


在过去的一周,世界见证了两家科技巨头最具突破性的人工智能进步。OpenAI 推出了令人惊叹的 AI 视频生成器 Sora,而 Google 推出了 Gemini 1.5 模型,能够支持多达 100 万个 Token 上下文。
Gemma,是一个轻量级、最先进的开源模型系列,它建立在用于创建 Gemini 模型的研究和技术的基础上。
什么是Gemma
Gemma 是以拉丁语 gemma 命名,意思是宝石 ,Gemma 从其前身 Gemini 中汲取灵感,反映了它在科技界的价值和稀有性。
它们是文本到文本、仅限解码器的大型语言模型,提供英语版本,具有开放权重、预训练变体和指令调整变体。
Gemma 已经开始在全球范围内提供两种大小 2B 和 7B,支持多种工具和系统,并可以在开发人员笔记本电脑和工作站上运行。
2 种模型大小和功能
Gemma 模型有 20 billion 和 70 billion 参数大小可供选择。 2B 模型旨在移动设备和笔记本电脑上运行,而 7B 模型旨在台式计算机和小型服务器上运行。
调整模型
Gemma 也有两个版本:调整版和预训练版。
- 预训练:没有任何微调的基本模型。该模型未针对 Gemma 核心数据训练集之外的任何特定任务或指令进行训练。
- 指令调整:针对人类语言交互进行了微调,提高了其执行目标任务的能力。
与竞争对手相比?
由于 Gemma 体积小,因此能够直接在用户的笔记本电脑上运行。下图显示了 Gemma(7B)的语言理解和生成性能与 LLaMA 2 (7B)、LLaMA 2(13B) 和 Mistral(7B)等类似大小的开放模型的比较。
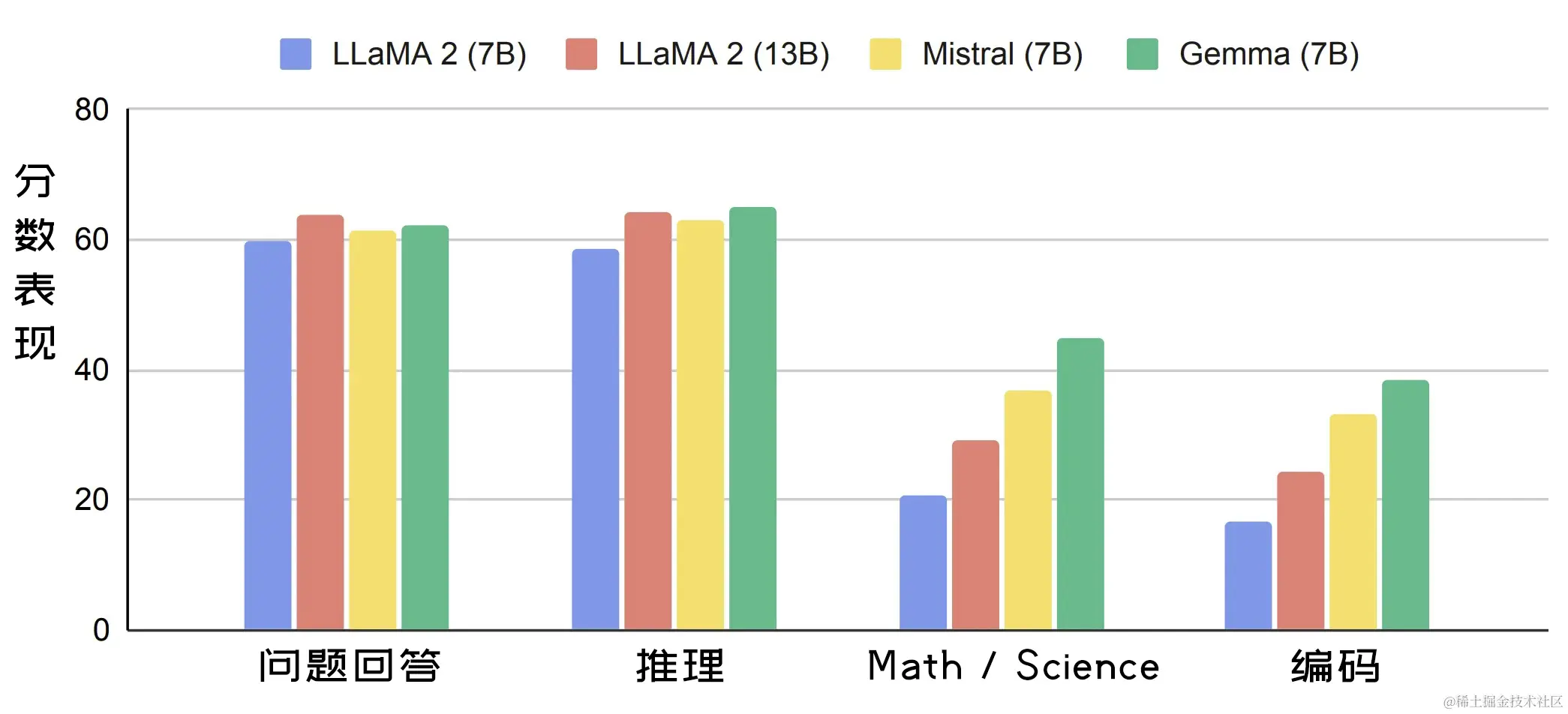
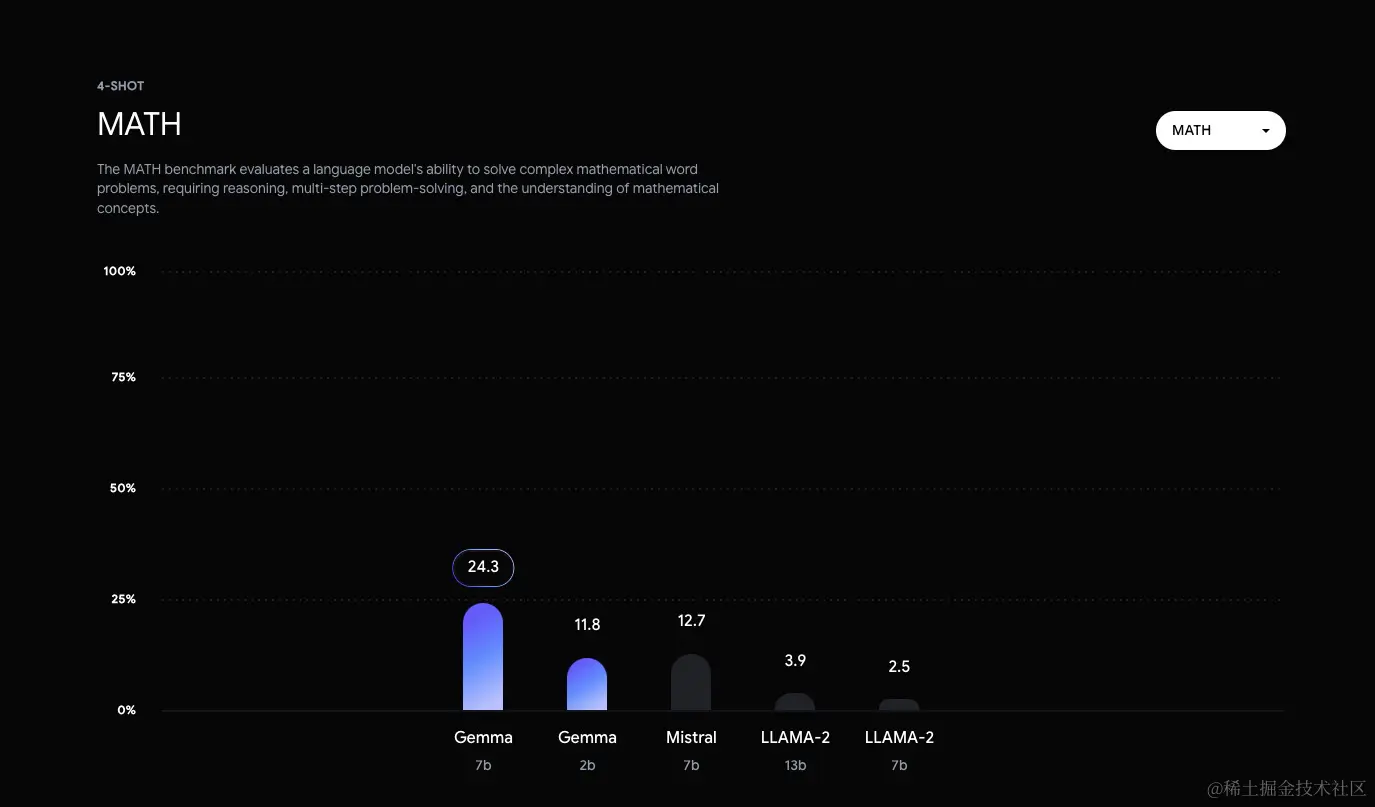
可以在此处查看每个基准的更详细比较。
Gemini 1.5 有什么新功能?
Gemini 1.5 提供了重大增强功能,旨在解决初始版本的缺点:
1,000,000个Token上下文:这是目前任何大型基础模型中最大的上下文。 OpenAI 的 GPT-4 具有128K上下文。- 将有更快的响应:谷歌正在采用可能为 GPT-4 提供支持的专家混合 MoE 架构,使得模型能够将提示分解为子任务并将其路由给专门的“专家”,从而显着提高效率和性能。
- 快速信息检索:新模型展示了在大量文本、视频或音频数据中精确定位特定细节的能力显着提高。
- 更擅长编码:大型上下文可以对整个代码库进行深入分析,帮助 Gemini 模型掌握复杂的关系、模式和对代码的理解。
可以用来做什么?
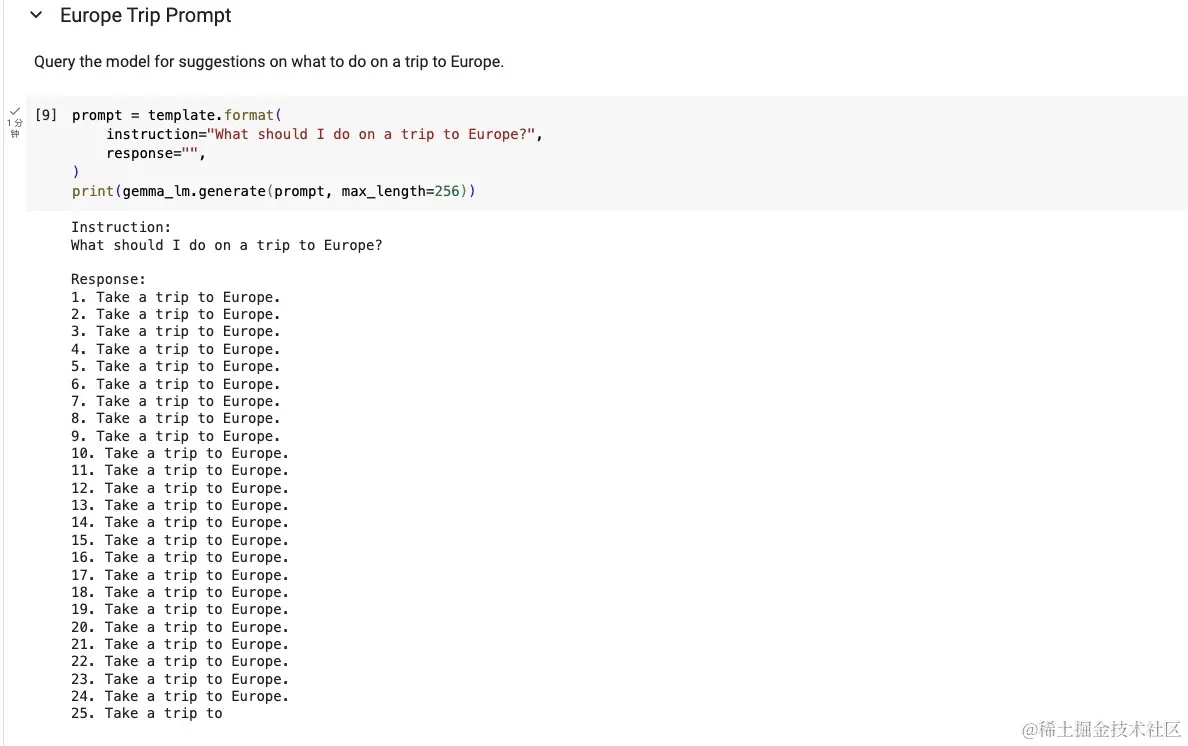
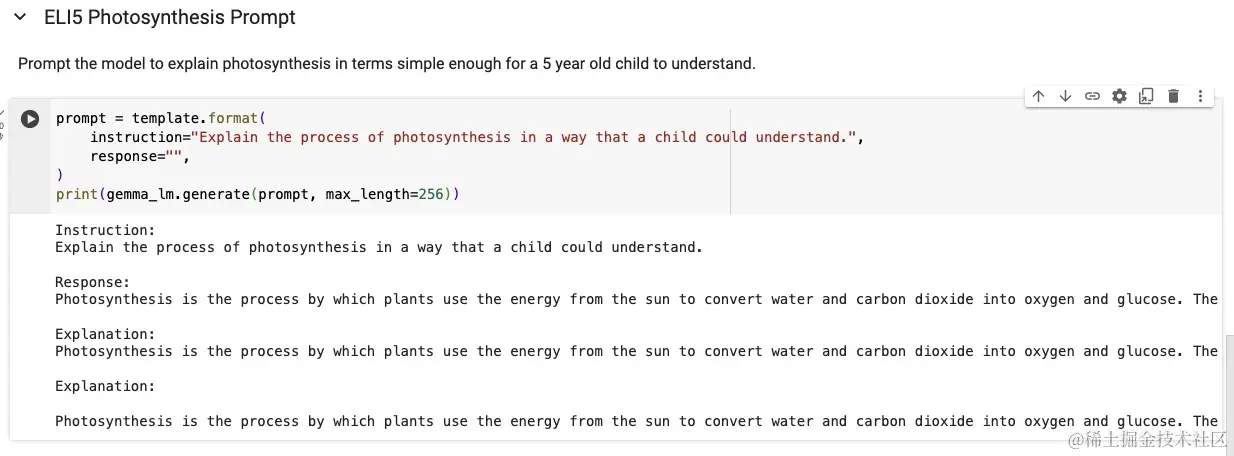
以下是 Gemma 的一些可能的使用场景:
内容创作与传播
- 文本生成
- 聊天机器人和对话式人工智能
- 文本摘要
研究与教育
- 自然语言处理 (NLP)研究:作为 NLP 研究的基础,试验技术、开发算法并为该领域的进步做出贡献。
- 语言学习工具:支持交互式语言学习体验、帮助语法纠正或提供写作练习。
- 知识探索:通过生成摘要或回答有关特定主题的问题,帮助研究人员探索大量文本。
以前需要非常大的模型的任务现在可以使用最先进的、更小的模型。这开启了开发 AI 应用程序的全新方式,很快就可以在智能手机上看到设备内的 AI 聊天机器人——不需要互联网连接。
尝试开始
Gemma 模型可以从 Kaggle Models 下载运行。
进入页面后,选择 Code 标签:
随便选择一个点击进去,这里选择第一个:
总结
虽然 Gemma 模型可能很小并且缺乏复杂性,但它们可以在速度和使用成本方面弥补这一点。
从更大的角度来看,谷歌不是追逐消费者眼前的兴奋,而是为企业培育市场。设想一下,当开发人员使用 Gemma 创建创新的新消费者应用程序时,公司会为 Google Cloud 服务付费。
