

大型语言模型(LLM)可以回答各种类型的问题,但有一个明显的局限,那就是:
LLM只了解训练过的内容,而不了解你的个人数据。
比如,
- 你所在公司内部的专有文档
- LLM训练完成后新产生的数据
为了解决这个问题,在这门课程中,我们将深入研究LangChain的一个广受欢迎的用例:
如何使用LangChain与你的数据进行对话。
我们假设你已经掌握了LangChain的基础知识,如果你还不了解LangChain是什么,欢迎先阅读以下两篇文章:
文档加载
文档加载器的介绍

文档加载器的作用,是将不同格式和来源的数据加载到标准的文档对象中,包括内容本身以及关联的元数据。

LangChain提供了多种类型的文档加载器,用于处理非结构化数据,根据数据来源的不同大致可分为:
-
公共数据源加载器,如YouTube、Twitter;
-
专有数据源加载器,如Figma、Notion。
文档加载器也可以加载结构化数据,比如基于表格中包含的文本数据,对问题进行回答或语义搜索。
这种技术我们称之为检索增强生成(RAG,Retrieval-Augmented Generation)。
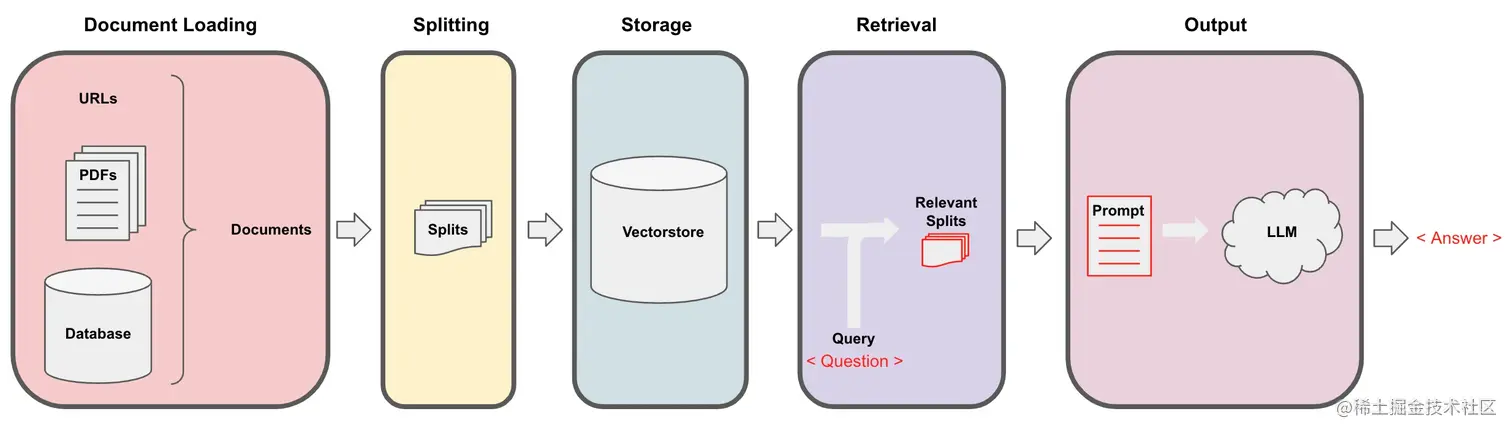
在RAG中,LLM会从外部数据集中检索上下文文档,作为其执行的一部分,这对于询问特定文档的问题非常有用。
下面我们来实际使用其中的一些文档加载器。
加载PDF文档
ini复制代码# 导入PyPDFLoader文档加载器
from langchain.document_loaders import PyPDFLoader
# 将位于特定路径下的PDF文档放入到加载器中
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
# 加载PDF文档
pages = loader.load()
默认情况下,这将加载一系列的文档。以页面为单位,每个页面都是一个独立的文档。
python复制代码# PDF的总页数
len(pages)
# 22
每个文档都包含「页面内容」和「与文档关联的元数据」。
页面内容:
bash复制代码# 仅打印前500个字符
print(page.page_content[0:500])
MachineLearning-Lecture01
Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine learning class. So what I wanna do today is ju st spend a little time going over the logistics of the class, and then we’ll start to talk a bit about machine learning.
By way of introduction, my name’s Andrew Ng and I’ll be instru ctor for this class. And so I personally work in machine learning, and I’ ve worked on it for about 15 years now, and I actually think that machine learning i
元数据:
shell复制代码page.metadata
# source: 源信息,这里对应PDF的文件名
# page:页码信息,这里对应PDF的页码
# {'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf', 'page': 0}
加载YouTube视频
步骤1:导入几个关键部分,包括
-
YouTube音频加载器:从YouTube视频加载音频文件
-
OpenAI Whisper解析器:使用OpenAI的Whisper模型(一个语音转文本的模型),将YouTube音频转换为我们可以处理的文本格式
javascript复制代码from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
步骤2:指定URL及保存音频文件的目录,创建组合了步骤1两个关键部分的通用加载器并执行加载
ini复制代码url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(
YoutubeAudioLoader([url],save_dir),
OpenAIWhisperParser()
)
docs = loader.load()
步骤3:查看加载完成的视频文稿
css复制代码docs[0].page_content[0:500]

加载网络URL
ini复制代码from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/37signals-is-you.md")
docs = loader.load()
print(docs[0].page_content[:500])
文档分割
在上一节中,我们将不同格式和来源的数据加载到了标准的文档对象中。但是,这些文档经过转换后依然很大,而我们通常只需要检索文档中与主题最相关的内容,可能只是几个段落或句子,而不需要整个文档。
因此,在这一节中,我们将使用LangChain的文本分割器,把大型的文档分割成更小的块。
文档分割的重要性
文档分割发生在数据加载之后,放入向量存储之前。
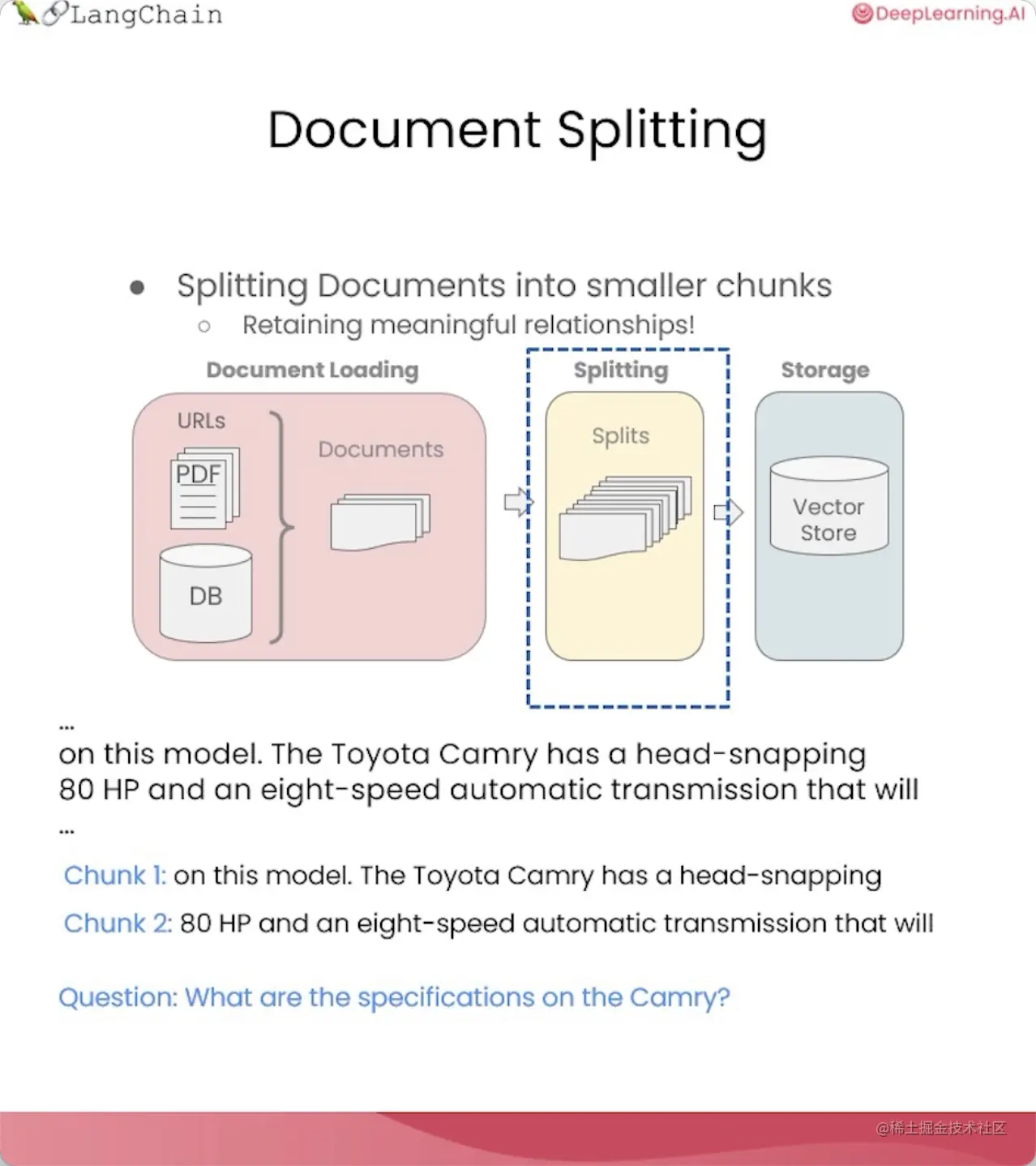
如果简单地按字符长度来分割文档,可能会造成句子的断裂,导致语义的丢失或混乱。这样的分割方式,无法为我们正确地回答问题。
合理的做法,是尽量保持语义的连贯性和完整性,分隔出有意义的块。
文档分割的方式
在LangChain中,所有的文本分割器都遵循同一个原理,就是根据「块大小(chunk_size)」和「两个块之间的重叠大小(chunk_overlap)」进行分割。

chunk_size指的是每个块包含的字符或Token(如单词、句子等)的数量。
chunk_overlap指的是两个块之间共享的字符或Token的数量。chunk_overlap可以帮助保持上下文的连贯性,避免因为分割而丢失重要的信息。
LangChain提供了多种类型的分割器,主要差别在于如何确定块的边界、块由哪些字符或Token组成、以及如何测量块的大小(按字符还是按Token)。

元数据(Metadata)是块分割的另一个重要部分,我们需要在所有块中保持元数据的一致性,同时在需要的时候添加新的元数据。
基于字符的分割
如何分割块通常取决于我们正在处理的文档类型。
比如,处理代码的分割器拥有许多不同编程语言的分隔符,如Python、Ruby、C等。当分割代码文档时,它会考虑到不同编程语言之间的差异。
步骤1:导入文本分割器
python复制代码# RecursiveCharacterTextSplitter-递归字符文本分割器
# CharacterTextSplitter-字符文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
步骤2:设定块大小和块重叠大小
ini复制代码chunk_size =26
chunk_overlap = 4
步骤3:初始化文本分割器
ini复制代码r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
步骤4:使用不同的分割器对字符串进行分割
递归字符文本分割器
ini复制代码text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg'
r_splitter.split_text(text2)
# ['abcdefghijklmnopqrstuvwxyz', 'wxyzabcdefg']
可以看到,第二个块是从「wxyz」开始的,刚好是我们设定的块重叠大小。
css复制代码text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
r_splitter.split_text(text3)
# ['a b c d e f g h i j k l m', 'l m n o p q r s t u v w x', 'w x y z']
字符文本分割器
scss复制代码c_splitter.split_text(text3)
# ['a b c d e f g h i j k l m n o p q r s t u v w x y z']
可以看到,字符文本分割器实际并没有分割这个字符串,这是因为字符文本分割器默认是以换行符为分隔符的,为此,我们需要将分隔符设置为空格。
ini复制代码c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator = ' '
)
c_splitter.split_text(text3)
# ['a b c d e f g h i j k l m', 'l m n o p q r s t u v w x', 'w x y z']
步骤5:递归分割长段落
ini复制代码some_text = """When writing documents, writers will use document structure to group content.
This can convey to the reader, which idea's are related. For example, closely related ideas
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. nn
Paragraphs are often delimited with a carriage return or two carriage returns.
Carriage returns are the "backslash n" you see embedded in this string.
Sentences have a period at the end, but also, have a space.
and words are separated by space."""
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["nn", "n", " ", ""]
)
r_splitter.split_text(some_text)
这里,我们传入一个分隔符列表,依次为双换行符、单换行符、空格和一个空字符。
这就意味着,当你分割一段文本时,它会首先采用双换行符来尝试初步分割,并视情况依次使用其他的分隔符来进一步分割。
最终分割结果如下:
[“When writing documents, writers will use document structure to group content. This can convey to the reader, which idea’s are related. For example, closely related ideas are in sentances. Similar ideas are in paragraphs. Paragraphs form a document.”,
‘Paragraphs are often delimited with a carriage return or two carriage returns. Carriage returns are the “backslash n” you see embedded in this string. Sentences have a period at the end, but also, have a space.and words are separated by space.’]
如果需要按照句子进行分隔,则还要用正则表达式添加一个句号分隔符:
ini复制代码r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["nn", "n", "(?<=. )", " ", ""]
)
r_splitter.split_text(some_text)
[“When writing documents, writers will use document structure to group content. This can convey to the reader, which idea’s are related.”,
‘For example, closely related ideas are in sentances. Similar ideas are in paragraphs. Paragraphs form a document.’,
‘Paragraphs are often delimited with a carriage return or two carriage returns.’,
‘Carriage returns are the “backslash n” you see embedded in this string.’,
‘Sentences have a period at the end, but also, have a space.and words are separated by space.’]
这就是递归字符文本分割器名字中“递归”的含义,总的来说,我们更建议在通用文本中使用递归字符文本分割器。
基于Token的分割
很多LLM的上下文窗口长度限制是按照Token来计数的。因此,以LLM的视角,按照Token对文本进行分隔,通常可以得到更好的结果。
为了理解基于字符分割和基于Token分割的区别,我们可以用一个简单的例子来说明。
ini复制代码from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text1 = "foo bar bazzyfoo"
text_splitter.split_text(text1)
这里,我们创建了一个Token文本分割器,将块大小设为1,块重叠大小设为0,相当于将任意字符串分割成了单个Token组成的列表,每个Token的内容如下:
css复制代码['foo', ' bar', ' b', 'az', 'zy', 'foo']
因此,Token的长度和字符长度是不一样的,Token通常为4个字符。
分割Markdown文档
分块的目的旨在将具有共同上下文的文本放在一起。
通常,我们可以通过使用指定分隔符来进行分隔,但有些类型的文档(例如 Markdown)本身就具有可用于分割的结构(如标题)。
Markdown标题文本分割器会根据标题或子标题来分割一个Markdown文档,并将标题作为元数据添加到每个块中。
步骤1:定义一个Markdown文档
swift复制代码from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = """# Titlenn
## Chapter 1nn
Hi this is Jimnn Hi this is Joenn
### Section nn
Hi this is Lance nn
## Chapter 2nn
Hi this is Molly"""
步骤2:定义想要分割的标题列表和名称
ini复制代码headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
步骤3:初始化Markdown标题文本切分器,分割Markdown文档
css复制代码markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits[0]
# Document(page_content='Hi this is Jim nHi this is Joe', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1'})
md_header_splits[1]
# Document(page_content='Hi this is Lance', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1', 'Header 3': 'Section'})
可以看到,每个块都包含了页面内容和元数据,元数据中记录了该块所属的标题和子标题。
我们已经了解了如何将长文档分割为语义相关的块,并且包含正确的元数据。下一步则是将这些分块后的数据移动到向量存储中,以便进行检索或生成,敬请期待。
