

使用LangChain开发LLM应用时,需要机器进行GLM部署,好多同学第一步就被劝退了,那么如何绕过这个步骤先学习LLM模型的应用,对Langchain进行快速上手?本片讲解3个把LangChain
使用LangChain开发LLM应用时,需要机器进行GLM部署,好多同学第一步就被劝退了,那么如何绕过这个步骤先学习LLM模型的应用,对Langchain进行快速上手?本片讲解3个把LangChain跑起来的方法,如有错误欢迎纠正。
Langchain官方文档地址: python.langchain.com/
基础功能
LLM 调用
- 支持多种模型接口,比如 OpenAI、HuggingFace、AzureOpenAI …
- Fake LLM,用于测试
- 缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
- 用量记录
- 支持流模式(就是一个字一个字的返回,类似打字效果)
Prompt管理,支持各种自定义模板
拥有大量的文档加载器,比如 Email、Markdown、PDF、Youtube …
对索引的支持
- 文档分割器
- 向量化
- 对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
Chains
- LLMChain
- 各种工具Chain
- LangChainHub
详细地址可参考:
www.langchain.cn/t/topic/35
测试Langchain工程的3个方法:
1 使用Langchian提供的FakeListLLM
为了节约时间,直接上代码
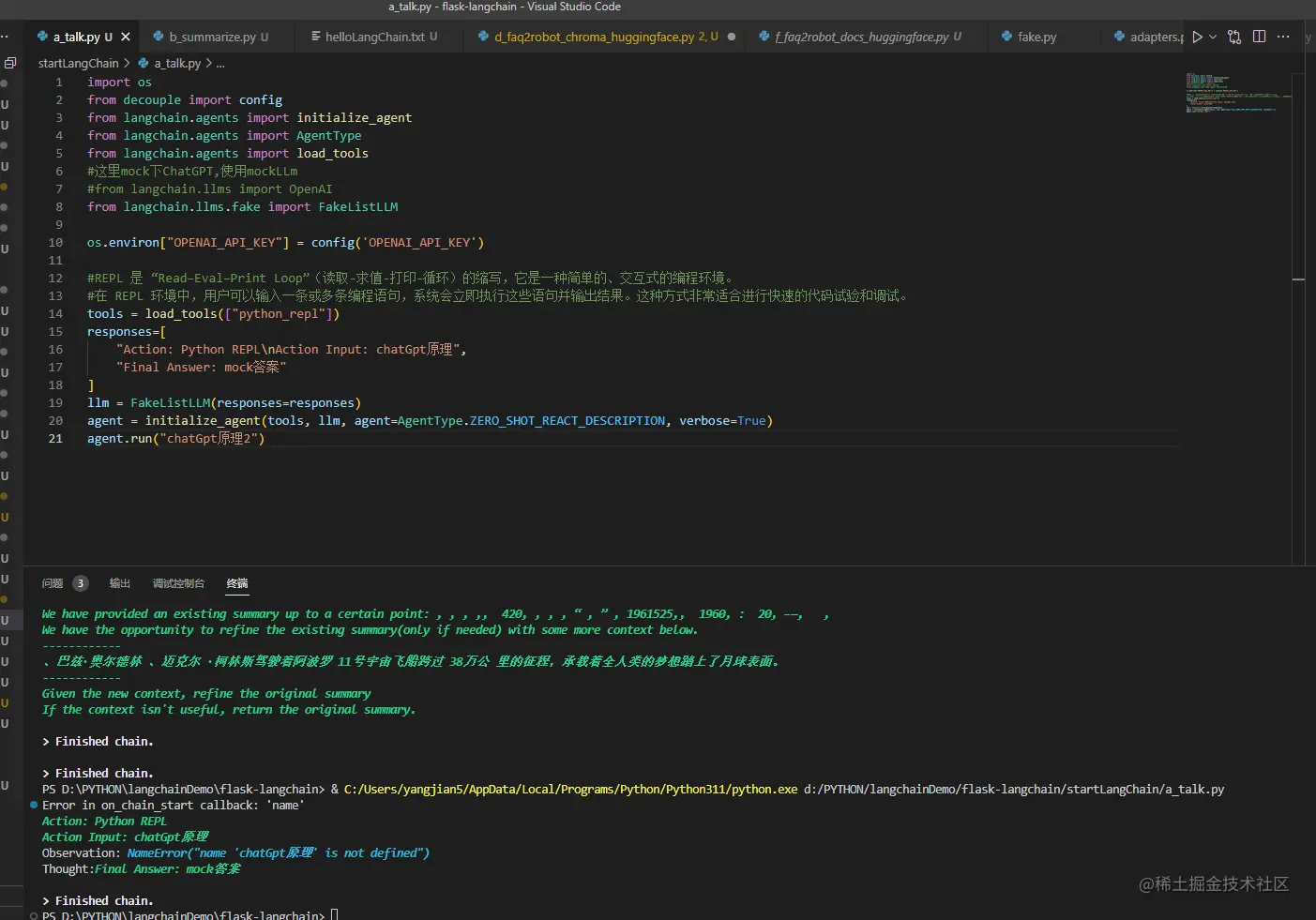
javascript复制代码import os
from decouple import config
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.agents import load_tools
这里mock下ChatGPT,使用mockLLm
javascript复制代码#from langchain.llms import OpenAI
from langchain.llms.fake import FakeListLLM
os.environ["OPENAI_API_KEY"] = config('OPENAI_API_KEY')
REPL 是 “Read–Eval–Print Loop”(读取-求值-打印-循环)的缩写,它是一种简单的、交互式的编程环境。
在 REPL 环境中,用户可以输入一条或多条编程语句,系统会立即执行这些语句并输出结果。这种方式非常适合进行快速的代码试验和调试。
ini复制代码tools = load_tools(["python_repl"])
responses=[
"Action: Python REPLnAction Input: chatGpt原理",
"Final Answer: mock答案"
]
llm = FakeListLLM(responses=responses)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("chatGpt原理2")
2 使用Langchian提供的HumanInputLLM,访问维基百科查询
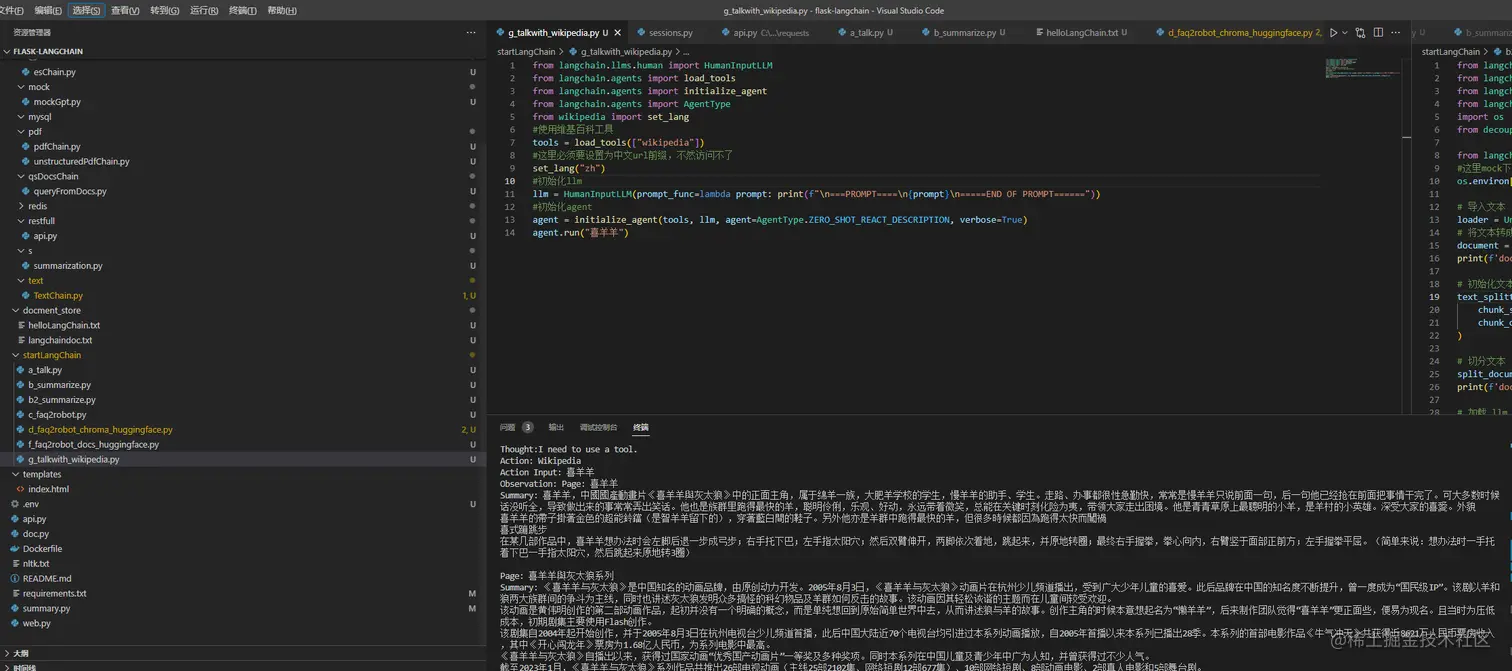
javascript复制代码from langchain.llms.human import HumanInputLLM
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from wikipedia import set_lang
使用维基百科工具
ini复制代码tools = load_tools(["wikipedia"])
这里必须要设置为中文url前缀,不然访问不了
scss复制代码set_lang("zh")
初始化LLM
swift复制代码llm = HumanInputLLM(prompt_func=lambda prompt: print(f"n===PROMPT====n{prompt}n=====END OF PROMPT======"))
初始化agent
ini复制代码agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("喜羊羊")
3 使用huggingface
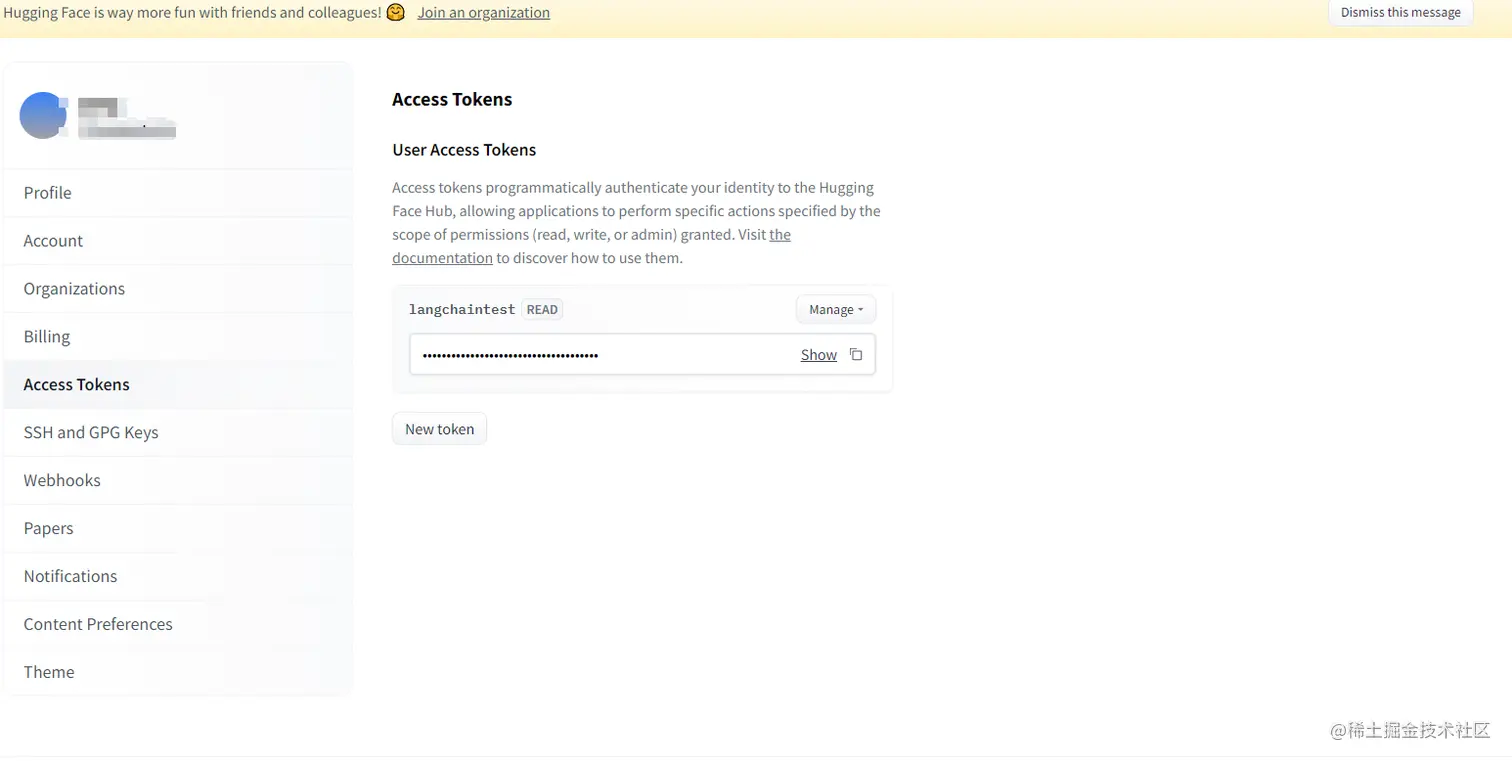
1.注册账号
2.创建Access Tokens
Demo: 使用模型对文档进行摘要
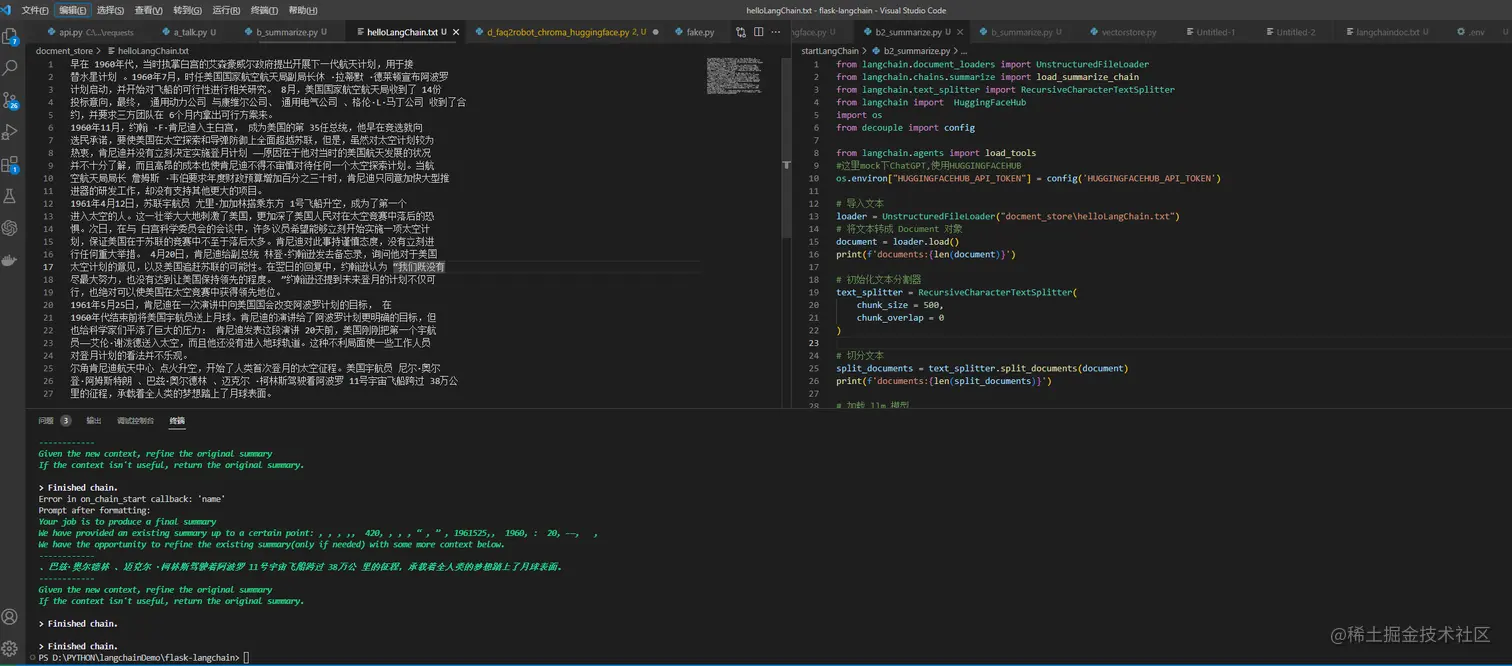
javascript复制代码from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import HuggingFaceHub
import os
from decouple import config
from langchain.agents import load_tools
这里mock下ChatGPT,使用HUGGINGFACEHUB
lua复制代码os.environ["HUGGINGFACEHUB_API_TOKEN"] = config('HUGGINGFACEHUB_API_TOKEN')
导入文本
ini复制代码loader = UnstructuredFileLoader("docment_storehelloLangChain.txt")
将文本转成 Document 对象
python复制代码document = loader.load()
print(f'documents:{len(document)}')
初始化文本分割器
ini复制代码text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 0
)
切分文本
python复制代码split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')
加载 LLM 模型
ini复制代码overal_temperature = 0.1
flan_t5xxl = HuggingFaceHub(repo_id="google/flan-t5-xxl",
model_kwargs={"temperature":overal_temperature,
"max_new_tokens":200}
)
llm = flan_t5xxl
tools = load_tools(["llm-math"], llm=llm)
创建总结链
ini复制代码chain = load_summarize_chain(llm, chain_type="refine", verbose=True)
执行总结链
scss复制代码chain.run(split_documents)
作者:京东科技 杨建
来源:京东云开发者社区
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
