

前言
上篇博文中,说了copilot和agent的原理,这篇博文重点是代码实现。
首先看一下代码架构
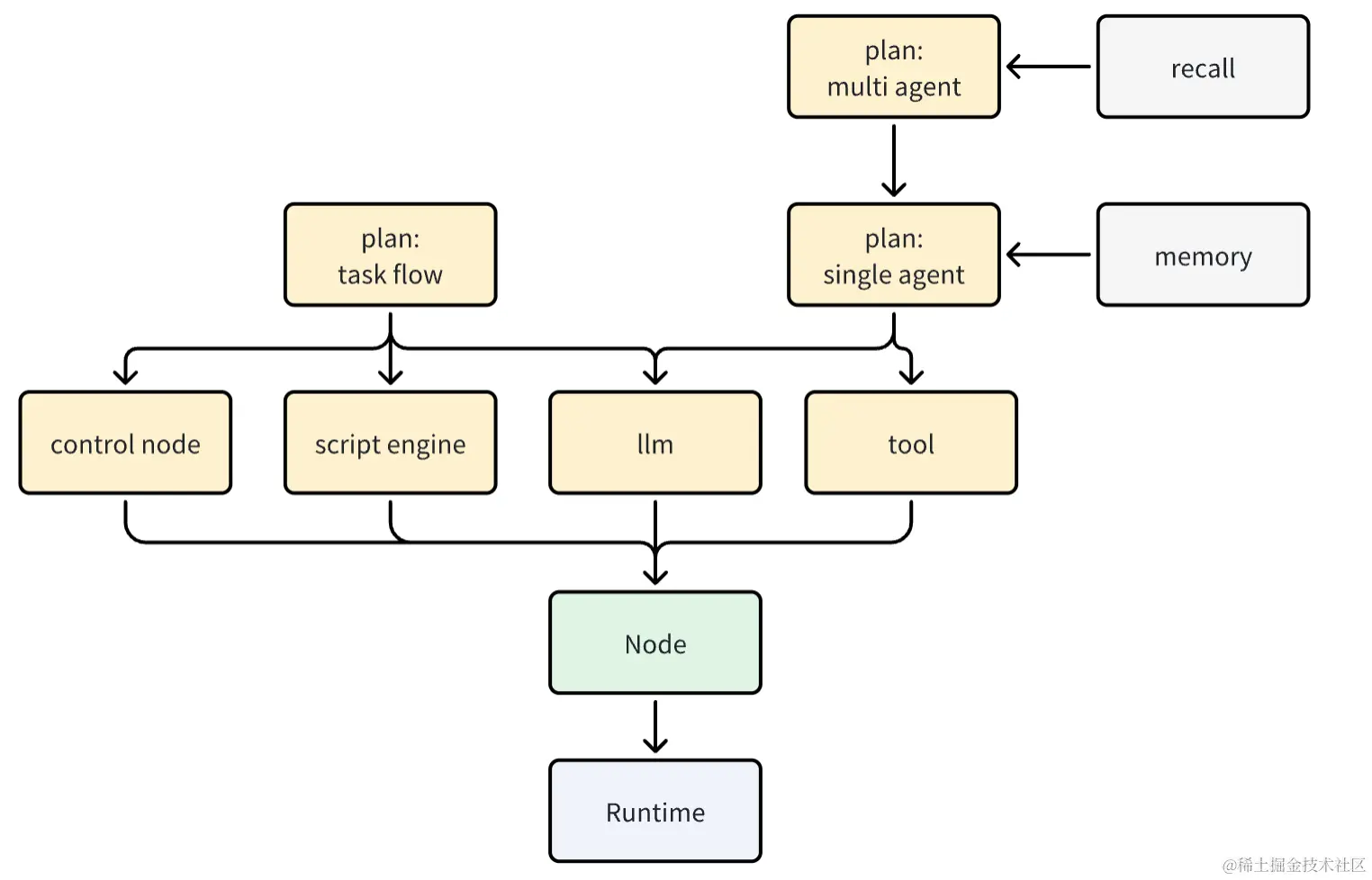
- runtime:能够按照一定策略,将一个复杂的任务按照,一个一个节点的方式运行起来。可以理解为对流程图的高度抽象。
- Node:对节点抽象出的接口,上面所有黄色的节点,都要实现这个接口,并最终放在runtime上执行。
- llm:基座大模型,tool:工具,script engine:脚本引擎,control node:节点控制器
single agent:按照论文的说法,是一个在某个场景下的专家,比如画画专家,购物专家。multi agent:让多个专家协同工作task flow:执行一个特定的任务流,相当于按照流程图执行任务。
本文重点:基于runtime实现single agent和multi agent。task flow我们以后再说。其实有了runtime,taskflow自动就实现了。
Runtime&Node
runtime的作用:假设我们有了一些能够运行的节点,当一个任务到达时,runtime需要按照一定的规则和流程,执行一系列节点,并最终给出一个结果。这里有两个需要注意的地方:
- 每个节点都必须是对等
- 节点之间的流转必须是自由的。
看代码实现,这里简化了,详细代码传送门
rust复制代码pub struct Runtime{
nodes: Arc<dyn NodeLoader> // 所有节点
...
}
// 运行一个任务的入口
// 入参:任务名,第一个节点的id,输入input
// 输出:Out
pub async fn run<In,Out>(&self,task_code:S,first_node_id:F,input:In)->anyhow::Result<Out>{
...
}
再看一下Node的抽象,很简单,每个节点只需要关注,自己能否运行,和自己如何运行。
rust复制代码#[async_trait::async_trait]
pub trait Node: Send + Sync {
// 节点id
fn id(&self) -> String;
// ready: 节点是否准备好开始工作,只能判断流程节点,不用来做参数校验
fn ready(&self, _ctx: Arc<Context>, _args: &TaskInput) -> bool {
true
}
// 运行节点,执行特定任务
async fn go(&self, ctx: Arc<Context>, args: TaskInput) -> anyhow::Result<TaskOutput>;
}
LLM
LLM是一切的灵魂,我们第一个实现。当然也不复杂,我们直接调用openai的开发接口。下面看一下简化代码。详细代码传送门。
rust复制代码pub struct LLMNode {
id: String,
// 大模型相关的默认参数:比如模型,tokens,temperature 等
default_req: LLMNodeRequest,
client: Client<OpenAIConfig>,
}
#[async_trait::async_trait]
impl rt::Node for LLMNode {
async fn go(&self, ctx: Arc<Context>, mut args: TaskInput) -> anyhow::Result<TaskOutput> {
let req = if let Some(query) = args.get_value::<String>() {
...
} else if let Some(mut req) = args.get_value::<LLMNodeRequest>() {
...
} else {
return anyhow::anyhow!("llm: task_input is unknown").err();
};
//调用openai的接口,发起聊天,这里没有用stream接口
let resp = self.chat(req).await?;
//继续执行下一个节点
go_next_or_over(ctx, resp)
}
}
Tool
tool由两部分组成,代码传送门
- tool的描述,就是我们告诉大模型我们的tool是做什么用的,包括参数是做什么。
- 注意当参数较为复杂的时候,尽量用gpt的模型,国内的很多模型对复杂参数的拼接是极为离谱的。
- tool的实现,这部分我们直接用
Fntrait作为一个抽象
简易代码如下:
rust复制代码pub struct ToolNode {
id: String,
// 函数描述和入参等信息
meta: FunctionObject,
// 函数的具体实现,为了兼容异步,函数的实际返回是个future。
handle: Box<
dyn Fn(String) -> Pin<Box<dyn Future<Output = anyhow::Result<String>> + Send>>
+ Send
+ Sync
+ 'static,
>,
}
#[async_trait::async_trait]
impl Node for ToolNode {
//兼容多种入参
async fn go(&self, ctx: Arc<Context>, mut args: TaskInput) -> anyhow::Result<TaskOutput> {
//如果入参是String,则直接调用handle
if let Some(input) = args.get_value::<String>() {
let resp = (self.handle)(input).await?;
return go_next_or_over(ctx, resp);
}
//如果入参是模型给出的结果,则需要先将入参抽出来,并且返回一个聊天的消息。
//这种方式相当于聊天中的一环
if let Some(call) = args.get_value::<ChatCompletionMessageToolCall>() {
let input = call.function.arguments;
let resp = (self.handle)(input).await?;
let msg: ChatCompletionRequestMessage = ChatCompletionRequestToolMessageArgs::default()
.tool_call_id(call.id)
.content(resp)
.build()
.unwrap()
.into();
return go_next_or_over(ctx, msg);
};
return anyhow::anyhow!("tool args error").err();
}
}
有了ToolNode之后,我们可以实现几个默认的函数看一下效果
rust复制代码//查询天气的函数,入参是城市
pub(crate) fn mock_get_current_weather() -> Self {
ToolNode::new(
"get_current_weather",
"Get the current weather in a given location",
r#"{"type":"object","properties":{"location":{"type":"string","description":"the city","enum":["beijing","shanghai"]}},"required":["location"]}"#,
Self::get_current_weather,
)
}
//taobao的函数,能够在线购物,不过`Self::submit_order`只能购买雨伞。
pub(crate) fn mock_taobao() -> Self {
ToolNode::new(
"submit_order",
"在线购物",
r#"{"type":"object","properties":{"product":{"type":"string","description":"商品名称"}},"required":["product"]}"#,
Self::submit_order,
)
}
agent
有了llm+tool我们可以尝试实现一个做简单的agent。详细代码传送门。
最简agent结构图:
还是画一下最简单agent的结构图:
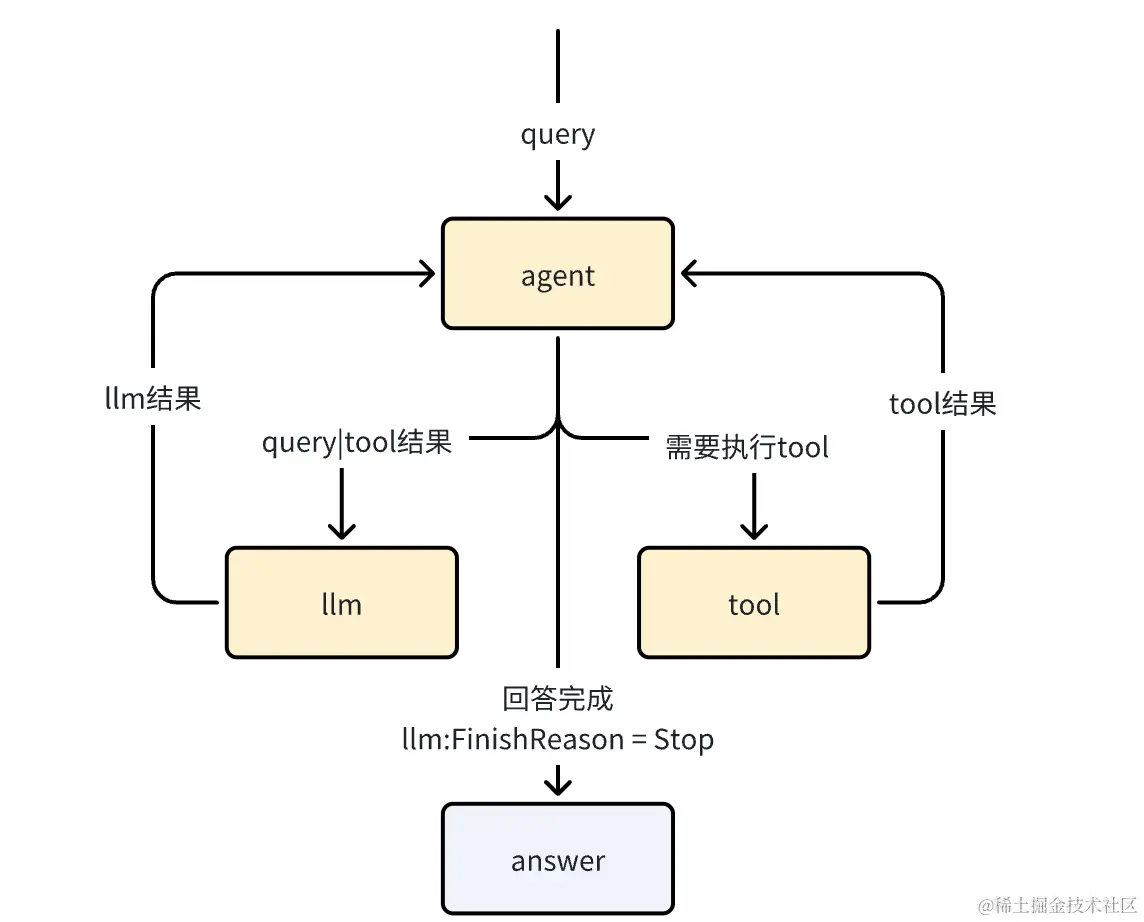
agent主要还是用来决策,是调用llm还是调tool,经过若干次循环后,最终给出结果。
代码实现
rust复制代码#[derive(Clone)]
pub struct SingleAgentNode {
//agent的设定,按照论文的说法,这是某个领域的专家
prompt: String,
//工具
tools: Vec<ChatCompletionTool>,
//memory能够简单的存储聊天记录,这里简单抽象一下,不用关心,以后还会变。
memory: Arc<dyn Memory>,
id: String,
//上下文窗口大小
max_context_window: usize,
//用哪个llm
llm_model: String,
}
#[async_trait::async_trait]
impl Node for SingleAgentNode {
async fn go(&self, ctx: Arc<Context>, mut args: TaskInput) -> anyhow::Result<TaskOutput> {
let mut status = ctx.remove::<usize>(AGENT_EXEC_STATUS);
if status.is_none() {
status = Some(1);
}
match status.unwrap() {
//用户query到达,调用模型
1 => {
...
return self.exec_llm(ctx);
}
//执行tool给出的结果
2 => {
...
Self::add_msg_to_context(ctx.clone(), resp);
return self.exec_llm(ctx);
}
//调用模型后给出的回复
3 => {
let mut resp: CreateChatCompletionResponse = args.get_value().unwrap();
...
match finish_reason.unwrap() {
//回复完成
FinishReason::Stop => {
return self.over(ctx, message.content.unwrap_or("无语".to_string()))
}
//模型让我们去执行tool
FinishReason::ToolCalls => {
return self.function_call(ctx, message.tool_calls.unwrap().remove(0))
}
_ => return anyhow::anyhow!("unknown finish_reason").err(),
}
}
//错误
_ => return anyhow::anyhow!("single agent unknown status").err(),
}
// Err(anyhow::anyhow!(""))
}
}
对于上下文的处理。
在agent的实现中,上下文分为了两个部分,其中用户的query和最终answer作为整体上下文的内容。
而中间调用函数和函数的返回结果的部分,作为一次会话的上线文。最终不会被记录。
如下代码处理:
rust复制代码//在用户发问时创建当前会话的短期上下文,并且存储在Context中
if ctx.get(
"session_context",
|x: Option<&mut Vec<ChatCompletionRequestMessage>>| x.is_none(),
) {
ctx.set(
"session_context",
Vec::<ChatCompletionRequestMessage>::new(),
);
}
//在聊天结束后,我们将user_question和ai_response放入到memory中
self.memory.add_session_log(vec![user_question, ai_response]);
效果验证
创建3.5的llm,两个mock的tool,和一个agent放入到runtime中。启动测试
bash复制代码cargo test single_agent::test::test_single_agent -- --nocapture

多智能体
关于多智能体其实就是多个agent之间的合作,文论中的实现过于繁琐,我的实现加以结合修改。使之更具备可用性。
流程&结构
看图是不是就清晰了,当query到达后,从多个agent中选出几个专家,并选出一个最相关的agent,将用户query交给他,然后他和其他专家共同探讨,最终得出一个结论。
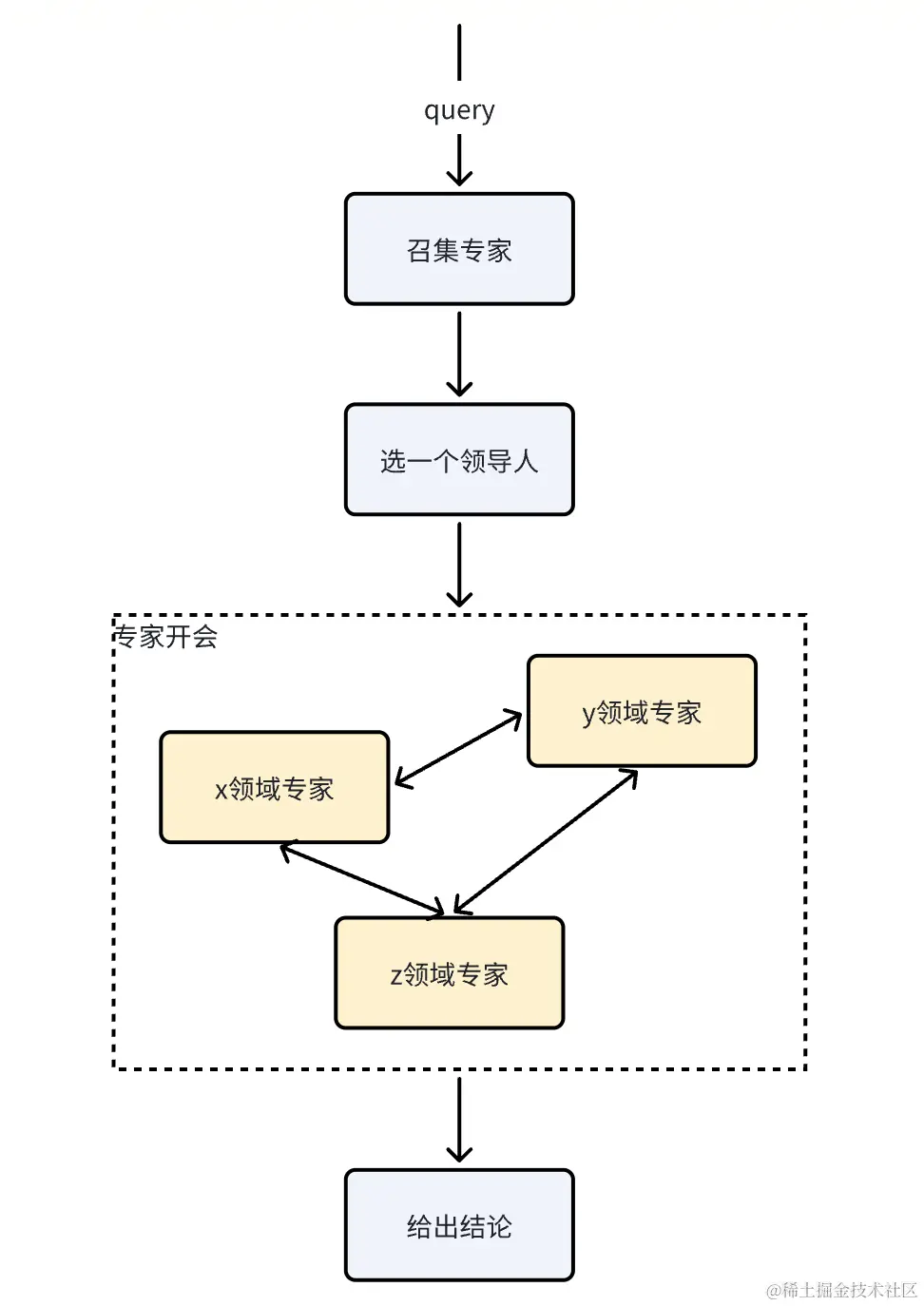
代码实现
rust复制代码pub struct MultiAgent {
//专家的id 和 专家作用的描述
agents: Vec<(String, String)>,
//为了能够让agent进行协作,需要给agent包装一个Node节点
agent_tools: Vec<AgentTool>,
//agent的向量描述,方便召回
agent_vec: Vec<Vec<f32>>,
id: String,
debug: bool,
recall_mod: RecallMod,
}
impl Node for MultiAgent {
async fn go(&self, ctx: Arc<Context>, mut args: TaskInput) -> anyhow::Result<TaskOutput> {
let query = args.get_value::<String>().unwrap();
//召回agent,并找到最相关的agent
let (agent, tools) = self.agent_recall(query.as_str()).await?;
Self::add_tools_to_context(ctx.clone(), tools);
//将query丢给专家团
if self.debug {
callback_self(ctx, self.id(), agent, query)
} else {
TaskOutput::new(agent, query).ok()
}
}
}
专家团召集
一个多智能体,最终会有非常多的专精agent,但解决一个query并不需要这么多agent,并且agent过多还会拖慢速度。所以需要召回专家。
我们这里主要用的embedding计算query和agent的余弦相似度召回。并将最相似的agent作为领导人。
注意,这种方式并不严谨,我的实际测试数据显示,准召率在90%~95%左右。并且难以优化。
应该支持多种召回方式。
rust复制代码// fixme 实际召回比较准的方式应该是根据 query+pe+portrait+context 进行召回,或者走个小模型
pub async fn agent_recall(&self, query: &str) -> anyhow::Result<(String, Vec<AgentTool>)> {
match self.recall_mod {
//这种方式,适合决策树,或者代理agent模式
RecallMod::First => {
let tools = self
.agent_tools
.iter()
.map(|t| t.clone())
.collect::<Vec<AgentTool>>();
return (self.agents[0].0.clone(), tools).ok();
}
//指定某个agent
//这种方式适合 agent的结构为对等拓扑,能够延续上一次记录。
RecallMod::Specific(ref id) => {
let tools = self
.agent_tools
.iter()
.map(|t| t.clone())
.collect::<Vec<AgentTool>>();
return (id.clone(), tools).ok();
}
//embedding召回
RecallMod::Embedding(ref n) => {
let query_vec = embedding_small_1536(vec![query]).await?;
let list = top_n(&query_vec[0], &self.agent_vec, *n);
let mut tools = vec![];
for i in list {
if let Some(i) = self.agent_tools.get(i) {
tools.push(i.clone());
}
}
return (tools[0].get_agent_id().to_string(), tools).ok();
}
}
}
验证效果
创建两个agent,一个生活agent,一个信息agent,并将他们和multi agent绑定,都放到runtime中测试:
bash复制代码cargo test multi_agent::test::test_multi_agent -- --nocapture

看这个交互,能够很明显看到两个agent在相互协作完成任务。并且记忆完好。
尾语
至此,整个copilot&agent的方案基本实现完成了。通过上面两个plan的实现,其实taskflow这种固定流程的就更加简单了,正好留给看官老爷尝试一下。
关于几个细节,最后再补充一下。
- 为啥用的是对等式节点的设计,不用层级结构的设计?
原因很简单,为了方便扩展。上面个每个模块都是Node抽象的实现,但相互之间可以无缝调用,保持了开放能力。如果是层次机构的设计,比较呆板固定。并且会被业务限制死了。虽然实际也有用,但我不喜欢。
-
对于memory和pe的部分,并没有很详细的实现,会单开两篇写。
-
如果你略有收获,希望点个赞,或有问题,欢迎留言。
