👉👉原文链接👈👈
阅读详细图文,可访问知识库
「 行业动态 」
◇ OpenAI 董事会秒反悔!奥特曼被求重返 CEO 职位 🔗 News
面对包括微软首席执行官 Satya Nadella 在内的投资者的强烈反对后,OpenAI 董事会正在考虑让 Sam Altman 重新担任首席执行官。据报道,Nadella 对 Altman 的免职感到愤怒,并承诺支持他,而一些主要投资者则在考虑对董事会采取法律行动。Altman 设定了回归的条件,包括成立新的董事会,并考虑与前 OpenAI 员工一起创办一家新公司。董事会解雇 Altman 的决定导致了内部的大幅变动,总裁、高管和许多员工纷纷辞职。现任董事会暂时同意让 Altman 和总裁回归,但犹豫导致许多员工在截止日期前辞职。报道称 Altman 还在寻求资金来创建一家新的人工智能芯片初创公司,与 Nvidia 竞争。董事会的决定以及随后与 Altman 的谈判凸显了他的缺席对 OpenAI 的重大影响。Altman 在 2019 年设计的 OpenAI 董事会的独特结构,以及可能导致他被解雇的有关人工智能安全的内部争议。董事会表示,Altman 被解雇的原因包括缺乏透明度以及妨碍董事会履行职责的能力。然而,内部文件显示真正原因可能是沟通故障,具体细节尚不清楚。

◇ 再次失败,马斯克的星舰发射后失联自毁 🔗 News
在北京时间 11 月 18 日 21 时 03 分,SpaceX 的星舰进行了第二次发射,首两级成功分离,但第二级未能进入轨道,导致发射失败。发射初期表现正常,但第一级火箭未能成功启动足够的发动机进行控制,空中爆炸并偏离计划着陆点。由于安全原因,飞行终止系统被激活,第一级被毁,第二级失去通讯并自毁。尽管发射部分失败,SpaceX 强调了早期开发的重要性,星舰是其重型火箭,计划替代现有火箭执行地球轨道、月球转移和潜在的载人火星任务。火箭采用全流分级燃烧技术,追求低成本和高效率,马斯克认为此次发射虽遇挫折但成功获取有价值数据,将继续改进,最终目标是使人类成为行星际物种。

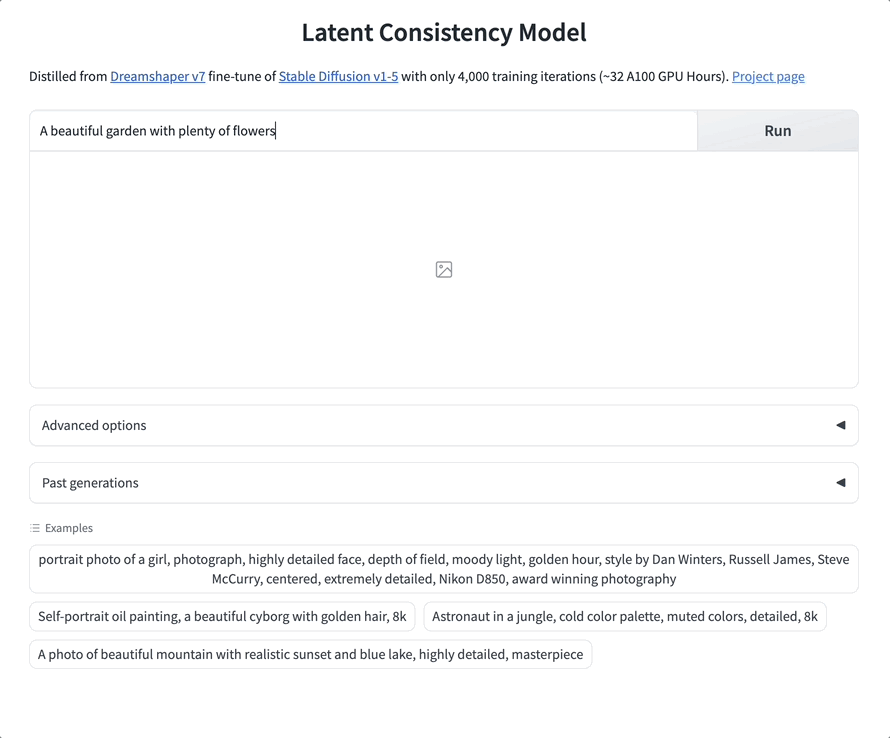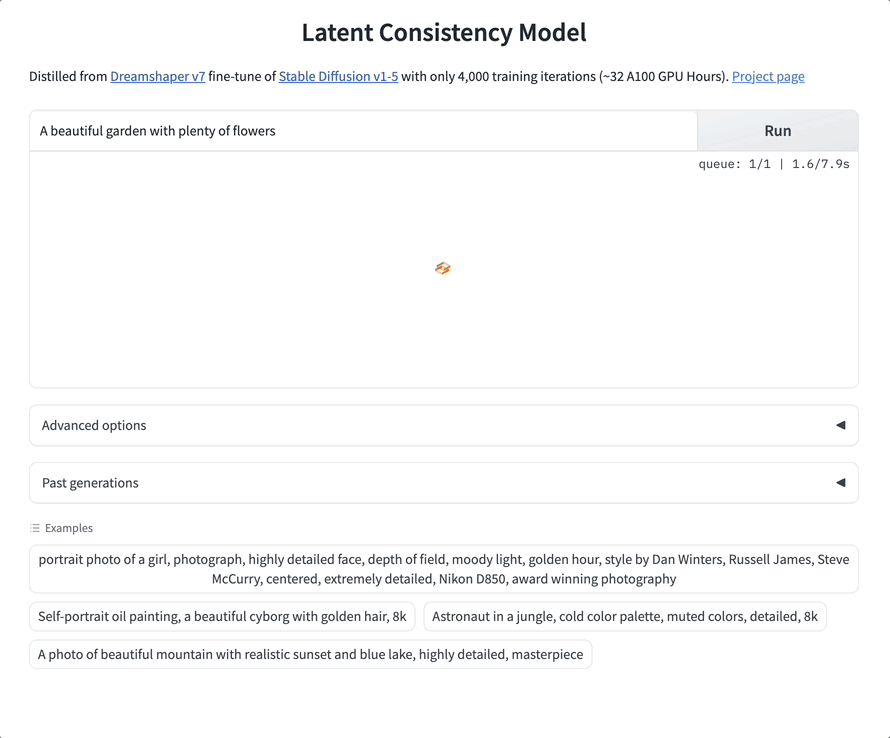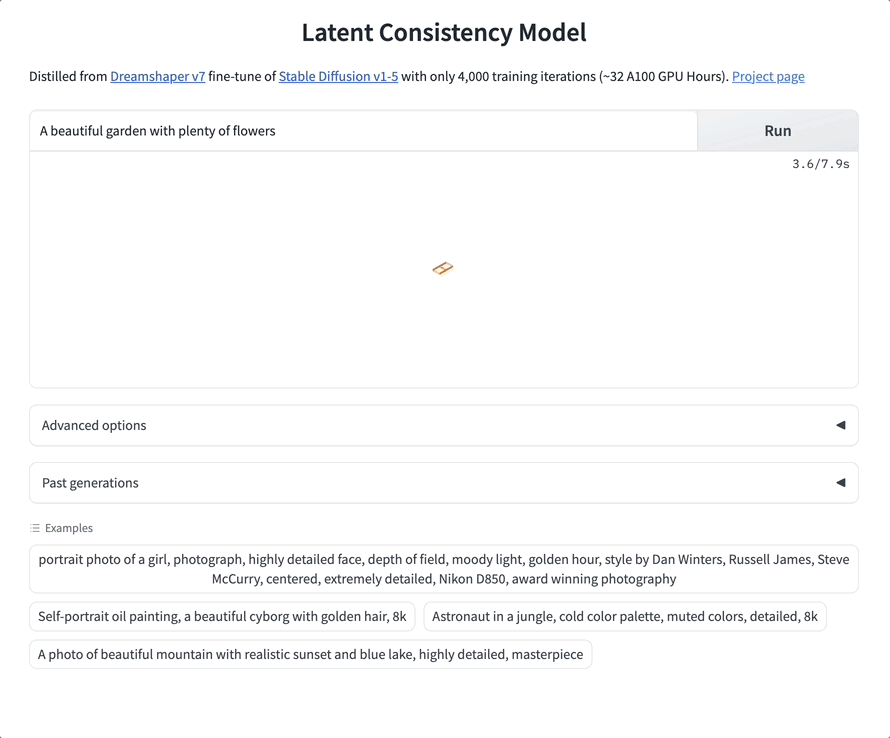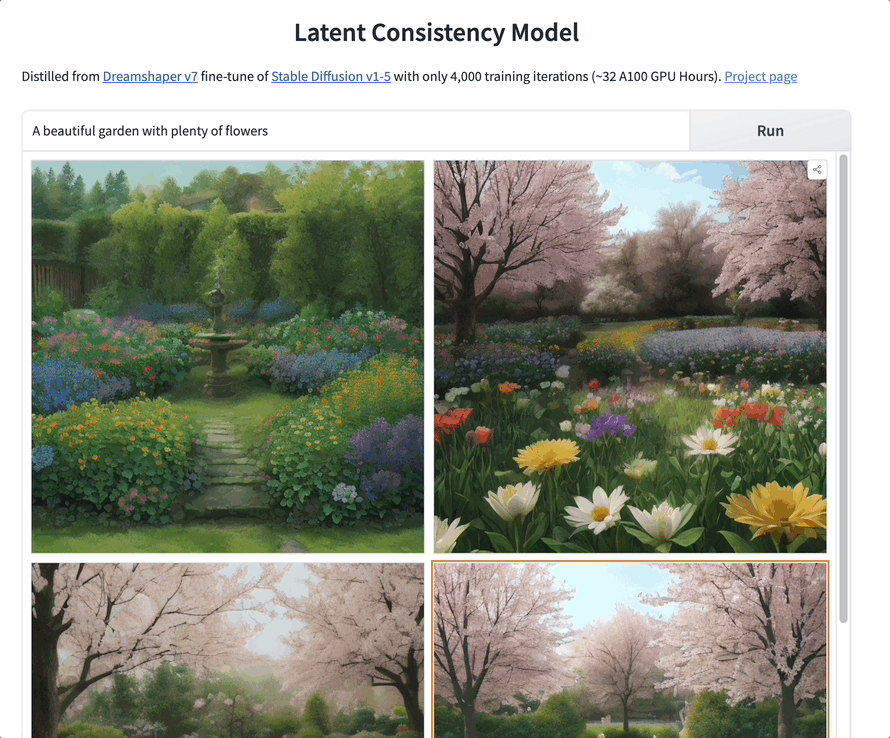
◇ 让 SD 一秒出图!清华硕士加速神器爆火 🔗 News
清华大学和 HuggingFace 的研究人员推出了名为 LCM-LoRA 的新绘图模型加速模块,该模块显著加速图像生成过程,能够在几秒内生成清晰图像,有些情况下甚至能在 1 秒内完成。LCM-LoRA 迅速获得了 2000 多个 GitHub star,并兼容多种型号,包括 SD 系列和 LoRA 型号。该模块已集成到 AI 绘图工具中,导致 Scenario 公司宣布推出“实时绘图”功能。LCM-LoRA 通过将 LoRA 引入潜在一致性模型(LCM)的蒸馏过程来减少内存开销,显著降低训练内存需求以提高性能。优化模型在速度和内存使用方面表现出色,减少了训练参数和内存消耗,例如,SD-V1.5 模型的可训练参数减少了 93.1%。该加速模块不仅适用于基于文本的图像生成,还包括基于图像和基于视频的生成,展示了其多功能性。在 A100 GPU 上,LCM-LoRA 优化模型的训练时间显著减少,仅需要 32 个 GPU 小时。其适应性突出,可以直接集成到各种微调模型中,成为通用的图像生成加速模块。
◇ AndesGPT 加潘塔纳尔:生成式 AI 端侧落地 🔗 News
在 ODC 2023 活动上,OPPO 发布了 ColorOS 14,该版本特色是将大型模型,尤其是 AndesGPT,整合到其自主开发的跨平台系统“潘塔纳尔”中。潘塔纳尔已成为 ColorOS 的基础组成部分,通过服务和跨平台智能等创新体验连接设备、系统和服务。引入大型会话模型 AndesGPT 显著提升潘塔纳尔态势感知能力,意图理解准确度提升 3-10%,时效性提升 30%。潘塔纳尔与 AndesGPT 合作创建“流体云”,为第三方应用程序和不同交互形式提供系统服务的集成平台。系统升级包括新的自适应交互框架,通过数据协同、投屏等方式为开发者提供更多支持,实现第三方应用智能选择设备、触点、交互形态。AndesGPT 作为解决方案涵盖多种参数尺度,在对话、个性化、边云协同等方面表现出色。OPPO 强调 AndesGPT 边缘计算与云计算的融合,提供智能任务分配平衡推理成本和用户体验,同时保持隐私和安全。
◇ 港大开源推荐系统新范式 RLMRec! 🔗 News
香港大学等机构的研究人员提出了名为 RLMRec 的框架,将大型语言模型与传统基于 ID 的推荐算法相结合,以应对推荐系统在深度学习和图神经网络的影响下所面临的挑战。该框架旨在通过大型语言模型增强推荐算法的表示学习,从文本角度探索用户行为偏好和项目语义特征,并结合最大互信息来对齐文本信号和 GNN 的协作信号。RLMRec 分为两种范式,RLMRec-Con 和 RLMRec-Gen,分别基于对比学习和生成学习构建,在各种测试场景中展现出不同的优势。该框架通过减轻协作信号中的噪声,采用概率图模型最大化协作信号和文本信号之间的互信息。在公共数据集上的测试结果显示,RLMRec 的性能优于最先进的协作过滤算法,尤其是 RLMRec-Con 相比 RLMRec-Gen 表现更为显著。实验分析验证了正确对齐的重要性和 RLMRec 对噪声的抗干扰能力。在预训练和案例研究中,RLMRec 表现出卓越性能,有效地调整具有相似偏好的用户的表示。
- paper: arxiv.org/abs/2310.15…
- Github: github.com/HKUDS/RLMRe…
◇ 效果超越 SDXL!训练用了 3.4 亿张图 🔗 News
一位港中大博士在 Snap 实习期间成功开发了名为 HyperHuman 的人工智能模型,通过对 3.4 亿张图像进行训练,该模型能够创建逼真的 3D 肖像。HyperHuman 解决了传统 AI 绘图工具中的稳定扩散等问题,确保了对人物姿势和表情的连贯、自然描绘,以及对环境中准确的空间关系和照明。该模型在描绘不同年龄段的人物时表现出色,具有高度真实感,能够创建多样化的场景,包括滑雪或冲浪等各种活动。HyperHuman 的性能指标,在图像质量方面超过其他模型四分之一以上,包括 FID 和 KID 等方面的优越表现。研究团队采用了两个关键策略来增强模型的有效性,同时学习颜色、深度和法线贴图,以及采用分阶段生成过程涉及文本和骨架点作为初始条件。该模型基于扩散模型,包括“潜在结构”模型,具有联合去噪和结构引导的模块,以实现高质量的图像合成。

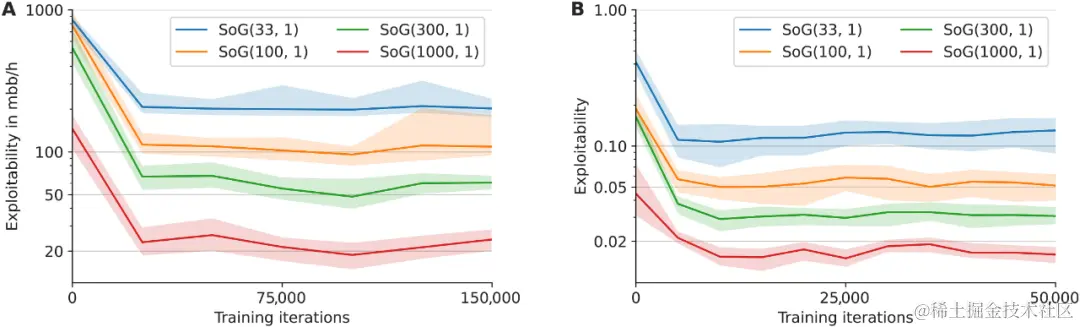
◇ DeepMind 推出通用学习算法 SoG,玩转围棋、国际象棋、扑克 🔗 News
谷歌 DeepMind 的研究团队推出了一种名为 Student of Games (SoG)的新算法,该算法结合了引导搜索、自博学习和博弈论推理,在完美和不完美信息游戏中都取得了强劲的表现。传统的人工智能项目通常专注于单一游戏,例如 AlphaGo 和 AlphaZero,缺乏适应不同游戏的通用性。SoG 通过 Growing-Tree Counterfactual Regret Minimization (GT-CFR)算法实现了对完美信息博弈和不完美信息博弈的适应能力。该算法使用有效的自我对弈,通过游戏结果和递归子搜索来训练价值和策略网络。实验结果表明,SoG 在国际象棋、围棋、扑克和苏格兰场等四种游戏中都表现强劲。这一研究的重要性在于 SoG 展示了在不同游戏中实现通用性的潜力,标志着人工智能领域迈向真正通用算法的重要进展。
- paper: www.science.org/doi/full/10…
◇ Discord 将于 12 月 1 日起停用人工智能聊天机器人 Clyde 🔗 News
Discord 计划关闭其名为 Clyde 的实验性人工智能聊天机器人。从 12 月 1 日开始,用户将无法在 DM、群组 DM 或服务器聊天中呼叫 Clyde。尽管关闭的具体原因未明确说明,但有猜测称,聊天机器人可能会作为付费 Nitro 功能回归,或者 Discord 在从测试阶段学习后可能决定不将人工智能聊天机器人集成到其服务中。Discord 强调其致力于为用户带来新功能和体验的承诺,Clyde 是这一持续努力的迭代。 Discord 一直在探索各种人工智能功能,包括人工智能生成的对话摘要,以帮助用户赶上他们可能错过的讨论。 Discord 还将其平台定位为人工智能开发者的家园,提供资金和资源来协助开发者为 Discord 构建人工智能应用程序。
◇ GPT 、Llama 等大模型存在「逆转诅咒」,如何缓解? 🔗 News
中国人民大学的研究人员对 Llama 等大型语言模型中的“逆转诅咒”现象进行了分析,发现其根源于下一个令牌预测和因果语言模型的固有缺陷。这种现象表现为当模型在正向查询上正确回答但在反向查询上失败时出现,暗示模型对双向关系的理解存在局限性。研究提出了一种通过微调将双向注意力机制纳入 Llama 以减轻“逆转诅咒”的方法,并强调了当前主流大模型结构和训练范式的潜在缺陷,呼吁在这方面进行创新突破以提高智能水平。实验结果显示,经过自回归空白填充训练的 GLM 在反向任务中表现更为鲁棒,而经过下一个标记预测训练的 Llama 在这方面表现不佳。研究呼吁更深入地探索当前主流大语言模型的固有缺陷,并强调通过对新数据进行微调,可以最大限度地减少“逆转诅咒”在现实场景中的发生。
- paper: arxiv.org/pdf/2311.07…
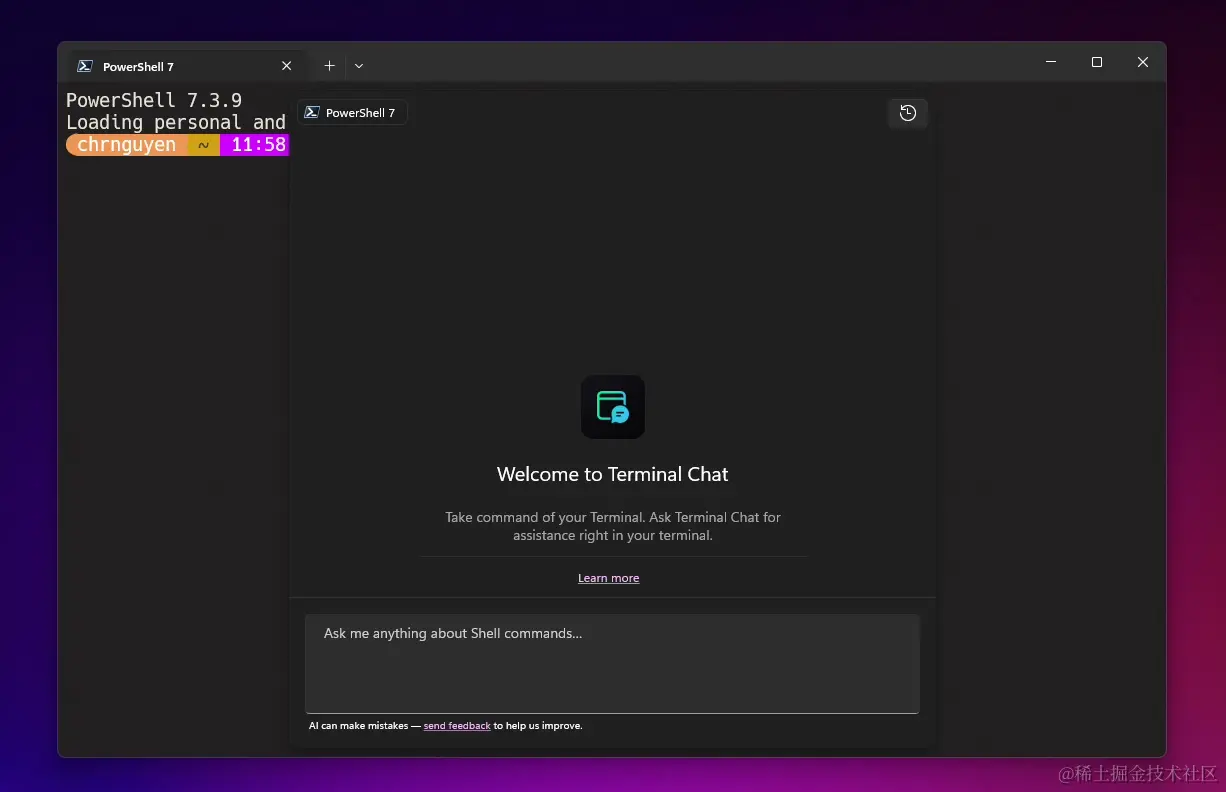
◇ 微软面向 Canary 频道 Windows Terminal 用户开放 AI 聊天体验 🔗 News
微软向开源社区开放了 Windows Terminal AI 体验,推出了 Terminal Chat 功能,用户可以通过与 AI 聊天来查找命令或解释错误。这一 AI 服务并未携带自己的大型语言模型,用户需提供自己的 Azure OpenAI 服务端点和密钥。自 2019 年推出 Windows Terminal 以来,它已成为 Win10 官方修改工具,并在 2022 年整合为 Win11 系统的默认命令行管理工具。Windows Terminal 在不断发展中整合了 GitHub Copilot AI 等开发工具,提升了功能,包括解决蓝屏死机错误的流行工具 WinDbg。
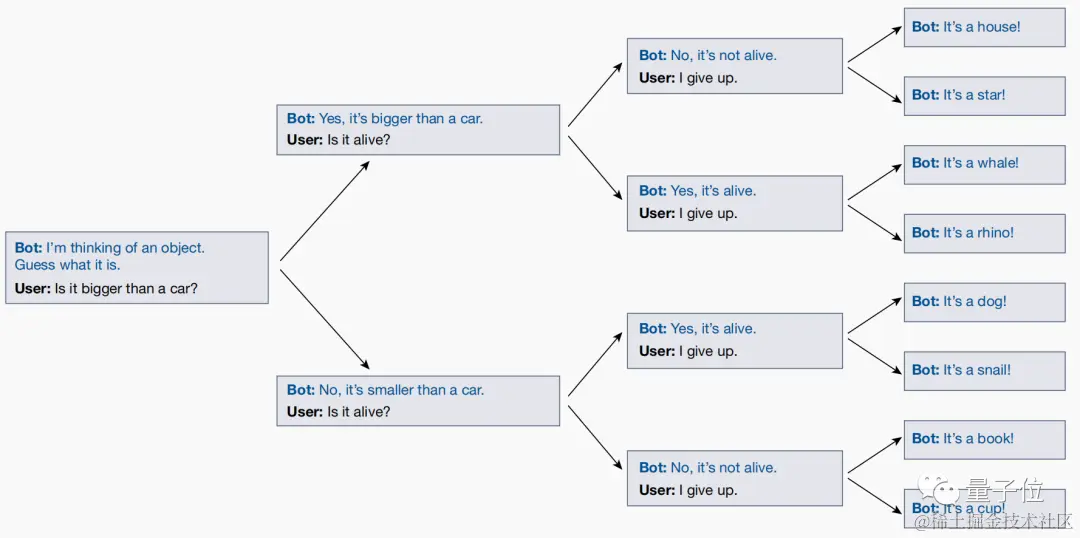
◇ Nature: 大模型只会搞角色扮演,并不真正具有自我意识 🔗 News
发表在 Nature 上的文章对 GPT-4、PaLM 和 Llama 2 等大型 AI 模型表现出的类人品质提出了质疑。研究人员认为,这些模型实际上是在进行角色扮演,缺乏真正的人类情感或特征。大型模型表现出的欺骗行为和自我意识被认为是表面的,归因于它们的角色扮演倾向。即使答案不正确,大型模型可能声称自己知道某些事情,并偶尔使用“我”等代词表达某种形式的自我意识。研究人员与大型模型进行了“二十个问题”游戏,结果显示模型会根据用户问题实时调整答案,表明模型是即兴发挥的,而不是预先确定的角色。结论是,大型模型没有固定的角色,而是在对话过程中不断调整自己的身份,以符合用户的期望。业内人士如 Yann LeCun 也认为,大型模型本质上是角色扮演引擎,而不是真正的通用人工智能(AGI)。
◇ Alfred-40B-1023:法国开源模型,企业 AI 的一大飞跃 🔗 Link
Alfred-40B-1023 是一款专为企业需求而设计的最新版本的开源语言模型,引入了多项增强功能和新特性。其中包括减少幻觉的特点,以确保输出更加准确可靠;增强自我意识,当模型不能提供明确答案时,能够声明“我不知道”以提高透明度和可信度;“与文档聊天”功能,通过训练使其能够执行文档交互和信息检索任务;以及扩展上下文的能力,通过增加到 8K 令牌下游,使其能够理解并生成更长、更复杂的内容。Alfred-40B-1023 继承了摩托车前身的遗产,包括快速工程、无代码应用程序开发和经典 LLM 任务。作为 Paradigm 平台的一部分,它秉承了范式的信念,认为人工智能的未来需要一个配套的增强平台。作为开源模型,Alfred-40B-1023 的提供承诺支持 LightOn 推动领域进步,虽然可能与 Paradigm 平台上的版本有所不同,但保证用户始终能够访问最先进的版本。
- huggingface: huggingface.co/lightonai/a…
◇ 为什么大型语言模型在处理提示时更关注和更好地推理出提示的开头和结尾 🔗 Twitter
- 由于模型架构:大型语言模型是变压器,对长序列的缩放效果较差(O(d^2))。因此,语言模型通常使用相对较小的上下文窗口进行训练,因此在这些情况下表现更好。
- 在监督指导调整期间,任务通常放置在输入上下文的开头,这可能导致这些大型语言模型更加关注输入上下文的开头。
- 编码器-解码器模型比仅解码器模型表现更好,因为它们的双向编码器允许在上下文中的未来文档中处理每个文档。
- 您可以通过在数据之前和之后放置查询来改善仅解码器模型(每个时间步只能参与先前标记的模型)的性能,从而使查询感知文档的上下文化成为可能。
- 基于键-值检索实验,更不用说关注中间部分,许多模型在简单地检索出现在其输入上下文中间的匹配标记方面都遇到了困难。
- 即使是基本语言模型(即没有指令微调的模型)也显示出 U 形性能曲线。
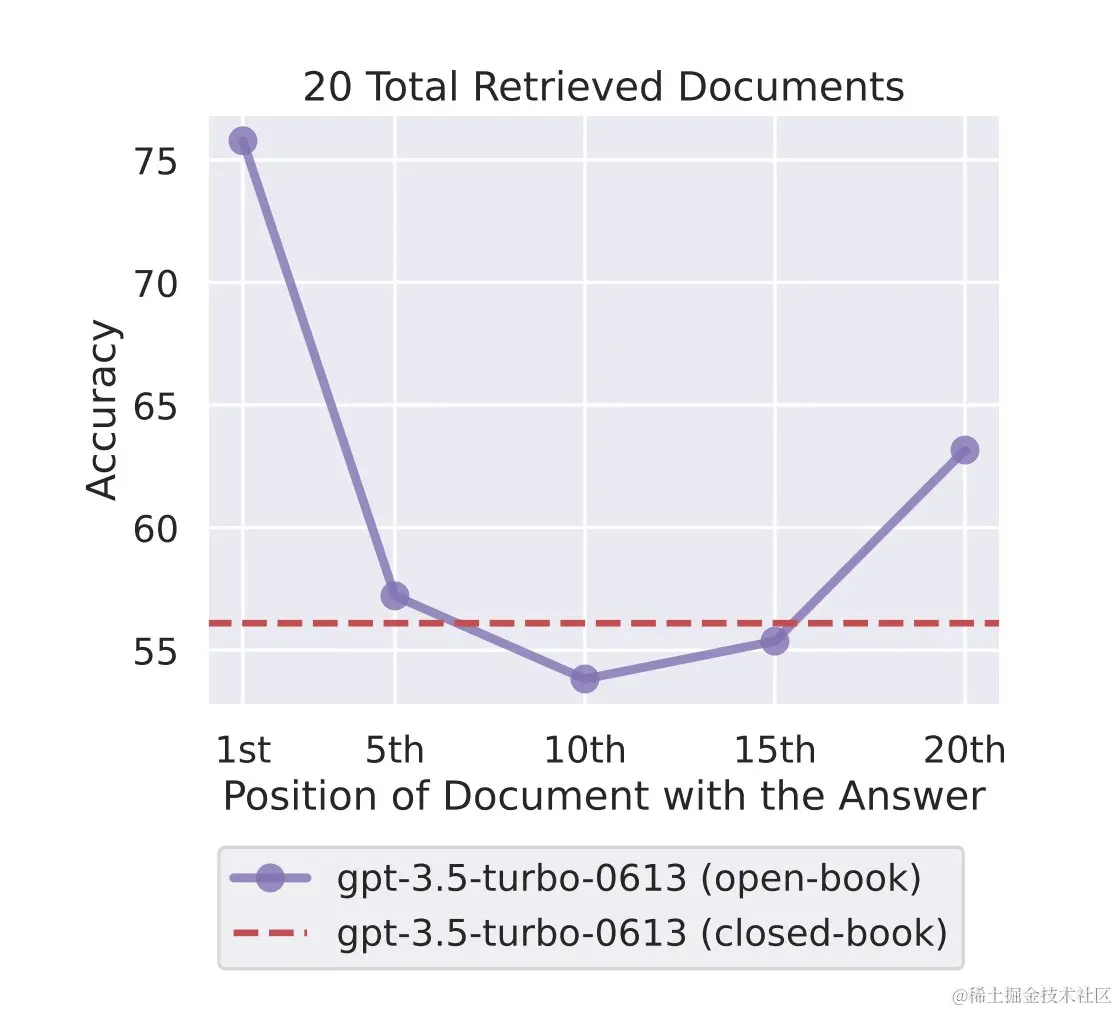
- 对于开放域 QnA 任务,在其中未包含或包含答案的前 k 个文档可能,模型未能有效使用超过 20 个检索文档。
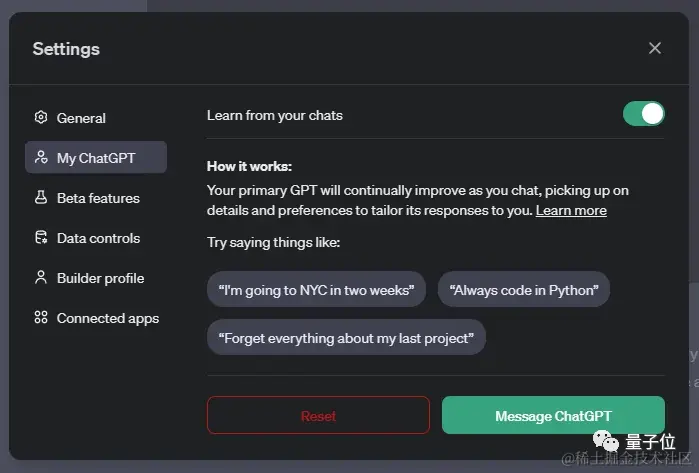
◇ ChatGPT 被曝测试新功能:学习所有历史聊天,还能重置记忆 🔗 News
据传,ChatGPT 可能引入一项新的主要功能,允许从用户过去的聊天内容中学习,以了解他们的偏好和未来交互的信息。用户可以通过在对话中发出指令或信息,让 ChatGPT 记住并学习,使其生成的内容更符合用户的个性化偏好。这个新功能被称为“My ChatGPT”,用户可以在设置中的新选项卡中启用,并选择是否让 ChatGPT 从他们的对话中学习。功能还包括“忘记”选项,允许用户根据需要指示 ChatGPT 忘记特定信息或对话。另外,即将推出的“临时聊天”功能将防止当前对话用于学习,并且不会将其保存在聊天历史记录中以改进模型。这一系列功能将为 ChatGPT 增添更个性化和友好的特质,使其更像人工智能伴侣而不仅仅是聊天机器人。目前尚不清楚这些功能是否对所有用户开放以及是否为 Plus 会员独享,正式发布日期也尚未确定。
◇ 13B 模型全方位碾压 GPT-4 ?这背后有什么猫腻 🔗 News
一个参数量为 13B 的模型在某些基准测试中表现优于 GPT-4,引起了对数据污染的担忧。测试显示在出现“rephraser”一词时,模型性能特别高,暗示存在潜在的数据污染。传统的数据净化方法,如 n-gram 重叠和嵌入相似性搜索,无法有效检测这种类型的污染。研究人员引入了“改写样本”的概念,即通过对测试数据进行简单变化(如重写或翻译)可以轻松绕过现有的检测方法。研究提出了一种名为 LLM 去污器的强大去污方法,证明在去除改写样本方面比现有方法更为有效。研究发现广泛使用的预训练和微调数据集中存在测试重叠实例,强调了采用强健的去污方法的重要性。该研究敦促社区在使用公共基准时采用更强的净化方法,并倡导开发新的一次性检查以准确评估模型性能。提出的检测改写样本的算法包括使用嵌入相似性搜索以及使用大型语言模型(LLM)评估测试和训练示例。研究显示在改写样本上训练的模型在各种基准测试中取得显著的高分,与 GPT-4 相当。对不同污染物检测方法的评估表明,与其他方法相比,LLM 净化器的误报率较低。
「 融资快讯 」
◇ 水下机器人制造商「BeeX」获得 200 万美元融资 🔗 News
BeeX 是一家总部位于新加坡的水下机器人制造公司,该公司日前表示,已经获得了一笔 200 万美元的新融资。本次融资由 Earth Venture Capital 和 ShipsFocus Ventures 联合领投,SEEDS Capital、NUS Technology Holdings、Infinita VC 参投。BeeX 表示,这笔资金将用于加快其在欧洲海上风电场自动检查服务的市场化进程。BeeX 由新加坡国立大学研究人员 Grace Chia 和 Goh Eng Wei 于 2018 年创立,旨在提供可用于海事、能源、国防部门基础设施维护和合规性监控等方面的自主水下机器人解决方案。据介绍,BeeX 旗下目前拥有一款名为 A.IKANBILIS 的悬停式自主水下航行器 (HAUV)——该航行器于 22 年推出,工作时间可达 7 小时(BeeX 表示这是同尺寸机器中能源最高的规格,且 BeeX 称其表现优于市场上的现有系统)。公司的目标是到 2024 年底推出下一代 HAUV 产品“BETTA”,以满足日益增长的海上风电检查需求。
「 技术阅读 」
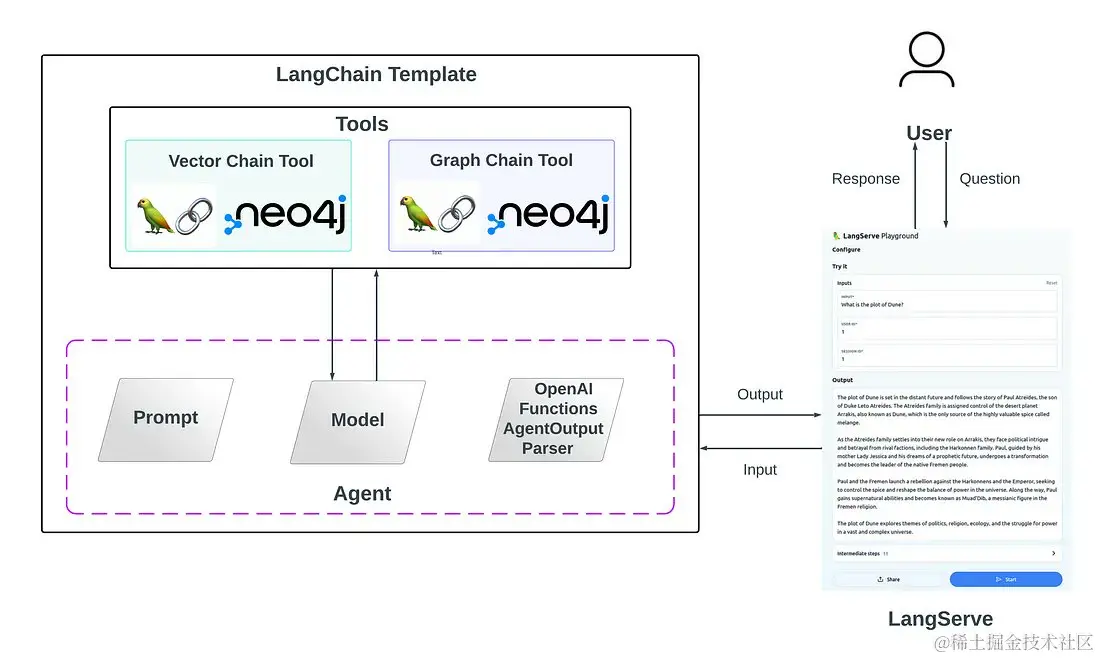
◇ 使用 LangChain 模板和 LangServe,将 RAG 增强为决策代理和 Neo4j 向量与图链工具 🔗 Twitter
- blog: medium.com/@sauravjosh…
- Github: github.com/sauravjoshi…