

前言
不管你承不承认,ai的时代已经到来了。个人看来,chatgpt具有划时代的意义,更甚于蒸汽机的发明。
chatgpt发布仅仅一年的时间,已经充斥在了互联网的方方面面。国内大厂也是纷纷跟风,厂均一个大模型。这里就得吐槽一下,虽然国内大模型数量众多,但质量明显不高,且很多存在套壳嫌疑。
你对大模型的印象是否还停留在聊天阶段?实际上大模型的发展可能已经远远超乎你我的预料。
本文重应用和场景,有少量代码帮助理解,还有一些个人的测试结论。
system/prompt
在和模型聊天的时候,可以预先给模型立个人设,让它以固定的身份,风格来对话。 比如在和模型对话的时候,可以这样调用:
- 通过system设置模型身份是一个助手
curl https://api.openai.com/v1/chat/completions
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Who won the world series in 2020?"
}
]
}'
这个功能是大模型得以在多方面应用的基础。不需要编程技术,只需要写一段人设,或者一段约束,就可以自定义一个特定功能的聊天机器人。
在工程应用上,prompt是非常重要的一块,下面实例会有讲到。
function call / 插件
如果说大模型相当于人的大脑,那function call就相当于人的手脚。通过这个功能,可以将大模型的思考的结果加以实施。chatgpt上的插件本质都是function call。
比如,用户的问题是今天天气怎么样?。显然模型是不知道今天天气如何的,但是我们告诉它,你可以通过什么方法来查询天气。这个时候模型会判断,如果需要查询天气,则应该调用该方法,并且把参数也按照要求告诉我们。
看api,在请求模型的时候带上tools
request.tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location."
},
"required": ["location"],
},
},
}
]
# 返回值 choices的 message 会有如下的结构
{
'role': 'assistant',
'content': None,
'tool_calls': [{
'id': 'call_o7uyztQLeVIoRdjcDkDJY3ni',
'type': 'function',
'function': {
'name': 'get_current_weather',
'arguments': '{n "location": "Glasgow, Scotland",n "format": "celsius"n}'
}
}]
}
知道这个函数调用之后,就可以调用我们自己的函数实现开始查询天气了。
embedding
在传统的推荐系统里,最重要的一步就是item向量化(embedding)。大模型在理解我们的文本时,也是要先进行向量化的,那我们就可以利用大模型来实现embedding。
比如我们传一段文本到大模型里
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-ada-002"
)
print(response.data[0].embedding)
我们就会得到一个embedding后的结果。
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
Fine-tuning
如果对模型不满意,可以直接对模型进行参数调整,当然大多数情况下,并不会用到这种方式。
图片生成和理解
日常聊天中,图片也是很重要的内容,chatgpt刚发布图片理解能力的时候,属实惊讶到我。
只需要问模型图片是啥意思?,并且带上图片的链接或内容。官网推荐的理解模型是gpt-4-vision-preview。
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
至于chatgpt的图片生成 DALL·E 3,请无视吧,并左转去找 midjourney
模型
在说具体的模型之前,先说一下 窗口 和 tokens。
大模型并不能无限的对话,就像打工人开会,开一个小时之后,前面的内容几乎都忘记了。而这个记忆的内容大小称为窗口。
模型也并不能直接理解人类的话,需要先分词转成tokens,至于具体的分词方法,参考这里。
常说的窗口大小为8k 16k 32k,就是指tokens的大小为8*1024 16*1024 32*1024。截止目前,最新的模型出到了 gpt-4-1106-preview可以放 128000 tokens。
比较推荐的模型是gpt-4-32k,逻辑性和准确率相对较好。
图片理解模型用官方主推的 gpt-4-vision-preview。
gpt3.5 推荐用gpt-3.5-turbo-16k,虽然tokens小,但反应快,在request比较大的时候,速度是gpt-4-32k 2到3倍。
embedding模型,如果你喜欢gpt则用text-embedding-ada-002,中文还是推荐moka的m3e模型。
如何让模型对不同的人表现出差异化?
模型是通过prompt来确定人设的,那么可以通过动态生成prompt来实现,个性化回复。
比如上面那个询问天气的问题,对于不同城市的人来说就需要不同的回复。这要求在我们和模型会话时告诉模型,我当时的地理信息。而这个信息可以在prompt中上报,并且做到无感。
此外prompt不光可以在system中定义,也可以在user中增加多重定义来实现个性化需求。
模型记忆力过短的问题?
这主要有两方面的问题:
- 模型窗口有限制,导致上文超出窗口,以致记忆缺失。
这种情况可以换更大窗口的模型,或者优化对话结构。需要注意,越大的窗口处理速度越慢。并且窗口最终还是会迎来上限。
- 时间空间维度过长,模型记忆丢失,比如我在三个月前告诉过模型,我叫xxx,三个月之内对话了很多次,再问模型的时候,模型已经不知道了。
这种情况可以通过 function call的功能来解决,在用户告诉我们姓名时 记录在数据库里。每个新的会话中在prompt中指定。
企业私有的数据应该如何让模型知道?
一种方法是利用自己的数据对模型进行微调,这种对于情感类数据较为有效。比如一个情感助手,在对话中扮演一个小姐姐的角色,你可以用小姐姐的文本来训练模型该如何回复。
另一种是推荐类的数据,可以用向量库的方式接入模型。比如新闻类数据,用户对话新闻助手给我推荐三条时下热门新闻。这种情况下可以先利用大模型的embedding能力,在向量库中先一轮召回一定数目的新闻,再调用大模型进行语义处理。参考langChain框架
如何让模型化被动为主动?
现在的主流,依然是人主动和模型对话,那模型可以主动和人说话吗?
这还是需要function call来实现。
比如用户在对话时下达命令在三个小时后,帮我订一份肯德基。在轮对话中模型识别到用户的意图是在三个小时后触发,会调用我们预设的定时任务的function 下达一个定时任务。三个小时后自动触发。
如何让模型更人性化?更像一个人?如何适应更复杂的场景?
在上面的几个例子中,我们发现每一个任务,都需要模型和各种插件的配合才能完成工作。为了能够让他们更好的协作。我们可以将他们组成工作流,来完成更复杂的工作,或者表现的更人性化。
还是查询天气的例子,在我们调用查询天气的插件后,返回的内容是一个json 或者一段文本。如果直接把文本给用户看到,是十分粗糙 且难以理解的。这个时候就需要将查询结果再过一遍大模型。得到一段更人性化,更容易理解的回答,
比如上海今天多云,最低温度-2℃,最高温度2℃,建议着厚羽绒服等隆冬服装;体弱者尽量少出门。,这就是按照人设回复的内容。
而不是上海天气:多云,最低温度-2℃,最高温度2℃,空气质量优,pm2.5指数50,湿度40,东南风1级。,直接搜出来的内容,正常人会关心 东南风1级 吗
这就构成了一个最基本的工作流:
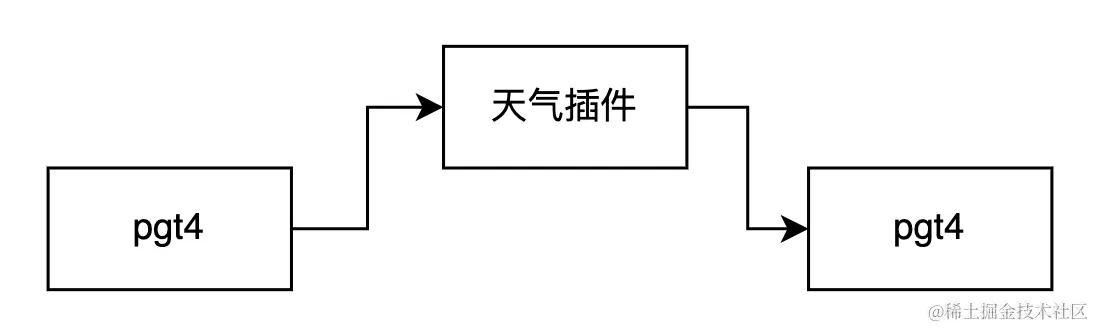
当你的插件增多,模型增多,再增加一些流程处理的功能等等 就能够做更多更复杂的事情。
尾语
大语言模型虽然才刚刚起步,面临的问题也很多,但是,前景是一片光明的。这也是我打算开始一个大模型应用专栏的原因。本文只算浅尝辄止,后面会分享实践的代码。
国内的各个大厂 也都在大力发展大模型,额 或者说大量”借鉴”chatgpt。对于打工人而言 本着打不过就加入的原则,那就一起搞。
最后推荐一下chatgpt的助手平台,相信我,会让你眼前一亮。
