

最近想搞点什么东西练练手,传统crud又没有意义,于是就看到了给介绍AI的文章,然后就慢慢自己摸索,从0到1,独自部署应用。
项目简介
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
具体请查看官方GitHub github.com/THUDM/ChatG…
环境
python
项目要求python环境最低3.10,安装完成后执行
python -v查看python版本
conda
安装conda
这里我选的是miniconda,具体请自行选择docs.conda.io/en/latest/
安装完成使用conda -V 查看版本号即可表示安装成功

部署
先把项目拿下来
git clone https://github.com/THUDM/ChatGLM3
切换到根目录,使用pip安装依赖
bash复制代码cd ChatGLM3
pip install -r requirements.txt
在ChatGLM3basic_demo目录下执行命令
arduino复制代码streamlit run web_demo_streamlit.py
第一次执行需要下载很大的模型文件,大概11g左右

特别注意,此处需要使用魔法(非国内节点),否则会报错。

启动成功后,如果你的控制台出现以下一句话就说明你使用的是cpu在运算
WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu and disk.

因为CPU跑太慢了,我们必须要使用GPU进行运算。 在web_demo_streamlit.py文件里面有这么一段代码
python复制代码def get_model():
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").eval()
return tokenizer, model
我们把他改造一下
python复制代码def get_model():
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True,device_map="cuda").quantize(4).cuda()
return tokenizer, model
然后再启动我们的项目,心想美滋滋啊,终于能跑了。
但是事情没有想象中那么简单启动后还是会出现WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu and disk.
pytorch
查阅资料后发现,是因为我们的pytorch没有安装正确的版本
使用python交互模式输入
python复制代码import torch as t
print(t.cuda.is_available())
print(t.__version__)
可以看到输出是False和xxx+cpu这样的数据
既然是错误的版本,那重新安装就可以了吧。 我们去到PyTorch官网根据我们的机器进行版本安装 pytorch.org/get-started…
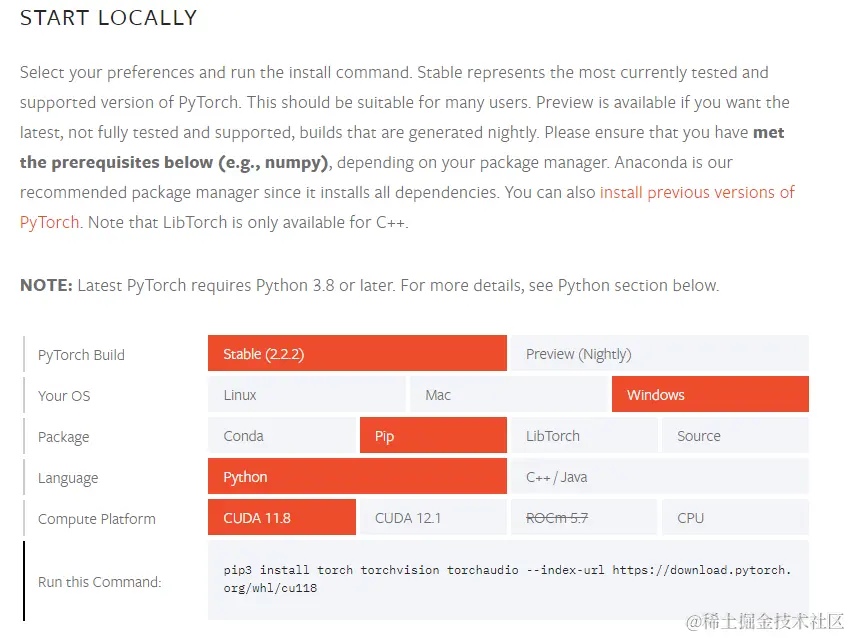
cuda版本
控制台输入
复制代码nvidia-smi
查看GPU信息

右边的cuda是最高支持的版本,左边是GPU驱动信息
然后根据你的驱动版本在cuda官网查看对应的cuda版本 docs.nvidia.com/cuda/cuda-t…

找到对应的cuda版本之后我们到
developer.nvidia.com/cuda-toolki…
下载你的GPU对应的版本号。
安装cuda的时候注意,这个界面只是把安装程序解压到此目录,真正的安装在后面。

这个目录cuda安装完成后会自动删除,但是还是不建议放在c盘。 等待一段时间后会出现以下窗口。

此处才是真正的cuda安装路径,还是不要放在c盘,安装过程屏幕可能会闪烁,这属于正常现象。
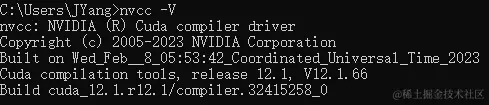
安装完成后控制台使用
nvcc -V查看版本
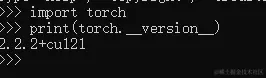
python复制代码import torch
print(torch.cuda.is_available())

python复制代码import torch
print(torch.__version__)
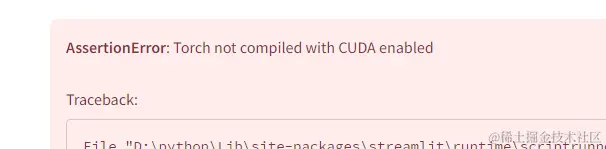
注意,笔者使用conda安装pytorch后运行出现以下情况
再来启动一次AI,等待一段时间后会自动跳转到以下界面
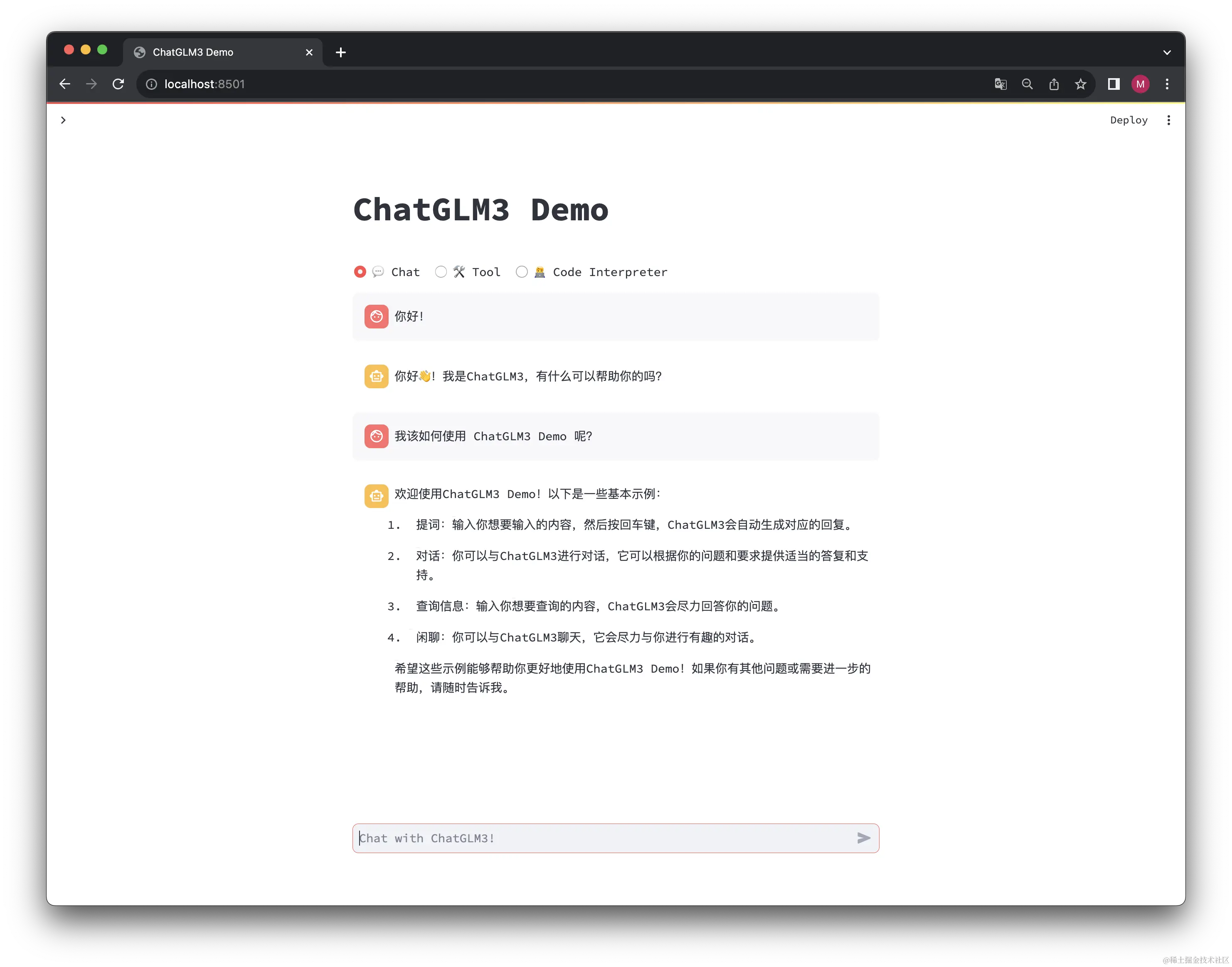
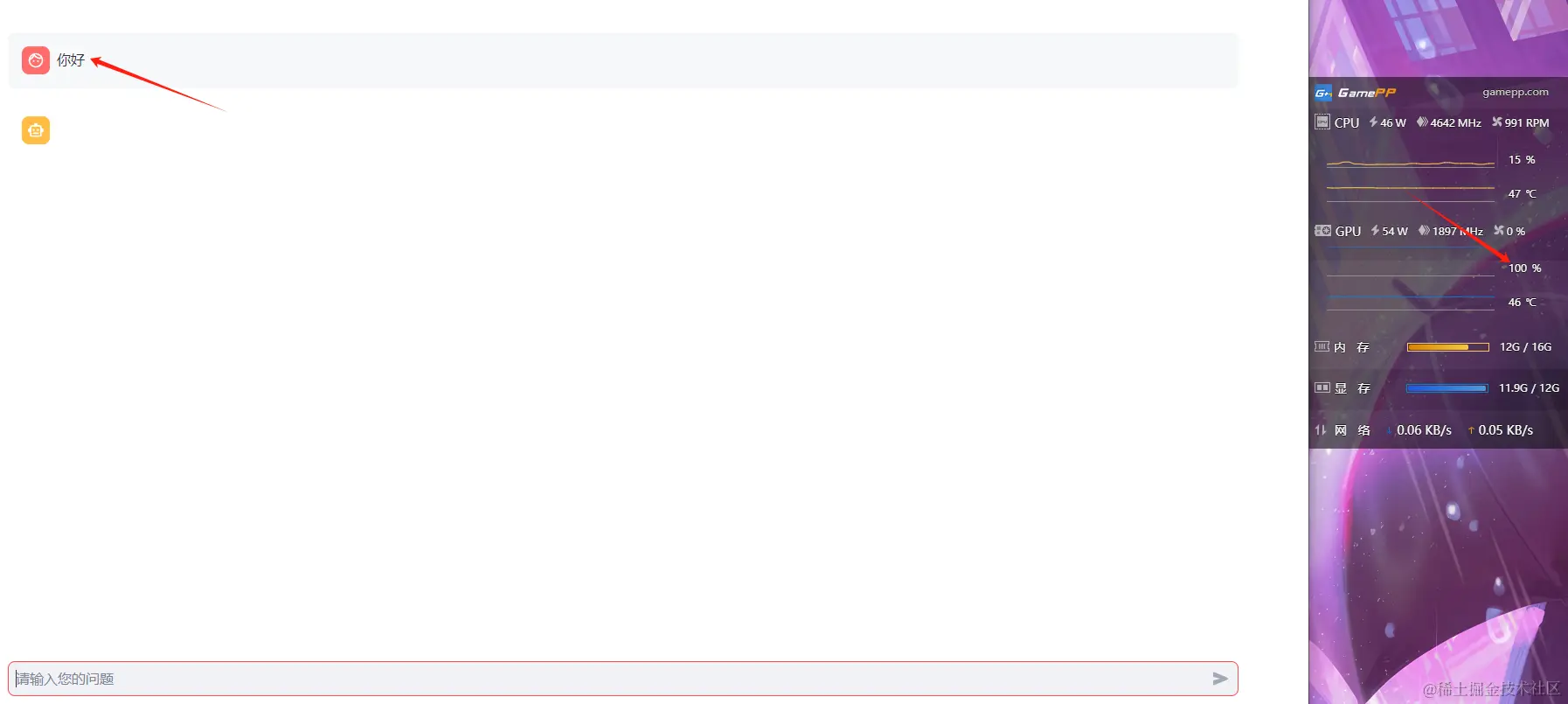
我本来以为我的显卡能跑起来的,但是试了之后发现,三分钟跑一个字
总结
虽然跑起来很吃力,但是总算是踩了几个坑跑完了了,只是有点慢(
朋友们安装pytorch的时候要注意版本以及cuda的版本对应关系,坑都是这两个比较深。
笔者也是第一次玩这东西,欢迎大家评论区讨论指出不足。
