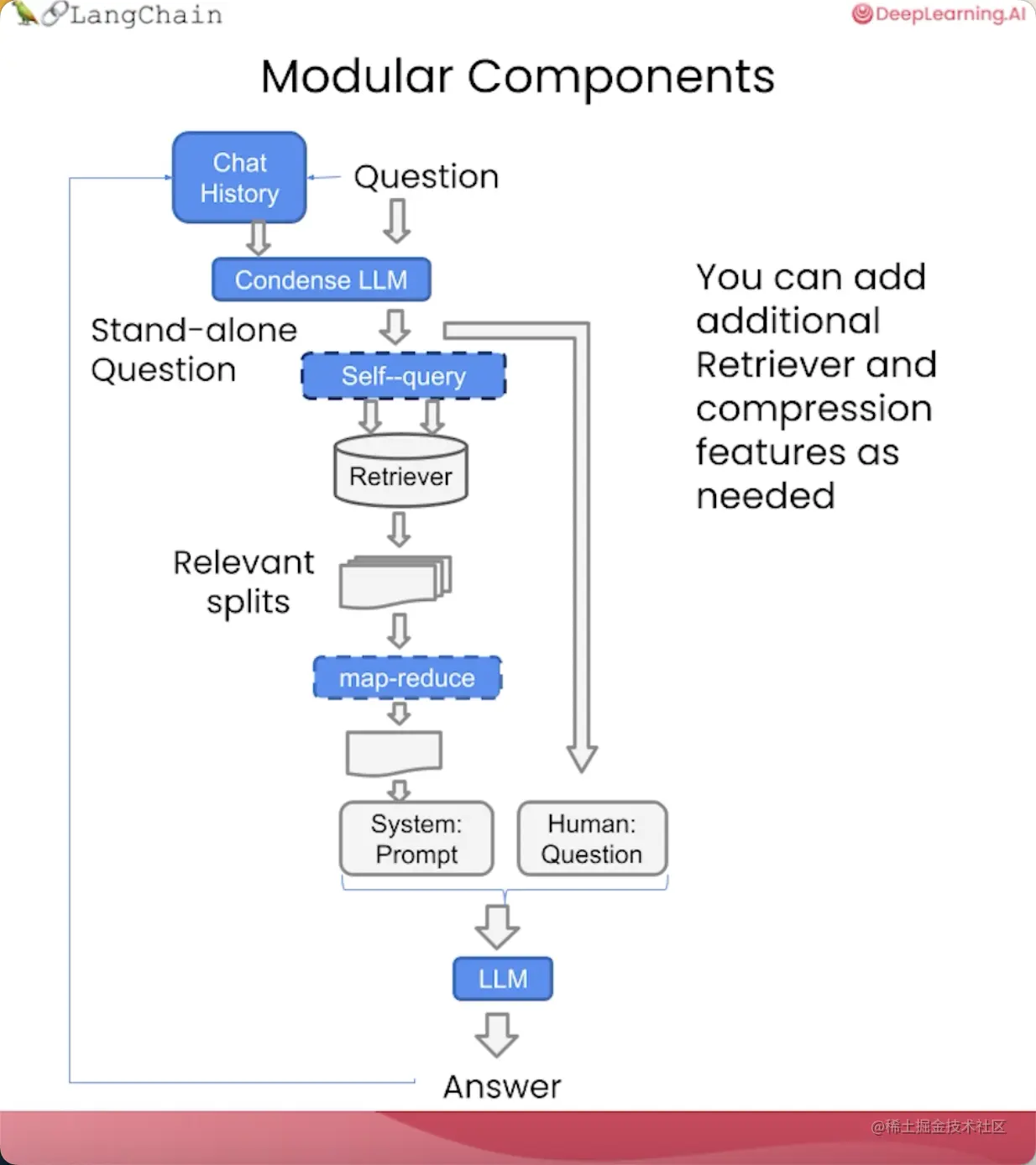
在这节课中,我们将构建一个完整的问答聊天机器人,它将结合我们之前讲过的所有组件,并引入“聊天历史”这个概念,让它在回答问题时能够考虑到之前的对话或信息,也就是说,它能记住你之前说过什么。
步骤1:初始化用于保存大量文档内容的向量数据库
ini复制代码from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
步骤2:初始化将作为聊天机器人使用的语言模型
ini复制代码llm_name = "gpt-3.5-turbo"
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name=llm_name, temperature=0)
步骤3:初始化提示模板,让输出结果更简介、更少编造、更礼貌
ini复制代码# 构建提示
from langchain.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,)
步骤4:创建检索QA链,用于合并检索到的文本片段并调用语言模型
ini复制代码# 运行链
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
步骤5:使用ConversationBufferMemory增加聊天机器人的记忆功能
ini复制代码from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
ConversationBufferMemory提供了一个聊天消息历史的记忆缓冲区,并且每次都会将这部分历史消息传入聊天机器人。
return_messages=True表示将返回一个列表类型的聊天历史记录,而不是一个字符串。
步骤6:创建ConversationalRetrievalChain(对话检索链),传入语言模型、检索器和记忆系统
ini复制代码from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)
ConversationalRetrievalChain会在RetrievalQAChain的基础上,将聊天历史和新提的问题整合成一个新的独立问题,以传递给向量存储库,查找相关文档。
步骤7:使用PyPDFLoader加载所要参考的文档
python复制代码from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
def load_db(file, chain_type, k):
# 加载文档
loader = PyPDFLoader(file)
documents = loader.load()
...
步骤8:分割文档,为每个分块创建嵌入,并存储到向量存储库中。
ini复制代码def load_db(file, chain_type, k):
...
# 分隔文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# 定义嵌入
embeddings = OpenAIEmbeddings()
# 基于文档数据创建向量数据库
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
...
步骤9:从向量数据库创建一个基于“相似度”的检索器。
ini复制代码def load_db(file, chain_type, k):
...
# 定义检索器
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
...
步骤10:创建对话检索链,用于将聊天历史和新提的问题整合成一个新的独立问题
ini复制代码def load_db(file, chain_type, k):
...
# create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model_name=llm_name, temperature=0),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
)
return qa
需要注意的是,这里我们并没有传入记忆系统,而是将记忆管理交给了GUI,这意味着聊天历史需要在链之外进行维护。
步骤11:提供一个与聊天机器人交互的用户界面
less复制代码import panel as pn
import param
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
def call_load_db(self, count):
if count == 0 or file_input.value is None: # init or no file specified :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # local copy
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
def convchain(self, query):
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' #clears loading indicator when cleared
return pn.WidgetBox(*self.panels,scroll=True)
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
ini复制代码cb = cbfs()
file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')
bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp)
jpg_pane = pn.pane.Image( './img/convchain.jpg')
tab1 = pn.Column(
pn.Row(inp),
pn.layout.Divider(),
pn.panel(conversation, loading_indicator=True, height=300),
pn.layout.Divider(),
)
tab2= pn.Column(
pn.panel(cb.get_lquest),
pn.layout.Divider(),
pn.panel(cb.get_sources ),
)
tab3= pn.Column(
pn.panel(cb.get_chats),
pn.layout.Divider(),
)
tab4=pn.Column(
pn.Row( file_input, button_load, bound_button_load),
pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),
pn.layout.Divider(),
pn.Row(jpg_pane.clone(width=400))
)
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),
pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)
dashboard
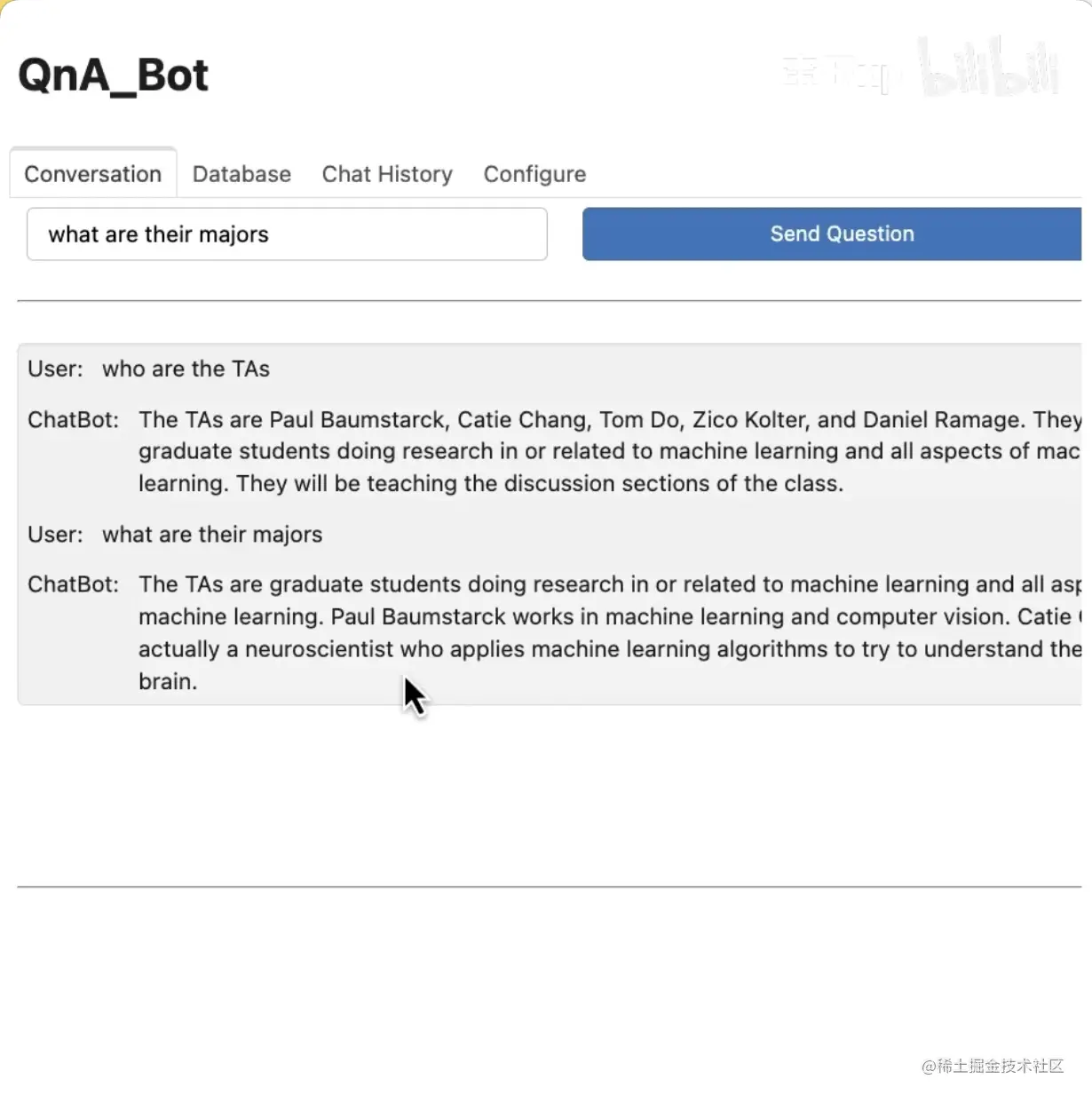
步骤12:在运行起来的用户界面上进行实际的问答对话。