

前言
编写代码一直是计算机科学和软件开发的核心活动。然而,随着AIGC领域的兴起,我们正迎来一场革命,它将永久性地改变我们编写代码的方式!今天就让我们来一起体验体验,AI能给我们带来什么便利和变化。
正文
Colaboratory
Colaboratory(通常简称Colab)是由Google开发和提供的免费的云端Jupyter笔记本环境。适用于Python编程、数据分析和机器学习,使用户能够无需担心本地计算资源的限制,轻松进行各种计算任务。在我们拥有一个Google账号之后,我们将使用Colab来进行我们的学习。
首先让我们进入官网:colab.research.google.com/ 。随后让我们找到文件–>然后新建笔记本(如下图):

跳转到之后的界面我们就可以开始编写我们的代码了,点击左边的“播放按钮”可以运行当前框内的代码,当然运行完每次的代码后,通过点击“+代码”来进行新的代码编写(如下图):

这样你就学会了基本的使用方法啦~
Customer_service
我们先来试试一个最简单的AI客服的例子。
我们先让新建的笔记本安装一个openai:
python复制代码!pip install openai==0.10.2
再进行客服模块的一系列调试:
python复制代码# 基于openai 的大模型来强化客服
import openai
# api_key
openai.api_key="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"
# 常量 文本生成的模型
COMPLETION_MODEL="text-davinci-003"
# 系统后台生成了一条记录,再调用我们这个AIGC来生成客服
prompt="""请你使用朋友的语气回复客户,并称他为亲,他的订单已经发货在路上了,
预计在三天之内会送达,订单号2021AEDG,我们很抱歉因为天气的原因物流时间比原来长,
感谢他选购我们的商品。"""
# 封装了openai回复的功能
def get_response(prompt, temperature=1.0):
# Completion模块
# 生成内容 同步的
# 调用openai库的Completion模块,创建一个新的
# 字典 {key:value}
completions = openai.Completion.create(
engine=COMPLETION_MODEL,
prompt=prompt,
max_tokens=1024, # 最大算力
n=1, # 返回一条结果
# null True
stop=None, # 内容没有执行完不要停下来
temperature=temperature
)
# 返回的结果由JSON返回为text
print(completions)
message = completions.choices[0].text
return message
最后让我们来看看效果:
python复制代码print(get_response(prompt))
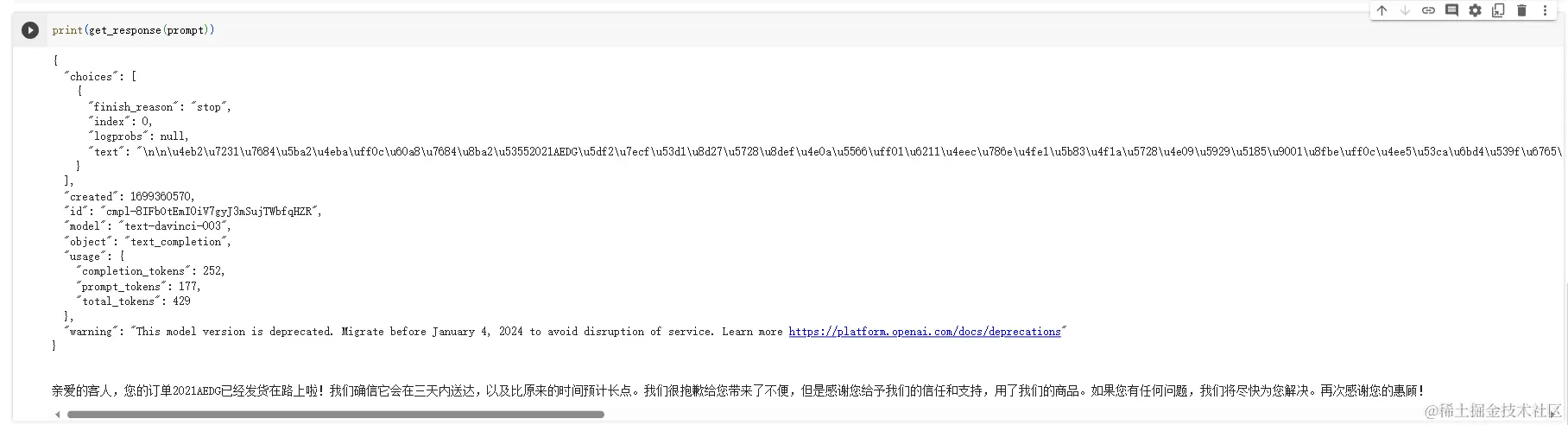
“亲爱的客人,您的订单2021AEDG已经发货在路上啦!我们确信它会在三天内送达,以及比原来的时间预计长点。我们很抱歉给您带来了不便,但是感谢您给予我们的信任和支持,用了我们的商品。如果您有任何问题,我们将尽快为您解决。再次感谢您的惠顾!”这一段就是我们想要拿到的结果,也就是客户得到的反馈。怎么样?是不是很简单?让我们再来试试其他的。
Sentiment-analysis
情绪分析(sentiment-analysis),根据字面意思我们就能理解这个模块就是用来进行分析情绪的,比如分辨出是积极的还是消极的,程度如何等等。接下来我们来试试这个模块:
python复制代码!pip install transformers # 安装一个transformers --- huggingface的核心库
然后我们来安装一下情绪分析和派发模块:
python复制代码from transformers import pipeline # pipeline 派发模块,用于分发任务 —— pipeline(task, model)
classifer = pipeline('sentiment-analysis') # 情感分析

接下来我们就可以试一试对于各个词AI对它的认识是怎样的,然后运行看看:
python复制代码result = classifer('I love you')
result
返回结果:[{'label': 'POSITIVE', 'score': 0.9998656511306763}]
python复制代码result = classifer('thank you')
result
返回结果:[{'label': 'POSITIVE', 'score': 0.9998352527618408}]
python复制代码result = classifer('shut up')
result
返回结果:[{'label': 'NEGATIVE', 'score': 0.9992936849594116}]
python复制代码result = classifer('遥遥领先')
result
返回结果:[{'label': 'NEGATIVE', 'score': 0.8616330027580261}]
'label'给我们展示了这个词是积极的还是消极的,'score'是一个相似值让我们有一个值能够参考。
前面几个例子属于正常,但我们在最后一个'遥遥领先'的词时,在我们现有的理解应该是积极的,但AI可能由于数据不足等原因导致了误判。有什么解决办法吗?当然有:
python复制代码# 中文模型 大众点评的亿万条数据训练出来的
classifer = pipeline('sentiment-analysis', model="uer/roberta-base-finetuned-dianping-chinese") # pipeline 派发一个任务

让我们安装一个经过训练的中文模型,这样AI就能更好地理解中文的意思。现在让我们再来看看调教之后的结果:
python复制代码result = classifer('遥遥领先')
result
返回结果:[{'label': 'positive (stars 4 and 5)', 'score': 0.941333532333374}]
这时我们就能很明显地看到返回结果被“矫正”过来了。
结语
今天我们简单体验了一下AI的使用和调试,是不是感觉很新奇?这仅仅是一个开始,之后还会带大家进行更多地尝试!如果对文章感兴趣的话,还希望能给博主一个免费的小心心♡呀~
