

随着科技的发展,处理大量数据和进行复杂计算的需求越来越高,人工智能、大数据和物联网等领域更是如此,传统的计算方式已经无法满足这些需求。因此,加速计算作为一种现代计算方式,成了必要的手段。加速计算具有前所未有的处理能力,在云基础设施中发挥着核心作用,因为它有助于更高效、更有效地管理数据中心的海量信息。此外,加速计算还能提供必要的计算能力和内存,以便更高效地训练和实施 GPT-4 等高级生成式人工智能模型。这种能力可加快训练时间、处理大型数据集和开发日益复杂的模型。
加速计算利用 GPU、ASIC、TPU 和 FPGA 等专用硬件来执行比 CPU 更高效的计算,从而提高速度和性能。它尤其适用于可并行化的任务,如高性能计算、深度学习、机器学习和人工智能。
加速计算发展迅速,各种硬件和软件解决方案如 GPU、ASIC、TPU、FPGA、CUDA、OpenCL 和网络技术层出不穷。下面我们来深入了解一下加速计算,就能明白为何它会成为 AI 时代的计算力“新宠”。
什么是加速计算
加速计算是指使用专用硬件来执行某些类型的计算,其效率要比仅使用通用中央处理器(CPU)高。利用图形处理单元(GPU)、专用集成电路(ASIC)(包括张量处理单元(TPU))和现场可编程逻辑门阵列(FPGA)等设备的强大功能,以更高的速度执行计算,从而加速计算过程,一般我们也将这些设备称之为加速器。
这些加速器尤其适用于可被分解为较小并行任务的项目,如高性能计算 (HPC)、深度学习、机器学习、人工智能和大数据分析。通过将指定类型的工作分派到这些专用加速计算硬件上,大大提高了系统的性能和效率。
加速计算因其高效处理海量数据的能力,从而推动了机器学习、AI、实时分析和科学研究的进步。加速计算在图形、游戏、边缘计算和云计算领域的影响力与日俱增,是数据中心等数字基础设施的骨干力量。随着对更强大应用和系统的需求日益增长,传统的 CPU 方法难以与加速计算竞争,而加速计算可提供更快、更具成本效益的性能升级。
加速计算解决方案
加速计算解决方案涉及硬件、软件和网络的结合。这些解决方案专门用于提高复杂计算任务的速度和效率。
硬件
硬件加速器是加速计算的基础,这些加速器包括图形处理器 (GPU)、专用集成电路 (ASIC) 和现场可编程门阵列 (FPGA)。
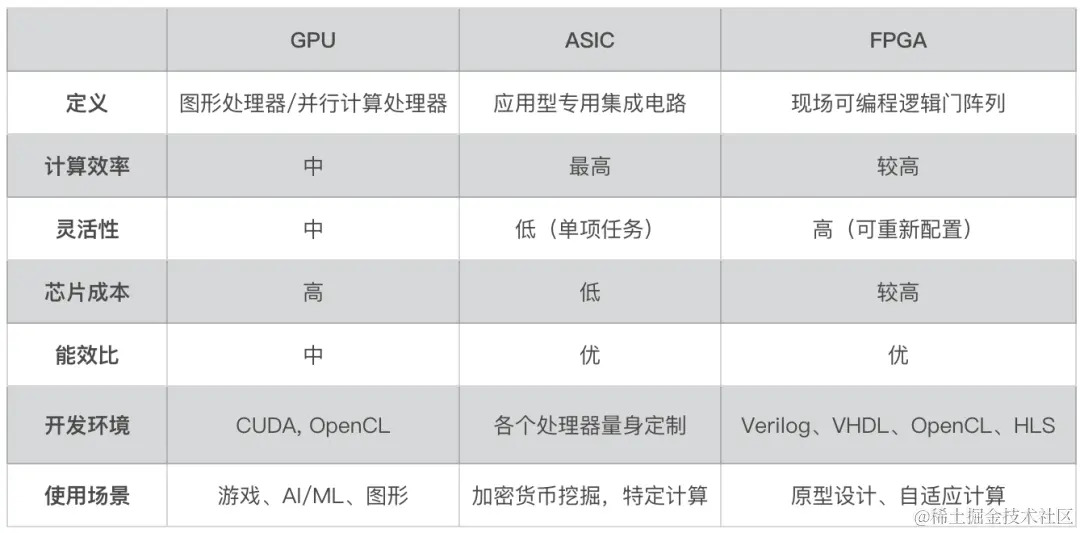
GPU
图形处理器(GPU)广泛用于各种计算密集型任务,其优势在于可以同时执行许多复杂的计算,因此非常适合高性能计算(HPC)和机器学习中的神经网络训练等任务。
英伟达公司数据中心和计算密集型任务(机器学习、人工智能)的 GPU 市场上处于领先地位。该公司用于数据中心的主要 GPU 架构包括 Hopper (H100) 和 Ampere (A100)。值得一提的是,H100 GPU 非常适合加速涉及大型语言模型 (LLM)、深度推荐系统、基因学和复杂数字孪生的应用。
**应用型专用集成电路 ASIC ** 应用型专用集成电路(ASIC)是为执行特定任务而设计的定制芯片,与 CPU 不同, CPU 可处理各种应用。由于专用集成电路是为特定功能定制的,因此执行任务的效率比 CPU 更高,在速度、功耗和整体性能方面都具有优势。
我们常常在科技文章中看到的神经处理单元(NPU)和深度学习处理器(DLP)就是 ASIC 中的一员,还有谷歌的张量处理单元(TPU)也是 ASIC 下的一员猛将。TPU 专为加速机器学习工作荷载而设计,它们被广泛应用于语言翻译、谷歌助手中的语音识别和智能化广告排名等项目中。
现场可编程逻辑门阵列 FPGA
现场可编程逻辑门阵列(FPGA)是一种半导体集成电路,与 CPU 相比,FPGA 可重新编程以便能更高效地执行特定任务。与 ASIC、GPU 和 CPU 的固定架构不同,FPGA 硬件包括可配置逻辑块和可编程互连。这样,即使在芯片出厂和部署后,也可以进行功能更新。
FPGA 凭借其灵活性和并行计算能力,在数据中心的高性能计算、AI、机器学习中越来越受欢迎。不过,与 GPU 和定制 ASIC 解决方案相比,FPGA 的开发速度较慢,其软件生态系统目前也不够健全,由于其编程复杂,专业工程师的数量也很有限。
软件
加速计算利用应用编程接口(API)和编程模型(如 CUDA 和 OpenCL)来连接软件和硬件。这样可以优化数据流,从而提高性能、能效、成本效益和准确性。开发人员通过 API 和编程模型,就能够编写在 GPU 上运行的代码,并利用软件程序库实现高效算法。
CUDA
CUDA(全称为 Compute Unified Device Architecture,统一计算架构)是英伟达公司开发的专有并行计算平台和 API 模型,通过这个技术,开发者可利用英伟达的 GPU 进行图像处理之外的运算,显著加速计算任务。该平台包括 cuDNN、TensorRT 和 DeepStream 等深度学习库,可增强人工智能训练和推理任务。
自 2006 年推出以来,CUDA 已被下载 4000 万次,在全球拥有 400 万开发者用户群,已形成了一个庞大的开发者社区,因此英伟达公司在数据中心硬件和软件市场上占据了显著优势。
OpenCL
OpenCL(Open Computing Language,开放计算语言)是一个为异构平台编写程序的框架。OpenCL 的一个特别显著的特点是它在不同硬件类型之间的可移植性,平台可由 CPU、GPU、FPGA 或其他类型的处理器与硬件加速器所组成。其广泛的兼容性使开发人员能够利用这些不同硬件的强大功能,来进行加速计算。
网络
网络在加速计算中发挥着至关重要的作用,因为它有助于成千上万个处理单元和内存以及存储设备之间的通信。各种网络技术被用来实现这些计算设备与系统其他设备之间的通信,并在网络内的多个设备之间共享数据。常见的技术有:
- PCI Express(PCIe):PCIe 是计算机总线的一个重要分支,它沿用既有的 PCI 编程概念及信号标准,并且构建了更加高速的串行通信系统标准。这一标准提供了计算设备与 CPU、内存之间的直接连接。在加速计算中,PCIe 通常用于将 GPU 或其他加速器连接到主机系统。
- NVLink:英伟达公司专有的高带宽、高能效互连技术,可提供比 PCIe 高得多的带宽。该技术旨在促进 GPU 之间以及 GPU 与 CPU 之间更高效的数据共享。
- Infinity Fabric:AMD 公司专有的互连技术,用于连接其芯片中的各种组件,包括 CPU、GPU 和内存。
- Compute Express Link (CXL):CXL 是一种开放式互连标准,有助于减少 CPU 和加速器之间的延迟同时增加带宽。它将多个接口合并为一个 PCIe 接口,连接到 CPU。
- InfiniBand:一种高速、低延迟的互连技术,通常用于高性能计算(HPC)设置。它实现了服务器集群和存储设备之间的高速互连。
- 以太网:应用最广泛最成熟的网络技术,主要用于在数据中心的服务器之间传输大量数据。但是,它无法提供与 NVLink 或 InfiniBand 相同的性能水平。
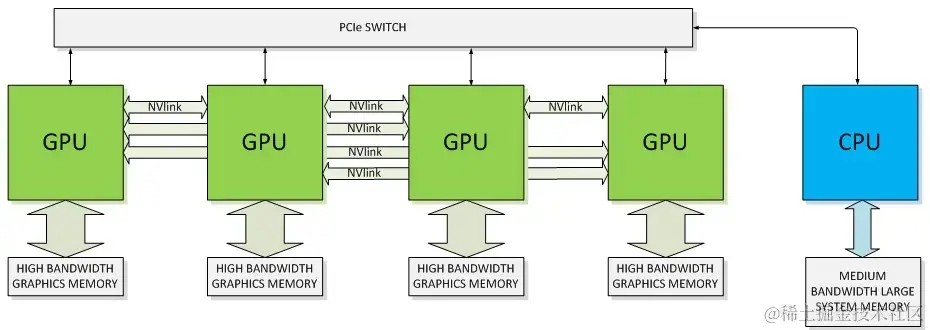
△ NVLink 和 PCIe 与 CPU 连接的 GPU 架构
加速计算应用场景
生成式AI
加速计算是开发和实施先进的生成式 AI 模型的关键因素。生成式 AI 涉及使用算法来统计特征上与训练集相似的数据,在图像、文本和语音领域都有广泛应用。
在生成式 AI 领域,会用到生成对抗网络(GANs)、变异自动编码器(VAEs)和变换器(Transformers)等模型,还有包括 OpenAI 的 ChatGPT 的大型语言模型(LLMs)。这些模型所涉及到的复杂数学运算,需要在大型数据集上进行训练,并需要大量的计算能力和内存。更具体地说,模型大小、每层复杂度、序列长度和多样化是计算需求日益增加的最主要因素。
加速计算在解决生成式 AI 的计算能力和内存需求方面发挥着至关重要的作用,其主要作用在加快训练时间、处理大型数据集、支持复杂模型、促进实时生成并保障高效梯度计算。
加快训练时间
加速计算在生成式 AI 中最重要的作用是缩短 GAN、VAE 和 Transformer 模型的训练时间。在基于 CPU 的传统架构上,这些模型的训练通常需要数天、数周甚至数月的时间,但 GPU 和 TPU 等加速计算平台是专为并行处理而设计的加速硬件,它们能够同时并行处理多个计算,从而大大缩短了训练时间。
处理大型数据集
生成式 AI 模型通常在海量数据集上进行训练,与传统 CPU 相比,加速计算硬件可以更高效地处理这些大型数据集。此外,使用先进的内存架构(如某些 GPU 中的高带宽内存)可以在训练过程中高效处理这些大型数据集。
创建复杂模型
加速计算所带来的计算能力的提升,可以创建更复杂、更大型的模型,从而获得更好的结果。例如,像 GPT-4 这样拥有 170 万亿个参数的生成型预训练变换模型,只有通过加速计算才能实现。
实时功能
在某些应用中,人工智能模型需要实时(或接近实时)生成输出。这对于交互式应用(如视频游戏中的人工智能和实时翻译)尤为重要。加速计算可确保快速执行这些操作,从而实现实时功能。
高效的计算梯度
深度学习模型通过使用基于梯度的优化技术(如反向传播)进行学习。这些计算方法以误差或损失函数最小化的方向来迭代调整模型参数。由于计算是基于矩阵的,因此具有很高的并行性,非常适合选用加速计算方案来处理。
AI数据中心
加速计算平台的目的是加速各类数据中心的计算密集型工作,包括人工智能、数据分析、图形和科学计算。这些数据中心包括企业、主机托管、超大规模/云、边缘和模块化设施,其主要目标是提高工作负载性能,同时降低功耗和每次查询的成本。
生成式 AI 和大型语言模型(LLM)在消费者、互联网公司、企业和初创公司中的兴起,使人工智能的应用进入了一个快速发展时刻,加速了数据中心和云平台中的 AI 推理部署。目前,大多数 AI 推理工作都部署在 CPU 和网络接口卡(NIC)上运行。然而,由于性能、能效、成本效益和功耗限制的日益增加,业界正在转向利用 GPU 和 ASIC 等专用硬件进行加速计算。
现代数据中心的发展方向之一,就是建立一个可持续运行的 ” AI 工厂”。通过 LLM、推荐系统以及最终的推理模型等人工智能模型,配备推理机群,以便支持各种各样的工作任务,例如视频处理、文本生成、图像生成以及虚拟世界和虚拟 3D 图形。
使用GPU进行加速计算
使用 GPU 进行加速计算方法主要有三大类:
- 使用商业套装软件
- 使用开源或官方函式库
- 自行编程 CUDA
第一项种类繁多,其中又以有限元素分析领域最多,此领域相关计算包含流体力学分析、热传导分析、电磁场分析或应力分析等等应用。由于范围涵盖 IC 设计、建筑设计、甚至许多交通工具或化工厂也需要通过这类软件进行模拟分析,所以开发这类软件有很大的商业价值。
第二项则比较个性化,由开发者自行编写程序,GPU 的计算组件则可以引用他人已经准备好的函数库,或者参考英伟达官方提供的函数库,也可以从 GitHub 上进行搜索。
第三项就必须通过编程语言进行 CUDA 编写,不同的编程语言能够操纵的自由度也各不相同,其中 C/C++ 或 Fortran属于开发自由度最高的编程语言,可从底层控制 GPU 计算,甚至可以针对本机内存与 GPU 内存数据的传输进行优化。其次则为 Python,Python 也是目前市面上最主流的 AI 应用开发语言,实现的方式包括 PyCuda 或者使用Numba 函数库。另外,Java、R、C# 等也都可以支持 CUDA。
又拍云联合厚德云推出 GPU 产品,可方便快捷一键搭建 CUDA 、Stable Diffusion 等开发环境,现活动期间新用户注册即可免费体验 RTX4090 GPU。
