

随着OpenAI将 gpt-3.5-turbo 切换到 gpt-3.5-turbo-1106 这个版本,也就是token价格和之前一样,但是长度成了16K,足足是之前的四倍,那么embedding这种方式才有可能派上用场。之前的4k,还不够塞牙缝!
当然如果你是很差钱,直接使用 gpt-4-1106-preview (也就是 gpt-4-turbo) 这个模型更爽,长度可达128K,尽管返回最长是4096,对于大部分场景已经足够。
一、注册账号
登录网址 FELH AI,注册账号后登录。
二、准备数据
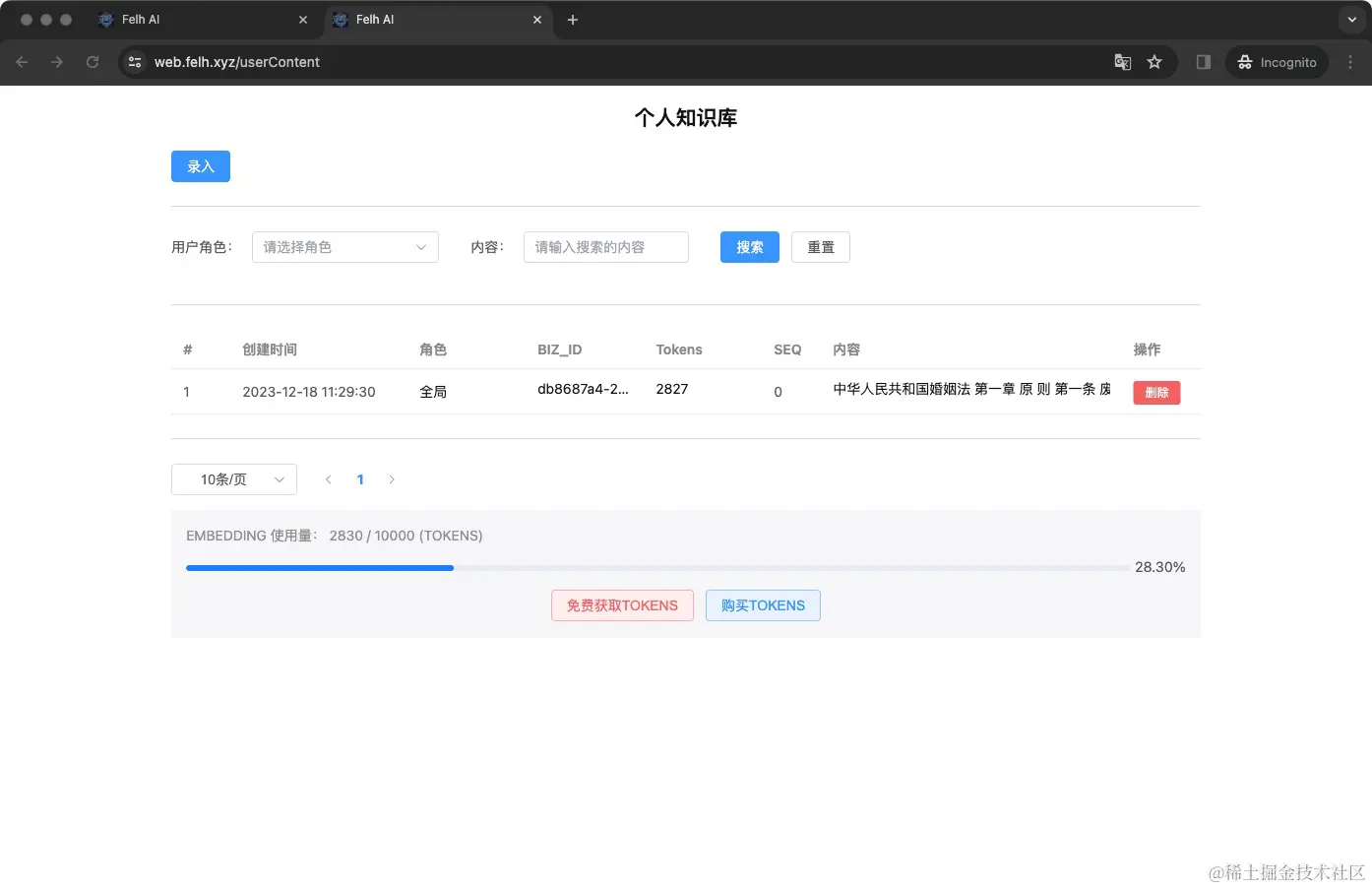
点击左下角菜单中的【个人知识库】,录入自己的AI问答问题。
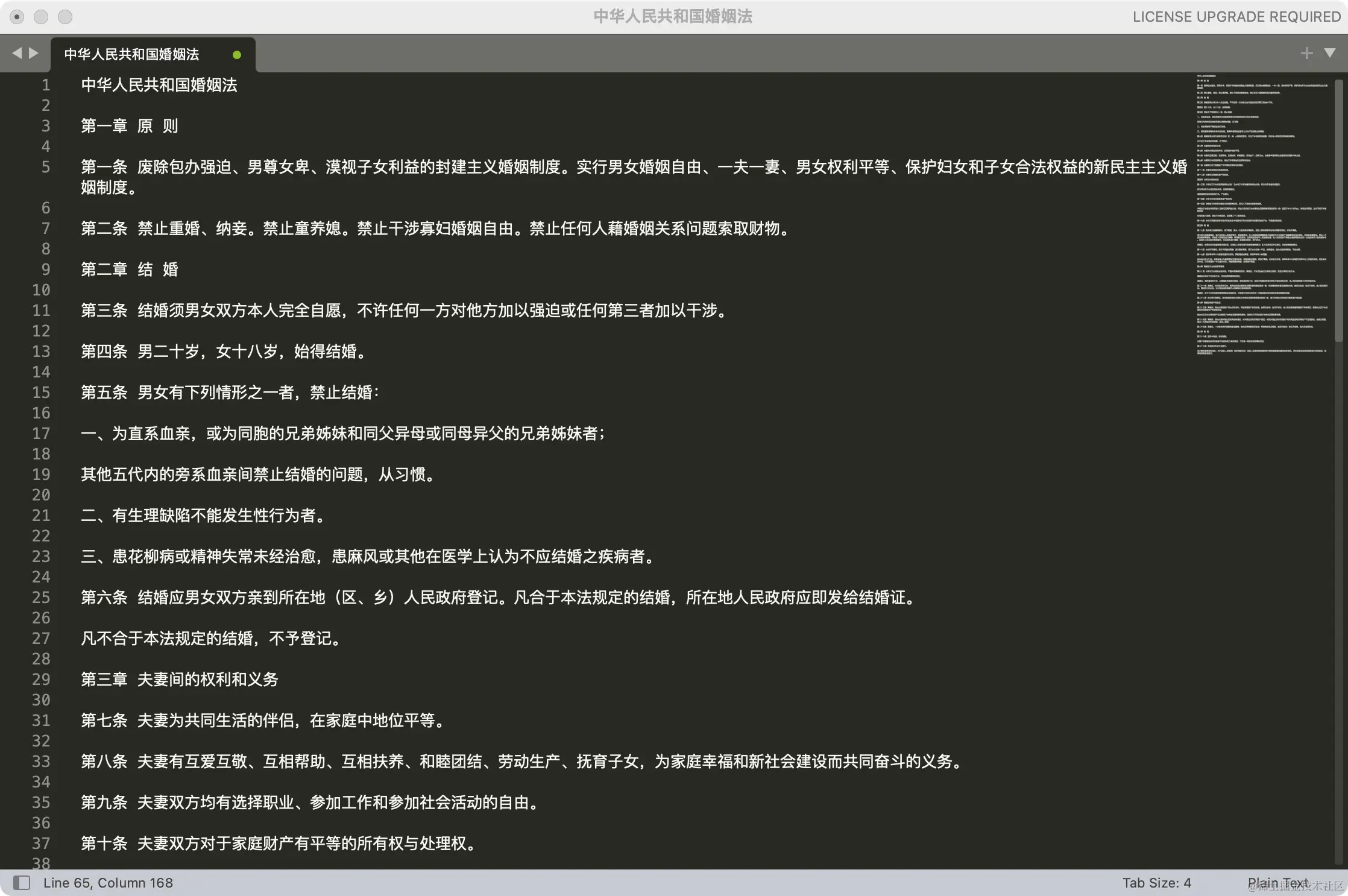
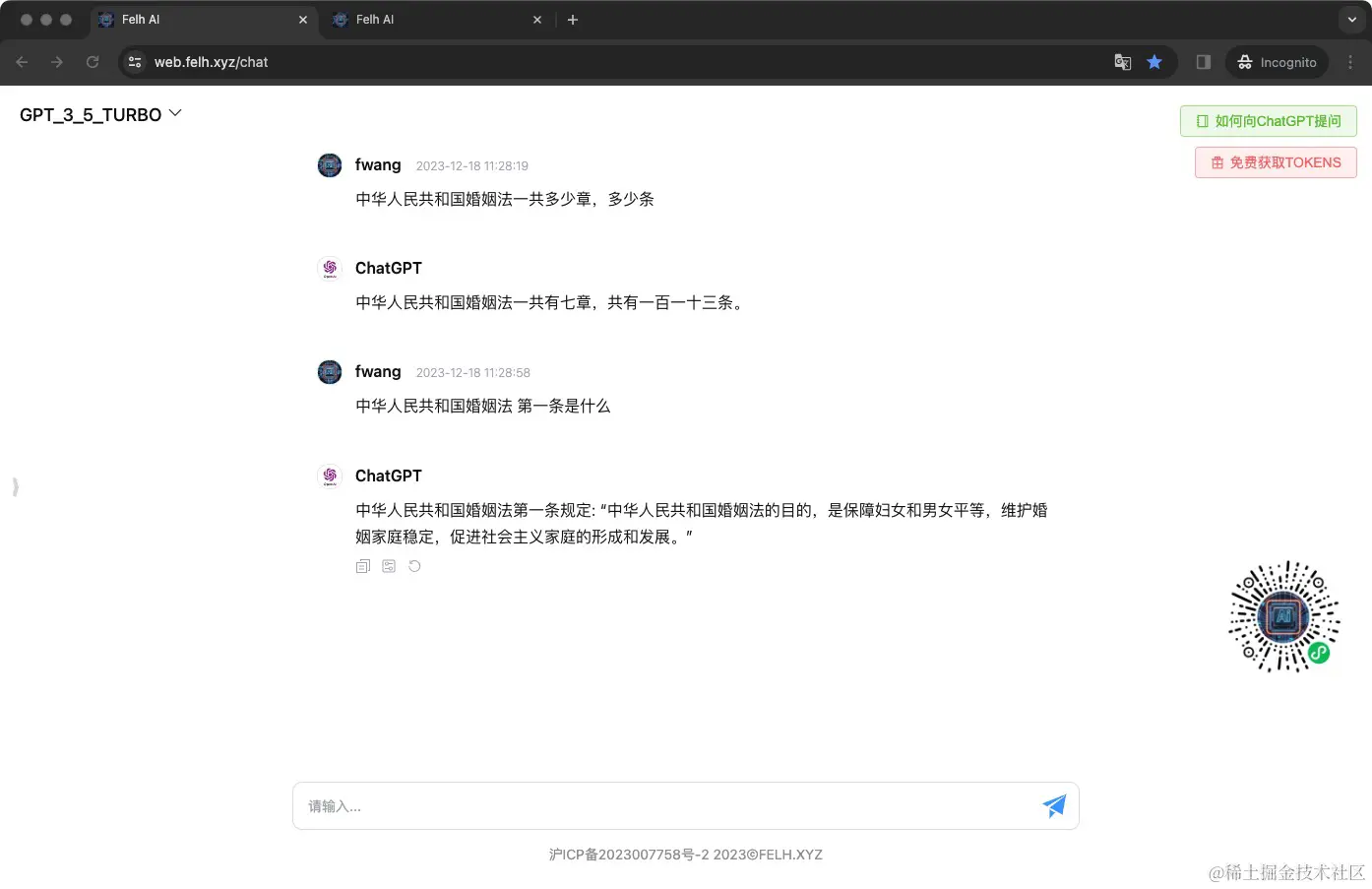
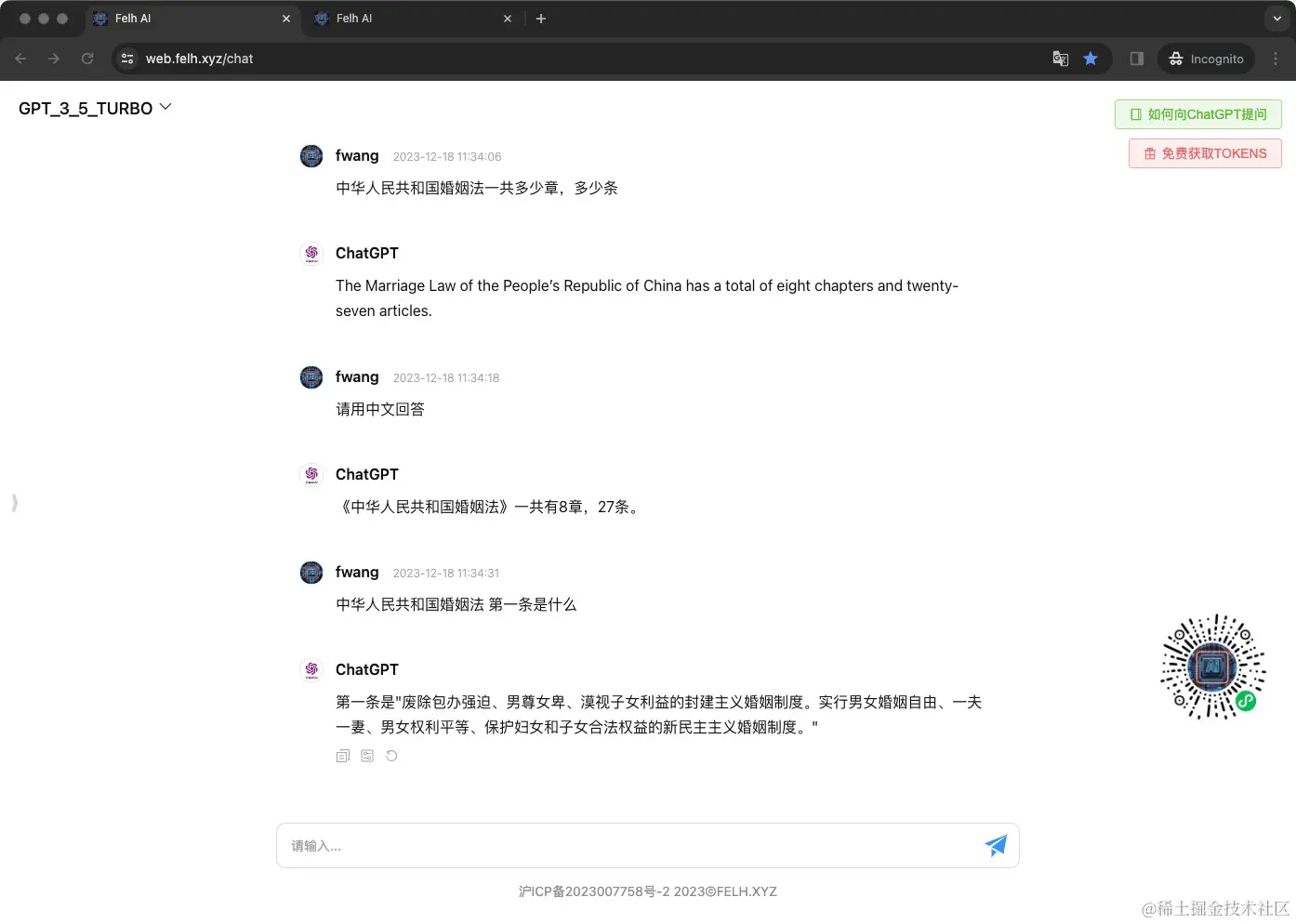
我从 www.npc.gov.cn/zgrdw/npc/l… 复制了《中华人民共和国婚姻法》,一共八章,27条。
三、向量化
将以上内容录入【个人知识库】
向量化工具的选择说明
最开始使用了阿里云的向量数据库(DashVector),同样也使用了百度云的向量数据库。最后我都放弃了,功能基本可以达到我的要求,对于我这么小的应用,性能肯定也也没有问题。问题在于,对于开发者小规模测试居然开始收费。
- 阿里云从12-15号开始收费,之前的测试cluster保留一个月
- 腾讯云不收费,但是每个月都要去申请一下免费资格(免费就免费吧,还要人去签到,脑子有坑)
果断都放弃了。
现在我的应用里面同时使用了三家向量数据库,作为索引,以免由于某些不可抗因素,突然不可用了。
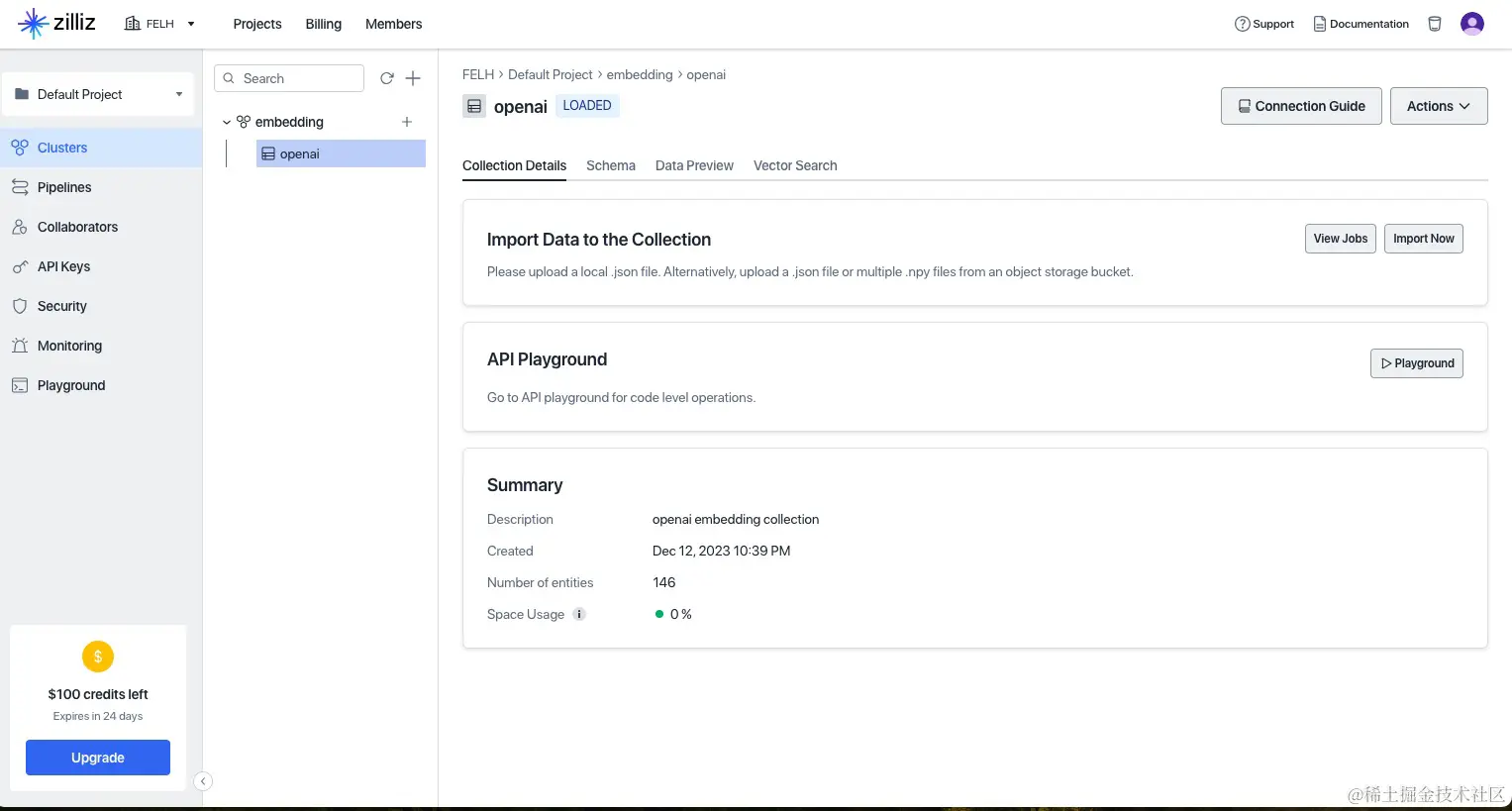
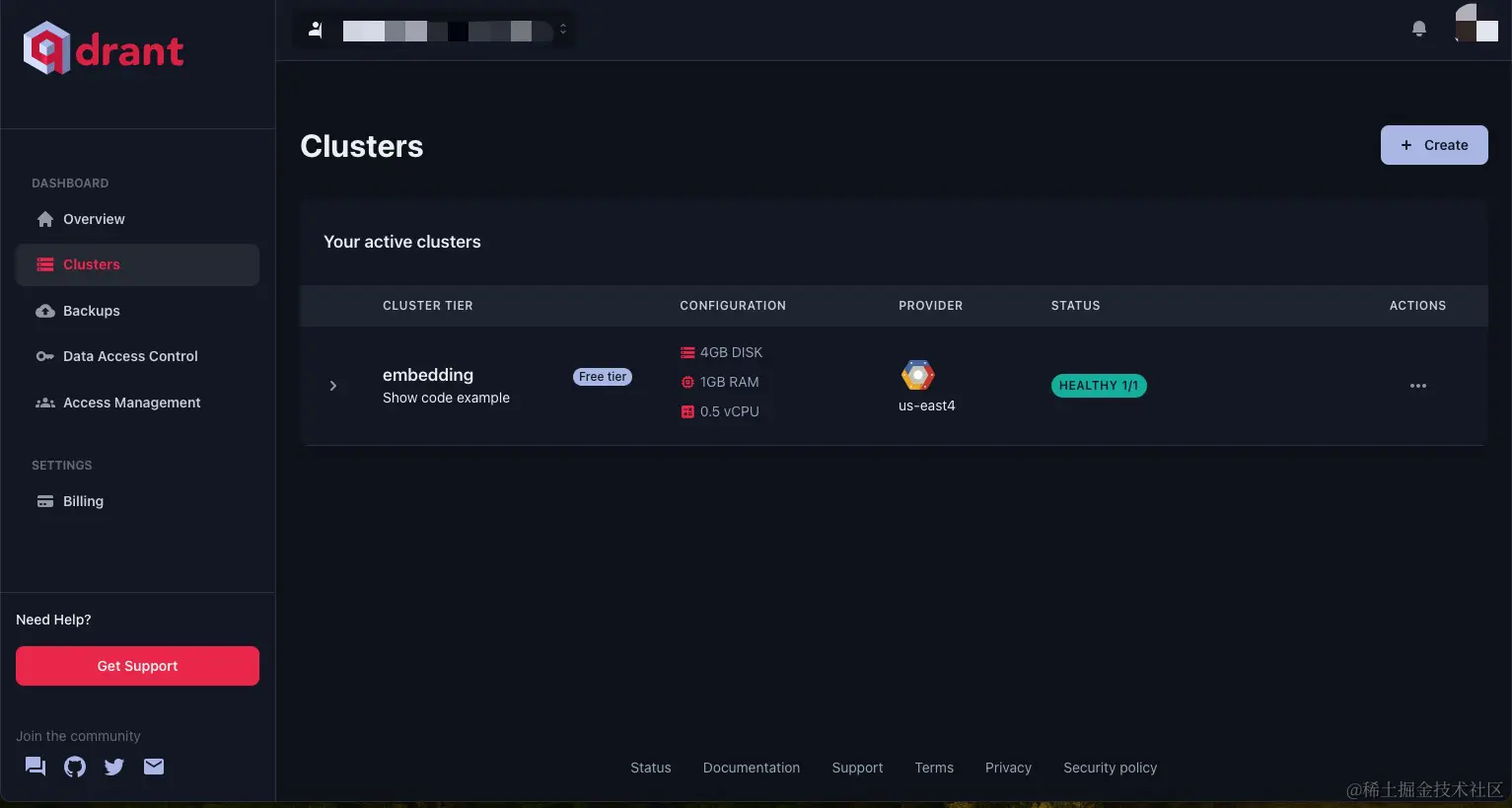
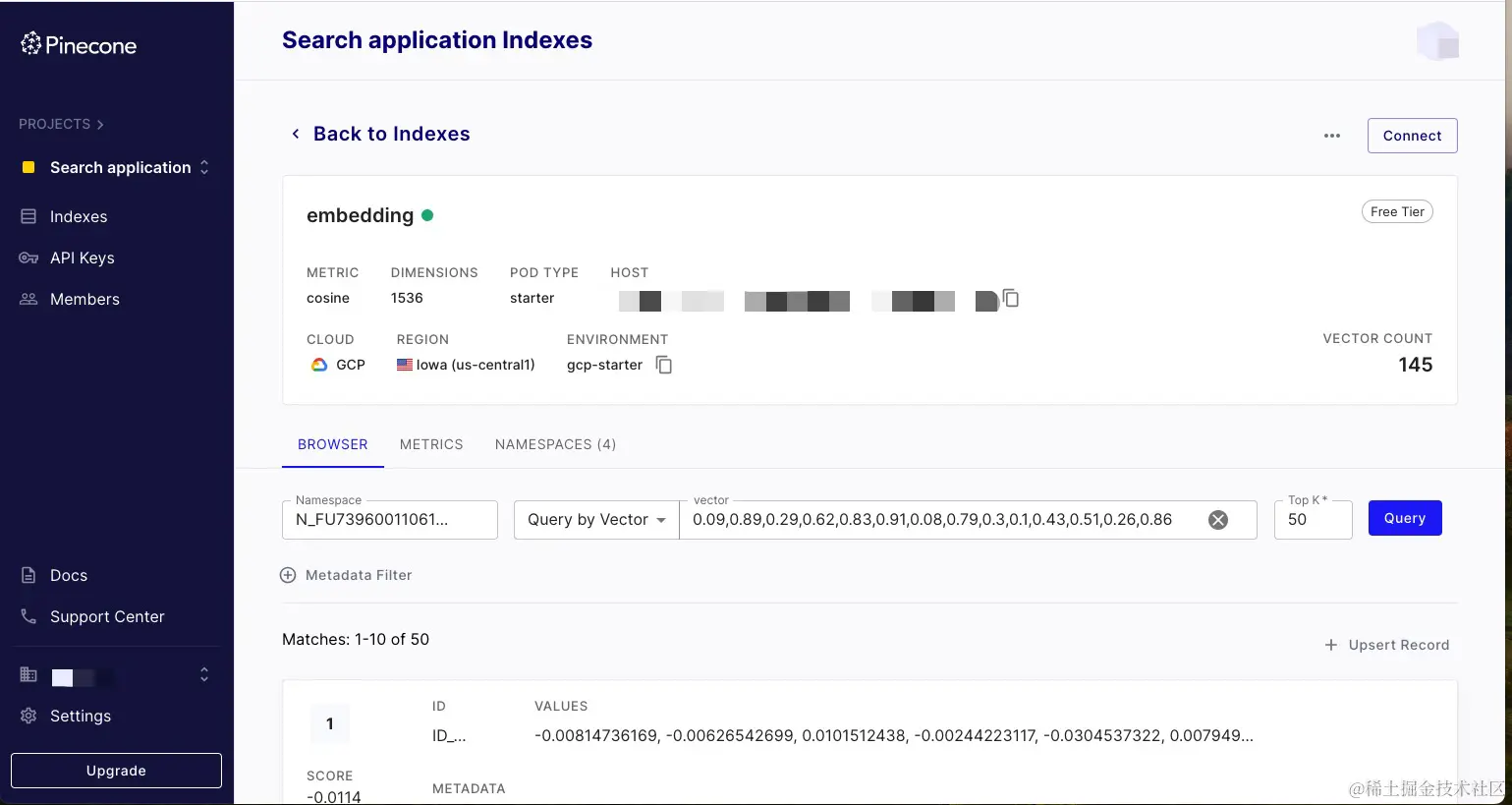
这三家提供的服务很接近,比较下来Zilliz更多都可以支持pipelines,在我们使用的向量数据库相似度查询上没有什么区别。他们三家都为开发者提供了单一副本的服务,完全免费,对于OpenAI的embedding这种1536维度的向量,大概都能支持到50万条数据左右,我想对于开发者,或者对于小规模应用完全够用了。当然由于是1副本集,所以最好在自己应用数据库中做好数据备份,以免服务不可用造成数据丢失。
四、调整参数,结果对比
下面是未使用知识库。
在【聊天设置】中开启【个人知识库】
体验方式:通过下面第2条的网址即可马上体验
- OpenAI API SDK java版本,可访问 github:openai-java
- 用VUE3写了一个网站应用,包括H5和PC两个版本(网址都是 web.felh.xyz ),还有小程序版【FELH AI】(后续不会更新了,因为不要face的微信开始对个人小程序也开始收年审的费用了)
到目前为止SDK已经支持所有2023-11-06 API更新后新加的接口(Assistants, Threads, Messages, Runs),移除了废弃和过时接口(Completions, Edits, Fine-tunes)。此SDK完全是个人利用业务时间在维护,如果您觉得有用,请顺手点个star,感谢!
当然Embedding还可以做很多事情:
- Search (where results are ranked by relevance to a query string)
- Clustering (where text strings are grouped by similarity)
- Recommendations (where items with related text strings are recommended)
- Anomaly detection (where outliers with little relatedness are identified)
- Diversity measurement (where similarity distributions are analyzed)
- Classification (where text strings are classified by their most similar label)
具体可以参考官方文档 Embeddings。
