


距离破解大模型「黑箱」难题又近了一步!近日,来自 Anthropic 的研究团队通过采用稀疏自动编码器的弱字典学习算法,从 512 个神经元中提取出来了 4000 多个可解释特征。
长久以来,我们都无从理解 AI 是如何进行决策和输出的。
模型开发人员只能决定算法、数据,最后得到模型的输出结果,而中间部分——模型是怎么根据这些算法和数据输出结果,就成为了不可见的「黑箱」。

所以就出现了「模型的训练就像炼丹」这样的戏言。
但现在,模型黑箱终于有了可解释性!
来自 Anthropic 的研究团队提取了模型的神经网络中最基本的单位神经元的可解释特征。

这将是人类揭开 AI 黑箱的里程碑式的一步。
Anthropic 激动地表示:
「如果我们能够理解模型中的神经网络是如何工作的,那么诊断模型的故障模式、设计修复程序,并让模型安全地被企业和社会采用就将成为触手可及的现实!」
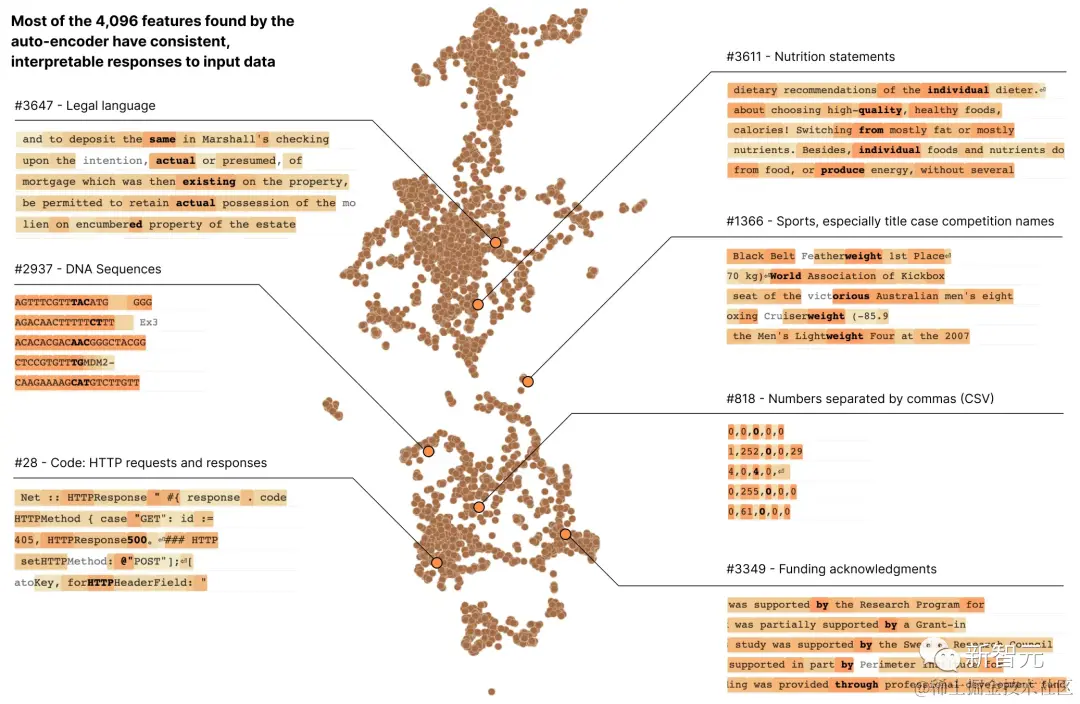
在 Anthropic 的最新研究报告,Towards Monosemanticity: Decomposing Language Models With Dictionary Learning(《走向单语义性:用字典学习分解语言模型》),研究人员通过字典学习将包含 512 个神经元的层分解出了 4000 多个可解释的特征。

研究报告地址:transformer-circuits.pub/2023/monose…
这些特征分别表示 DNA 序列,法律语言,HTTP 请求,希伯来文本,营养成分说明等。
当孤立地观察单个神经元的激活时,这些模型属性中的大多数都是不可见的。
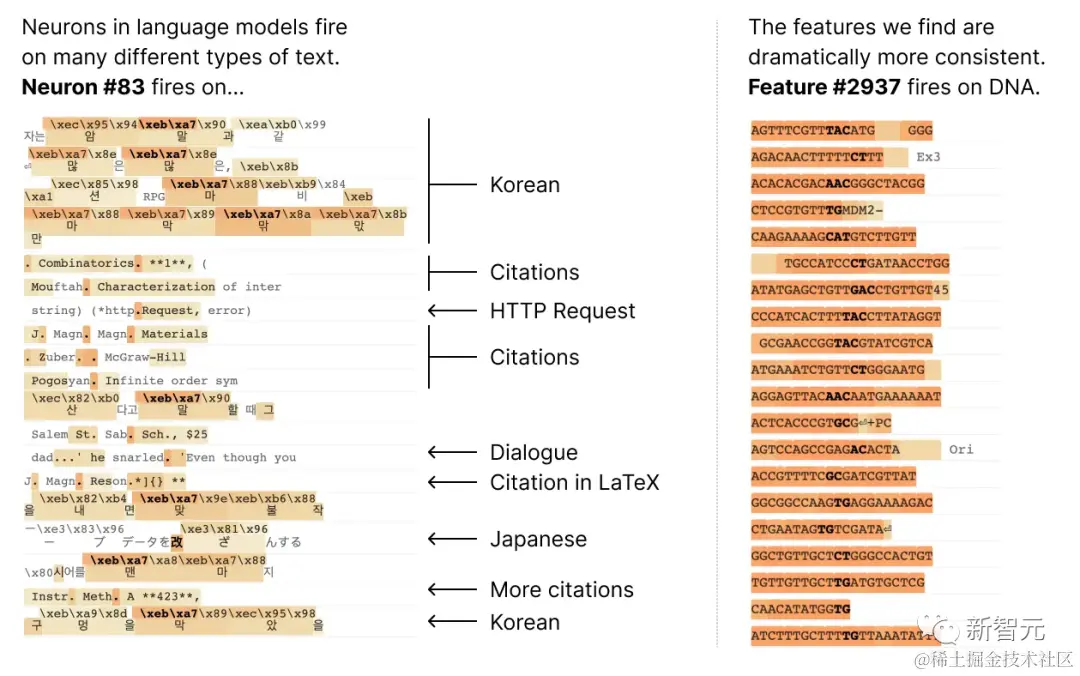
这是由于大多数神经元都是「多语义」的,单个神经元与网络行为没有对应一致的关系。
例如,在一个小型语言模型中,单个神经元在许多不相关的上下文中都很活跃,包括:学术引文、英语对话、HTTP 请求和韩语文本。
而在经典视觉模型中,单个神经元会对猫的脸和汽车的前脸做出反应。
不少研究都证实了一个神经元的激活在不同的语境中可能意味着不同的含义。
而神经元多语义的一个潜在原因是叠加,这是一种假设的现象,即神经网络通过为每个特征分配自己的神经元线性组合,来表示数据的独立「特征」多于它的神经元数量。
如果将每个特征视为神经元上的一个向量,那么特征集就构成了网络神经元激活的一个过完备线性基础。
在 Anthropic 之前的 Toy Models of Superposition(《叠加玩具模型》)论文中,证明了稀疏性在神经网络训练中可以消除歧义,帮助模型更好地理解特征之间的关系,从而减少激活向量的来源特征的不确定性,使模型的预测和决策更可靠。
这一概念类似于压缩感知中的思想,其中信号的稀疏性允许从有限的观测中还原出完整的信号。

但在 Toy Models of Superposition 中提出的三种策略中:
(1)创建没有叠加的模型,或许可以鼓励激活稀疏性;
(2)使用字典学习在表现出叠加态的模型中寻找过完备特征;
(3)依赖于两者结合的混合方法。
方法(1)不足以防止多义性,方法(2)则存在着严重的过度拟合问题。
因此,这次 Anthropic 的研究人员使用了一种称为稀疏自动编码器的弱字典学习算法,从经过训练的模型中生成学习到的特征,这些特征提供了比模型神经元本身更单一的语义分析单位。
具体来说,研究人员采用了具有 512 个神经元的 MLP 单层 transformer,并通过从 80 亿个数据点的 MLP 激活上训练稀疏自动编码器,最终将 MLP 激活分解为相对可解释的特征,扩展因子范围从 1×(512 个特征)到 256×(131,072 个特征)。
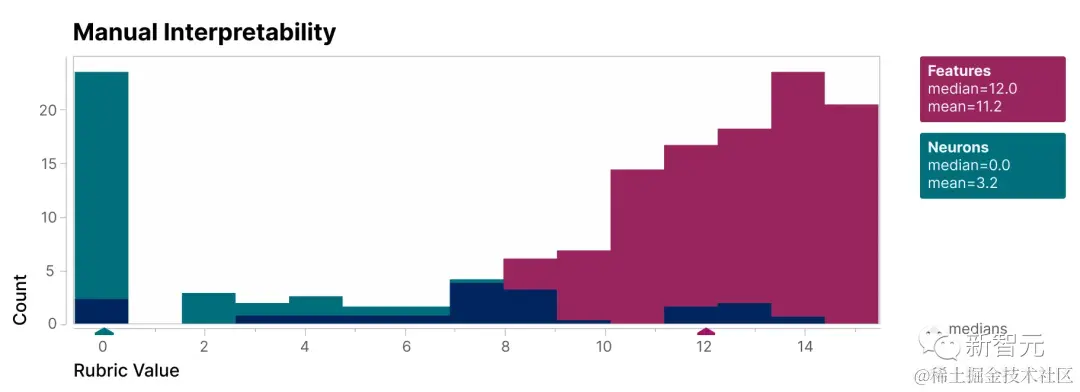
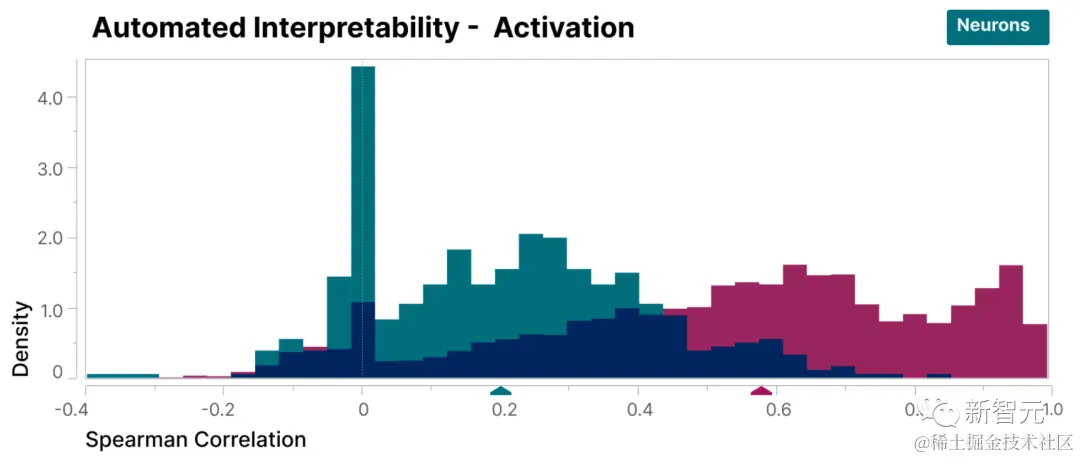
为了验证本研究发现的特征比模型的神经元更具可解释性,采用了盲审评估,让一位人类评估员对它们的可解释性进行评分。
可以看到,特征(红色)的得分比神经元(青色)高得多。
证明了研究人员找到的特征相对于模型的内部神经元来说更易理解。
此外,研究人员还采用了「自动解释性」方法,通过使用大型语言模型生成小型模型特征的简短描述,并让另一个模型根据该描述预测特征激活的能力对其进行评分。
同样,特征得分高于神经元,证明了特征的激活及其对模型行为的下游影响具有一致的解释。
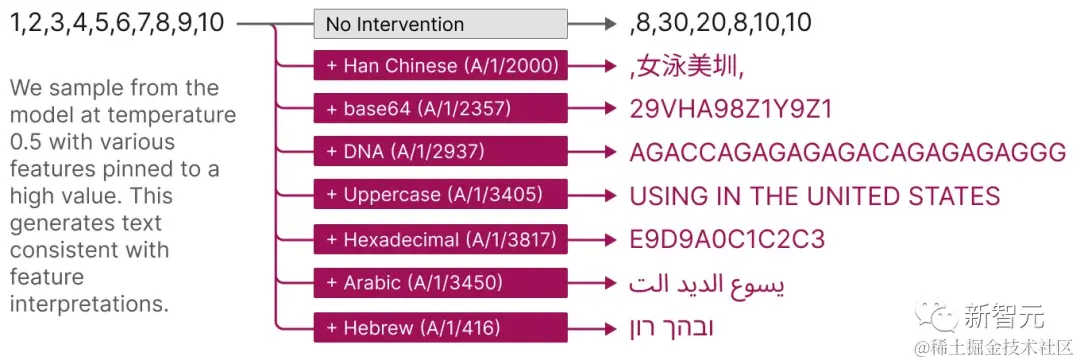
并且,这些提取出的特征还提供了一种有针对性的方法来引导模型。
如下图所示,人为激活特征会导致模型行为以可预测的方式更改。
这些被提取的可解释性特征可视化图如下:
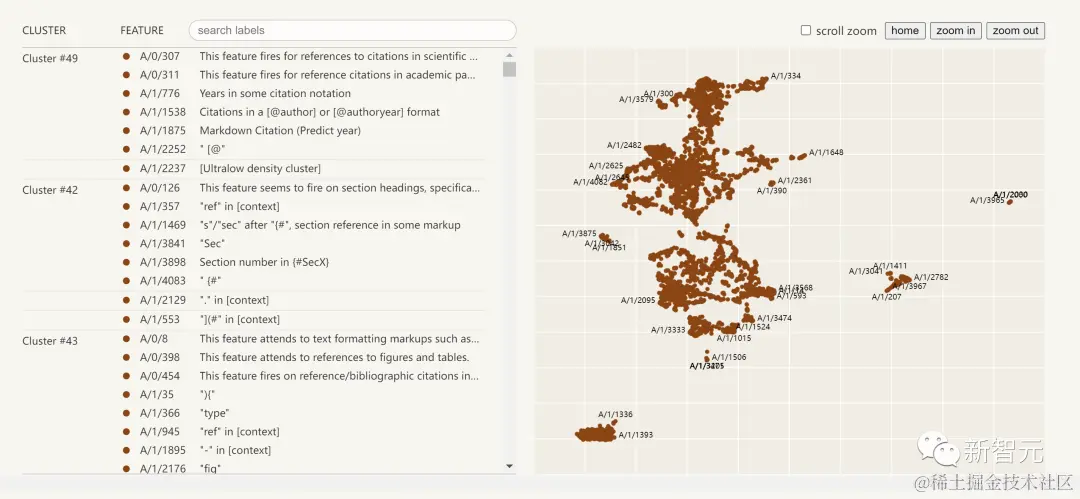
点击左边的特征列表,就能与神经网络中的特征空间进行交互式探索。
研究报告概要
这份来自 Anthropic 的研究报告,Towards Monosemanticity: Decomposing Language Models With Dictionary Learning,主要可以分为四个部分。
问题设置,研究人员介绍了研究动机,并阐述训练的 transfomer 和稀疏自动编码器。
单个特征详细调查,证明了研究发现的几个特征是功能上特定的因果单元。
全局分析,论证了典型特征是可解释的,并且它们可以解释 MLP 层的重要部分。
现象分析,描述了特征的几个属性,包括特征分割、普遍性,以及它们如何形成类似于「有限状态自动机」的系统来实现复杂的行为。
结论包括以下 7 个:
-
稀疏自动编码器能提取相对单一的语义特征。
-
稀疏自编码器能产生可解释的特征,而这些特征在神经元基础中实际上是不可见的。
-
稀疏自动编码器特征可用于干预和引导变压器的生成。
-
稀疏自编码器能生成相对通用的特征。
-
随着自动编码器大小的增加,特征有「分裂」的倾向。
-
仅 512 个神经元就能代表数以万计的特征。
-
这些特征在类似「有限状态自动机」的系统中连接起来,从而实现复杂的行为,如下图。
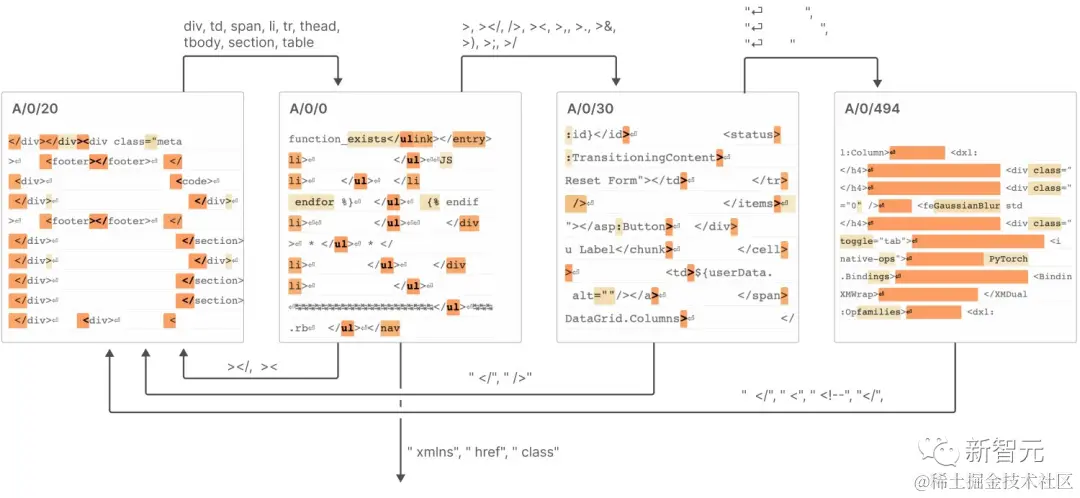
具体详细内容可见报告。
但对这份研究报告,Anthropic 认为想要将本研究报告中小模型的成功复制到更大的模型上,我们今后面临的挑战将不再是科学问题,而是工程问题。
而这意味着为了在大模型上实现解释性,需要在工程领域投入更多的努力和资源,以克服模型复杂性和规模带来的挑战。
包括开发新的工具、技术和方法,以应对模型复杂性和数据规模的挑战;也包括构建可扩展的解释性框架和工具,以适应大规模模型的需求。
这将是解释性 AI 和大规模深度学习研究领域的最新趋势。
参考资料:
transformer-circuits.pub/2023/monose…
