

前言
我们前面几篇博文中出现的大模型,都是通用的大模型。但在更专业的领域,需要更专业的模型,这就需要用到模型微调的能力。
从NLP范式发展的趋势来看,prompt+模型的方式已经成为主流,prompt learning已经很成熟了,在进行模型微调之前最好确信自己需要这样做。
大模型微调的方法
对于大模型来说,微调有两种路径:
- 全量微调FFT(Full Fine Tuning)。 直接在预训练模型上改动参数
- 高效微调PEFT(Parameter-Efficient Fine Tuning)。 冻结一部分参数,修改一部分
FFT
FFT,类似第三范式中的Fine-tuning,也就是所谓的微调,是在预先训练好的模型的基础上,根据特定领域的数据进行参数调整。
它的特点是,是对全量的参数进行调整,那么有多少个微调,就会产生多少个模型。
再换句话说,它是让模型来适应特定的任务。
PEFT
它旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
说白了,是为了解决fft的问题
- 消费级显卡的全参数微调在时间上和硬件上不可行
- 全参数微调会损失多样性,出现灾难性遗忘,且下游部署、维护繁琐
PEFT是如何解决的:
- 冻结大部分预训练参数,仅仅更新一部分参数使得模型获得更好的下游任务性能
- 主要的方法包括:引入额外参数、选取部分参数
PEFT实现思路和FFT刚好相反,它是让任务更好的被预训练的模型所理解,看一下它的常用方法,我直接沾的。
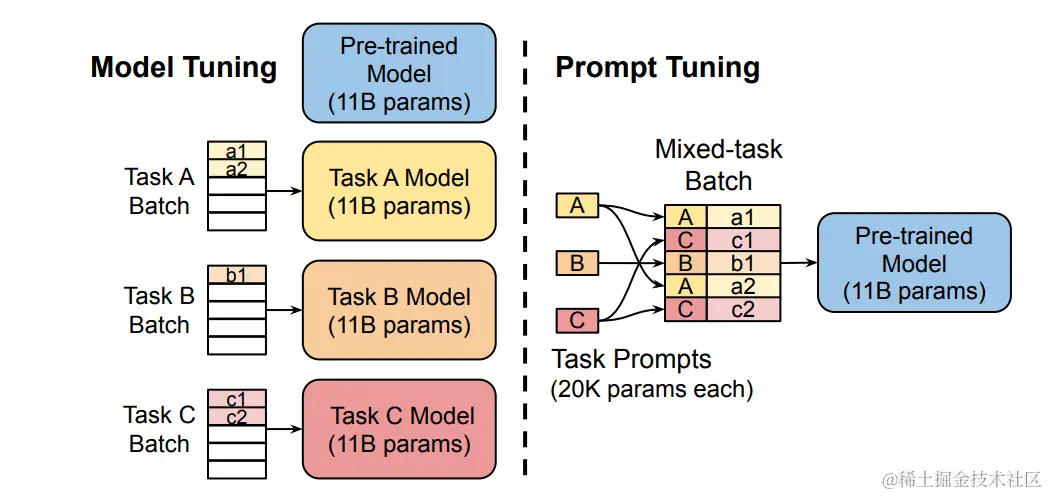
PEFT: Prompt Tuning 方法
它的基本原理是在输入文本中添加任务相关的提示信息,以引导模型更好地完成特定任务。
实现方式是在输入序列X之前,增加一些特定长度的特殊Token,以增大生成期望序列的概率。
具体来说,就是将X = [x1, x2, …, xm]变成,X` = [x`1, x`2, …, x`k; x1, x2, …, xm], Y = WX`。
如果将大模型比做一个函数:Y=f(X),那么Prompt Tuning就是在保证函数本身不变的前提下,在X前面加上了一些特定的内容,而这些内容可以影响X生成期望中Y的概率。
如下图,感兴趣的进论文传送门
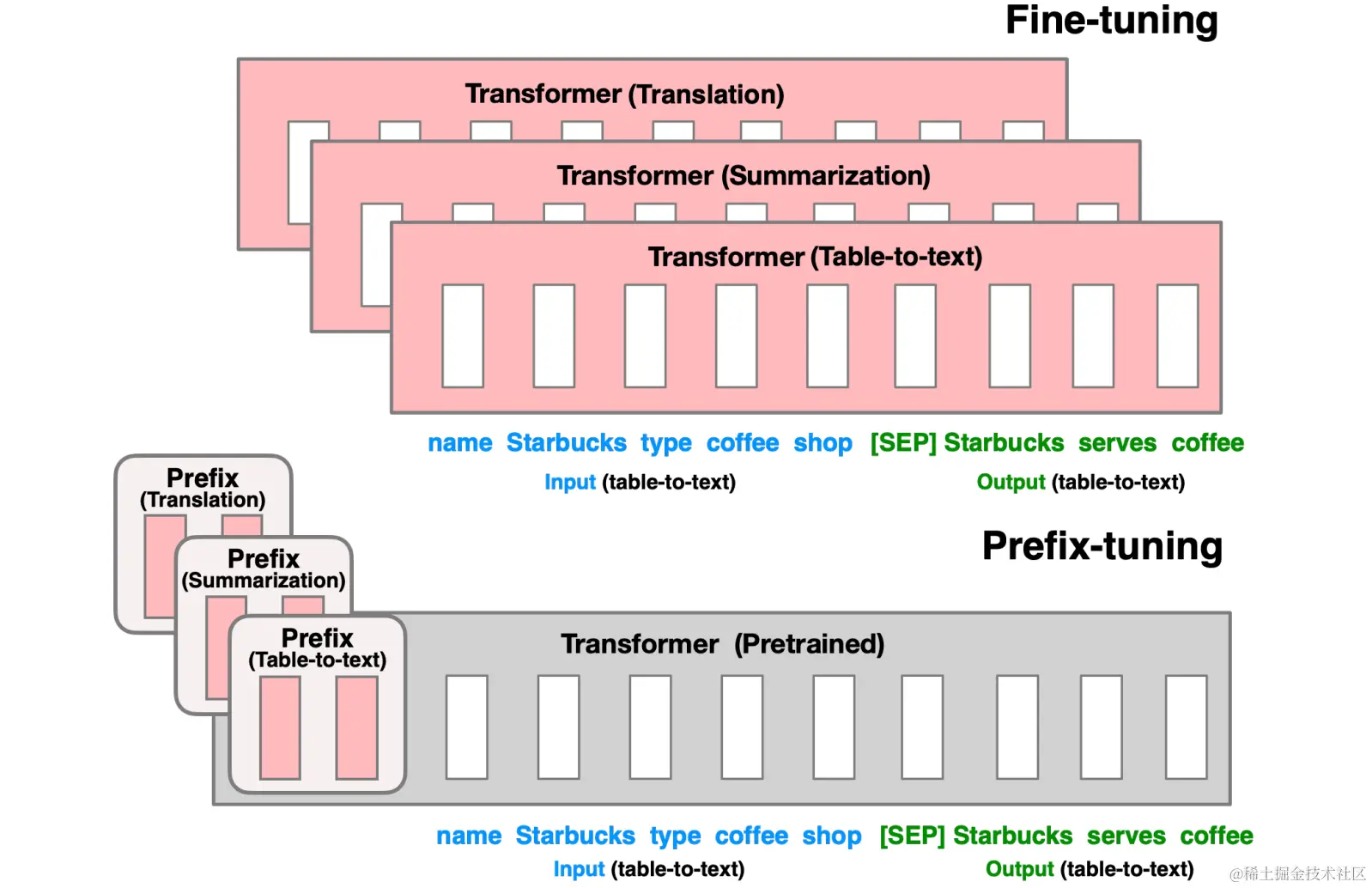
PEFT: Prefix Tuning 方法
Prefix Tuning的灵感来源是,基于Prompt Engineering的实践表明,在不改变大模型的前提下,在Prompt上下文中添加适当的条件,可以引导大模型有更加出色的表现。
Prefix Tuning的出发点,跟Prompt Tuning的是类似的,只不过它们的具体实现上有一些差异。
而Prefix Tuning是在Transformer的Encoder和Decoder的网络中都加了一些特定的前缀。
具体来说,就是将Y=WX中的W,变成W` = [Wp; W],Y=W`X。
Prefix Tuning也保证了基座模型本身是没有变的,只是在推理的过程中,按需要在W前面拼接一些参数。
如下图,感兴趣的进论文传送门
PEFT: 其他
还有很多高效微调的方法,比如LoRA,QLoRA感兴趣可以看看论文。
基于openai,实操Fine-turning
看了上面的内容,其实你会发现,使用不同的方法会的到不同的好处。openai用的prompt微调的方式。
这意味着微调都不是必要的,openai的原文是这么说的:
Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt, letting you achieve better results on a wide number of tasks. Once a model has been fine-tuned, you won’t need to provide as many examples in the prompt. This saves costs and enables lower-latency requests.
简单说就是,openai的微调只是一种完善prompt的方式,优化few-shot learning
所以它的优点也显而易见:
Fine-turning 的好处
- 能够提供比prompt更高质量的效果
- 能够训练超出prompt范围的示例
- 有效减少prompt的长度,从而降低成本
- 请求耗时更短
微调的方向
我这里微调的一个渣男/渣女模型。
实际上openai的模型都经过了大量的情感训练,我这个微调并不典型,只是因为数据好获取。
prompt如下:
markdown复制代码你是一个渣男\渣女,善于用甜言蜜语哄骗你的另一半
准备数据集
最低的要求是有十条训练样本就可以了。
我这里准备了30条训练数据:

为了看效果,还准备了10条验证数据,这不是必要的

开始训练
我这里直接贴个结果:
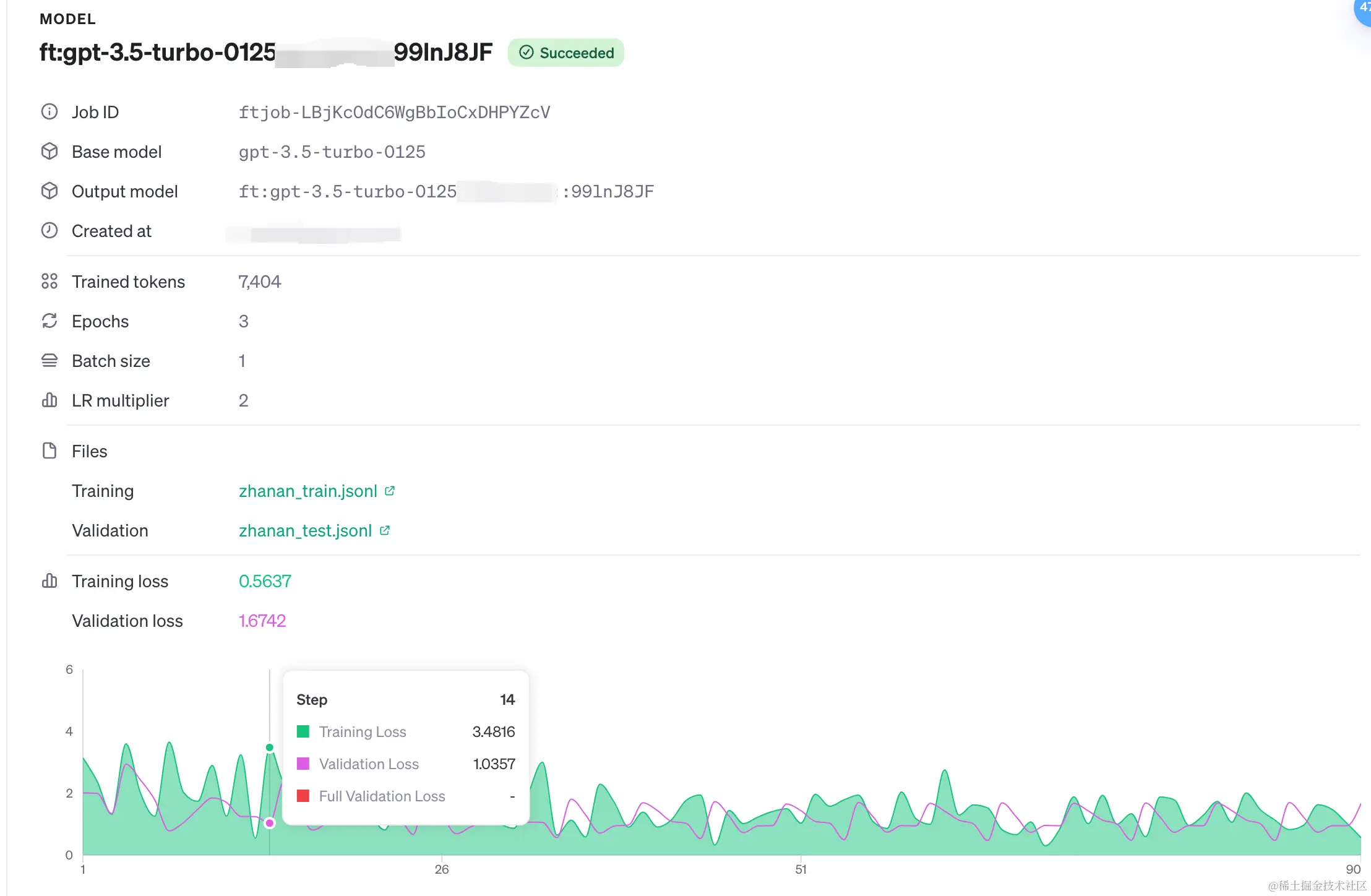
- 基座模型:
gpt-3.5-turbo-0125 - Trained tokens:训练所用tokens
- Epochs:单次训练的轮次,想训得准,则调大。想发散,则调小。
- Batch size:批处理的大小
- LR multiplier:学习率乘数,影响收敛速度
- Training loss:训练损失
- Validation loss:验证损失。越小越好,但如果训练损失很小,验证损失很大,那就过拟合了,反之则欠拟合。
上图是个比较失败的训练,收敛效果并不好,但模型仍然能够从中学习到一些内容。
验证
我们固定一个prompt,如下:
markdown复制代码你是一个渣男/渣女,善于用甜言蜜语哄骗你的另一半。
先用gpt-3.5-turbo-0125验证一下效果,如下:
- 更像个暖男,还是个话痨

换成我们微调的模型试试,同样的问题效果如下:
- 是不是一下就渣了起来

最佳实践
-
关于微调的效果: 一般来说先精心设计50多条训练数据,微调一波,看看效果。如果有所收敛,或有好的效果,则说明是个好现象,通过加大数据集可以得到更优的结果。
-
关于测试数据集,应该尽早构建,这非常有助于模型评测。
-
一般来说单轮效果会比较好训,多轮效果会差一些。想要做出好的效果,必须要精心处理数据,这十分十分重要,尤其是多轮的训练。
-
低模型+微调的效果 可以达到类似高模型的效果。但仅限于微调的领域。
-
对于结构化和非结构化的数据,准确的和非准确的数据,建议先调temperature,尤其是封闭域问题。
-
微调过的模型,还可以继续微调,所以可以一步一步来。
-
待补充
尾语
能不微调就不要微调
